
[TOC]
**B tree:** 二叉樹(Binary tree),每個節點只能存儲一個數。
**B-tree:**B樹(B-Tree,并不是B“減”樹,橫杠為連接符,容易被誤導)
B樹屬于多叉樹又名平衡多路查找樹。每個節點可以多個數(由磁盤大小決定)。
**B+tree** 和 **B\*tree** 都是 B-tree的變種
## 索引為什么是用B樹呢?
一般來說,索引本身也很大,不可能全部存儲在內存中,因此索引往往以索引文件的形式存儲的磁盤上。這樣的話,索引查找過程中就要產生磁盤I/O消耗,相對于內存存取,I/O存取的消耗要高幾個數量級,所以評價一個數據結構作為索引的優劣最重要的指標就是在查找過程中磁盤I/O操作次數的漸進復雜度。換句話說,索引的結構組織要盡量減少查找過程中磁盤I/O的存取次數。而B-/+/\*Tree,經過改進可以有效的利用系統對磁盤的塊讀取特性,在讀取相同磁盤塊的同時,盡可能多的加載索引數據,來提高索引命中效率,從而達到減少磁盤IO的讀取次數。
不了解磁盤相關知識的可以查看 [硬盤基本知識(磁頭、磁道、扇區、柱面)](https://www.jianshu.com/p/9aa66f634ed6)
下面通過示意圖來看一下,B-tree、B+tree、B\*tree
## B-tree
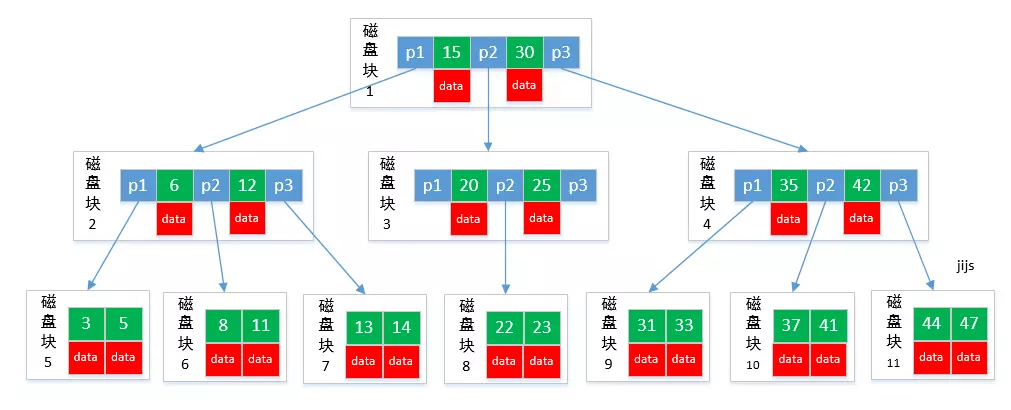
B-樹
從圖中可以看出,B-tree 利用了磁盤塊的特性進行構建的樹。每個磁盤塊一個節點,每個節點包含了很關鍵字。把樹的節點關鍵字增多后樹的層級比原來的二叉樹少了,減少數據查找的次數和復雜度。
B-tree巧妙利用了磁盤預讀原理,將一個節點的大小設為等于一個頁(每頁為4K),這樣每個節點只需要一次I/O就可以完全載入。
B-tree 的數據可以存在任何節點中。
## B+tree
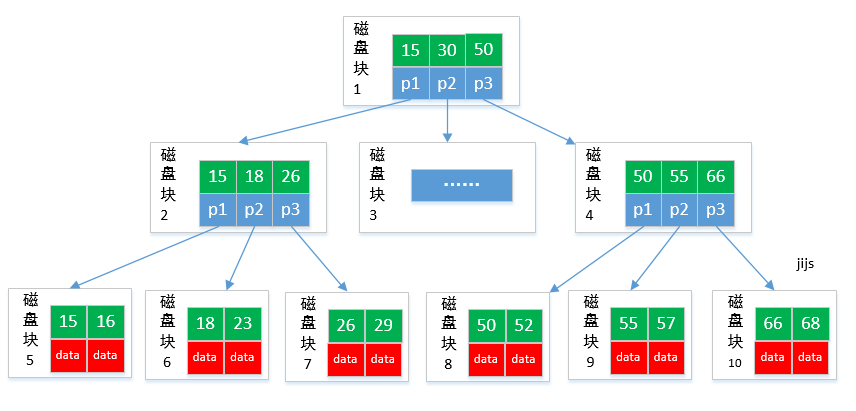
B+樹
B+tree 是 B-tree 的變種,數據只能存儲在葉子節點。
B+tree 是 B-tree 的變種,B+tree 數據只存儲在葉子節點中。這樣在B樹的基礎上每個節點存儲的關鍵字數更多,樹的層級更少所以查詢數據更快,所有指關鍵字指針都存在葉子節點,所以每次查找的次數都相同所以查詢速度更穩定;
> 如果每個節點能存放M個數據,每個節點的數據在M/2到M之間。預留出空間可以插入新的數據。
## B\*tree
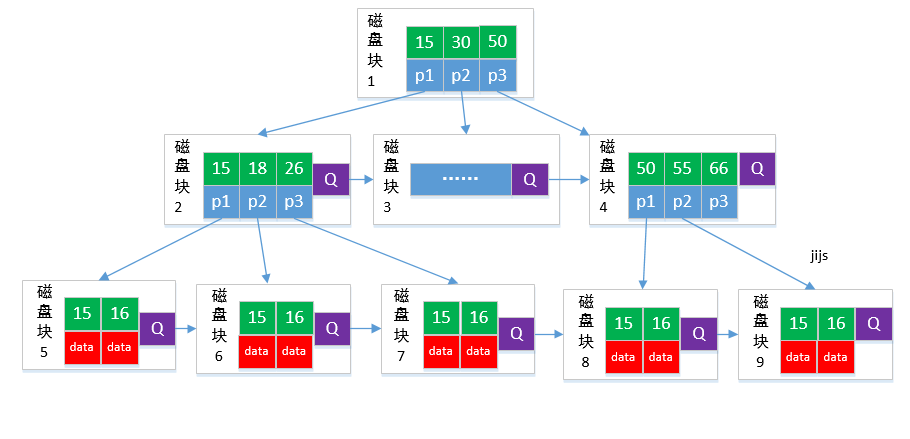
B\*樹
B\*tree 每個磁盤塊中又添加了對下一個磁盤塊的引用。這樣可以在當前磁盤塊滿時,不用擴容直接存儲到下一個臨近磁盤塊中。當兩個鄰近的磁盤塊都滿時,這兩個磁盤塊各分出1/3的數據重新分配一個磁盤塊,這樣這三個磁盤塊的數據都為2/3。
> 如果每個節點能存放M個數據,每個節點的數據在2M/3到M之間。預留出空間可以插入新的數據。
在B+樹的基礎上因其初始化的容量變大,使得節點空間使用率更高,而又存有兄弟節點的指針,可以向兄弟節點轉移關鍵字的特性使得B\*樹額分解次數變得更少;
- 線程參數含義
- Inoddb索引實現
- 為什么是B+tree
- Redis使用,分布式鎖的實現
- 操作系統虛擬內存換頁的過程
- TCP三次握手
- Volatile關鍵字的作用
- 樂觀鎖,悲觀鎖
- HashMap結構,是否線程安全
- ConcurrentHashMap如何保證線程安全
- 說一下B樹和B+樹的區別
- HashMap的實現,擴容機制,擴容時如何保證可操作?
- Spring AOP的原理
- Spring IoC的原理,如何實現,如何解決循環依賴?
- 兩線程對變量i進行加1操作,結果如何?為什么?怎么解決?
- CAS概念、原子類實現原理
- synchronize底層實現,如何實現Lock?
- AQS有什么特點?
- 介紹各種網絡協議。
- DNS在網絡層用哪個協議,為什么。
- 介紹HTTPS協議,詳述SSL建立連接過程。
- 反轉單鏈表
- 復雜鏈表復制
- 數組a,先單調地址再單調遞減,輸出數組中不同元素個數
- 說一下Java垃圾回收機制
- 64匹馬,8個賽道,找最快的4匹馬
- 64匹馬,8個賽道,找最快的8匹馬
- 給出兩個升序數組A、B和長度m、n,求第k個大的
- 講一下多線程與多進程區別
- JVM中什么時候會進行垃圾回收?什么樣的對象是可以回收的?
- Spring主要思想是什么?