# Kudu Schema Design ( 模式設計 )
原文鏈接 : [http://kudu.apache.org/docs/schema_design.html](http://kudu.apache.org/docs/schema_design.html)
譯文鏈接 : [http://cwiki.apachecn.org/pages/viewpage.action?pageId=10813632](http://cwiki.apachecn.org/pages/viewpage.action?pageId=10813632)
貢獻者 : [小瑤](/display/~chenyao) [ApacheCN](/display/~apachecn) [Apache中文網](/display/~apachechina)
## Apache Kudu Schema Design ( Apache Kudu 模式設計 )
**Kudu** 表具有與傳統 **RDBMS** 中的表類似的結構化數據模型。模式設計對于實現 **Kudu** 的最佳性能和運行穩定性至關重要。每個工作負載都是獨一無二的,沒有一個最合適每個表的單一模式設計。本文檔概述了 **Kudu** 的有效模式設計理念,特別注意與傳統 **RDBMS** 模式所采用的方法不同的地方。
在高層次上,創建 **Kudu** 表有三個問題:[列設計](/pages/viewpage.action?pageId=10813632),[主鍵設計](/pages/viewpage.action?pageId=10813632)和[分區設計](/pages/viewpage.action?pageId=10813632)。其中只有分區對于熟悉傳統的非分布式關系數據庫的人來說將是一個新的概念。最后一節討論 [改變現有表的模式](/pages/viewpage.action?pageId=10813632) ,以及關于模式設計的 [已知限制](/pages/viewpage.action?pageId=10813632) 。
## The Perfect Schema ( 完美的模式 )
完美的模式將完成以下工作:
* 數據將以這樣的方式進行分發,即讀取和寫入在 **tablet servers** 上均勻分布。這受到分區的影響。
* **Tablets** 將以均勻,可預測的速度增長, **tablets** 的負載將隨著時間的推移而保持穩定。這最受影響分區。
* 掃描將讀取完成查詢所需的最少數據量。這主要受到主鍵設計的影響,但分區也通過分區修剪來起作用。
完美的模式取決于數據的特性,需要做的事情以及集群的拓撲。模式設計是您最大限度地發揮 **Kudu** 集群性能的最重要的一件事。
## Column Design ( 列設計 )
**Kudu** 表由一個列或多個列組成,每個列都有一個定義的類型。不屬于主鍵的列可能為空。支持的列類型包括:
* boolean
* 8-bit signed integer
* 16-bit signed integer
* 32-bit signed integer
* 64-bit signed integer
* unixtime_micros (從 UNIX 時代起,64 位微秒)
* single-precision (32-bit) IEEE-754 floating-point number ( 單精度,32位,IEEE-754 浮點數 )
* double-precision (64-bit) IEEE-754 floating-point number ( 雙精度,64位,IEEE-754 浮點數 )
* UTF-8 encoded string (up to 64KB uncompressed) ( UTF-8 編碼字符串(高達 64KB 未壓縮)?)
* binary (up to 64KB uncompressed) ( 二進制(高達 64KB 未壓縮) )
**Kudu** 利用強類型的列和柱狀磁盤存儲格式來提供高效的編碼和序列化。為了充分利用這些功能,列應該被指定為適當的類型,而不是使用字符串或二進制列來模擬 '**schemaless**' 表,否則可能會進行結構化。除了編碼之外,Kudu 允許按照每列進行壓縮。
### Column Encoding ( 列編碼 )
可以根據列的類型,使用編碼創建 **Kudu** 表中的每個列。
表 1\. **Encoding type** ( 編碼類型?)
| Column Type ( 列類型 ) | Encoding ( 編碼 ) | Default ( 默認 ) |
| --- | --- | --- |
| int8, int16, int32 | plain, bitshuffle, run length | bitshuffle |
| int64, unixtime_micros | ?plain, bitshuffle, run length | bitshuffle |
| float, double | plain, bitshuffle | bitshuffle |
| bool | plain, run length | run length |
| string, binary | plain, prefix, dictionary | dictionary |
**plain Encoding ( 普通編碼 )**
數據以其自然格式存儲。例如,**int32 values** 作為固定大小的 **32** 位 **little-endian integers** 存儲。
**Bitshuffle Encoding**
重新排列一組值以存儲每個值的最高有效位,其次是每個值的第二個最高有效位,依此類推。最后,結果是 **LZ4** 壓縮。 **Bitshuffle** 編碼對于具有許多重復值的列或按主鍵排序時少量更改的列是不錯的選擇。 **bithuffle** 項目對性能和用例有很好的概述。
**Run Length Encoding ( 運行長度編碼 )**
通過僅存儲值和計數,在列中壓縮運行(連續重復值)。當按主鍵排序時,運行長度編碼對于具有許多連續重復值的列是有效的。
**Dictionary Encoding ( 字典編碼 )**
構建了唯一值的字典,并且每個列值都被編碼為字典中的相應索引。字典編碼對于基數較低的列是有效的。如果給定行集的列值由于唯一值的數量太高而無法壓縮,則 **Kudu** 將透明地回退到該行集的純編碼。這在 **flush** 過程中進行評估。
**Prefix Encoding ( 前綴編碼 )**
公共前綴在連續列值中進行壓縮。前綴編碼對于共享公共前綴的值或主鍵的第一列可能有效,因為行按 **tablet** 內的主鍵排序。
### Column Compression ( 列壓縮 )
**Kudu** 允許使用 **LZ4** , **Snappy** 或 **zlib** 壓縮編解碼器進行每列壓縮。默認情況下,列未壓縮存儲。如果減少存儲空間比原始掃描性能更重要,請考慮使用壓縮。
## Primary Key Design ( 主鍵設計 )
每個 **Kudu** 表必須聲明一個主鍵索引由一個或多個列組成。主鍵列必須不可為空,并且可能不是布爾值或浮點型。在表創建期間設置后,主鍵中的列集合可能不會更改。像 **RDBMS** 主鍵一樣,**Kudu** 主鍵強制執行唯一性約束;嘗試插入與現有行具有相同主鍵值的行將導致重復的鍵錯誤。
與 **RDBMS** 不同,**Kudu** 不提供自動遞增列功能,因此應用程序必須始終在插入期間提供完整的主鍵。行刪除和更新操作還必須指定要更改的行的完整主鍵; ?**Kudu** 本身不支持范圍刪除或更新。在插入行之后,列的主鍵值可能不會被更新;但是,可以刪除該行并重新插入更新的值。
### Primary Key Index ( 主鍵索引 )
與許多傳統關系數據庫一樣,**Kudu** 的主鍵是 **clustered index** ( 聚集索引?)。 **tablet** 中的所有行都保持主鍵排序順序。在主鍵上指定相等或范圍約束的 **Kudu** 掃描將自動跳過不能滿足謂詞的行。這允許通過在主鍵列上指定相等約束來有效地找到各行。
注意
主鍵索引優化適用于單個 **tablet** 上的掃描。有關掃描如何使用謂詞跳過整個 tablet 的詳細信息,請參閱 [分區修剪](/pages/viewpage.action?pageId=10813632) 部分。
## Partitioning ( 分區 )
為了提供可擴展性,**Kudu** 表被劃分為稱為 **tablets** 的單元,并分布在許多 **tablet servers** 上。行總是屬于單個 **tablet** 。將行分配給 **tablet** 的方法由在表創建期間設置的表的分區決定。
選擇分區策略需要了解數據模型和表的預期工作負載。對于寫入繁重的工作負載,重要的是設計分區,以使寫入分散在 **tablet** 上,以避免單個 **tablet** 的超載。對于涉及許多短掃描的工作負載,如果所有掃描的數據位于同一個 **tablet** 中,那么遠程服務器的開銷占主導地位,可以提高性能。了解這些基本權衡是設計有效的分區模式的核心。
重要
沒有默認分區
**Kudu** 在創建表時不提供默認分區策略。建議預期具有較大讀寫工作負荷的新表至少與 **tablet servers** 一樣多的 **tablets** 。
**Kudu** 提供了兩種類型的分區:[**range partitioning** ( 范圍分區?)](/pages/viewpage.action?pageId=10813632)?和 [**hash partitioning** ( 哈希分區?)](/pages/viewpage.action?pageId=10813632)。表也可能具有 [多級分區](/pages/viewpage.action?pageId=10813632) ,其結合范圍和哈希分區,或多個散列分區實例。
### Range Partitioning ( 范圍分區 )
范圍分區使用完全有序的分區鍵分配行。每個分區分配了范圍分區密鑰空間的連續段。密鑰必須由主鍵列的子集組成。如果范圍分區列與主鍵列匹配,則行的范圍分區鍵將等于其主鍵。在沒有哈希分區的范圍分區表中,每個范圍分區將對應于一個 **tablet** 。
在創建表時,將初始的范圍分區集合指定為一組分區邊界和拆分行。對于每個綁定,將在表中創建一個范圍分區。每個分割將兩個范圍分割。如果沒有指定分區界限,則表將默認為覆蓋整個密鑰空間的單個分區(下面和下面無界限)。范圍分區必須始終不重疊,拆分行必須在范圍分區內。
重要
請參閱 [范圍分區示例](/pages/viewpage.action?pageId=10813632) ,以進一步討論范圍分區。
#### Range Partition Management ( 范圍分區管理?)
**Kudu** 允許在運行時從表中動態添加和刪除范圍分區,而不影響其他分區的可用性。刪除分區將刪除屬于分區的 tablet 以及其中包含的數據。隨后插入到丟棄的分區將失敗。可以添加新分區,但不能與任何現有的分區分區重疊。 **Kudu** 允許在單個事務性更改表操作中刪除并添加任意數量的范圍分區。
動態添加和刪除范圍分區對于時間序列使用情況尤其有用。隨著時間的推移,可以添加范圍分區以覆蓋即將到來的時間范圍。例如,存儲事件日志的表可以在每月開始之前添加一個月份的分區,以便保存即將到來的事件。必要時可以刪除舊范圍分區,以便有效地刪除歷史數據。
#### Hash Partitioning ( 哈希分區 )
哈希分區通過哈希值將行分配到許多 **buckets** ( 存儲桶?)之一。在 **single-level hash partitioned tables** ( 單級散列分區表?)中,每個 **bucket ?**( 存儲桶?) 將對應于一個 tablet 。在創建表時設置桶數。通常,主鍵列用作散列的列,但與范圍分區一樣,可以使用主鍵列的任何子集。
哈希分區是一種有效的策略,當不需要對表進行有序訪問時。哈希分區對于在 tablet 之間隨機散布這些功能是有效的,這有助于減輕熱點和 **tablet** 大小不均勻。
注意
有關哈希分區的進一步討論,請參閱 [哈希分區示例](/pages/viewpage.action?pageId=10813632) 。
#### Multilevel Partitioning ( 多級分區 )
**Kudu** 允許一個表在單個表上組合多級分區。零個或多個哈希分區級別可以與可選的范圍分區級別組合。除了單個分區類型的約束之外,多級分區的唯一附加約束是多個級別的哈希分區不能對相同的列進行哈希。
當正確使用時,多級分區可以保留各個分區類型的優點,同時減少每個分區的缺點。多級分區表中的 **tablet** 總數是每個級別中分區數量的乘積。
注意
請參閱 [哈希和范圍分區示例](/pages/viewpage.action?pageId=10813632) 以及 [哈希和哈希分區示例](/pages/viewpage.action?pageId=10813632) ,以進一步討論多級分區。
#### Partition Pruning ( 分區修剪 )
當可以確定分區可以被掃描謂詞完全過濾時,**Kudu** 掃描將自動跳過掃描整個分區。 要修剪哈希分區,掃描必須在每個散列列上包含相等謂詞。 要修剪范圍分區,掃描必須在范圍分區列上包含相等或范圍謂詞。 對多級分區表的掃描可以獨立地利用任何級別的分區修剪。
#### Partitioning Examples ( 分區示例 )
為了說明與為表設計分區策略相關的因素和權衡,我們將通過一些不同的分區方案。 考慮存儲機器度量數據的下表模式(為了清楚起見,使用 **SQL** 語法和日期格式的時間戳):
```
CREATE TABLE metrics (
host STRING NOT NULL,
metric STRING NOT NULL,
time INT64 NOT NULL,
value DOUBLE NOT NULL,
PRIMARY KEY (host, metric, time),
);
```
##### Range Partitioning Example ( 范圍分區示例 )
分割度量表的一種自然方式是在時間列上對范圍進行分區。假設我們想要每年都有一個分區,該表將保存 **2014** 年,**2015** 年和 **2016** 年的數據。表格至少有兩種方式可以被分割:具有無界范圍的分區,也可以是有限范圍的分區。
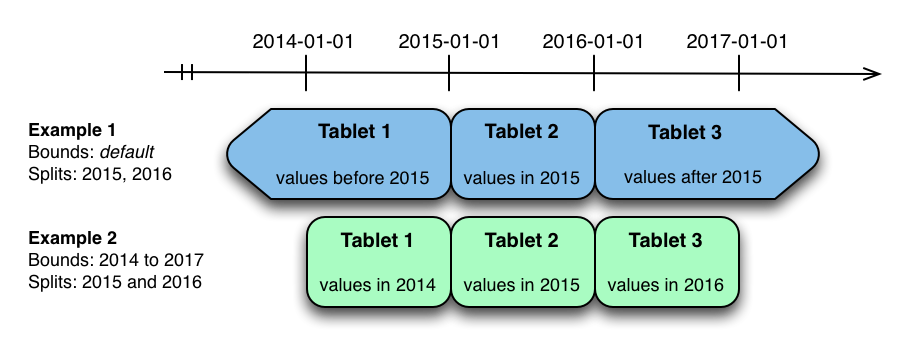
上圖顯示了度量表可以在時間列上進行范圍分區的兩種方式。在第一個示例(藍色)中,使用默認范圍分區邊界,并在 **2015-01-01** 和 **2014** 年 **1** 月分隔。這導致三個 **tablet** : **2015** 年之前的第一個值, **2015** 年的第二個值,以及 2016 年以后的第三個值。第二個例子(綠色)使用了**[(2014-01-01)** ,**(2017-01-01)]**,并分期于 **2015-01-01** 和 **2016-01-01** 。第二個例子可以等價地通過**[(2014-01-01),(2015-01-01)],[(2015-01-01)**,**(2016-01-01)]**和**[(2016-01-01),(2017-01-01)]**,沒有分裂。第一個例子有無界的下限和上限分區,而第二個例子包括邊界。
上述范圍分區示例中的每一個都允許有時限的掃描來修剪掉在掃描時間限制之外的分區。當有很多分區時,這可以大大提高性能。寫作時,兩個例子都有潛在的熱點問題。由于度量趨向于始終在當前時間寫入,大多數寫入將進入單個范圍分區。
第二個例子比第一個例子更靈活,因為它允許未來幾年的范圍分區添加到表中。在第一個示例中,在 **2016-01-01** 之后的時間的所有寫入將落入最后一個分區,因此分區可能最終變得太大,以致于單個 **tablet servers** 無法處理。
##### Hash Partitioning Example ( 哈希分區示例 )
分割 **metrics table** ( 度量表?) 的另一種方法是在 **host** 和 **metric columns** ( 度量列?) 上哈希分區。
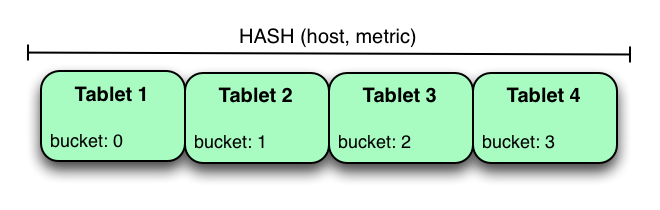
在上面的示例中,**metrics table** 是將 host 和 **metric columns** 上的哈希分區分為四個存儲桶。與前面的范圍分區示例不同,此分區策略將均勻地在表中的所有 **tablets** 上傳播寫入,這有助于總體寫入吞吐量。通過指定相等謂詞,掃描特定的 **host** 和 **metric** 可以利用分區修剪,將掃描的 **tablet** 數量減少到一個。使用純哈希分區策略要小心的一個問題是,隨著越來越多的數據被插入到表中, **tablet** 可以無限期地增長。最終 **tablet** 將變得太大,無法讓個人 **tablet servers** 持有。
注意
雖然這些示例編號為 tablet ,但實際上 **tablet** 只提供 **UUID** 標識符。哈希分區表中的 **tablet** 之間沒有自然排序。
##### Hash and Range Partitioning Example ( 哈希和范圍分區示例 )
以前的示例顯示了 **metrics table** 如何在 **time column** ( 時間列?) 上進行范圍分區,或者在 **host** 和 **metrics column** 上進行哈希分區。這些策略具有相關的實力和弱點:
表 2.?**Partitioning Strategies** ( 分區策略 )
| Strategy ( 策略 ) | Writes ( 寫入 ) | Reads ( 讀取 ) | Tablet Growth ( tablet 增長 ) |
| --- | --- | --- | --- |
| range(time) | ? - 所有寫入到最新分區 | ? - 可以修剪與時間綁定的 **scan** | ? - 可以在未來的時間段添加新的 **tablets** |
| hash(host, metric) | ? - 在 **tablets** 上均勻分布 | ? - 可以修剪對特定 **hosts** 和 **metrics** 的 **scan** | ? - **tablets** 可以增長到很大 |
哈希分區有利于最大限度地提高寫入吞吐量,而范圍分區可避免 tablet 無限增長的問題。這兩種策略都可以利用分區修剪來優化不同場景中的掃描。使用多級分區,可以組合這兩種策略,以獲得兩者的優點,同時最大限度地減少每個策略的缺點。
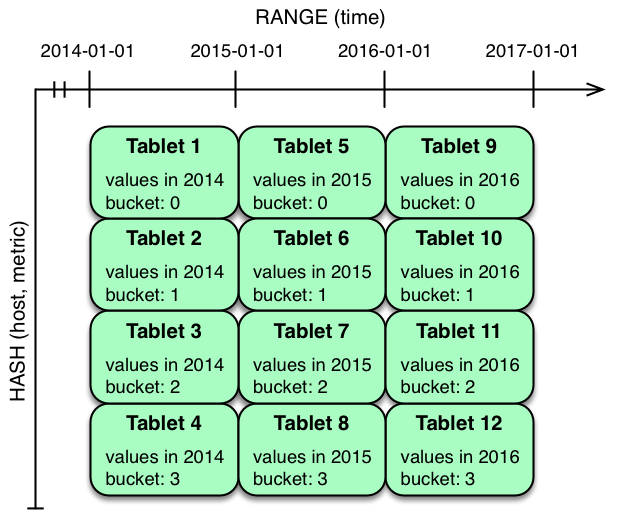
在上面的示例中, **time column** ?上的范圍分區與 **host** 和 **metric columns** 上的哈希分區相結合。這個策略可以被認為具有二維劃分:一個用于哈希級別,一個用于范圍級別。在當前時刻寫入此表將并行化到哈希桶的數量,在 **4** 這種情況下。讀取可以利用時間限制和特定的 **host** 和 **metric** 謂詞來修剪分區。可以添加新的范圍分區,這將導致創建 **4** 個額外的 **tablet** (好像新列已添加到圖表中)。
##### Hash and Hash Partitioning Example ( 哈希和哈希示例?)
**Kudu** 可以在同一個表中支持任意數量的哈希分區級別,只要這些級別沒有共同的 **hashed columns** ( 散列列?) 。
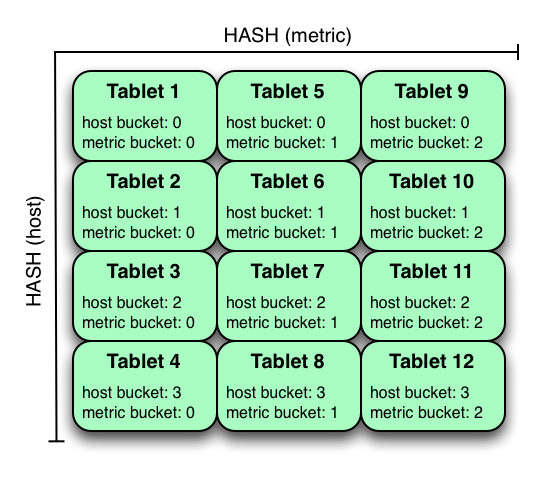
在上面的示例中,表是主機上的哈希分區,分為 **4** 個桶,散列在公制中分區為 **3** 個桶,從而產生12個 **tablet** 。盡管在使用此策略時,所有 **tablets** 中的寫入將趨向于傳播,但是比單獨的 **host** 或 **metric** 的所有值始終屬于單個 **tablet** 時,與多個獨立列的哈希分區相比,它更容易受到熱點查找。掃描可以分別利用 **host** 和 **metric columns** 上的等式謂詞來修剪分區。
多級哈希分區也可以與范圍分區相結合,邏輯上增加了分區的另一個維度。
## Schema Alterations ( 模式變更 )
您可以通過以下方式更改表的模式:
* 重命名表
* 重命名主鍵列
* 重命名,添加或刪除非主鍵列
* 添加和刪除范圍分區
可以在單個事務操作中組合多個更改步驟。
注意
**重命名主鍵列**
**[KUDU-1626](https://issues.apache.org/jira/browse/KUDU-1626)** :**Kudu** 還不支持重命名主鍵列。
## Known Limitations ( 已知限制 )
**Kudu** 目前有一些已知的限制,可能會影響模式設計。
**Number of Columns ( 列數 )**
默認情況下,**Kudu** 不允許創建 **300** 列以上的表。我們建議使用較少列的模式設計來獲得最佳性能。
**Size of Cells ( 單元格大小 )**
在編碼或壓縮之前,沒有單個單元格可能大于 **64KB** 。組合密鑰的單元在 **Kudu** 完成的內部復合密鑰編碼之后,總共限制在 **16KB** 。插入不符合這些限制的行將導致錯誤返回給客戶端。
**Size of Rows ( 行大小 )**
盡管單個單元格可能高達 **64KB** ,而 **Kudu** 最多支持 **300** 列,但建議不要單行大于幾百 **KB** 。
**Valid Identifiers ( 有效標識符 )**
諸如表和列名稱的標識符必須是有效的 **UTF-8** 序列,不超過 **256** 個字節。
**Immutable Primary Keys ( 不可變的主鍵?)**
**Kudu** 不允許您更新一行的主鍵列。
**Non-alterable Primary Key ( 不可更改的主鍵?)**
表創建后,**Kudu** 不允許您更改主鍵列。
**Non-alterable Partitioning ( 不可更改的分區?)**
**Kudu** 不允許您更改創建后如何分區表,但添加或刪除范圍分區除外。
**Non-alterable Column Types ( 不可更改的列類型?)**
**Kudu** 不允許更改列的類型。
**Partition Splitting ( 分區切分 )**
表創建后,分區不能拆分或合并。
