## **這篇文章,我們來聊一下對于一個支撐日活百萬用戶的高并系統,他的數據庫架構應該如何設計?**
看到這個題目,很多人第一反應就是:
**分庫分表啊!**
但是實際上,數據庫層面的分庫分表到底是用來干什么的,他的不同的作用如何應對不同的場景,我覺得很多同學可能都沒搞清楚。
* * *
**(1)用一個創業公司的發展作為背景引入**
假如我們現在是一個小創業公司,注冊用戶就20萬,每天活躍用戶就1萬,每天單表數據量就1000,然后高峰期每秒鐘并發請求最多就10。
天哪!就這種系統,隨便找一個有幾年工作經驗的高級工程師,然后帶幾個年輕工程師,隨便干干都可以做出來。
因為這樣的系統,實際上主要就是在前期快速的進行業務功能的開發,搞一個單塊系統部署在一臺服務器上,然后連接一個數據庫就可以了。
接著大家就是不停的在一個工程里填充進去各種業務代碼,盡快把公司的業務支撐起來,如下圖所示。
結果呢,沒想到我們運氣這么好,碰上個優秀的CEO帶著我們走上了康莊大道!
公司業務發展迅猛,過了幾個月,注冊用戶數達到了2000萬!每天活躍用戶數100萬!每天單表新增數據量達到50萬條!高峰期每秒請求量達到1萬!
同時公司還順帶著融資了兩輪,估值達到了驚人的幾億美金!一只朝氣蓬勃的幼年獨角獸的節奏!
好吧,現在大家感覺壓力已經有點大了,為啥呢?
因為每天單表新增50萬條數據,一個月就多1500萬條數據,一年下來單表會達到上億條數據。
經過一段時間的運行,現在咱們單表已經兩三千萬條數據了,勉強還能支撐著。
但是,眼見著系統訪問數據庫的性能怎么越來越差呢,單表數據量越來越大,拖垮了一些復雜查詢SQL的性能啊!
然后高峰期請求現在是每秒1萬,咱們的系統在線上部署了20臺機器,平均每臺機器每秒支撐500請求,這個還能抗住,沒啥大問題。
但是數據庫層面呢?
如果說此時你還是一臺數據庫服務器在支撐每秒上萬的請求,負責任的告訴你,每次高峰期會出現下述問題:
* 你的數據庫服務器的磁盤IO、網絡帶寬、CPU負載、內存消耗,都會達到非常高的情況,數據庫所在服務器的整體負載會非常重,甚至都快不堪重負了
* 高峰期時,本來你單表數據量就很大,SQL性能就不太好,這時加上你的數據庫服務器負載太高導致性能下降,就會發現你的SQL性能更差了
* 最明顯的一個感覺,就是你的系統在高峰期各個功能都運行的很慢,用戶體驗很差,點一個按鈕可能要幾十秒才出來結果
* 如果你運氣不太好,數據庫服務器的配置不是特別的高的話,弄不好你還會經歷數據庫宕機的情況,因為負載太高對數據庫壓力太大了
* * *
**(2)多臺服務器分庫支撐高并發讀寫**
首先我們先考慮第一個問題,數據庫每秒上萬的并發請求應該如何來支撐呢?
要搞清楚這個問題,先得明白一般數據庫部署在什么配置的服務器上。
通常來說,假如你用普通配置的服務器來部署數據庫,那也起碼是16核32G的機器配置。
這種非常普通的機器配置部署的數據庫,一般線上的經驗是:不要讓其每秒請求支撐超過2000,一般控制在2000左右。
控制在這個程度,一般數據庫負載相對合理,不會帶來太大的壓力,沒有太大的宕機風險。
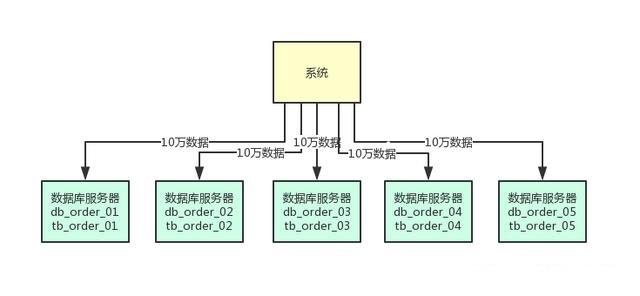
所以首先第一步,就是在上萬并發請求的場景下,部署個5臺服務器,每臺服務器上都部署一個數據庫實例。
然后每個數據庫實例里,都創建一個一樣的庫,比如說訂單庫。
此時在5臺服務器上都有一個訂單庫,名字可以類似為:db\_order\_01,db\_order\_02,等等。
然后每個訂單庫里,都有一個相同的表,比如說訂單庫里有訂單信息表,那么此時5個訂單庫里都有一個訂單信息表。
比如db\_order\_01庫里就有一個tb\_order\_01表,db\_order\_02庫里就有一個tb\_order\_02表。
這就實現了一個基本的分庫分表的思路,原來的一臺數據庫服務器變成了5臺數據庫服務器,原來的一個庫變成了5個庫,原來的一張表變成了5個表。
然后你在寫入數據的時候,需要借助數據庫中間件,比如sharding-jdbc,或者是mycat,都可以。
你可以根據比如訂單id來hash后按5取模,比如每天訂單表新增50萬數據,此時其中10萬條數據會落入db\_order\_01庫的tb\_order\_01表,另外10萬條數據會落入db\_order\_02庫的tb\_order\_02表,以此類推。
這樣就可以把數據均勻分散在5臺服務器上了,查詢的時候,也可以通過訂單id來hash取模,去對應的服務器上的數據庫里,從對應的表里查詢那條數據出來即可。
依據這個思路畫出的圖如下所示,大家可以看看。
*
做這一步有什么好處呢?
第一個好處,原來比如訂單表就一張表,這個時候不就成了5張表了么,那么每個表的數據就變成1/5了。
假設訂單表一年有1億條數據,此時5張表里每張表一年就2000萬數據了。
那么假設當前訂單表里已經有2000萬數據了,此時做了上述拆分,每個表里就只有400萬數據了。
而且每天新增50萬數據的話,那么每個表才新增10萬數據,這樣是不是初步緩解了單表數據量過大影響系統性能的問題?
另外就是每秒1萬請求到5臺數據庫上,每臺數據庫就承載每秒2000的請求,是不是一下子把每臺數據庫服務器的并發請求降低到了安全范圍內?
這樣,降低了數據庫的高峰期負載,同時還保證了高峰期的性能。
* * *
**(3)大量分表來保證海量數據下的查詢性能**
但是上述的數據庫架構還有一個問題,那就是單表數據量還是過大,現在訂單表才分為了5張表,那么如果訂單一年有1億條,每個表就有2000萬條,這也還是太大了。
**所以還應該繼續分表,大量分表。**
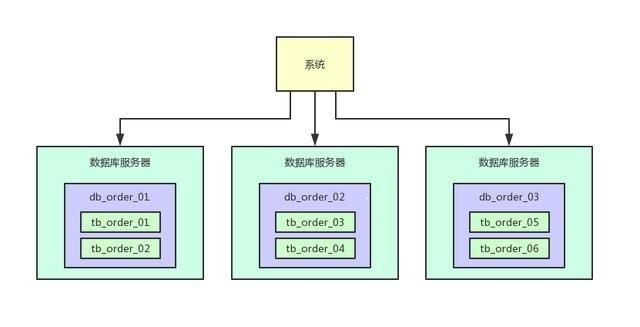
比如可以把訂單表一共拆分為1024張表,這樣1億數據量的話,分散到每個表里也就才10萬量級的數據量,然后這上千張表分散在5臺數據庫里就可以了。
在寫入數據的時候,需要做**兩次路由**,先對訂單id hash后對數據庫的數量取模,可以路由到一臺數據庫上,然后再對那臺數據庫上的表數量取模,就可以路由到數據庫上的一個表里了。
通過這個步驟,就可以讓每個表里的數據量非常小,每年1億數據增長,但是到每個表里才10萬條數據增長,這個系統運行10年,每個表里可能才百萬級的數據量。
這樣可以一次性為系統未來的運行做好充足的準備,看下面的圖,一起來感受一下:
* * *
**(4)讀寫分離來支撐按需擴容以及性能提升**
這個時候整體效果已經挺不錯了,大量分表的策略保證可能未來10年,每個表的數據量都不會太大,這可以保證單表內的SQL執行效率和性能。
然后多臺數據庫的拆分方式,可以保證每臺數據庫服務器承載一部分的讀寫請求,降低每臺服務器的負載。
但是此時還有一個問題,假如說每臺數據庫服務器承載每秒2000的請求,然后其中400請求是寫入,1600請求是查詢。
也就是說,增刪改的SQL才占到了20%的比例,80%的請求是查詢。
此時假如說隨著用戶量越來越大,假如說又變成每臺服務器承載4000請求了。
那么其中800請求是寫入,3200請求是查詢,如果說你按照目前的情況來擴容,就需要增加一臺數據庫服務器.
但是此時可能就會涉及到表的遷移,因為需要遷移一部分表到新的數據庫服務器上去,是不是很麻煩?
其實完全沒必要,數據庫一般都支持讀寫分離,也就是做主從架構。
寫入的時候寫入主數據庫服務器,查詢的時候讀取從數據庫服務器,就可以讓一個表的讀寫請求分開落地到不同的數據庫上去執行。
這樣的話,假如寫入主庫的請求是每秒400,查詢從庫的請求是每秒1600,那么圖大概如下所示。
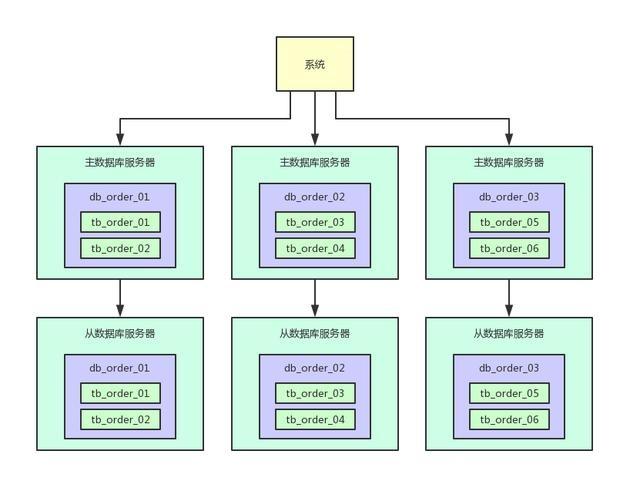
寫入主庫的時候,會自動同步數據到從庫上去,保證主庫和從庫數據一致。
然后查詢的時候都是走從庫去查詢的,這就通過數據庫的主從架構實現了讀寫分離的效果了。
現在的好處就是,假如說現在主庫寫請求增加到800,這個無所謂,不需要擴容。然后從庫的讀請求增加到了3200,需要擴容了。
這時,你直接給主庫再掛載一個新的從庫就可以了,兩個從庫,每個從庫支撐1600的讀請求,不需要因為讀請求增長來擴容主庫。
實際上線上生產你會發現,讀請求的增長速度遠遠高于寫請求,所以讀寫分離之后,大部分時候就是擴容從庫支撐更高的讀請求就可以了。
而且另外一點,對同一個表,如果你既寫入數據(涉及加鎖),還從該表查詢數據,可能會牽扯到鎖沖突等問題,無論是寫性能還是讀性能,都會有影響。
所以一旦讀寫分離之后,對主庫的表就僅僅是寫入,沒任何查詢會影響他,對從庫的表就僅僅是查詢。
* * *
**(5)高并發下的數據庫架構設計總結**
其實從大的一個簡化的角度來說,高并發的場景下,數據庫層面的架構肯定是需要經過精心的設計的。
尤其是涉及到分庫來支撐高并發的請求,大量分表保證每個表的數據量別太大,讀寫分離實現主庫和從庫按需擴容以及性能保證。
這篇文章就是從一個大的角度來梳理了一下思路,各位同學可以結合自己公司的業務和項目來考慮自己的系統如何做分庫分表應該怎么做。
另外就是,具體的分庫分表落地的時候,需要借助數據庫中間件來實現分庫分表和讀寫分離,大家可以自己參考 sharding-jdbc 或者 mycat 的官網即可,里面的文檔都有詳細的使用描述。
