原文:https://zookeeper.apache.org/doc/r3.4.14/
## Zookeeper
* [Zookeeper:一個為分布式應用設計的`分布式協調服務`](https://juejin.cn/post/6844903539358040078#1 "#1")
* [Zookeeper設計目標](https://juejin.cn/post/6844903539358040078#1.1 "#1.1")
* [Zookeeper`數據模型`和`層級命名空間`](https://juejin.cn/post/6844903539358040078#1.2 "#1.2")
* [Zookeeper`默認節點`和`臨時節點`](https://juejin.cn/post/6844903539358040078#1.3 "#1.3")
* [Zookeeper`條件更新`和`監視`(watches)](https://juejin.cn/post/6844903539358040078#1.4 "#1.4")
* [Zookeeper`保證`(Guarantees)](https://juejin.cn/post/6844903539358040078#1.5 "#1.5")
* [Zookeeper`簡單API`](https://juejin.cn/post/6844903539358040078#1.6 "#1.6")
* [Zookeeper`實現原理`](https://juejin.cn/post/6844903539358040078#1.7 "#1.7")
* [Zookeeper`使用`](https://juejin.cn/post/6844903539358040078#1.8 "#1.8")
* [Zookeeper`性能`](https://juejin.cn/post/6844903539358040078#1.9 "#1.9")
* [Zookeeper`可靠性`](https://juejin.cn/post/6844903539358040078#1.10 "#1.10")
* [Zookeeper項目](https://juejin.cn/post/6844903539358040078#1.11 "#1.11")
* * *
### [Zookeeper:一個為分布式應用設計的`分布式協調服務`](https://link.juejin.cn/?target=undefined)
ZooKeeper是一款開源的`分布式應用`的`分布式協調服務`。它包含一個簡單的`原語集`,分布式應用程序可以基于它實現同步服務,配置維護和命名服務等。Zookeeper 設計很容易進行編程,它使用一種類似于文件系統的目錄樹結構的數據模型,以 java 方式運行,有 java 和 c 的綁定(binding)。
`協調服務`是非常難以被正確實現的。他們特別容易產生諸如競態條件、死鎖等錯誤。ZooKeeper背后的動機是為分布式應用程序減輕從零開始實現協調服務的難度。
### [設計目標](https://link.juejin.cn/?target=undefined)
##### Zookeeper是非常簡單的。
ZooKeeper允許分布式進程通過與標準文件系統類似組織的共享層級命名空間來相互協調。命名空間被稱為`znode`的數據記錄組成,用ZooKeeper的說法,這些記錄和標準文件系統中的文件和目錄非常相似。與典型的用于存儲的文件系統不同,ZooKeeper數據保存在內存中,這意味著ZooKeeper可以實現高吞吐量和低延遲。
Zookeeper的實現著重于高性能、高可用性和嚴格的順序訪問。ZooKeeper的性能方面意味著它可以用于大型分布式系統。可靠性方面使它不會造成單點故障。嚴格的排序意味著可以在客戶端實現復雜的同步原語。
##### Zookeeper 是復制的(replicated)
就像它協調的分布式進程一樣,Zookeeper 自身也在被稱為“ensemble”的一組主機之間進行復制。
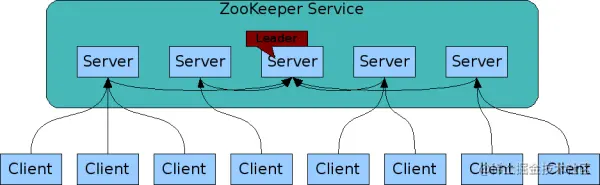
組成 Zookeeper 服務(Service)的每個服務器(server)之間都必須相互了解對方。他們維護一個內存狀態圖,以及一個持久存儲的事務日志和快照。只要這些服務器(servers)中大多數是可用的,整個ZooKeeper服務就是可用的。
客戶端(client)連接到任意一臺ZooKeeper服務器。客戶端維護一個TCP連接,通過它發送請求、獲取響應、獲取監視事件以及發送心跳。如果到服務器的TCP連接中斷,客戶端將連接到其他不同的服務器。
##### Zokeeper是有順序的
ZooKeeper使用反映所有ZooKeeper事務順序的數字來標記每個更新。后續操作可以使用該次序來實現更高級別的抽象,例如同步原語。
##### ZooKeeper 是快速的
在應對以“讀”為主的負載時尤其地快速。ZooKeeper應用程序在數千臺機器上運行,并且在讀取比寫入更為普遍的情況下,性能表現最佳,比例約為10:1。
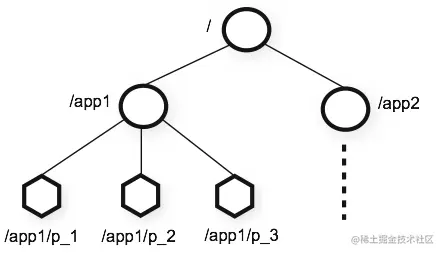
### [Zookeeper數據模型和層級命名空間](https://link.juejin.cn/?target=undefined)
ZooKeeper提供的命名空間與標準文件系統非常相似。路徑是由斜杠`/`分隔的一系列元素。 ZooKeeper命名空間中的每個節點都由一個路徑標識。
### [Zookeeper`默認節點`和`臨時節點`](https://link.juejin.cn/?target=undefined)
與標準文件系統不同的是,ZooKeeper命名空間中的每個節點都可以擁有與其相關的數據以及子節點。這就像一個文件系統中可以存在一個文件或一個目錄。ZooKeeper被設計用來存儲相關的協調數據,如狀態信息、配置、位置信息等等,所以每個節點上存儲的數據通常都很小,在字節(byte)到千字節(kb)范圍內。我們使用術語znode來清楚地說明我們正在討論ZooKeeper數據節點。
Znode 維護了一個狀態(`stat`)結構,其中包含了表示數據改變、訪問控制列表(ACL)改變的版本號、時間戳,可用于緩存校驗、協調更新。每當一個znode的數據發生變化,版本號就會增加。例如,每當客戶端檢索數據時,客戶端也會接收到相應數據的版本信息。
存儲在命名空間中每個節點上的數據是以原子方式讀取和寫入的。讀取一個znode將獲得其全部的數據,而寫入則替換其全部的數據。
ZooKeeper也有臨時節點的概念。當創建臨時節點的客戶端會話一直保持活動,瞬時節點就一直存在。而當會話終結時,瞬時節點被刪除。
### [Zookeeper`條件更新`和`監視`(watches)](https://link.juejin.cn/?target=undefined)
ZooKeeper 支持“監視”(watches)的概念。客戶端可以在znode上設置一個監視(watch)。當 znode改變時,監視(watch)將被觸發并移除。當監視(watch)被觸發時,當“監視”被觸發時,客戶端會收到一個描述了 znode 的變更的數據包。如果客戶端和Zookeeper服務器之間的連接斷開時,客戶端將會收到一個本地通知。
### [Zookeeper`保證`(Guarantees)](https://link.juejin.cn/?target=undefined)
Zookeeper非常地快速也非常簡單。不過,由于它的目標是作為構建諸如“同步”這類更復雜服務的基礎,它提供了一些的一組保證:
* 順序一致性 - 來自客戶端的更改請求將會按照它們的發送的順序被應用。
* 原子性 - 更改要么成功,要么失敗,不會存在部分成功、部分失敗的結果。
* 單一系統映像 - 客戶端會看到 Zookeeper 服務的相同的視圖,而無論它們連到具體哪一個服務器上
* 可靠性 - 一旦一次更改請求被應用,更改的結果就會被持久化,直到被下一次更改覆蓋。
* 及時性 - 客戶端看到的系統視圖在一定的時間范圍內總是最新的。
### [簡單的API](https://link.juejin.cn/?target=undefined)
ZooKeeper的一個設計目標是提供一個非常簡單的編程接口。 因此,它只支持這些操作:
* ###### create
> 在(命名空間)樹的一個特定地址上創建一個節點。
* ###### delete
> 刪除一個節點。
* ###### exists
> 判斷某個路徑下是否存在該節點。
* ###### get data
> 獲取節點的數據。
* ###### set data
> 向節點寫入數據。
* ###### get children
> 檢索節點的子節點列表。
* ###### sync
> 等待數據傳播完成。
### [Zookeeper`實現原理`](https://link.juejin.cn/?target=undefined)
[ZooKeeper Components](https://link.juejin.cn/?target=http%3A%2F%2Fzookeeper.apache.org%2Fdoc%2Fr3.4.11%2FzookeeperOver.html%23fg_zkComponents "http://zookeeper.apache.org/doc/r3.4.11/zookeeperOver.html#fg_zkComponents")顯示了ZooKeeper服務的高級組件。除`Request Processor`外,構成ZooKeeper服務的每個服務器都復制每個組件的副本。
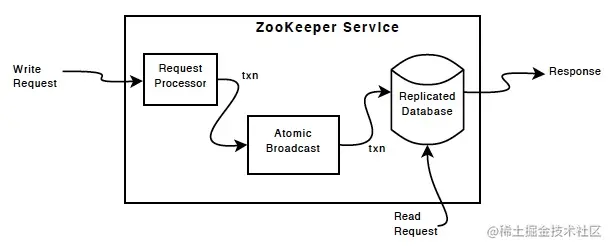
`replicated database`是一個內存數據庫,它包含了整顆數據樹。數據寫入在應用到內存數據庫之前,會先序列化到磁盤。
每一個 Zookeeper 服務器都向客戶端提供服務,客戶端連接到一個確切的Zookeeper服務器提交請求。讀請求從服務器數據庫的本地拷貝中獲取。改變Zookeeper服務狀態的請求、寫入請求通過一個一致性協議進行處理。
作為協議的一部分,客戶端的所有寫入請求都被轉發到一個單獨的服務器,該服務器被稱為 leader。而其余的服務器,被稱為follower,從leader接收消息提案(proposal)并對消息的交付取得一致。消息層維護leader失效時的更新替換以及leader和follower之間的同步。
Zookeeper 使用自定義的原子消息協議。由于消息層是原子的,Zookeeper可以保證本地的復制品不會不一致。當 leader收到一個寫入請求時,它計算系統所處的狀態以及何時應用寫入請求,并將此轉換為一個事務,包含新的狀態。
### [使用](https://link.juejin.cn/?target=undefined)
Zookeeper 的編程接口特意地定義得很簡單。然而,通過這些編程接口可以更高階的操作,例如同步原語,成員分組,所有權,等等。
### [性能](https://link.juejin.cn/?target=undefined)
Zookeeper 被設計為高性能。但實際是否如此呢?在雅虎研發中心的 Zookeeper 開發團隊的研究結果表明的確如此。(參見下圖:Zookeeper 吞吐量隨讀寫比的變化)。在“讀”多于“寫”的應用程序中尤其地高性能,因為“寫”會導致在所有的服務器間同步狀態。(“讀”多于“寫”是協調服務的典型場景。)
Zookeeper 吞吐量隨讀寫比的變化
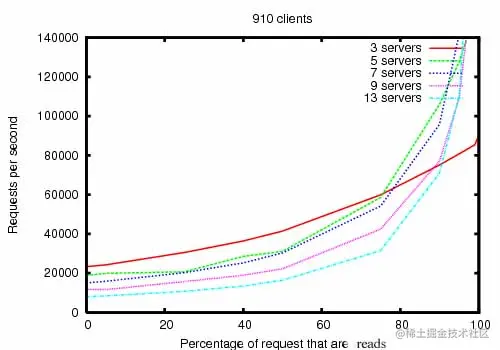
圖“Zookeeper 吞吐量隨讀寫比的變化” 是 Zookeeper3.2 版本運行于 Dual 2Gh Xeon + 2 個 15K RPM 的 SATA 硬盤驅動器的服務器上的結果。一個驅動器用作 Zookeeper 專用的日志設備。快照寫到操作系統驅動器。寫請求是 1K 數據的寫入而讀請求是 1K 的數據讀取。“Servers”標出了 Zookeeper Ensemble 的大小,即組成 Zookeeper 服務的服務器的數量。大約30臺其它的服務器被用作模擬客戶端。Zookeeper Ensemble 被配置為不允許客戶端連接到 Leader 。
注:3.2版本的讀/寫性能相對于3.1版本以前有最多達2倍的提升。
基準測試也表明了 Zookeeper 的可靠性。圖“錯誤發生的情況下的可靠性”展示了 Zookeeper 是如何應對各種不同的失效的。圖中標注的事件如下:
1. 一個 Follower 失效然后恢復。
2. 另一個不同的 Follower 失效然后恢復。
3. Leader 失效。
4. 兩個 Follower 失效然后恢復。
5. 另一個 Leader 失效。
### [可靠性](https://link.juejin.cn/?target=undefined)
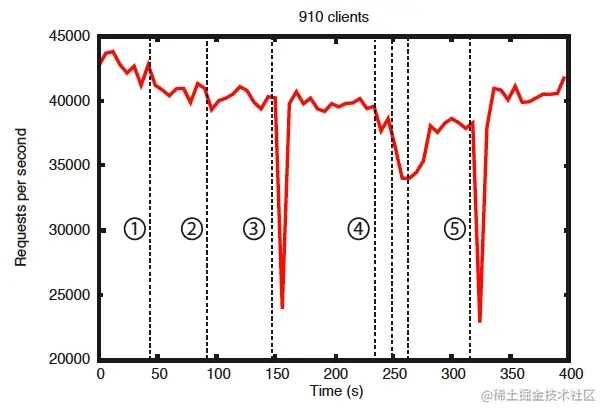
從這張圖中可以得到幾點重要的結果。首先,如果 follower 失效并快速恢復,Zookeeper 能夠維持高吞吐量,盡管存在失效。但也許更重要的是,leader選舉算法使系統足夠快地恢復,避免了吞吐量的總體下降。從觀察結果來看,Zookeeper花了不到200毫秒的時間選舉出了一個新的 leader。第三,只要follower恢復,Zookeeper的吞吐量能夠再次上升到剛開始處理請求時的水平。
### [關于ZooKeeper項目](https://link.juejin.cn/?target=undefined)
Zookeeper 已經被成功地用在許多工業級的應用。在雅虎,Zookeeper被用作雅虎消息中間件的協調和失效恢復服務,該系統是一個高伸縮性的發布訂閱系統,管理著成千上萬的主題復制和數據分發。Zookeeper還被用在雅虎爬蟲的抓取服務上,用于管理失效恢復。許多雅虎的廣告系統也用 Zookeeper 實現可靠的服務。
