實戰解答
>[danger]**問題一:Mysql怎么保證一致性的?**
OK,這個問題分為兩個層面來說。
從數據庫層面,數據庫通過原子性、隔離性、持久性來保證一致性。也就是說ACID四大特性之中,C(一致性)是目的,A(原子性)、I(隔離性)、D(持久性)是手段,是為了保證一致性,數據庫提供的手段。
數據庫必須要實現AID三大特性,才有可能實現一致性。例如,原子性無法保證,顯然一致性也無法保證。
<br>
但是,如果你在事務里故意寫出違反約束的代碼,一致性還是無法保證的。例如,你在轉賬的例子中,你的代碼里故意不給B賬戶加錢,那一致性還是無法保證。因此,還必須從應用層角度考慮。
從應用層面,通過代碼判斷數據庫數據是否有效,然后決定回滾還是提交數據!
<br>
>[danger]**問題二: Mysql怎么保證原子性的?**
OK,是利用Innodb的undo log。
undo log名為回滾日志,是實現原子性的關鍵,當事務回滾時能夠撤銷所有已經成功執行的sql語句,他需要記錄你要回滾的相應日志信息。
例如
```
(1)當你delete一條數據的時候,就需要記錄這條數據的信息,回滾的時候,insert這條舊數據
(2)當你update一條數據的時候,就需要記錄之前的舊值,回滾的時候,根據舊值執行update操作
(3)當你insert一條數據的時候,就需要這條記錄的主鍵,回滾的時候,根據主鍵執行delete操作
```
undo log記錄了這些回滾需要的信息,當事務執行失敗或調用了rollback,導致事務需要回滾,便可以利用undo log中的信息將數據回滾到修改之前的樣子。
<br>
>[danger]**問題三: Mysql怎么保證持久性的?**
OK,是利用Innodb的redo log。
正如之前說的,Mysql是先把磁盤上的數據加載到內存中,在內存中對數據進行修改,再刷回磁盤上。如果此時突然宕機,內存中的數據就會丟失。
怎么解決這個問題?
簡單啊,事務提交前直接把數據寫入磁盤就行啊。這么做有什么問題?
只修改一個頁面里的一個字節,就要將整個頁面刷入磁盤,太浪費資源了。畢竟一個頁面16kb大小,你只改其中一點點東西,就要將16kb的內容刷入磁盤,聽著也不合理。
畢竟一個事務里的SQL可能牽涉到多個數據頁的修改,而這些數據頁可能不是相鄰的,也就是屬于隨機IO。顯然操作隨機IO,速度會比較慢。
<br>
于是,決定采用redo log解決上面的問題。當做數據修改的時候,不僅在內存中操作,還會在redo log中記錄這次操作。
當事務提交的時候,會將redo log日志進行刷盤(redo log一部分在內存中,一部分在磁盤上)。當數據庫宕機重啟的時候,會將redo log中的內容恢復到數據庫中,再根據undo log和binlog內容決定回滾數據還是提交數據。
>[success] 采用redo log的好處?
其實好處就是將redo log進行刷盤比對數據頁刷盤效率高,具體表現如下
redo log體積小,畢竟只記錄了哪一頁修改了啥,因此體積小,刷盤快。
redo log是一直往末尾進行追加,屬于順序IO。效率顯然比隨機IO來的快。
ps:不想具體去談redo log具體長什么樣,因為內容太多了。
<br>
>[danger]**問題四: Mysql怎么保證隔離性的?**
OK,利用的是鎖和MVCC機制。還是拿轉賬例子來說明,有一個賬戶表如下
表名t\_balance
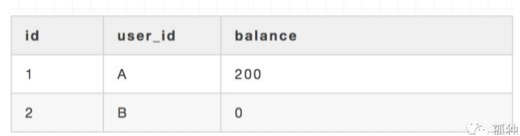
其中id是主鍵,user\_id為賬戶名,balance為余額。還是以轉賬兩次為例,如下圖所示

至于MVCC,即多版本并發控制(Multi Version Concurrency Control),一個行記錄數據有多個版本的快照數據,這些快照數據在undo log 中。
如果一個事務讀取的行正在做DELELE或者UPDATE操作,讀取操作不會等行上的鎖釋放,而是讀取該行的快照版本。
