
*****
## 調試和性能分析
### 用 pdb 進行代碼調試
首先,我們來看代碼的調試。也許不少人會有疑問:代碼調試?說白了不就是在程序中使用 print() 語句嗎?
<br>沒錯,在程序中相應的地方打印,的確是調試程序的一個常用手段,但這只適用于小型程序。因為你每次都得重新運行整個程序,或是一個完整的功能模塊,才能看到打印出來的變量值。如果程序不大,每次運行都非常快,那么使用 print(),的確是很方便的。
<br>可能又有人會說,現在很多的 IDE 不都有內置的 debug 工具嗎?
### 如何使用 pdb
首先,要啟動 pdb 調試,我們只需要在程序中,加入`import pdb`和`pdb.set_trace()`這兩行代碼就行了
~~~
a = 1
b = 2
import pdb
pdb.set_trace()
c = 3
print(a + b + c)
~~~
這時,我們就可以執行,在 IDE 斷點調試器中可以執行的一切操作,比如打印,語法是"p ":
~~~
(pdb) p a
1
(pdb) p b
2
~~~
除了打印,常見的操作還有“n”,表示繼續執行代碼到下一行
~~~
(pdb) n
-> print(a + b + c)
~~~
而命令`l`,則表示列舉出當前代碼行上下的 11 行源代碼,方便開發者熟悉當前斷點周圍的代碼狀態
~~~
(pdb) l
1 a = 1
2 b = 2
3 import pdb
4 pdb.set_trace()
5 -> c = 3
6 print(a + b + c)
~~~
命令“s“,就是 step into 的意思,即進入相對應的代碼內部。
<br>當然,除了這些常用命令,還有許多其他的命令可以使用
參考對應的官方文檔:[https://docs.python.org/3/library/pdb.html#module-pdb%EF%BC%89](https://docs.python.org/3/library/pdb.html#module-pdb%EF%BC%89)
## 用 cProfile 進行性能分析
關于調試的內容,我主要先講這么多。事實上,除了要對程序進行調試,性能分析也是每個開發者的必備技能。
日常工作中,我們常常會遇到這樣的問題:在線上,我發現產品的某個功能模塊效率低下,延遲高,占用的資源多,但卻不知道是哪里出了問題。
這時,對代碼進行 profile 就顯得異常重要了。
這里所謂的 profile,是指對代碼的每個部分進行動態的分析,比如準確計算出每個模塊消耗的時間等。
<br>計算斐波拉契數列,運用遞歸思想
~~~
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def fib_seq(n):
res = []
if n > 0:
res.extend(fib_seq(n-1))
res.append(fib(n))
return res
fib_seq(30)
~~~
接下來,我想要測試一下這段代碼總的效率以及各個部分的效率
~~~
import cProfile
cProfile.run('fib_seq(30)')
~~~
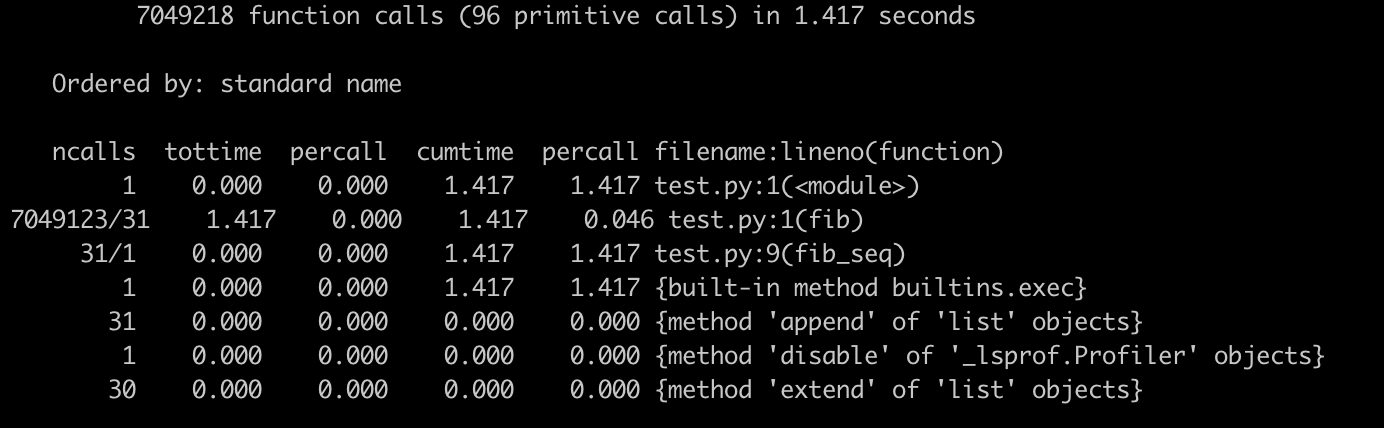
參數介紹:
* ncalls,是指相應代碼 / 函數被調用的次數
* tottime,是指對應代碼 / 函數總共執行所需要的時間(注意,并不包括它調用的其他代碼 / 函數的執行時間)
* tottime percall,就是上述兩者相除的結果,也就是tottime / ncalls
* cumtime,則是指對應代碼 / 函數總共執行所需要的時間,這里包括了它調用的其他代碼 / 函數的執行時間
* cumtime percall,則是 cumtime 和 ncalls 相除的平均結果。
