>[success] # 單一職責
單一職責原則的英文是 `Single Responsibility Principle`,原則的英文描述是這樣的:`A class or module should have a single responsibility`中文意思**一個類或者模塊只負責完成一個職責(或者功能)** 更通俗意思 **在定義類、接口、方法后,不能多于一個動機去改變這個類、接口、方法。**
* 在《敏捷軟件開發:原則、模式與實踐》這本書中,把**職責**定義為**變化的原因**。如果你能夠想到多于一個的動機去改變一個類,那么這個類就具有多于一個的職責
* 一個類只負責完成一個職責或者功能。也就是說,不要設計大而全的類,要設計**粒度小、功能單一**的類
* 一個類包含了**兩個或者兩個以上業務不相干的功能**,那我們就說它職責不夠單一,應該將它拆分成多個功能更加單一、粒度更細的類
*****
* **總結**:一個類只負責完成一個職責或者功能。不要設計大而全的類,要設計粒度小、功能單一的類。單一職責原則是為了實現代碼高內聚、低耦合,提高代碼的復用性、可讀性、可維護性。
*****
例如,在轉賬的情況下,它應該只負責傳入轉賬,而不是同時負責傳出、傳入和國際轉賬。此外,在這個特定的例子中,我們的類設計必須足夠靈活,不需要在數據庫架構更新后進行更改
>[danger] ##### 為什么要做職責分離
* [圖片來自 職責原則:如何在代碼設計中實現職責分離?](https://kaiwu.lagou.com/course/courseInfo.htm?courseId=710#/detail/pc?id=6872)
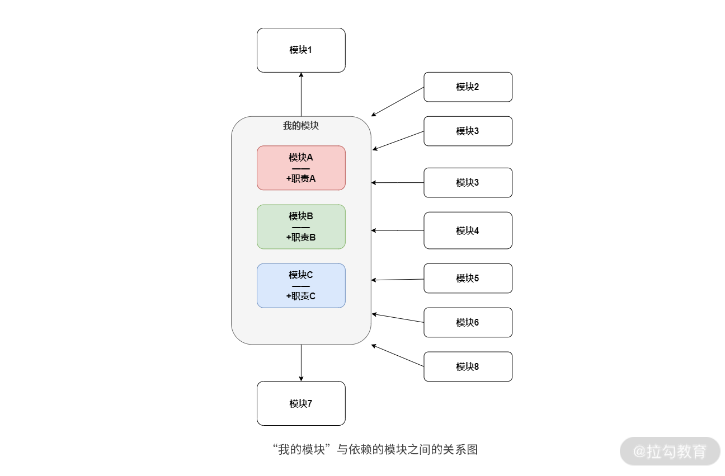
上圖中,`我的模塊`作為一個單獨模塊內部包含了`模塊 A、B、C`,但包含的`模塊 A、B、C`之間沒有相互關聯,外界的其他八個模塊都和`我的模塊`有關聯,此時如果修改`A`變相的`我的模塊`也被改動,那么其余八個模塊都有需要重新測試風險,或者其他未來業務需要和`模塊 A、B、C`中單獨任意一個模塊通信都需要和`我的模塊`整體通信
* 提高內聚 劃分清除職責[圖片來自 職責原則:如何在代碼設計中實現職責分離?](https://kaiwu.lagou.com/course/courseInfo.htm?courseId=710#/detail/pc?id=6872)
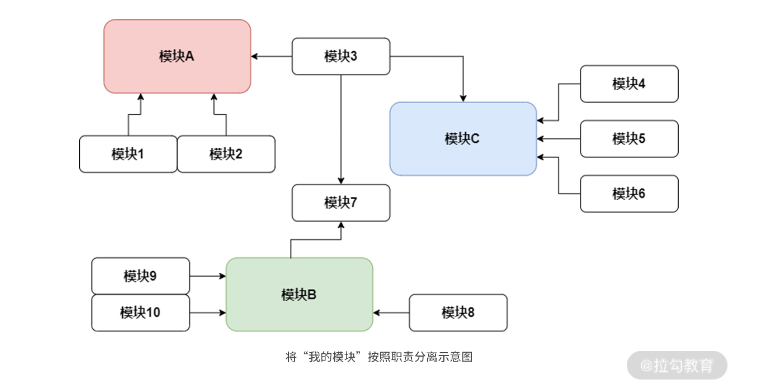
上圖中講我的模塊去掉依賴模塊直接找到彼此需要的對接,各個模塊專注于自己最重要的某個職責,并建立起與其他模塊之間清晰的界限
* 總結:**內聚本質上表示的是系統內部的各個部分對同一個問題的專注程度,以及這些部分彼此之間聯系的緊密性**,對同一個問題的專注程度才是判斷內聚高低的標準,而職責分離只是實現高內聚的一種方法而已
>[danger] ##### 職責分離的重要性
1. **直接對問題進行對象建模,方便厘清構建邏輯**
2. **將問題分解為各種職責,更有利于系統的測試、調試和維護**
3. **提高系統的可擴展性**
>[danger] ##### 從場景出發來看單一職責
并不是任何情況都要做到單一職責,
* **場景一** 類 T 只負責一個職責P,這樣設計是符合單一職責原則的。后來由于某種原因,也許是需求變更了,也許是程序的設計者境界提高了,需要將職責 P 細分為粒度更細的職責 P1,P2,這時如果要使程序遵循單一職責原則,需要將類T也分解為兩個類 T1 和 T2,分別負責 P1、P2 兩個職責。但是在程序已經寫好的情況下,這樣做簡直太費時間了。所以,簡單的修改類 T,用它來負責兩個職責是一個比較不錯的選擇,雖然這樣做有悖于單一職責原則。(這樣做的風險在于職責擴散的不確定性,因為我們不會想到這個職責P,在未來可能會擴散為P1,P2,P3,P4……Pn。所以記住,在職責擴散到我們無法控制的程度之前,立刻對代碼進行重構。)
* **場景二**
~~~
public class UserInfo {
private long userId;
private String username;
private String email;
private String telephone;
private long createTime;
private long lastLoginTime;
private String avatarUrl;
private String provinceOfAddress; // 省
private String cityOfAddress; // 市
private String regionOfAddress; // 區
private String detailedAddress; // 詳細地址
// ...省略其他屬性和方法...
}
~~~
UserInfo 類包含的都是跟用戶相關的信息,所有的屬性和方法都隸屬于用戶這樣一個業務模型,滿足單一職責原則;另一種觀點是,地址信息在 UserInfo 類中,所占的比重比較高,可以繼續拆分成獨立的 UserAddress 類,UserInfo 只保留除 Address 之外的其他信息,拆分之后的兩個類的職責更加單一,這要根據場景具體分析是否適合,如果后期公司發展增加了地址維護等一些場景那將地址抽離為類效果更好
* **場景三**
接收命令行的任意字符串參數,然后反轉每個字符,并檢查反轉后的字符是否為“hello world”,如果是,則打印一條信息
~~~
public class Application {
private static void process(String[] words) {
for (int i = 0; i < words.length; i++) {
String arg = "";
for (int j = words[i].length(); j > 0; j--) {
arg+=words[i].substring(j-1,j);
}
System.out.println(arg);
}
if (words.length == 2){
if (words[0].toLowerCase().equals("hello")
&& words[1].toLowerCase().equals("world")){
System.out.println("...bingo");
}
}
}
public static void main(String[] args) {
process(new String[]{"test","is","a","mighty,hahaah,world"});
process(new String[]{"hello","world"});
}
}
~~~
上面代碼中`process()` 直接看名字并不能很好理解這個方法打算做什么,如果純根據我們需求去起這個變量名,可能名字叫`reverseCharactersAndTestHelloWorld()`(反轉字符和測試helloword),確實比之前可以通過方法名大概知道方法部分功能實現,但是命名太過于籠統的通常就是內聚性較差的信號
* **分離后效果**
~~~
public class ApplicationOpt {
public void process(String[] words) {
for (int i = 0; i < words.length; i++) {
reversecharacters(words[i]);
System.out.println(words[i]);
}
if (isHelloWorld(words)) {
System.out.println("...bingo");
}
}
private String reversecharacters(String forward) {
String reverse = "";
for (int j = forward.length(); j > 0; j--) {
reverse += forward.substring(j - 1, j);
}
return reverse;
}
private boolean isHelloWorld(String[] names) {
if (names.length == 2){
if (names[0].toLowerCase().equals("hello")
&& names[1].toLowerCase().equals("world")){
return true;
}
}
return false;
}
public static void main(String[] args) {
ApplicationOpt myApp = new ApplicationOpt();
myApp.process(new String[]{"test","is","a","mighty,hahaah,world"});
myApp.process(new String[]{"hello","world"});
}
}
~~~
分離后,**每個步驟都由一個方法來實現,你也能很快區分每個方法具體負責的職責是什么**
* **案例四**
假設有一個書籍類,保存書籍的名稱、作者、內容,提供文字修訂服務和查詢服務
~~~
public class Book {
private String name;
private String author;
private String text;
//constructor, getters and setters
public String replaceWordInText(String word){
return text.replaceAll(word, text);
}
public boolean isWordInText(String word){
return text.contains(word);
}
}
~~~
在后來要增加打印閱讀這里功能添加,你為了方便將這個功能寫到了`Book`類中,當打印服務需要針對不同的客服端進行適配時,書籍類就需要多次反復地進行修改,那么不同的類實例需要修改的地方就會越來越多,系統明顯變得更加脆弱,同時也違反了 SRP
~~~
public class Book {
//...
//打印服務
void printText(){
//具體實現
}
//閱讀服務
void getToRead(){
//具體實現
}
}
~~~
>[danger] ##### 職責是否具有唯一性
**職責是否具有唯一性**。當你有多個動機來改變一個類時,那么職責就多于一個,也就違反了 SRP。
>[danger] ##### 考慮職責分離的時機
**從不同的業務層面去看待同一個類的設計,對類是否職責單一,也會有不同的認識**,**[設計模式之美](https://time.geekbang.org/column/article/171771)** 王爭老師給了幾條判斷原則,比起很主觀地去思考類是否職責單一,要更有指導意義、更具有可執行性
1. 類中的代碼行數、函數或屬性過多,會影響代碼的可讀性和可維護性,我們就需要考慮對類進行拆分;
2. 類依賴的其他類過多,或者依賴類的其他類過多,不符合高內聚、低耦合的設計思想,我們就需要考慮對類進行拆分;
3. 私有方法過多,我們就要考慮能否將私有方法獨立到新的類中,設置為 public 方法,供更多的類使用,從而提高代碼的復用性
4. 比較難給類起一個合適名字,很難用一個業務名詞概括,或者只能用一些籠統的 Manager、Context 之類的詞語來命名,這就說明類的職責定義得可能不夠清晰
5. 類中大量的方法都是集中操作類中的某幾個屬性,比如,在 UserInfo 例子中,如果一半的方法都是在操作 address 信息,那就可以考慮將這幾個屬性和對應的方法拆分出來
>[danger] ##### 單一職責原則優點
* 可以降低類的復雜度,一個類只負責一項職責,其邏輯肯定要比負責多項職責簡單的多,但職責不一定只有一個類或方法,還可能有多個類或方法,比如,上傳文件是單一職責,而上傳方法、增刪改查 URL 方法、校驗方法都服務于上傳文件
* 提高類的可讀性,提高系統的可維護性
* 變更引起的風險降低,變更是必然的,如果單一職責原則遵守的好,當修改一個功能時,可以顯著降低對其他功能的影響
>[danger] ##### 總結
**評價一個類的職責是否足夠單一,我們并沒有一個非常明確的、可以量化的標準**,**可以先寫一個粗粒度的類,滿足業務需求。隨著業務的發展,如果粗粒度的類越來越龐大,代碼越來越多,這個時候,我們就可以將這個粗粒度的類,拆分成幾個更細粒度的類。這就是所謂的持續重構**
關于代碼行數也給建議 **,如果你是沒有太多項目經驗的編程初學者,實際上,我也可以給你一個湊活能用、比較寬泛的、可量化的標準,那就是一個類的代碼行數最好不能超過 200 行,函數個數及屬性個數都最好不要超過 10 個。**
* 單一職責原則通過避免設計大而全的類,避免將不相關的功能耦合在一起,來提高類的內聚性。同時,類職責單一,類依賴的和被依賴的其他類也會變少,減少了代碼的耦合性,以此來實現代碼的高內聚、低耦合。但是,如果拆分得過細,實際上會適得其反,反倒會降低內聚性,也會影響代碼的可維護性。
>[info] ## 參考文章
[設計模式之美](https://time.geekbang.org/column/article/171771)
[單一職責原則SRP](https://geek-docs.com/design-pattern/design-principle/single-responsibility-principle.html)
[單一職責原則:軟件世界中最重要的規則 - DZone](https://www.jdon.com/57486)
[# 職責原則:如何在代碼設計中實現職責分離?](https://kaiwu.lagou.com/course/courseInfo.htm?courseId=710#/detail/pc?id=6872)
