# 1 教程
[全民一起玩 python](https://www.bilibili.com/video/av85391396?p=4)
## 語法特點
* 不用聲明變量
* if 后要加: 冒號
* **同一層級的代碼要對齊**,如果有縮進則會認為是被包含關系的下一層級的代碼
* 不要用 python 讀取 word 文件,因為 word 中有各種各樣的格式,讀取有誤
* print()里面內容用逗號, 連接,input里面內容用加號+連接。
* 自定義 函數:vba中自定義函數(如function ccc())如果有返回值,只需要寫 ccc = xxx即可。
* python中,自定義函數與c#一樣要寫一個return xxx。
* 冪運算 用兩個“/*/*” 表示 ‘2**3 = 8’
* 正數整除用“//”表示

## 快捷鍵
https://www.cnblogs.com/liyuanhong/articles/4375890.html
加縮進:可以直接選中按tab
批量注釋:alt +3
去注釋:alt +4
## 幫助文檔
https://docs.python.org/zh-cn
## 全民一起玩python教程資料
[https://www.ukoedu.com/pythoncourseinfo](https://www.ukoedu.com/pythoncourseinfo)
## bilibili 免費課程

[https://www.bilibili.com/video/av31294714?from=search&seid=14926404958243477782](https://www.bilibili.com/video/av31294714?from=search&seid=14926404958243477782)
pyp 中文網里面也有很多相關的視頻
官網:www.python.org,可以直接下載。也可以用 visual studio 編輯器編輯。但要注意重新安裝一下 python 模塊(重啟visuan studio 安裝程序,選擇“修改”即可)。
## 學習網站
[知乎問答](https://www.zhihu.com/question/36082950)
[某博客中推薦的內容](https://www.cnblogs.com/guohongwei/p/10840963.html)
[廖雪峰的官方網站](https://www.liaoxuefeng.com/wiki/897692888725344/897692941155968)
[runoob 網站(推薦)](https://www.runoob.com/python/python-tutorial.html)
## 環境設置:添加行號
[https://www.jianshu.com/p/dd1dc070367f](https://www.jianshu.com/p/dd1dc070367f)
[https://blog.csdn.net/huidr0/article/details/97804411](https://blog.csdn.net/huidr0/article/details/97804411)
[http://www.pythonheidong.com/blog/article/49497/](http://www.pythonheidong.com/blog/article/49497/)
其中文本configHandle里面設置的要跟linenumber里面一致。注意幾行代碼的一致性,比如configHandle.py 是否在python/Lin/idlelib文件夾,如果沒有,則從下載文件中復制到擴展包中。

可以先運行linenumber.py。看是否有問題,如果沒問題即可。
或者:用alt+g定位錯誤代碼行。

> 重啟后,在options設置里面記得勾選!!
## 符號
不等于:'!='
# 占位符 第18講
```
total = total +1
print('the total is:' , total) //這里用逗號隔開即可,而不是用加號
```
但是如果要連接字符串時,就要寫加號。

```
name = 'abc'
age = 12
s = '我叫'+ name + '我的年齡'+ age+'歲'
print(s)
上面可以替換成:
s = '我叫%s,我%d歲了,還 沒讀書。' &(name,age)
```
> 記得在后面加`& (name, age)` ,不同的占位符代表的不一樣。
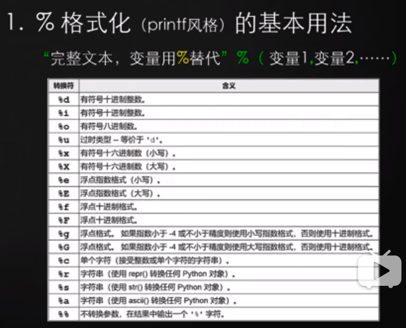

或者用`s = f ' 我叫{name},今年{age}歲 ,沒有讀書 ' `。直接 f 加引號的辦法,中間就可以直接用變量名+花括號。f與引號不能有空格。


# 交換變量
```
a = 3
b = 5
c = 1
a,b,c = c,a,b
print(a,b,c) #顯示結果為:a,b,c = 1,3,5 注意交換,是把等號右邊的值傳給左邊。
# 顯示
```
# 2 函數
python 里面有很多的庫,調用的時候要寫“import”,比如數學運算是在一個叫`math`的庫里面,要寫`import math`調用。同時如果要顯示結果必須寫
```
import math
print(math.sin(3))
```
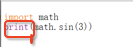
這里面 print 不能少,否則無法顯示計算結果。
> 同一層級的代碼必須對齊,否則默認為是下一層級
常見模塊(庫 ):
標準庫 http://docs.python.org
## print 函數
用逗號隔開,與其他語言不同!
`print ("張三",power)`
vba 里面是用`&` -> `msgbox '張三' & power`
用單引號還是雙引號都行。
## 交互式:用 input 函數
但是input 默認都是字符串,所以需要 int 或者 float函數轉化成數字

也就是說,`c = int( input ('請輸入漢字:') )` 這樣得到的c也是一個int,不管input里面是漢字+數字,只要用戶輸入的格式正確就行。
## 音頻文件
課程第六回
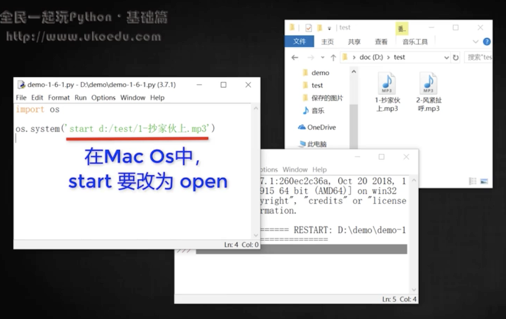
# 3 os 模塊
打開文件、打開文件夾。
其中有一條 `os.system()`可以用來執行類似打開文件夾、關閉等的操作

```
import os
os.system('start …… ' ) 用斜線/。
os.system('open ') //在蘋果操作系統上面要用 open
```
```
import os
os.system('start Y:/Desktop/測試.xlsx')
```
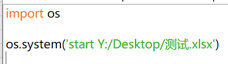
或者是反斜線也行。

## if else
```
if xxx:
elif xxx:
else:
```
## 邏輯運算 and 多條件
```
if gender =='femail' and (age<20 or age > 30):
也可以寫成:'if gender == 'femail' and not 20<age<30'
```
## open
如果直接寫`os.system('start Y:/Desktop/測試 .xlsx', 'r')`,則只是打開了這個文件,但后續想對文件進行操作,仍建議創建對象。
也可以弄成一個對象
`f = open('start Y:/Desktop/測試.xlsx','r') #只讀方式打開`
r:只讀,w:寫入(原文本全部清除后再添加新內容),a:追加。
用 open 方法,但 open()執行以后,就自動創建了一個對象,我們可以用 `f = open('')` 來表示,如果不,也可以直接用`open('')`來表示,后續可直接調用`open('').readlines`等。
所以 f 就表示我們打開的這個文件窗口了。
以下例子用來統計出現次數,同8字典。
```
f = open('','r')
p = f.readlines() #如果文本中有回車換行,那么 readlines 方法就會自動識別,如果有 4 個段落,那么 p 就變成了一個有 4 個元素的列表,其中每個元素是一個字符串,用 ' ' 括起來。
i = 0
for s in p:
if '你真漂亮' is s:
i=i+1
print(i,s)
f.close()
```
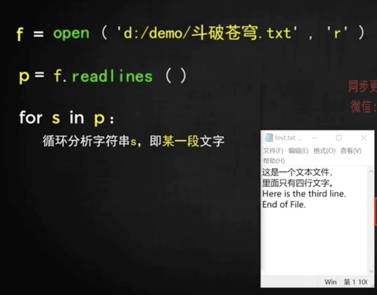
## readlines
`p = f.readlines()` #如果文本中有回車換行,那么 readlines 方法就會自動識別,如果有 4 個段落,那么 p 就變成了一個有 4 個元素的列表,其中每個元素是一個字符串,用 ' ' 括起來。
比如下面這段話一共3段。
“我去吃飯了,
你叫一下他。
他沒聽我說。
”
那么p = f.readlines()以后就是:`f.readlines() = ['我去吃飯了,' , '你叫一下他。' , '他沒聽我說。' ]`
所以如果p.count('我'),也可以統計出結果。
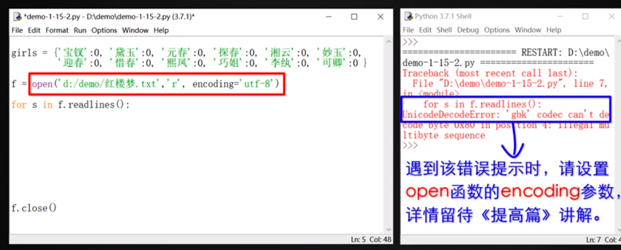
## 讀取文件保存報錯
UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 205: illegal multibyte sequence
因為不要用 python 讀取 word!!!,word 有自己軟件自帶的一些 markdown 語法,與 python 不兼容!!!
[https://blog.csdn.net/lqzdreamer/article/details/76549256](https://blog.csdn.net/lqzdreamer/article/details/76549256)
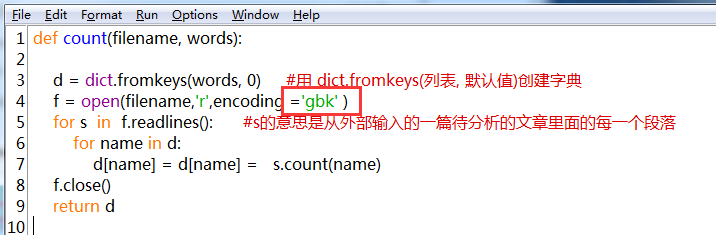
可修改代碼,`f = open('','r',encoding = 'gbk')` ,或者是`f = open('','r',encoding = 'utf-8)` 有的時候用gbk,有的時候用utf-8,看情況。比如字典中的自定義函數例子mytools.count就只能用gbk。
第16講。
## 用一個新的txt文件來存放拆分的單詞內容 拆分單詞 分詞 類似也可以用8 字典。
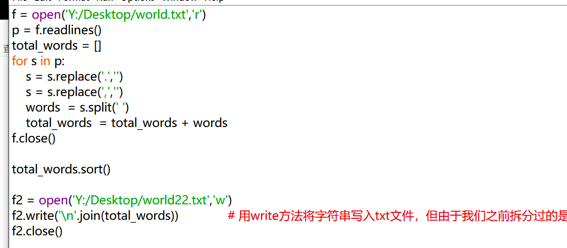
將一篇英語文章全部拆分成單詞,放入一個新的txt文件中:
```
f = open('Y:/Desktop/world.txt','r')
p = f.readlines()
# 如果f 文章一共4段,那么p就有4個元素,每個元素對應一段
total_words = []
for s in p:
#為了得出每一段中的所有單詞,再匯總
s = s.replace('.',' ')
#標點符號全部去掉,用空格代替,后續就可以只用空格進行劃分了
s = s.replace(',',' ')
#標點符號全部去掉,用空格代替,后續就可以只用空格進行劃分了
s = s.lower() #有的單詞大小寫不同會被識別成不同單詞,所以要統一格式
line_words = s.split(' ')
#每一段全部拆分成一個一個單詞
total_words.extend(line_words) #也可以寫成total_words = total_words + line_words
,但如果是加法,則每次都會新建一個列表,效率低,而用extend方法則可以直接在原有列表中添加。
f.close()
set_words = set(total_words)
total_words = list(set_words)
total_words.sort()
#排序一下按字母表順序排
f2 = open('Y:/Desktop/world22.txt','w')
f2.write('\n'.join(total_words)) # 用write方法將字符串寫入txt文件,但由于我們之前拆分過的是列表,不是字符串,所以要用join方法再連起來,但我們更希望換行,所以可以用'\n'把這些列表連接成一個字符串,同時又有換行的功能
f2.close()
#一定要記得寫close!!!!不然會發現新建了文件但打開沒有內容,因為如果不寫close,則默認東西還是在內存中。只有加了close以后才能看到文件內容。
```
> 用write方法將字符串寫入txt文件,但由于我們之前拆分過的是列表,不是字符串,所以要用join方法再連起來,但我們更希望換行,所以可以用'\n'把這些列表連接成一個字符串,同時又有換行的功能
;
> 一定要記得寫close!!!!不然會發現新建了文件但打開沒有內容,因為如果不寫close,則默認東西還是在內存中。只有加了close以后才能看到文件內容。
> **代碼簡化**!!!有一些s只是用來傳遞值,所以可以簡寫成`line_words = s.replace(',',' ').replace('.',' ').lower().split()`
> 

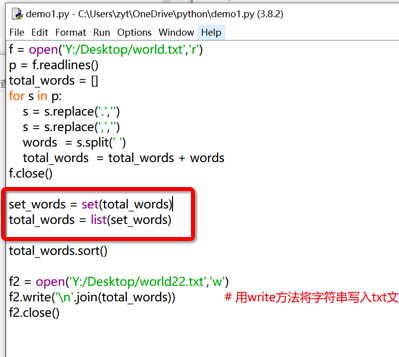
但還有個問題:上圖中單詞出現重復,我們需要的是不重復的單詞。此時可以用set解決。在sort轉置前加兩行:
```
set_words = set(total_words) # set功能的意思是得到不重復的子集,不考慮順序。詳見“7 集合”
total_words = list( set_words) # 詳見“7 集合”
```

> **簡化:**



也可以用第三方插件,如jieba.py
# 4 循環 if、while、for
```
if age<18 : $$冒號不能省略!注釋用$$美元符號
print('未成年')
else :
print("成年")
```

if 在 25-30之間:25<= age <=30
while 重復錄入
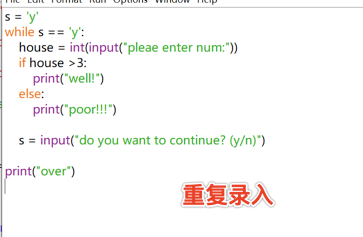
注意有計數器的功能! 用i++ 這樣的形式來計數,然后作為判斷條件。
```
s = 'y' #記得要有初始值!!!!
m= 0
while s =='y'
name = input('please enter name:')
age = input('please enter age:')
m = m +1
s = input('do you want to continue?(y/n)')
print("total:", i )
```

## 死循環
ctrl+c 強制退出
但有時候為了不斷輸入,可以人為制造死循環。如下圖
```while 1==1
x = int(input('請輸入數字:'))
```
## for
for i in 列表:
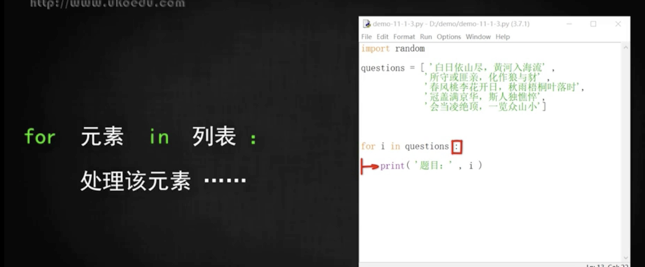
語句類似于c#、vba 中的`for each`
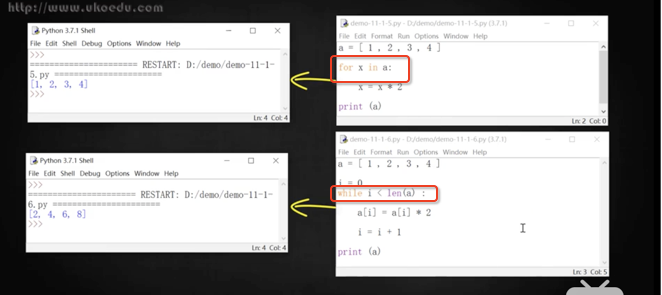
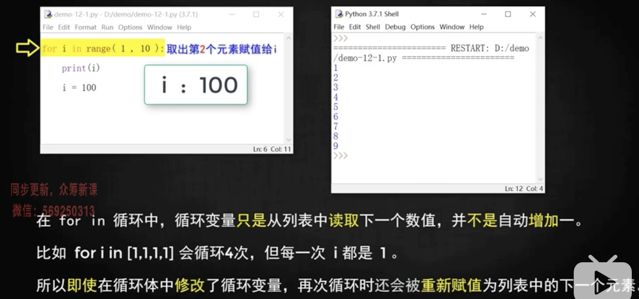
>**但 for 循環只能讀取,不能修改列表中的值,用 while 則可以修改列表中的值**
## 隨機數
`import random`
random.randint(a, b) 隨機生成 a b 之間的整數。
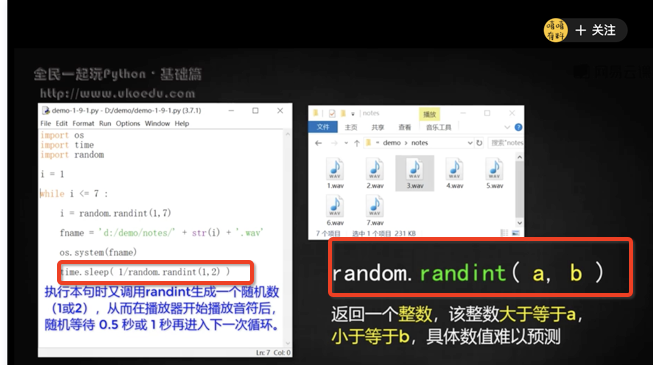
生成隨機數,用來猜大小
記得 break

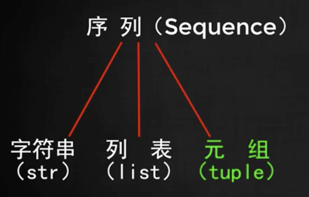
# 5 序列
包括列表、字符串、元組、集合等
# 6 列表,可以理解為數組 第 12講
用方括號`[]`
> 注意取數范圍!
可以用冒號表示數組中的某幾個元素,但注意右邊是開區間,要比下標元素大 1,也就是,如果列表里面只有 5 個元素,那么下標編號就是 0-4,如果要從下標 2 開始取數到下標 4,那么必須寫成 a[2:5),而不是 a[2:4]
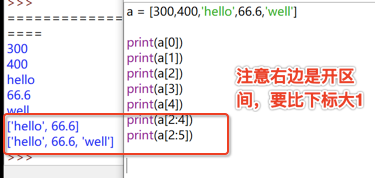
> 但如果不寫取值范圍的起始值,只寫冒號后面,與上面一樣,也是開區間,比下標大 1。
](images/screenshot_1582969650489.png)
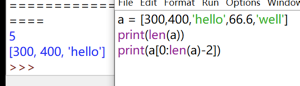
## 長度
```
a[300,400,'hello',66.6,'well']
print(len(a)) #即可求出長度
print(a[0:len(a)-1]) #即可列出 a 中所有元素,這樣當后續 a 進行修改時,就不用在修改 print 里面的內容了
```
## 相乘
```
a[1,2,'a']
print(a*3) # 則是把 a 里面的元素復制 3 次
```

## range(m,n) 第 12講
比如range(3,7)
自動生成 [3,7)之間的數字,也就是[3,4,5,6],左閉右開,要記得!!!
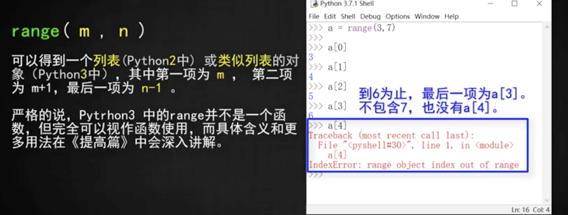
也可以只提供 一個7
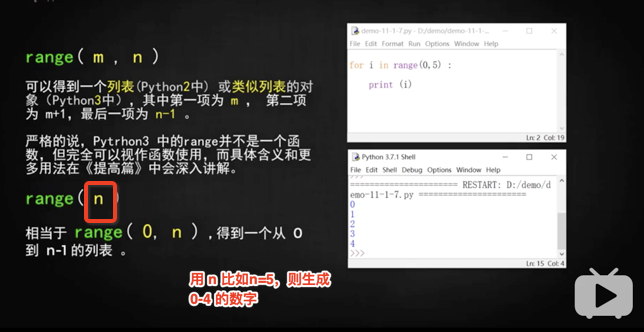
range 可指定步長,比如range(1,10,2),生[1,3,5,7,9],不需要跟其他語言一樣自己 i++,因為默認每次循環,都自動跳到下一個。
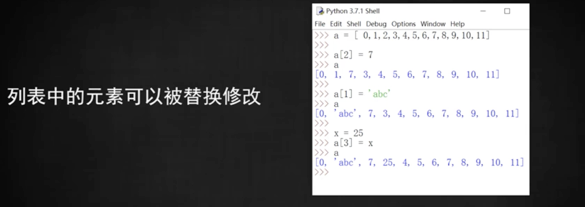
## 元素可替換
```
a = [300,400,'hello',66.6,'well']
a[3]='www'
顯示:a = [300,400,'hello','www','well']
```
## 添加列表元素
```
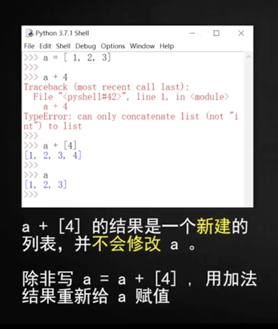
a=[1,2,3]
a+4 #報錯!!!!因為加號左右兩邊格式不一樣
a+[4] #可以,結果變為[1,2,3,4],但 a 本身還是[1,2,3]
a = a+[4] # 除非這么寫才可以a=[1,2,3,4]
a.insert(2,'qqq') #從下標2開始插入qqq,qqq的下標是2,原來的數據往后移
```
**更好的辦法:**
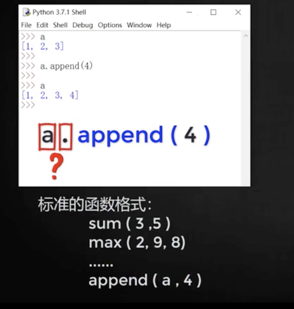
直接寫a.append(4)即可。因為列表是對象,可以用屬性!
第15講,也可以用`a.exten(b)`,如果用加法,則每次都會新增一個新的列表,效率低。

## 列表是個對象,可以用各種屬性!!! 第 13講

面向對象!——屬性+方法
所以上面的例子直接寫`a.append(4)`即可

其他方法:
```
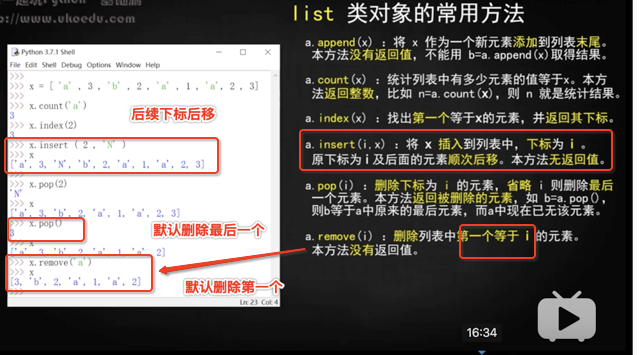
a.append()
a.count('NNN') #統計某個元素 NNN 出現的次數
a.insert(i,'NNN') #從下標 i 開始插入'NNN',原來下標 i 的元素變成下標 i+1
a.pop(i) #移除下標 i 的元素,不直接括號內寫要移除的內容!!!!如 a.pop('NNN')則報錯,而要用 remove 方法!
a.remove('NNN')
a.reverse() #倒序
a.sort() #從小到大自動排序
```
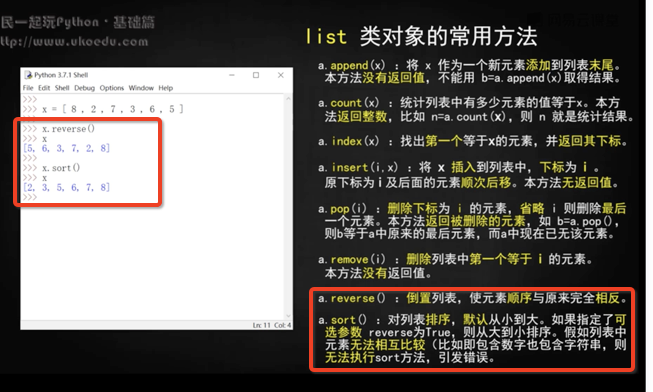
## 轉置或倒序
>注:如果要顯示轉置倒序后的數列,要先寫r.sort(),再寫print(r),不能寫成print(r.sort())!!!!

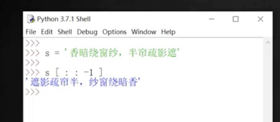
倒序也可以寫成
a[ : : -1] #步長-1,但原來的 a 數列沒有變化。
字符串也可以轉置,注意不要寫成s= ['spring is comming'],而是直接寫s = 'spring is comming'
## 切片
列表可切片,如
`a = [300,400,'hello',66.6,'well']`
字符串也可以切片。字符串本身不能改變元素,但通過切片就可以。
```
s = '春眠不覺曉'
s[2:] #顯示'不覺曉',從下標 2 開始,也就是第三個元素
s[:2] #顯示'春眠',從第一個元素開始一直到下標 2(不包含下標 2)
```
所以可以利用切片的特點,往字符串中間插入或者改變字符串,但其實只是顯示而已,原來的字符串還是不變,除非寫成`s = s[2:]`
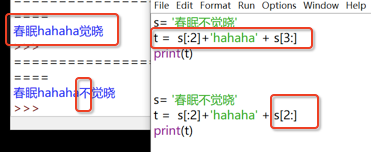

字符串也可以轉置,注意不要寫成s= ['spring is comming'],而是直接寫s = 'spring is comming'

# 7 set、list集合轉換成列表 列表轉換成集合 集合列表轉換 列表集合轉換 刪除重復 去除重復
在前序open類型中:
```
set_words = set(total_words)
total_words = list( set_words)
```
集合用{}表示,不允許重復,可以用多個數據類型,沒有順序,所以沒有下標,如果寫X[2]就會報錯,因為沒有下標。
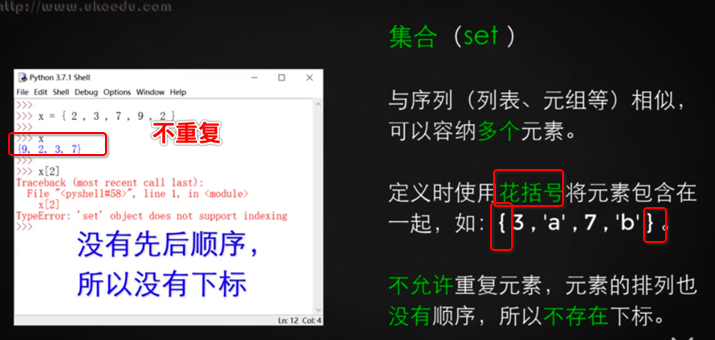
但python中提供了內置函數`set(x)` 以及`list()`函數
```
y = [3,4,5,1,3,1,3,23]
x = set(y) #第一次轉換:用set來得到一個不重復的集合,沒有順序,沒有下標
得出:x = {3,4,5,1,23} #注意是用花括號{}
y = list(x) #第二次轉換:用list將y轉換成列表
得出:y = [3,4,5,1,23] #注意是用[]
```
# 8 字典 第16講
集合、嵌套等。鍵值對。寫法:
`names = {'張三':24, '李四':25, '王五': '三好生' } # 注意不能寫成 '張三 : 24' `
無下標,無順序,所以如果寫`name[2]`,則會出錯。
## 查詢
`names['張三']` 就會顯示24。
鍵不能重復。如果有多個,那么默認以最后出現的鍵值對為準。
## 修改
值可以修改,**但鍵不允許修改**。
`names['張三'] = 30`,即可。
如果要修改鍵,則只能先把原來的鍵值對全部刪除,然后再新增。
## 刪除 再新增
```
names.pop('張三')
names['張六'] = 42
```
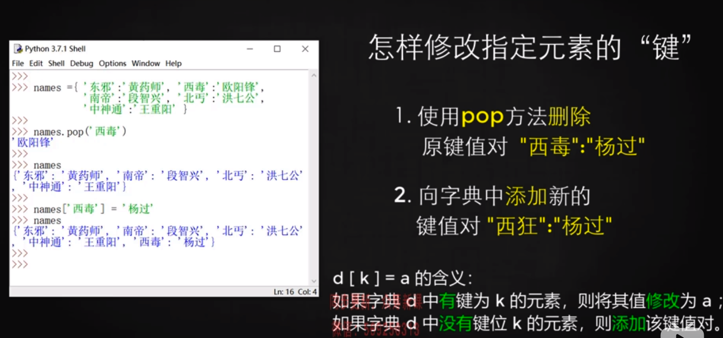
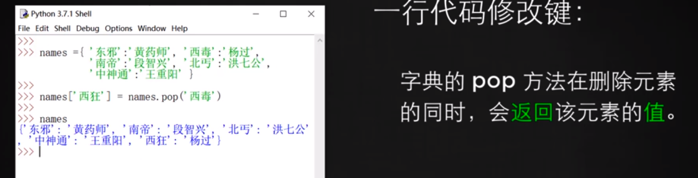
但因為pop時會有一個返回值,所以其實上面代碼可以合并:
`names['張六'] = names.pop('張三')`。
## 循環遍歷字典
用for,但遍歷后顯示的是鍵,不是值
```
names = {'張三': 24, '李四': 25, '王五': 28, '趙六': '劉能'}
for x in names:
print(x)
顯示:
張三
李四
王五
趙六
如果要顯示值,則:
for x in names:
print(names[x])
```

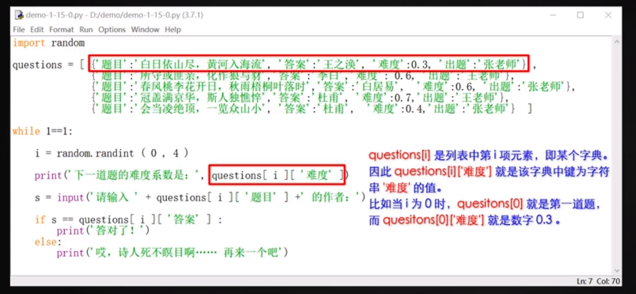
## 多個value的怎么處理:
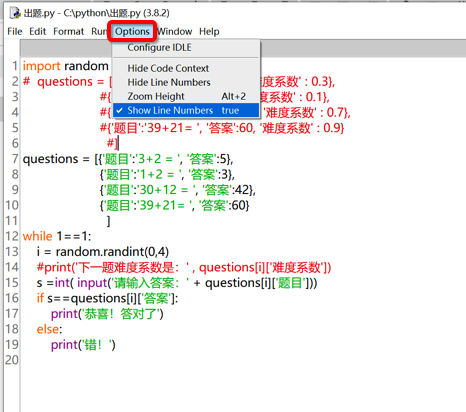
用“列表套字典”的形式:如圖。

```
import random
questions = [{'題目':'3+2 = ', '答案':5, '難度系數' : 0.3},
{'題目':'1+2 = ', '答案':3, '難度系數' : 0.1},
{'題目':'30+12 = ', '答案':42, '難度系數' : 0.7},
{'題目':'39+21= ', '答案':60, '難度系數' : 0.9}
]
while 1==1:
# 做一個死循環一遍一直出題
i = random.randint(0,4)
print('下一題難度系數是:' , questions[i]['難度系數'])
s =int( input('請輸入 ' + questions[i]['題目']+ '的答案:'))
# 注意是用加號連接,不是用逗號
if s==questions[i]['答案']:
print('恭喜答對了!繼續答題')
else:
print('錯!繼續答題')
```
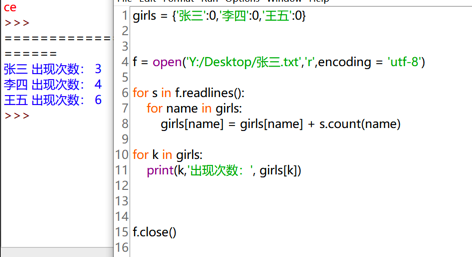
## 統計次數——同##open中的兩個例子。
1、先文章分段
2、統計某段中人物1-12分別出現的次數
3、把值加到原數組中
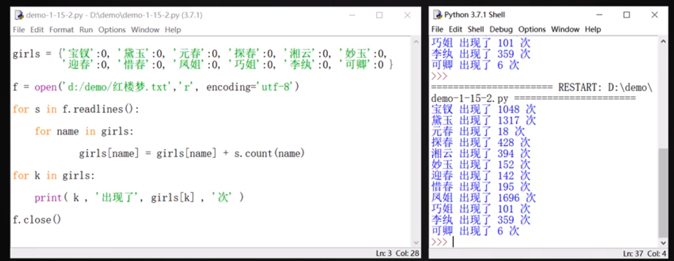
txt:
“張三約李四去打王五,但是王五剛好沒在家,于是張三又出主意說可以改天。張三這個人很不好,經常欺負李四他們。李四也不敢吭聲。
李四看起來老實,其實很不老實,是個名副其實的兩面派。王五真的是二百五。
王五媽媽經常說:“王五啊王五,你真的是個二百五。”
```
girls = {'張三':0,'李四':0,'王五':0}
f = open('Y:/Desktop/張三.txt','r',encoding = 'utf-8')
for s in f.readlines():
for name in girls:
girls[name] = girls[name] + s.count(name)
#詳見open里面的readlines注釋,s變成了一個由字符串構成的列表。
for k in girls:
print(k,'出現次數:', girls[k])
f.close()
```
# 9 str 類
上述各種字符串的操作,也可以用 str 類自帶的方法解決:如
`s.replace('a','b')`
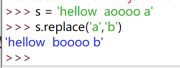
str.find('a'),默認返回的是'a'出現的第一次的**下標**
str.find('a', 6,10) 表示查找從下標 6 開始,找到下標是 10,如果沒找到,返回-1
> 如果想查找到第二個'的' 下標,則可以先用 find 找到第一個'的'下標,在從其下標開始往后找。
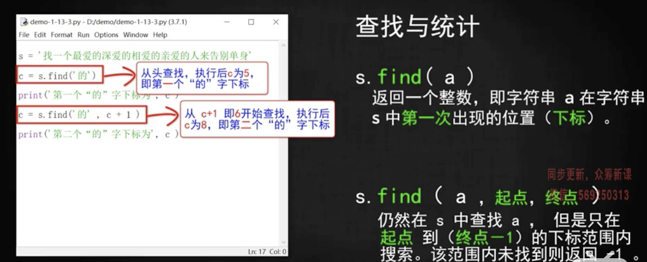
所以可以用一個循環,每次找到下標,就從后一個開始找,就能找到所有的關鍵字了。
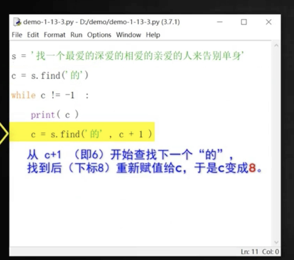
```
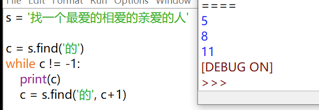
s = '找一個最愛的相愛的親愛的人'
c = s.find('的')
while c != -1:
# 如果找不到,則 c 返回的是-1,所以可以來控制。不要寫成while c < len(s),因為 c 是下標。
print('的出現在:'c)
c = s.find('的', c+1)
```
`s.rfind('xx')` 表示從后開始往前找
`s.strip()` 表示去掉最左右兩頭的空格,也有s.lstrip和s.rstrip就是去掉左邊或者右邊的空格
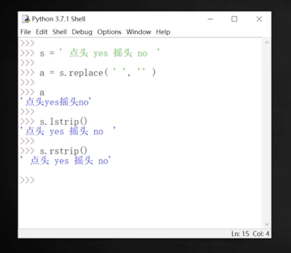
`s.replace(' ', '')` 表示去掉字符串里面的空格,但不改變字符串,如果要改變,則要寫成`s = s.replace(' ', '')`
還有其他方法
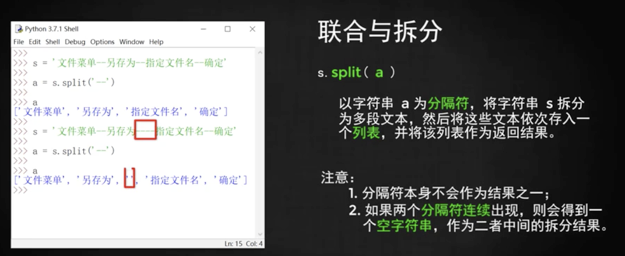
`s.split()` 分割
分割完就變成了列表的形式
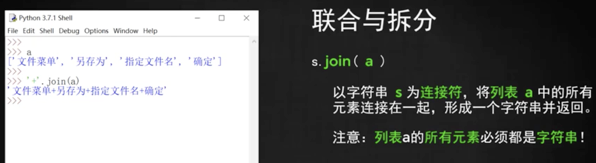
`'$'.join()` 拼接
意思是用$拼接兩個字符串,如果只想接起來,則可以用空字符串拼接
如果要用+加號拼接,則可以直接寫`'+'.join(a)`,這樣的寫法意思是,python 會自動識別'',或者[],或者()元組,將這三種都視為對象,所以可以直接`[20,30,33,20].count(20)`調用這種方法,只不過不便于閱讀。
# 10 元組
`a = ('mm', 22, 'hello')`
與列表類似,只不過用圓括號標識,可以用不同類型的數據,但也同字符串一樣不允許修改。
# 11 模塊
## 如何引用模塊
`import math`即可。可以簡寫`import math as m`
即可,后續就不用寫math.sin(3),可以直接寫m.sin(3) ,但如果后面又重新定義了m=7,則無法引用m.sin(3),也無法引用math.sin(3)了。
也可以寫`from math import *` 但不推薦。

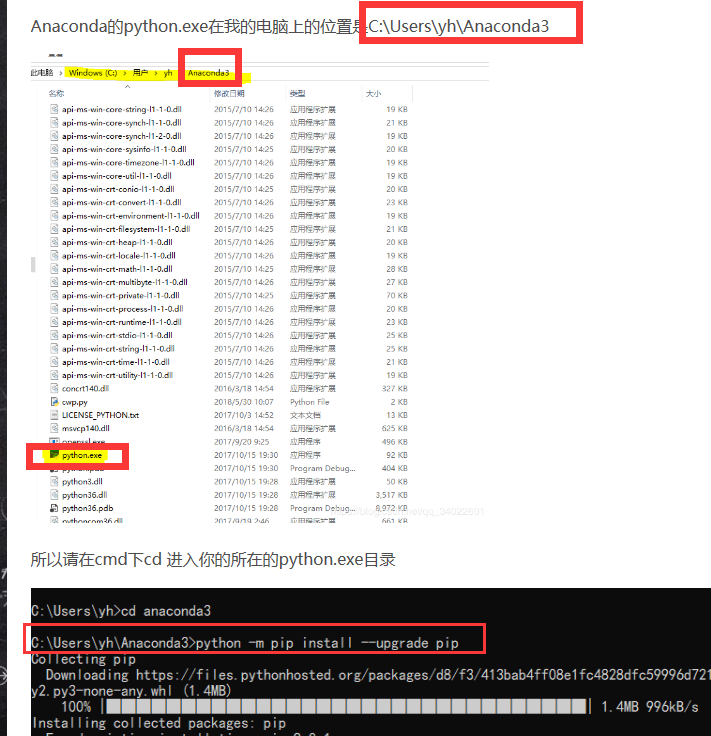
## 模塊無法安裝
可用cmd命令安裝,如果需要更新pip,則可以用cmd 的cd命令找到python.exe文件夾,然后在upgrade。
## 自定義函數 def
比如數字轉換中文。這個函數不需要在函數里面寫for循環。
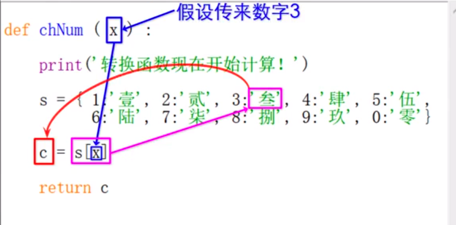
如果自定義函數無返回值,則最好也寫一下return,只不過return后面不需要再寫東西。
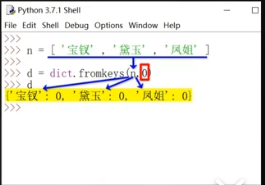
## 列表轉字典 字典轉列表
python中有一個字典類dict類。dict.fromkeys(列表, 默認值) 有兩個參數。比如:
```
n = ['張三','李四','王五','趙六']
d = dict.fromkeys(n,55)
得出:
d = {'張三':55,'李四':55,'王五':55,'趙六':55}
```
dic.fromke

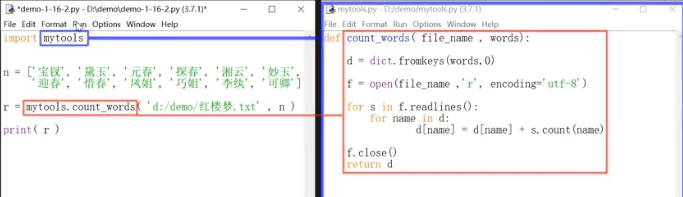
可以將所有def自定義的函數全部存放在一個類似mytools.py的文件中。下次只需要確保要調用的mytools.py與要輸入的文件在同一個文件夾下, 就可以直接import mytools即可。調用時:`r = mytools.count('d:/desktop/張三.txt',n)`
即可。
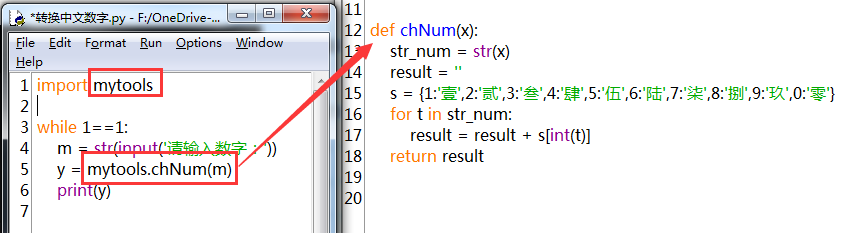
## 數字轉中文大小寫
`def chNum(x):`
如果是532,可將各個位數識別出來,也可以直接‘伍叁柒’
## 安裝第三方庫 第17講
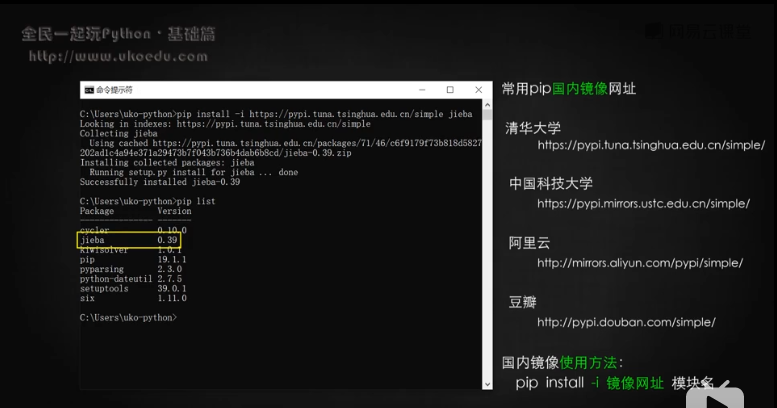
用系統自帶的pip命令行。不是在idle窗口中,而是在cmd命令行中輸入pip list。
命令行輸入pip提示非外部或內部指令:解決辦法:https://jingyan.baidu.com/article/ca41422f8db0f05eae99ed84.html
由于org是國外網站,如果無法安裝,可在國內的網站安裝,輸入pip install -i +網址 +插件名結巴
`pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jieba`

## 炒股模塊

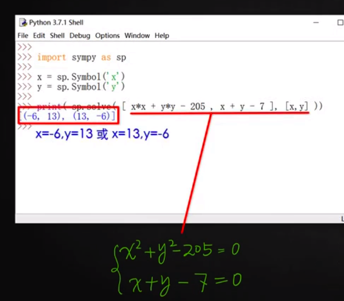
## 解方程
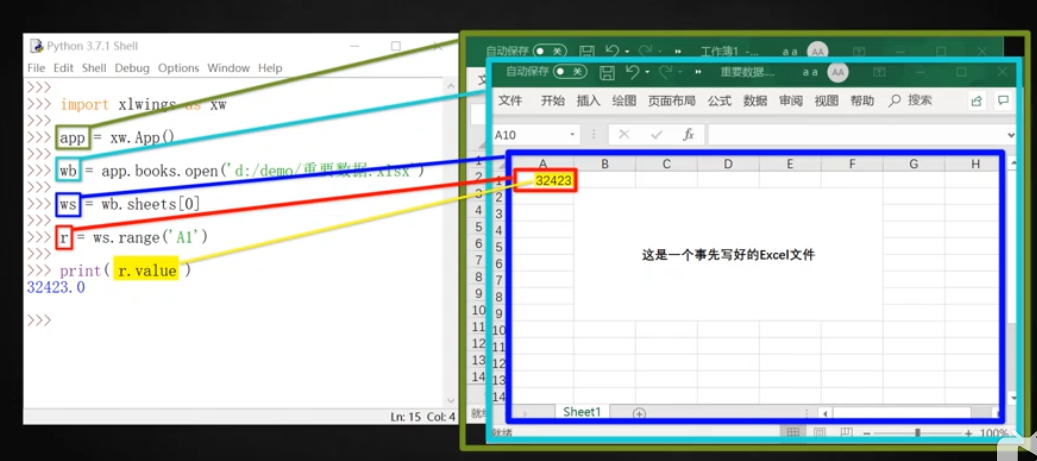
## excel模塊

```
import xlwings as xw
excel = xw.App() # 一定要先創建excel 的app才可以有下一步
excel.quit() # 用來退出excel程序。如果是關閉excel文件的,一般不用這個,用close()
wb = excel.books.open('C:/Users/zyt/Desktop/22222.xlsx') # 接下來就可以用wb來指定打開某個excel文件了
wb=excel.books.add() # 先add完再用save方法保存,不能直接在add括號中寫路徑,會出錯
wb.save('C:/Users/zyt/Desktop/bbbb.xlsx') # 可以把打開的文件另存
wb.close() # 關閉excel文件
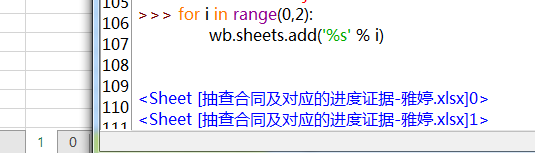
wb.sheets.add() # 增加一個sheet,可以括號里面加sheet的名字,可以用一個循環添加多個sheet,名字可以用占位符表示,如下圖
wt = wb.sheets['第一張sheet'] # 可以寫sheets[0],或者直接寫sheet的名字。注意點后面是sheets類,而不是sheet類 不要寫錯
wt.name='hhh' # 改sheet名字
wt.clear() # 清空sheet內容,包括格式
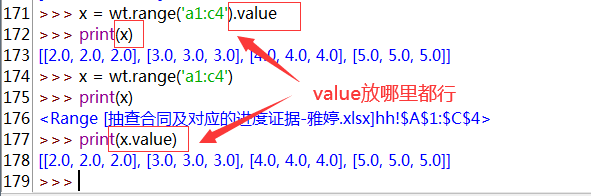
wt.range() # 其余的range對象跟vba中差不多功能
wt.range('a1').color = 65533 #設置單元格格式黃色,不能寫成rgb(253,255,0)
```
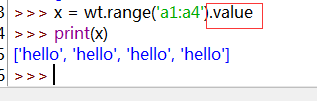
也可以把range賦值給一個變量x,就自動生成一個列表對象。
## python調用excel中的vba
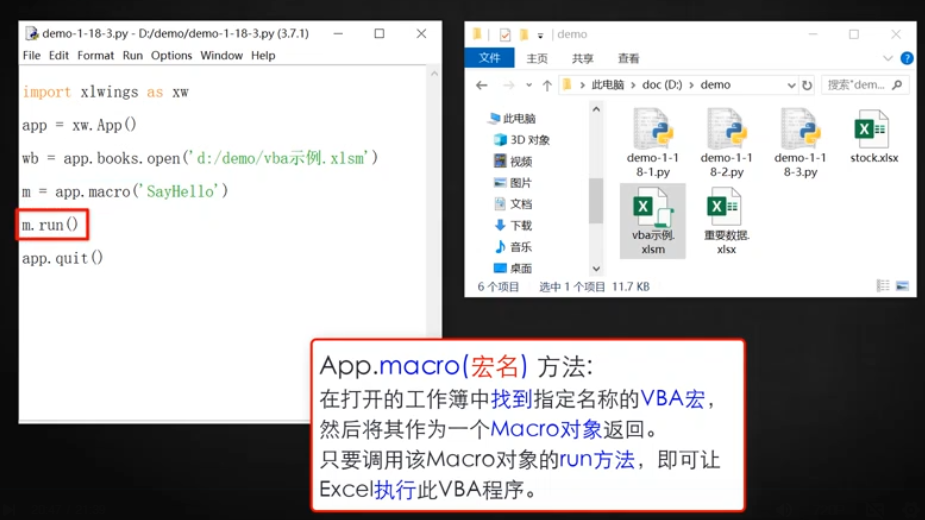
創建對象m,
```
import xlwings as xw
app = xw.App()
wb = app.boos.open('C:/')
m = app.macro('VBA的名字') # 用macro方法,但這個方法是app.macro,不是wb.macro
m.run()
```
## os 第20講
```
import os
x = os.listdir('c:/users/zyt/desktop') # 用listdir屬性可以得到某個文件夾下所有文件的名字列表。
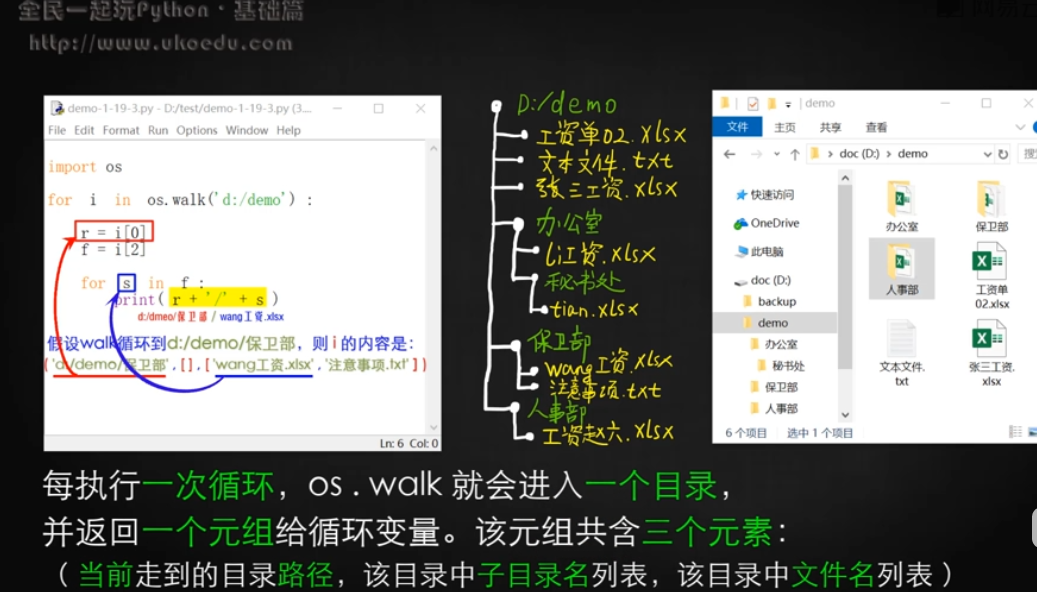
但listdir只返回第一層,如果要返回第二層 用walk方法,一般放for里面
for i in os.walk('c:/users/zyt/desktop')
```
# 爬蟲
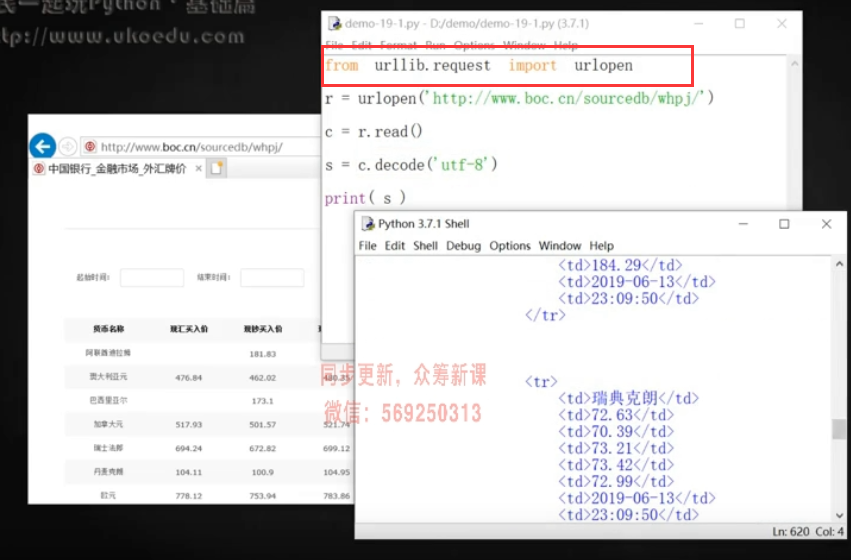
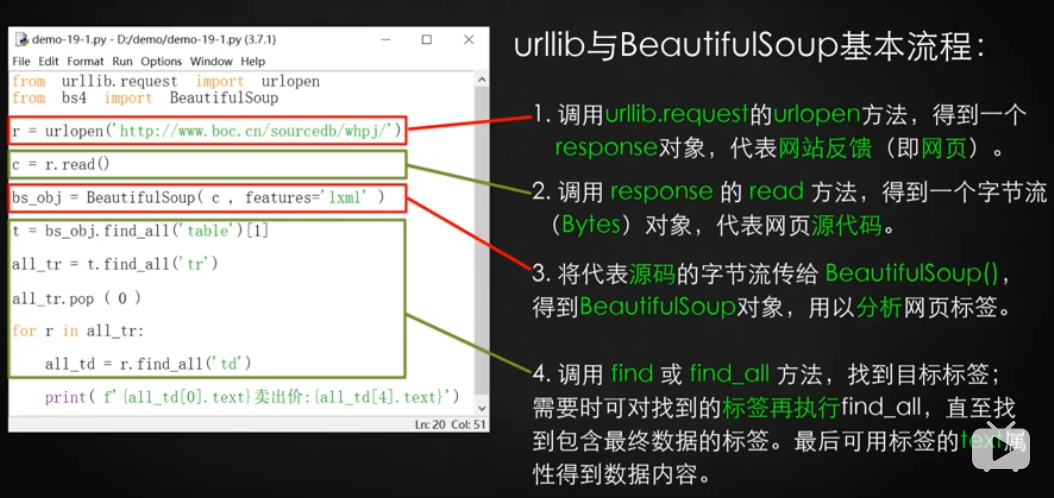
模塊 urllib.request 模塊中的urlopen功能
`from urllib.request import trlopent` 即可。也可以寫import urllib.request
再用一個bs4 外掛中的 BeautifulSoup功能。
```
from urllib.request import urlopen
from bs4 import BeautifulSoup
r = urlopen('http://192.168.168.231:8080/WebReport/ReportServer?reportlet=PM%2FXMSZ%2FAssessmentReportQuery.cpt')
c = r.read()
#s = c.decode('gbk') ##在網頁中點擊F12,查找“charset”就可以得到該網頁的編碼方式,集團這個網站是gbk編碼
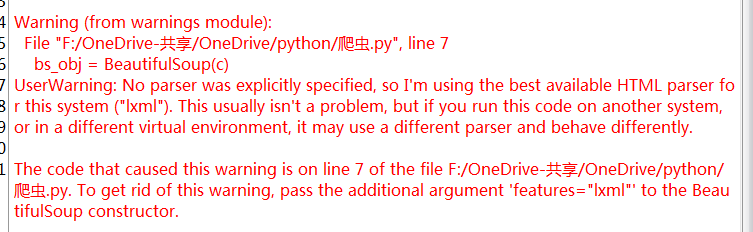
bs_obj = BeautifulSoup(c, features = 'lxml')
# 有這一步以后暫時不需要上面的decode轉換了。但是會提示。'UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("lxml"). '錯誤,如下圖。只要加入 feature = 'lxml'即可
```
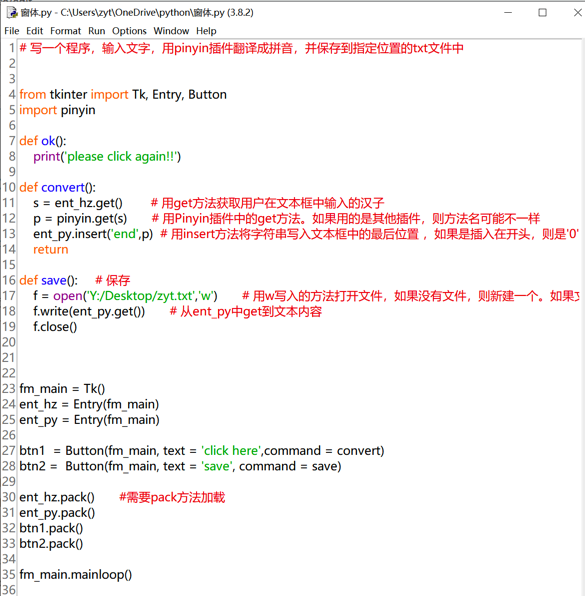
# 加載窗體
## 加載 fomr、單行文本框、按鈕
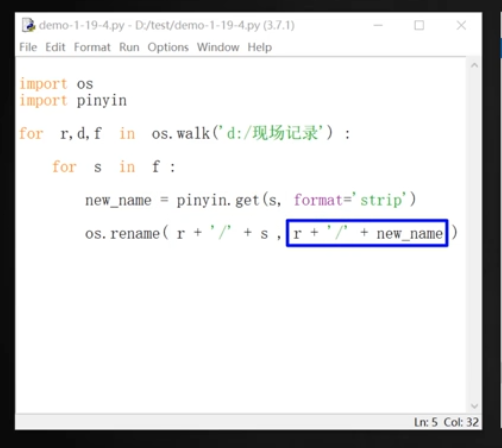
在輸入漢字時點擊按鈕,轉化成拼音。這里要用到pinyin這個插件。詳見“窗體.py”。
```
from tkinter import Tk
, Entry, Button # Entry是用來插入單行文本的框,Button是按鈕
import pinyin
fm_main = Tk()
def ok():
print('hellohhhhhh')
def convert():
s = ent_hanzi.get() # 獲取用戶在文本框中輸入的字符串
p = pinyin.get(s) # 用插件中的get方法,及可轉換成拼音。如果用的是其他插件,估計方法名稱不同。
ent_pinyin.insert('end', p) # 直接用文本框后面加個點,接insert方法,即可插入,兩個參數,一個是指定插入的位置,如果是end就是光標后面,如果是‘0’,就是在最開始插入;第二個參數是插入的內容,也就是上一步中翻譯好的拼音。
return
ent_hanzi = Entry(fm_main) # 創建單行輸入框對象,命名為ent,調用Entry方法,括號內指定要顯示在哪個form中,
ent_pinyin = Entry(fm_main)
btn = Button(fm_main, text = 'click here', command = convert) # 點擊可執行自定義函數,用command直接跟函數名即可,無需引號。
ent_hanzi.pack() # 創建完以后,還需要對象的pack方法,才能加載顯示
ent_pinyin.pack()
btn.pack()
fm_main.mainloop() # 這個是默認添加的
```
> 自定義函數必須寫在調用的語句前,比如command前,如果寫在command后面,則出錯。
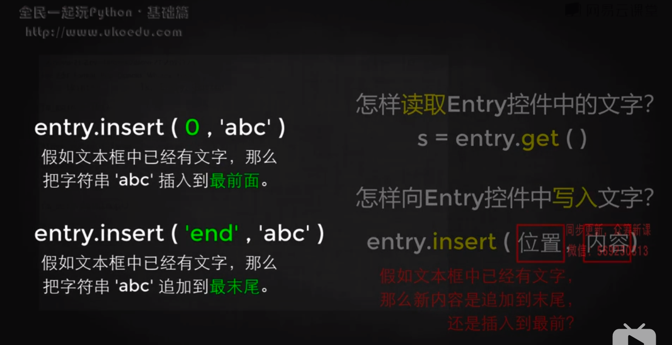
## 讀取文本框內容、將內容寫入文本框中
一些方法
[https://www.cnblogs.com/hackpig/p/8196480.html](https://www.cnblogs.com/hackpig/p/8196480.html)
讀取:get即可。初學者容易犯的錯誤:不需要去管使用者一輸入數據就去讀取文本框中的內容,而只需要當他們按下button按鈕以后再去讀取。
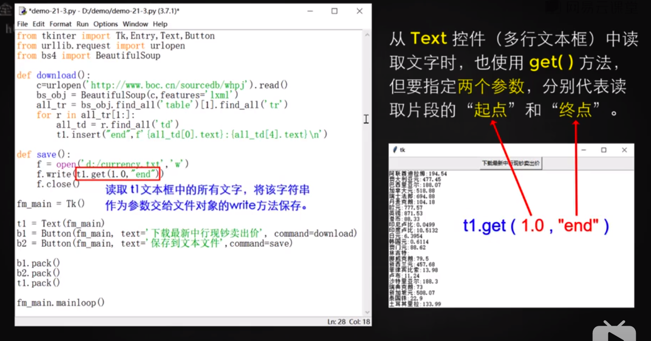
## text插件
讀取網絡股市信息并顯示在text控件中。
```
fm_main = Tk()
t1 = Text(fm_main)
f = open('Y:/user/desktop/zyt.txt')
f.write( t1.get(1.0,'end' ) ) #text 的get方法可以指定從哪個字符開始復制,1.0 的意思就是開始,end表示讀到最后
```