
## 17\. Unicode - 簡要介紹(高級)
> 原文: [http://exploringjs.com/impatient-js/ch_unicode.html](http://exploringjs.com/impatient-js/ch_unicode.html)
>
> 貢獻者:[飛龍](https://github.com/wizardforcel)
Unicode 是在世界上大多數書寫系統中表示和管理文本的標準。幾乎所有使用文本的現代軟件都支持 Unicode。該標準由 Unicode Consortium 維護。該標準的新版本每年發布(帶有新的 Emoji 等)。 Unicode 1 于 1991 年發布。
### 17.1。代碼點與代碼單元
兩個概念對于理解 Unicode 至關重要:
* 代碼點:是表示 Unicode 字符的數字。
* 代碼單元:是具有固定大小的數據片段。一個或多個代碼單元編碼單個代碼點。代碼單元的大小取決于編碼格式。最流行的格式 UTF-8 具有 8 位代碼單元。
#### 17.1.1。代碼點
Unicode 的第一個版本有 16 位代碼點。從那時起,字符數量大大增加,代碼點的大小擴展到 21 位。這 21 個位分為 17 個平面,每個平面 16 位:
* 平面 0:**基本多文種平面(BMP)**,0x0000-0xFFFF
* 這是最常用的平面。粗略地說,它包含原始的 Unicode。
* 平面 1:多文種補充平面(SMP),0x10000-0x1FFFF
* 平面 2:表意文字補充平面(SIP),0x20000-0x2FFFF
* 平面 3-13:未分配
* 平面 14:特別用途補充平面(SSP),0xE0000-0xEFFFF
* 平面 15-16:私人用途補充區域(S PUA A / B),0x0F0000-0x10FFFF
平面 1-16 稱為輔助平面或**星形平面**。
讓我們檢查幾個字符的代碼點:
```js
> 'A'.codePointAt(0).toString(16)
'41'
> 'ü'.codePointAt(0).toString(16)
'fc'
> 'π'.codePointAt(0).toString(16)
'3c0'
> '\u{1f642}'.codePointAt(0).toString(16)
'1f642'
```
代碼點的十六進制數告訴我們前三個字符位于平面 0(16 位內)中,而表情符號位于平面 1 中。
#### 17.1.2。代碼單元的編碼格式:UTF-32,UTF-16,UTF-8
讓我們介紹將代碼點編碼為代碼單元的三種方法。
##### 17.1.2.1。 UTF-32(Unicode 轉換格式 32)
UTF-32 使用 32 位來存儲代碼單元,從而每個代碼點產生一個代碼單元。這種格式是唯一具有*固定長度編碼*的格式(所有其他格式使用不同數量的代碼單元來編碼單個代碼點)。
##### 17.1.2.2。 UTF-16(Unicode 轉換格式 16)
UTF-16 使用 16 位代碼單元。它編碼代碼點如下:
* BMP(Unicode 的前 16 位):以單個代碼單元存儲。
* 星形平面:從 Unicode 的 0x110000 字符數減去 BMP 的 0x10000 個字符數后,保留 0x100000 個字符(20 位)。這些存儲在 BMP 中未占用的“空隙”中:
* 最高有效 10 位(*前導*):0xD800-0xDBFF
* 最低有效 10 位(*尾隨*):0xDC00-0xDFFF
因此,通過查看 UTF-16 代碼單元,我們可以判斷它是否是 BMP 字符,星體平面字符的前半部分(前導)或星形平面字符的后半部分(尾隨)。
##### 17.1.2.3。 UTF-8(Unicode 轉換格式 8)
UTF-8 具有 8 位代碼單元。它使用 1-4 個代碼單元來編碼代碼點:
| 代碼點 | 代碼單元 |
| --- | --- |
| 0000-007F | 0xxxxxxx(7 位) |
| 0080-07FF | 110xxxxx,10xxxxxx(5 + 6 位) |
| 0800-FFFF | 1110xxxx,10xxxxxx,10xxxxxx(4 + 6 + 6 位) |
| 10000-1FFFFF | 11110xxx,10xxxxxx,10xxxxxx,10xxxxxx(3 + 6 + 6 + 6 位) |
筆記:
* 每個代碼單元的位前綴告訴我們:
* 它是一系列代碼單元中的第一個嗎?如果是,將跟隨多少代碼單元?
* 它是一系列代碼單元中的第二個還是后面的?
* 0000-007F 范圍內的字符映射與 ASCII 相同,這產生了與舊軟件的向后兼容性。
### 17.2。 Web 開發:UTF-16 和 UTF-8
對于 Web 開發,兩種 Unicode 編碼格式是相關的:UTF-16 和 UTF-8。
#### 17.2.1。內部源代碼:UTF-16
ECMAScript 規范在內部將源代碼表示為 UTF-16。
#### 17.2.2。字符串:UTF-16
JavaScript 字符串中的字符是 UTF-16 代碼單元:
```js
> const smiley = '\u{1f642}';
> smiley.length
2
> smiley === '\uD83D\uDE42' // code units
true
> smiley === '\u{1F642}' // code point
true
```
有關 Unicode 和字符串的更多信息,請參閱[字符串的文本原子](ch_strings.html#atoms-of-text)章節。
#### 17.2.3。文件中的源代碼:UTF-8
當 JavaScript 存儲在`.html`和`.js`文件中時,編碼幾乎總是 UTF-8:
```html
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
···
```
### 17.3。字形簇 - 真正的字符
一旦你考慮了世界上許多的書寫系統,字符的概念就變得非常復雜。
一方面,代碼點可以說代表 Unicode“字符”。
另一方面,存在*字形簇*。字形簇最接近于屏幕或紙張上顯示的符號。它被定義為“可水平分段的文本單元”。編碼字形簇需要一個或多個代碼點。
例如,一個家族的一個表情符號由 7 個代碼點組成 - 其中 4 個是字形本身,它們由不可見的代碼點連接起來:

另一個例子是標志表情符號:
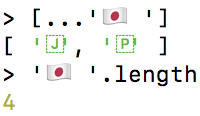
 **閱讀:關于字形簇**的更多信息
有關更多信息,請參閱 Manish Goregaokar 的[“讓我們停止將意義歸于代碼點”](https://manishearth.github.io/blog/2017/01/14/stop-ascribing-meaning-to-unicode-code-points/)。
 **測驗**
參見[測驗應用程序](ch_quizzes-exercises.html#quizzes)。
- I.背景
- 1.關于本書(ES2019 版)
- 2.常見問題:本書
- 3. JavaScript 的歷史和演變
- 4.常見問題:JavaScript
- II.第一步
- 5.概覽
- 6.語法
- 7.在控制臺上打印信息(console.*)
- 8.斷言 API
- 9.測驗和練習入門
- III.變量和值
- 10.變量和賦值
- 11.值
- 12.運算符
- IV.原始值
- 13.非值undefined和null
- 14.布爾值
- 15.數字
- 16. Math
- 17. Unicode - 簡要介紹(高級)
- 18.字符串
- 19.使用模板字面值和標記模板
- 20.符號
- V.控制流和數據流
- 21.控制流語句
- 22.異常處理
- 23.可調用值
- VI.模塊化
- 24.模塊
- 25.單個對象
- 26.原型鏈和類
- 七.集合
- 27.同步迭代
- 28.數組(Array)
- 29.類型化數組:處理二進制數據(高級)
- 30.映射(Map)
- 31. WeakMaps(WeakMap)
- 32.集(Set)
- 33. WeakSets(WeakSet)
- 34.解構
- 35.同步生成器(高級)
- 八.異步
- 36. JavaScript 中的異步編程
- 37.異步編程的 Promise
- 38.異步函數
- IX.更多標準庫
- 39.正則表達式(RegExp)
- 40.日期(Date)
- 41.創建和解析 JSON(JSON)
- 42.其余章節在哪里?