本來就是真實的用戶,并且開通了appid,但是出現頻繁調用接口的情況;這種情況需要給相關appid限流處理,常用的限流算法有令牌桶和漏桶算法。
在開發中我們可能會遇到接口訪問頻次過高,這時候就需要做流量限制,你可能是用的`Nginx`這種 Web Server 來控制也可能是用了一些流行的類庫實現。在分布式系統中更是如此,限流是高并發系統的一大殺器,在設計限流算法之前我們先來了解一下它們是什么。
## 是什么
限流的英文是`Rate limit`(速率限制),維基百科中的定義比較簡單。我們編寫的程序可以被外部調用,Web 應用通過瀏覽器或者其他方式的 HTTP 方式訪問,接口的訪問頻率可能會非常快,如果我們沒有對接口訪問頻次做限制可能會導致服務器無法承受過高的壓力掛掉,這時候也可能會產生數據丟失。
而限流算法就可以幫助我們去控制每個接口或程序的函數被調用頻率,它有點兒像保險絲,防止系統因為超過訪問頻率或并發量而引起癱瘓。我們可能在調用某些第三方的接口的時候會看到類似這樣的響應頭:
> X-RateLimit-Limit: 60 //每秒60次請求
X-RateLimit-Remaining: 23 //當前還剩下多少次
X-RateLimit-Reset: 1540650789 //限制重置時間
## 常見限流算法
### 計數器
計數器是最簡單的限流算法,思路是維護一個單位時間內的計數器`Counter`,如判斷單位時間已經過去,則將計數器歸零。
**我們假設有個需求對于某個接口`/query`每分鐘最多允許訪問200次。**
1. 可以在程序中設置一個變量`count`,當過來一個請求我就將這個數`+1`,同時記錄請求時間。
2. 當下一個請求來的時候判斷`count`的計數值是否超過設定的頻次,以及當前請求的時間和第一次請求時間是否在 1 分鐘內。
* 如果在 1 分鐘內并且超過設定的頻次則證明請求過多,后面的請求就拒絕掉。
* 如果該請求與第一個請求的間隔時間大于 1 分鐘,且`count`值還在限流范圍內,就重置`count`。
```
public class CounterDemo {
public long timeStamp = getNowTime(); // 當前時間
public int reqCount = 0; // 初始化計數器
public final int limit = 100; // 時間窗口內最大請求數
public final long interval = 1000; // 時間窗口ms
public boolean grant() {
long now = getNowTime();
if (now < timeStamp + interval) {
// 在時間窗口內
reqCount++;
// 判斷當前時間窗口內是否超過最大請求控制數
return reqCount <= limit;
} else {
timeStamp = now;
// 超時后重置
reqCount = 1;
return true;
}
}
}
```
這種方法雖然簡單,但也有個大問題就是沒有很好的處理單位時間的邊界。
假設有個用戶在第 59 秒的最后幾毫秒瞬間發送 200 個請求,當 59 秒結束后 Counter 清零了,他在下一秒的時候又發送 200 個請求。那么在 1 秒鐘內這個用戶發送了 2 倍的請求,如下圖:
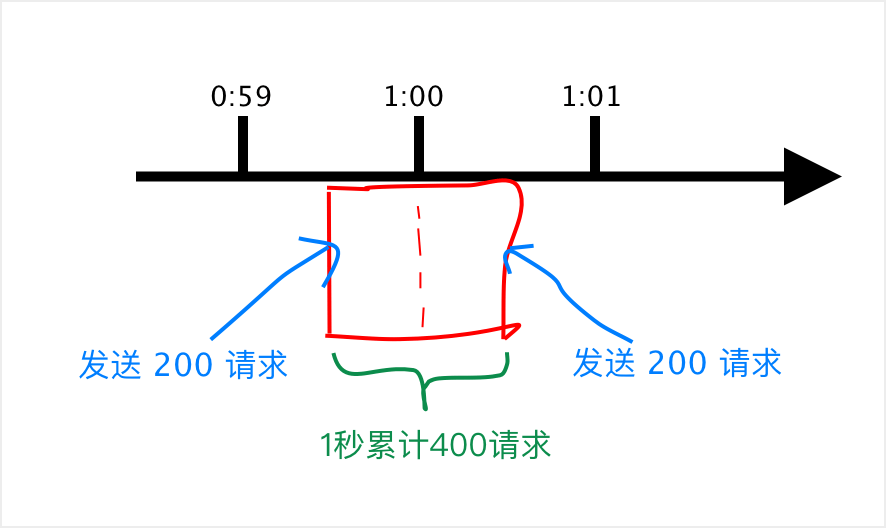
這種方式的缺點在于它沒有更細粒度的劃分臨界點,如果我們可以把這個時間窗口劃分成 6 份,每一份代表 10 秒,當然你可以將它劃分的更細。那么如何解決這里的臨界問題呢?來看看下面的滑動窗口吧。
### 滑動窗口(sentinel)
所謂[滑動窗口(Sliding window)](https://en.wikipedia.org/wiki/Sliding_window_protocol)是一種流量控制技術,這個詞出現在 TCP 協議中。我們來看看在限流中它是怎樣表現的:
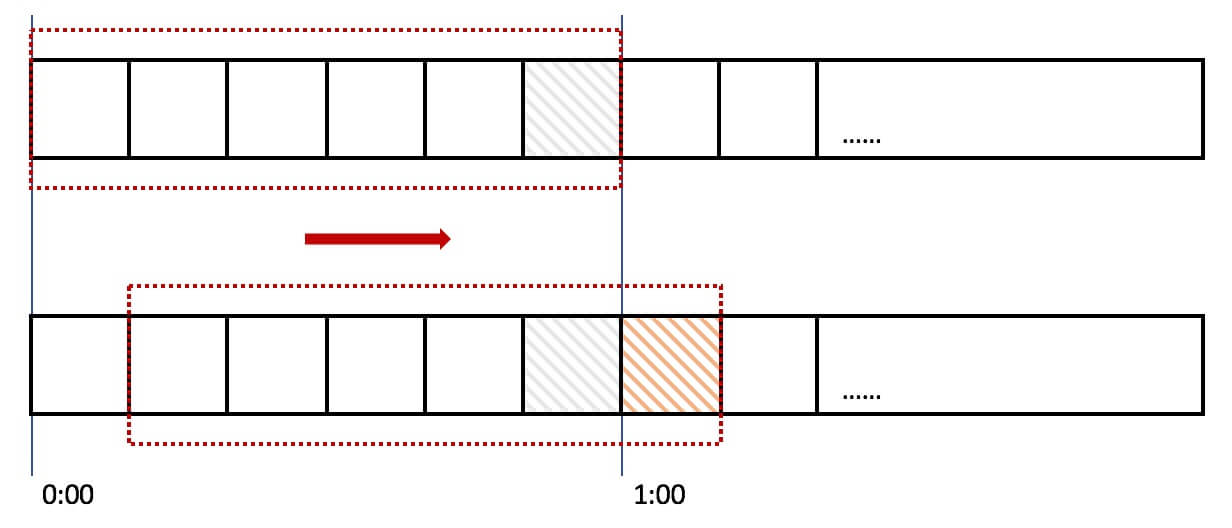
上圖中我們用紅色的虛線代表一個時間窗口(一分鐘),每個時間窗口有 6 個格子,每個格子是 10 秒鐘。每過 10 秒鐘時間窗口向右移動一格,可以看紅色箭頭的方向。我們為每個格子都設置一個獨立的計數器 Counter,假如一個請求在`0:45`訪問了那么我們將第五個格子的計數器 +1(也是就是`0:40~0:50`),在判斷限流的時候需要把所有格子的計數加起來和設定的頻次進行比較即可。
那么滑動窗口如何解決我們上面遇到的問題呢?來看下面的圖:
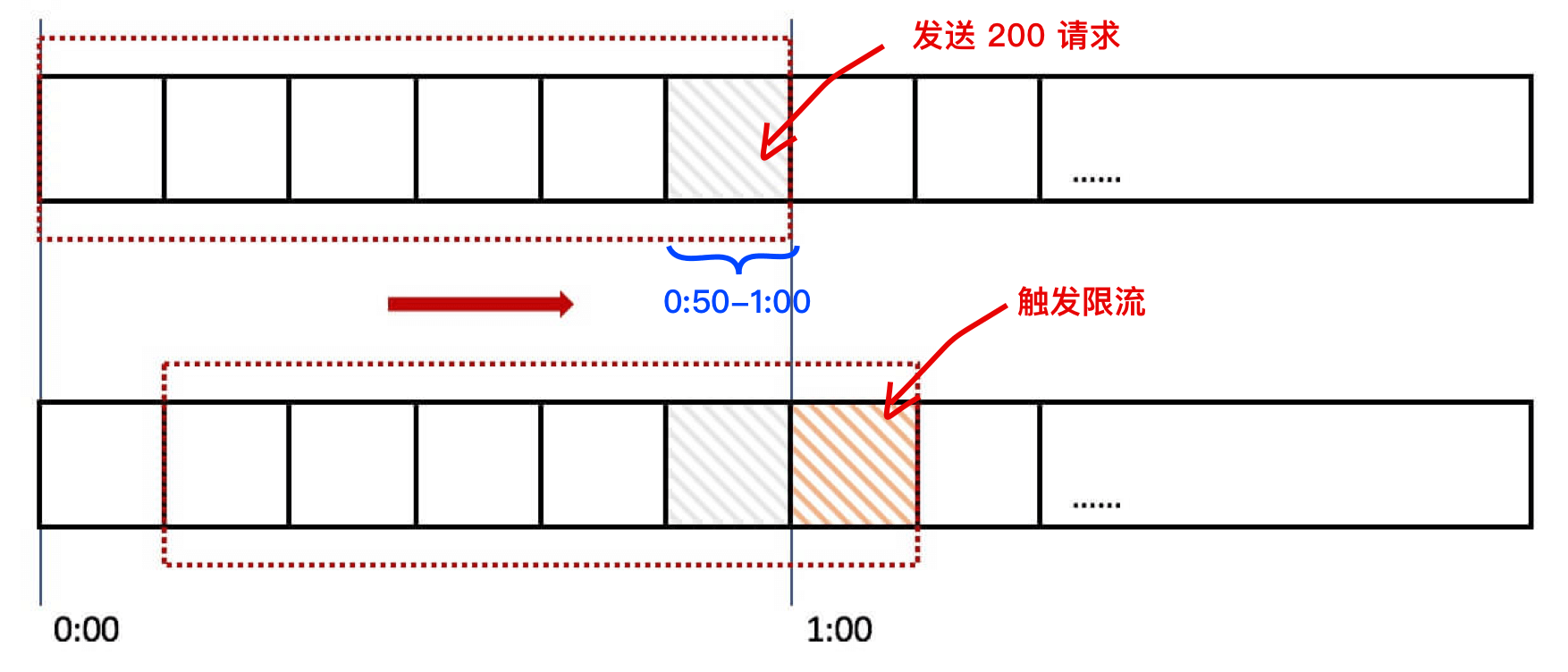
當用戶在`0:59`秒鐘發送了 200 個請求就會被第六個格子的計數器記錄 +200,當下一秒的時候時間窗口向右移動了一個,此時計數器已經記錄了該用戶發送的 200 個請求,所以再發送的話就會觸發限流,則拒絕新的請求。
通過上面的分析相信你了解什么是滑動窗口了,回想一下其實計數器就是滑動窗口啊,只不過只有一個格子而已,所以我們想讓限流做的更精確只需要劃分更多的格子就可以了,真是秒啊!為了更精確我們也不知道到底該設置多少個格子,所以又出了 2 種流行的平滑限流算法分別是漏桶算法和令牌桶算法,繼續往下看。
### 漏桶算法
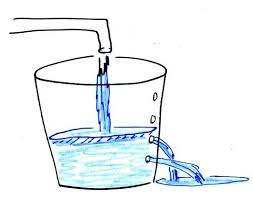
漏桶算法(Leaky Bucket)是什么呢?大家都用過水龍頭,打開龍頭開關水就會流下滴到水桶里,而漏桶指的是水桶下面有個漏洞可以出水。如果水龍頭開的特別大那么水流速就會過大,這樣就可能導致水桶的水滿了然后溢出。
而我們討論的漏桶算法的思路也很簡單,水龍頭打開后流下的水(請求)以一定的速率流到漏桶里(限流容器),漏桶以一定的速度出水(接口響應速率),如果水流速度過大(請求過多)就可能會導致漏桶的水溢出(訪問頻率超過接口響應速率),這時候我們需要關掉水龍頭(拒絕請求),下面是經典的漏桶算法圖示:
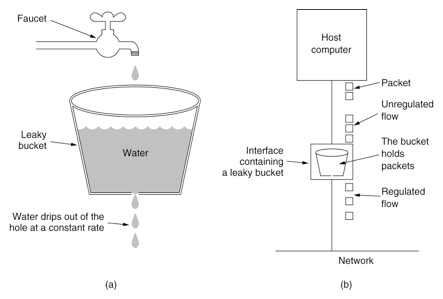
這張圖中有 2 個變量,一個是桶的大小(capacity),另一個是水桶漏洞的大小(rate),那么我們可以寫下如下代碼來實現:
```
public class LeakyDemo {
public long timeStamp = getNowTime(); // 當前時間
public int capacity; // 桶的容量
public int rate; // 水漏出的速度
public int water; // 當前水量(當前累積請求數)
public boolean grant() {
long now = getNowTime();
water = max(0, water - (now - timeStamp) * rate); // 先執行漏水,計算剩余水量
timeStamp = now;
if ((water + 1) < capacity) {
// 嘗試加水,并且水還未滿
water += 1;
return true;
} else {
// 水滿,拒絕加水
return false;
}
}
```
漏桶算法有以下特點:
* 漏桶具有固定容量,出水速率是固定常量(流出請求)
* 如果桶是空的,則不需流出水滴
* 可以以任意速率流入水滴到漏桶(流入請求)
* 如果流入水滴超出了桶的容量,則流入的水滴溢出(新請求被拒絕)
* 流入:以任意速率往桶中放入水滴。
* 流出:以固定速率從桶中流出水滴。
用白話具體說明:假設漏斗總支持并發100個最大請求,如果超過100個請求,那么會提示系統繁忙,請稍后再試,數據輸出那可以設置1個線程池,處理線程數5個,每秒處理20個請求。
缺點:因為當流出速度固定,大規模持續突發量,無法多余處理,浪費網絡帶寬
優點:無法擊垮服務
### 令牌桶算法(guava RateLimiter)
令牌桶算法(Token Bucket)是網絡流量整形(Traffic Shaping)和速率限制(Rate Limiting)中最常使用的一種算法。典型情況下,令牌桶算法用來控制發送到網絡上的數據的數目,并允許突發數據的發送。
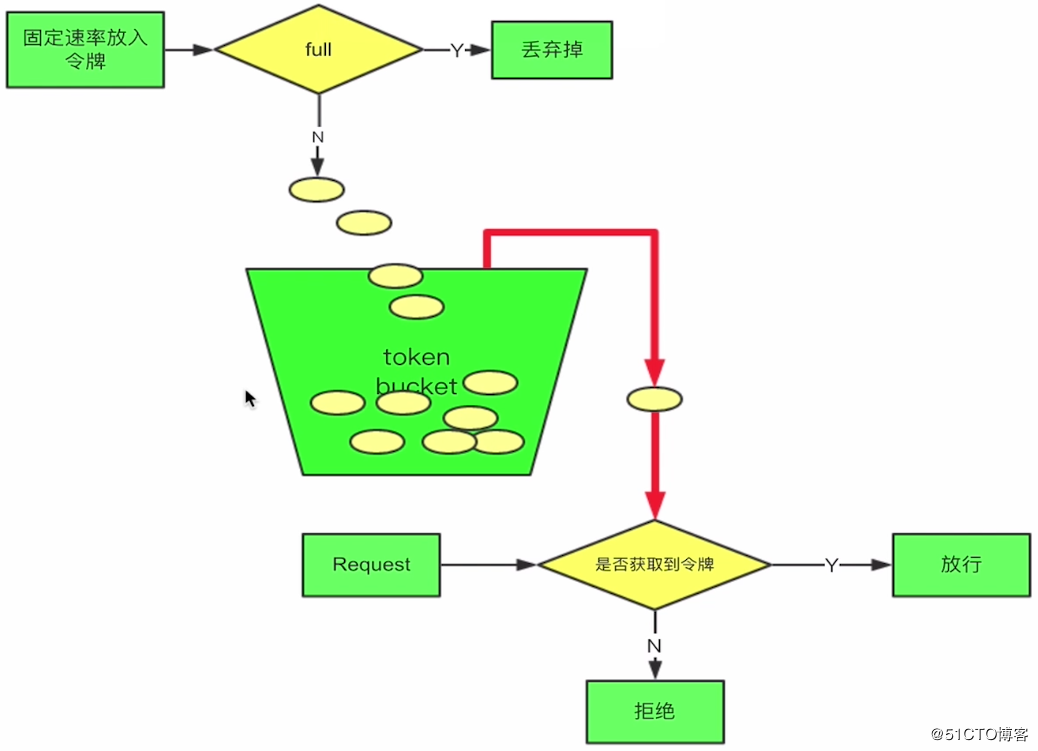
令牌桶算法和漏桶算法的方向剛好是相反的,我們有一個固定的桶,桶里存放著令牌(token)。一開始桶是空的,系統按固定的時間(rate)往桶里添加令牌,直到桶里的令牌數滿,多余的請求會被丟棄。當請求來的時候,從桶里移除一個令牌,如果桶是空的則拒絕請求或者阻塞。
```
public class TokenBucketDemo {
public long timeStamp = getNowTime(); // 當前時間
public int capacity; // 桶的容量
public int rate; // 令牌放入速度
public int tokens; // 當前令牌數量
public boolean grant() {
long now = getNowTime();
// 先添加令牌
tokens = min(capacity, tokens + (now - timeStamp) * rate);
timeStamp = now;
if (tokens < 1) {
// 若不到1個令牌,則拒絕
return false;
} else {
// 還有令牌,領取令牌
tokens -= 1;
return true;
}
}
}
```
若仔細研究算法,我們會發現我們默認從桶里移除令牌是不需要耗費時間的。如果給移除令牌設置一個延時時間,那么實際上又采用了漏桶算法的思路。Google的Guava庫下的SmoothWarmingUp類就采用了這個思路。
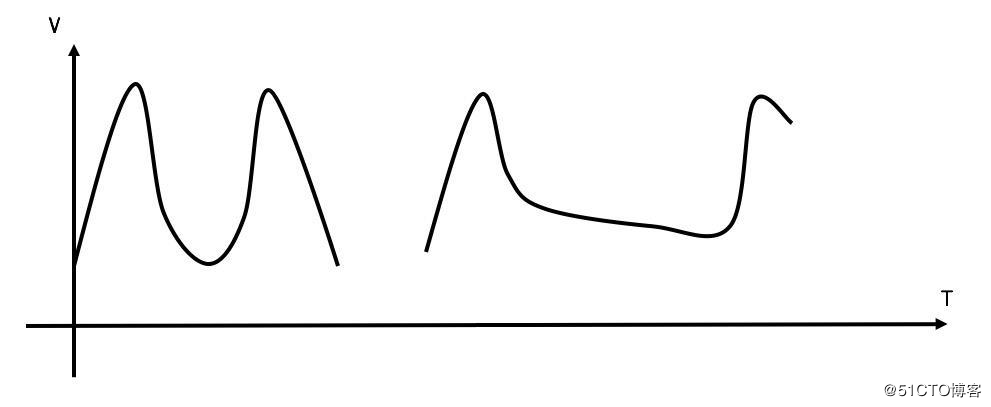
我們再來考慮一下臨界問題的場景。在0:59秒的時候,由于桶內積滿了100個token,所以這100個請求可以瞬間通過。但是由于token是以較低的速率填充的,所以在1:00的時候,桶內的token數量不可能達到100個,那么此時不可能再有100個請求通過。所以令牌桶算法可以很好地解決臨界問題。下圖比較了計數器(左)和令牌桶算法(右)在臨界點的速率變化。我們可以看到雖然令牌桶算法允許突發速率,但是下一個突發速率必須要等桶內有足夠的 token后才能發生
## 總結
計數器 VS 滑動窗口:
> 計數器算法是最簡單的算法,可以看成是滑動窗口的低精度實現。滑動窗口由于需要存儲多份的計數器(每一個格子存一份),所以滑動窗口在實現上需要更多的存儲空間。也就是說,如果滑動窗口的精度越高,需要的存儲空間就越大。
漏桶算法 VS 令牌桶算法:
> 漏桶算法和令牌桶算法最明顯的區別是令牌桶算法允許流量一定程度的突發。因為默認的令牌桶算法,取走token是不需要耗費時間的,也就是說,假設桶內有100個token時,那么可以瞬間允許100個請求通過。
* 令牌桶算法,放在服務端,用來保護服務端(自己),主要用來對調用者頻率進行限流,為的是不讓自己被壓垮。所以如果自己本身有處理能力的時候,如果流量突發(實際消費能力強于配置的流量限制=桶大小),那么實際處理速率可以超過配置的限制(桶大小)。
* 而漏桶算法,放在調用方,這是用來保護他人,也就是保護他所調用的系統。主要場景是,當調用的第三方系統本身沒有保護機制,或者有流量限制的時候,我們的調用速度不能超過他的限制,由于我們不能更改第三方系統,所以只有在主調方控制。這個時候,即使流量突發,也必須舍棄。因為消費能力是第三方決定的。
令牌桶算法由于實現簡單,且允許某些流量的突發,對用戶友好,所以被業界采用地較多。當然我們需要具體情況具體分析,只有最合適的算法,沒有最優的算法。
### RateLimiter使用示例
Google開源工具包Guava提供了限流工具類RateLimiter,該類基于令牌桶算法(Token Bucket)來完成限流,非常易于使用。RateLimiter經常用于限制對一些物理資源或者邏輯資源的訪問速率,它支持兩種獲取permits接口,一種是如果拿不到立刻返回false(`tryAcquire()`),一種會阻塞等待一段時間看能不能拿到(`tryAcquire(long timeout, TimeUnit unit)`)。
使用tryAcquire方法獲取令牌的示例代碼:
```
@Slf4j
public class RateLimiterExample1 {
/**
* 每秒鐘放入5個令牌,相當于每秒只允許執行5個請求
*/
private static final RateLimiter RATE_LIMITER = RateLimiter.create(5);
public static void main(String[] args) {
// 模擬有100個請求
for (int i = 0; i < 100; i++) {
// 嘗試從令牌桶中獲取令牌,若獲取不到則等待300毫秒看能不能獲取到
if (RATE_LIMITER.tryAcquire(300, TimeUnit.MILLISECONDS)) {
// 獲取成功,執行相應邏輯
handle(i);
}
}
}
private static void handle(int i) {
log.info("{}", i);
}
}
```
若想保證所有的請求都被執行,而不會被拋棄的話,可以選擇使用acquire方法:
```
@Slf4j
public class RateLimiterExample2 {
/**
* 每秒鐘放入5個令牌,相當于每秒只允許執行5個請求
*/
private static final RateLimiter RATE_LIMITER = RateLimiter.create(5);
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
// 從令牌桶中獲取一個令牌,若沒有獲取到會阻塞直到獲取到為止,所以所有的請求都會被執行
RATE_LIMITER.acquire();
// 獲取成功,執行相應邏輯
handle(i);
}
}
private static void handle(int i) {
log.info("{}", i);
}
```
### 集群限流
前面討論的幾種算法都屬于單機限流的范疇,但是業務需求五花八門,簡單的單機限流,根本無法滿足他們。
比如為了限制某個資源被每個用戶或者商戶的訪問次數,5s只能訪問2次,或者一天只能調用1000次,這種需求,單機限流是無法實現的,這時就需要通過集群限流進行實現。
如何實現?為了控制訪問次數,肯定需要一個計數器,而且這個計數器只能保存在第三方服務,比如redis。
大概思路:每次有相關操作的時候,就向redis服務器發送一個incr命令,比如需要限制某個用戶訪問/index接口的次數,只需要拼接用戶id和接口名生成redis的key,每次該用戶訪問此接口時,只需要對這個key執行incr命令,在這個key帶上過期時間,就可以實現指定時間的訪問頻率。
## 參考資料
> https://blog.51cto.com/zero01/2307787
> https://blog.biezhi.me/2018/10/rate-limit-algorithm.html
