前三章從 job 的角度介紹了用戶寫的 program 如何一步步地被分解和執行。這一章主要從架構的角度來討論 master,worker,driver 和 executor 之間怎么協調來完成整個 job 的運行。
> 實在不想在文檔中貼過多的代碼,這章貼這么多,只是為了方面自己回頭 debug 的時候可以迅速定位,不想看代碼的話,直接看圖和描述即可。
## 部署圖
重新貼一下 Overview 中給出的部署圖:
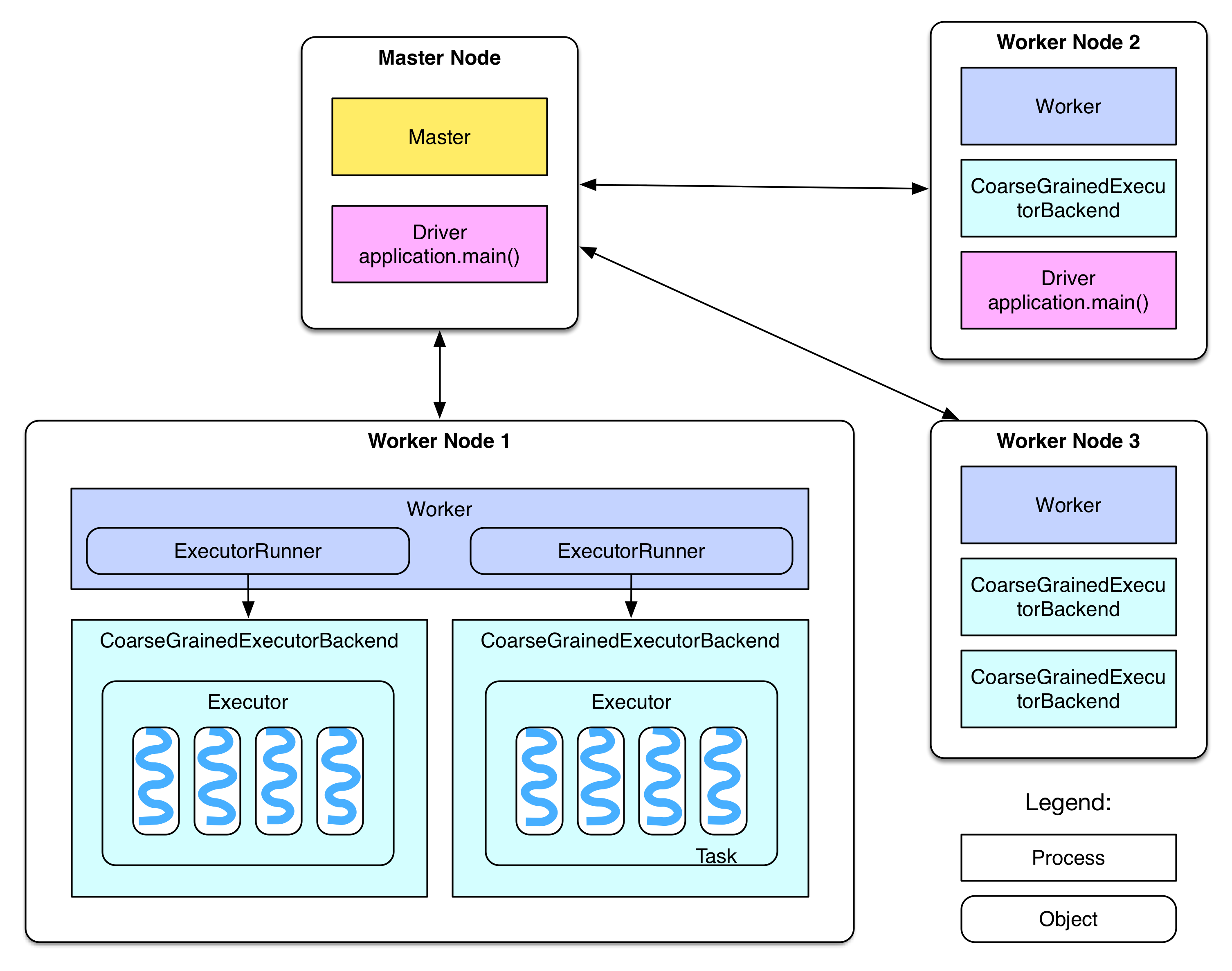
接下來分階段討論并細化這個圖。
## Job 提交
下圖展示了driver program(假設在 master node 上運行)如何生成 job,并提交到 worker node 上執行。
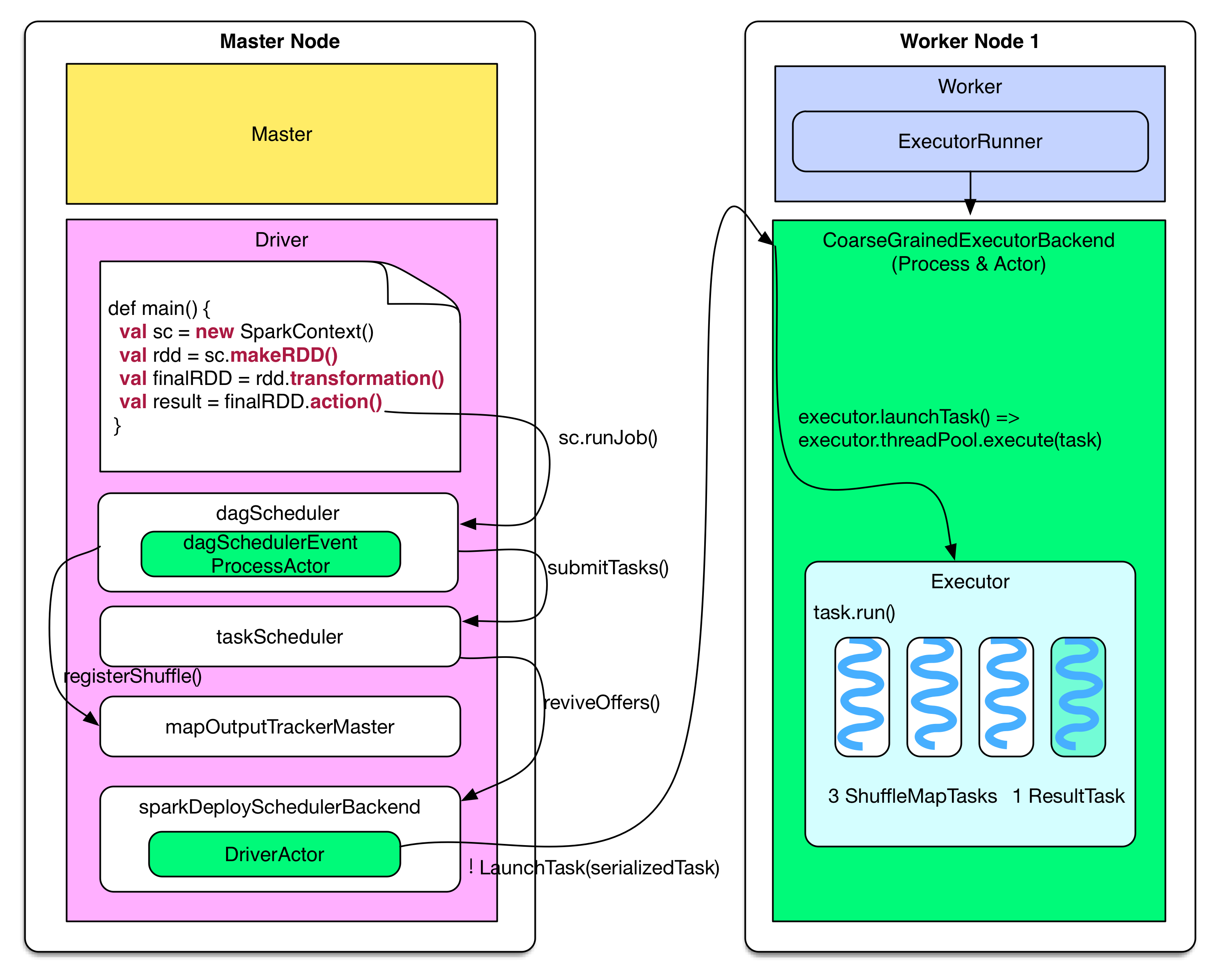
Driver 端的邏輯如果用代碼表示:
~~~
finalRDD.action()
=> sc.runJob()
// generate job, stages and tasks
=> dagScheduler.runJob()
=> dagScheduler.submitJob()
=> dagSchedulerEventProcessActor ! JobSubmitted
=> dagSchedulerEventProcessActor.JobSubmitted()
=> dagScheduler.handleJobSubmitted()
=> finalStage = newStage()
=> mapOutputTracker.registerShuffle(shuffleId, rdd.partitions.size)
=> dagScheduler.submitStage()
=> missingStages = dagScheduler.getMissingParentStages()
=> dagScheduler.subMissingTasks(readyStage)
// add tasks to the taskScheduler
=> taskScheduler.submitTasks(new TaskSet(tasks))
=> fifoSchedulableBuilder.addTaskSetManager(taskSet)
// send tasks
=> sparkDeploySchedulerBackend.reviveOffers()
=> driverActor ! ReviveOffers
=> sparkDeploySchedulerBackend.makeOffers()
=> sparkDeploySchedulerBackend.launchTasks()
=> foreach task
CoarseGrainedExecutorBackend(executorId) ! LaunchTask(serializedTask)
~~~
代碼的文字描述:
當用戶的 program 調用?`val sc = new SparkContext(sparkConf)`?時,這個語句會幫助 program 啟動諸多有關 driver 通信、job 執行的對象、線程、actor等,**該語句確立了 program 的 driver 地位。**
### 生成 Job 邏輯執行圖
Driver program 中的 transformation() 建立 computing chain(一系列的 RDD),每個 RDD 的 compute() 定義數據來了怎么計算得到該 RDD 中 partition 的結果,getDependencies() 定義 RDD 之間 partition 的數據依賴。
### 生成 Job 物理執行圖
每個 action() 觸發生成一個 job,在 dagScheduler.runJob() 的時候進行 stage 劃分,在 submitStage() 的時候生成該 stage 包含的具體的 ShuffleMapTasks 或者 ResultTasks,然后將 tasks 打包成 TaskSet 交給 taskScheduler,如果 taskSet 可以運行就將 tasks 交給 sparkDeploySchedulerBackend 去分配執行。
### 分配 Task
sparkDeploySchedulerBackend 接收到 taskSet 后,會通過自帶的 DriverActor 將 serialized tasks 發送到調度器指定的 worker node 上的 CoarseGrainedExecutorBackend Actor上。
## Job 接收
Worker 端接收到 tasks 后,執行如下操作
~~~
coarseGrainedExecutorBackend ! LaunchTask(serializedTask)
=> executor.launchTask()
=> executor.threadPool.execute(new TaskRunner(taskId, serializedTask))
~~~
**executor 將 task 包裝成 taskRunner,并從線程池中抽取出一個空閑線程運行 task。一個 CoarseGrainedExecutorBackend 進程有且僅有一個 executor 對象。**
## Task 運行
下圖展示了 task 被分配到 worker node 上后的執行流程及 driver 如何處理 task 的 result。
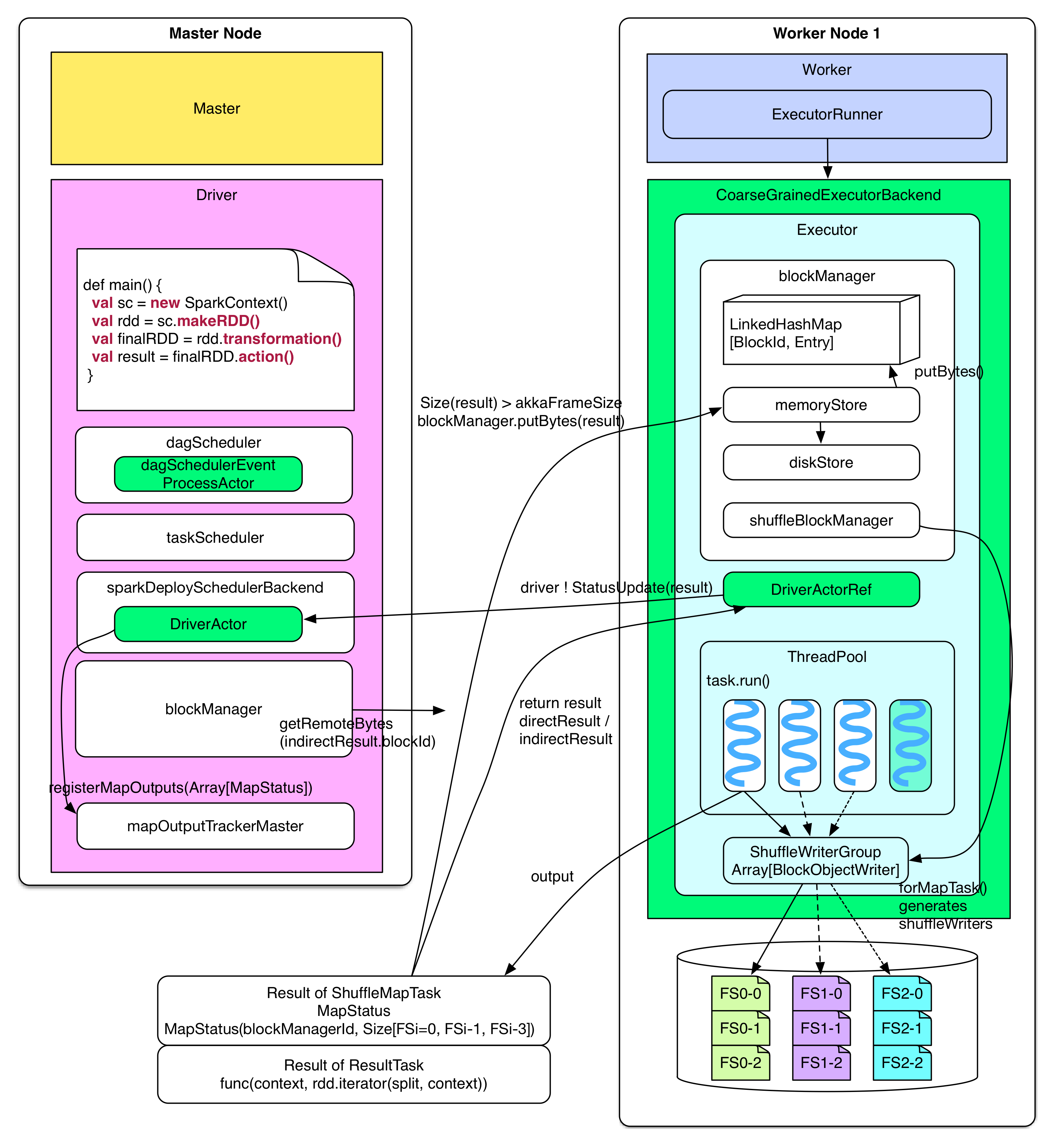
Executor 收到 serialized 的 task 后,先 deserialize 出正常的 task,然后運行 task 得到其執行結果 directResult,這個結果要送回到 driver 那里。但是通過 Actor 發送的數據包不易過大,**如果 result 比較大(比如 groupByKey 的 result)先把 result 存放到本地的“內存+磁盤”上,由 blockManager 來管理,只把存儲位置信息(indirectResult)發送給 driver**,driver 需要實際的 result 的時候,會通過 HTTP 去 fetch。如果 result 不大(小于`spark.akka.frameSize = 10MB`),那么直接發送給 driver。
上面的描述還有一些細節:如果 task 運行結束生成的 directResult > akka.frameSize,directResult 會被存放到由 blockManager 管理的本地“內存+磁盤”上。**BlockManager 中的 memoryStore 開辟了一個 LinkedHashMap 來存儲要存放到本地內存的數據。**LinkedHashMap 存儲的數據總大小不超過`Runtime.getRuntime.maxMemory * spark.storage.memoryFraction(default 0.6)`?。如果 LinkedHashMap 剩余空間不足以存放新來的數據,就將數據交給 diskStore 存放到磁盤上,但前提是該數據的 storageLevel 中包含“磁盤”。
~~~
In TaskRunner.run()
// deserialize task, run it and then send the result to
=> coarseGrainedExecutorBackend.statusUpdate()
=> task = ser.deserialize(serializedTask)
=> value = task.run(taskId)
=> directResult = new DirectTaskResult(ser.serialize(value))
=> if( directResult.size() > akkaFrameSize() )
indirectResult = blockManager.putBytes(taskId, directResult, MEMORY+DISK+SER)
else
return directResult
=> coarseGrainedExecutorBackend.statusUpdate(result)
=> driver ! StatusUpdate(executorId, taskId, result)
~~~
ShuffleMapTask 和 ResultTask 生成的 result 不一樣。**ShuffleMapTask 生成的是 MapStatus**,MapStatus 包含兩項內容:一是該 task 所在的 BlockManager 的 BlockManagerId(實際是 executorId + host, port, nettyPort),二是 task 輸出的每個 FileSegment 大小。**ResultTask 生成的 result 的是 func 在 partition 上的執行結果。**比如 count() 的 func 就是統計 partition 中 records 的個數。由于 ShuffleMapTask 需要將 FileSegment 寫入磁盤,因此需要輸出流 writers,這些 writers 是由 blockManger 里面的 shuffleBlockManager 產生和控制的。
~~~
In task.run(taskId)
// if the task is ShuffleMapTask
=> shuffleMapTask.runTask(context)
=> shuffleWriterGroup = shuffleBlockManager.forMapTask(shuffleId, partitionId, numOutputSplits)
=> shuffleWriterGroup.writers(bucketId).write(rdd.iterator(split, context))
=> return MapStatus(blockManager.blockManagerId, Array[compressedSize(fileSegment)])
//If the task is ResultTask
=> return func(context, rdd.iterator(split, context))
~~~
Driver 收到 task 的執行結果 result 后會進行一系列的操作:首先告訴 taskScheduler 這個 task 已經執行完,然后去分析 result。由于 result 可能是 indirectResult,需要先調用 blockManager.getRemoteBytes() 去 fech 實際的 result,這個過程下節會詳解。得到實際的 result 后,需要分情況分析,**如果是 ResultTask 的 result,那么可以使用 ResultHandler 對 result 進行 driver 端的計算(比如 count() 會對所有 ResultTask 的 result 作 sum)**,如果 result 是 ShuffleMapTask 的 MapStatus,那么需要將 MapStatus(ShuffleMapTask 輸出的 FileSegment 的位置和大小信息)**存放到 mapOutputTrackerMaster 中的 mapStatuses 數據結構中以便以后 reducer shuffle 的時候查詢**。如果 driver 收到的 task 是該 stage 中的最后一個 task,那么可以 submit 下一個 stage,如果該 stage 已經是最后一個 stage,那么告訴 dagScheduler job 已經完成。
~~~
After driver receives StatusUpdate(result)
=> taskScheduler.statusUpdate(taskId, state, result.value)
=> taskResultGetter.enqueueSuccessfulTask(taskSet, tid, result)
=> if result is IndirectResult
serializedTaskResult = blockManager.getRemoteBytes(IndirectResult.blockId)
=> scheduler.handleSuccessfulTask(taskSetManager, tid, result)
=> taskSetManager.handleSuccessfulTask(tid, taskResult)
=> dagScheduler.taskEnded(result.value, result.accumUpdates)
=> dagSchedulerEventProcessActor ! CompletionEvent(result, accumUpdates)
=> dagScheduler.handleTaskCompletion(completion)
=> Accumulators.add(event.accumUpdates)
// If the finished task is ResultTask
=> if (job.numFinished == job.numPartitions)
listenerBus.post(SparkListenerJobEnd(job.jobId, JobSucceeded))
=> job.listener.taskSucceeded(outputId, result)
=> jobWaiter.taskSucceeded(index, result)
=> resultHandler(index, result)
// if the finished task is ShuffleMapTask
=> stage.addOutputLoc(smt.partitionId, status)
=> if (all tasks in current stage have finished)
mapOutputTrackerMaster.registerMapOutputs(shuffleId, Array[MapStatus])
mapStatuses.put(shuffleId, Array[MapStatus]() ++ statuses)
=> submitStage(stage)
~~~
## Shuffle read
上一節描述了 task 運行過程及 result 的處理過程,這一節描述 reducer(需要 shuffle 的 task )是如何獲取到輸入數據的。關于 reducer 如何處理輸入數據已經在上一章的 shuffle read 中解釋了。
**問題:reducer 怎么知道要去哪里 fetch 數據?**
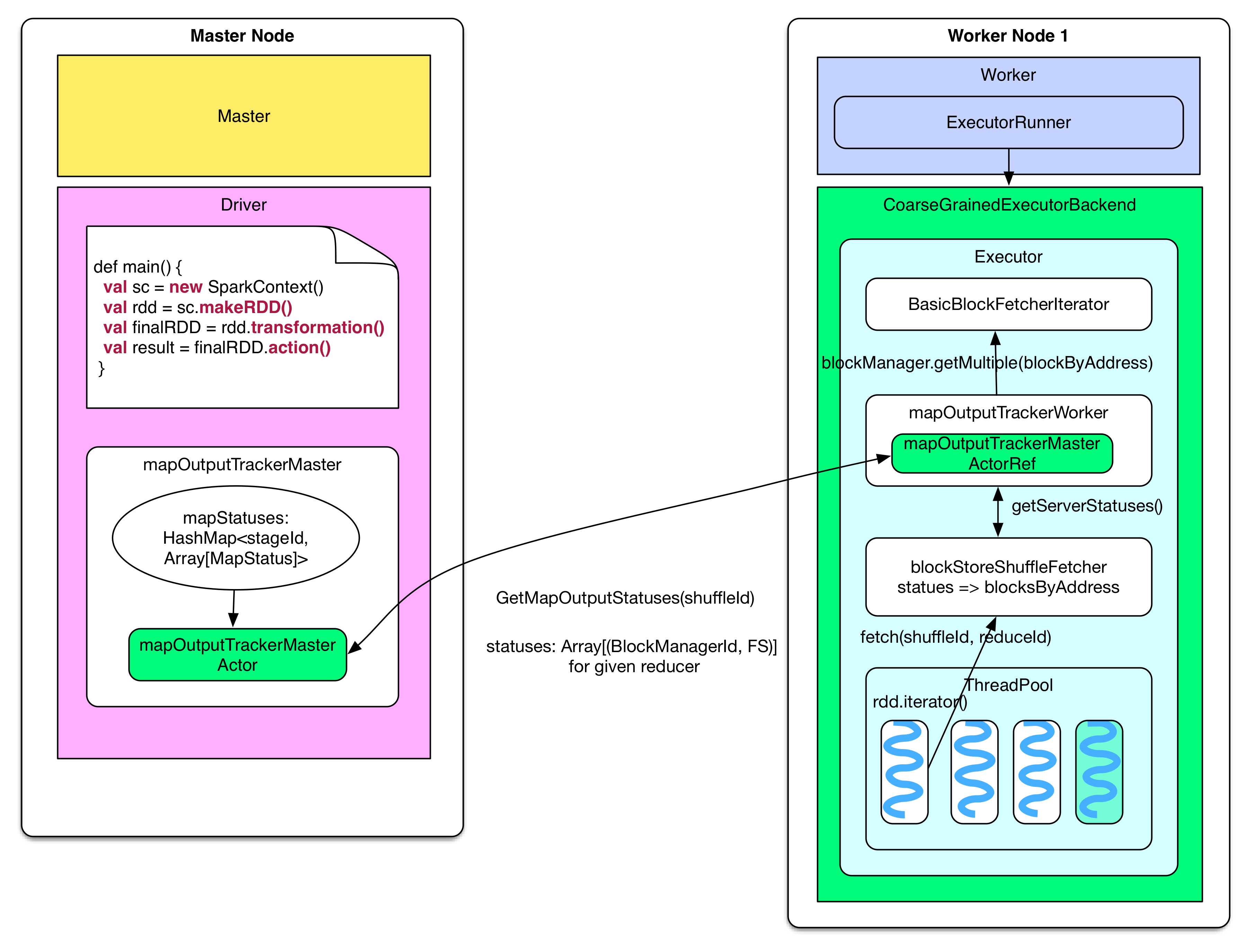reducer 首先要知道 parent stage 中 ShuffleMapTask 輸出的 FileSegments 在哪個節點。**這個信息在 ShuffleMapTask 完成時已經送到了 driver 的 mapOutputTrackerMaster,并存放到了 mapStatuses: HashMap?里面**,給定 stageId,可以獲取該 stage 中 ShuffleMapTasks 生成的 FileSegments 信息 Array[MapStatus],通過 Array(taskId) 就可以得到某個 task 輸出的 FileSegments 位置(blockManagerId)及每個 FileSegment 大小。
當 reducer 需要 fetch 輸入數據的時候,會首先調用 blockStoreShuffleFetcher 去獲取輸入數據(FileSegments)的位置。blockStoreShuffleFetcher 通過調用本地的 MapOutputTrackerWorker 去完成這個任務,MapOutputTrackerWorker 使用 mapOutputTrackerMasterActorRef 來與 mapOutputTrackerMasterActor 通信獲取 MapStatus 信息。blockStoreShuffleFetcher 對獲取到的 MapStatus 信息進行加工,提取出該 reducer 應該去哪些節點上獲取哪些 FileSegment 的信息,這個信息存放在 blocksByAddress 里面。之后,blockStoreShuffleFetcher 將獲取 FileSegment 數據的任務交給 basicBlockFetcherIterator。
~~~
rdd.iterator()
=> rdd(e.g., ShuffledRDD/CoGroupedRDD).compute()
=> SparkEnv.get.shuffleFetcher.fetch(shuffledId, split.index, context, ser)
=> blockStoreShuffleFetcher.fetch(shuffleId, reduceId, context, serializer)
=> statuses = MapOutputTrackerWorker.getServerStatuses(shuffleId, reduceId)
=> blocksByAddress: Seq[(BlockManagerId, Seq[(BlockId, Long)])] = compute(statuses)
=> basicBlockFetcherIterator = blockManager.getMultiple(blocksByAddress, serializer)
=> itr = basicBlockFetcherIterator.flatMap(unpackBlock)
~~~
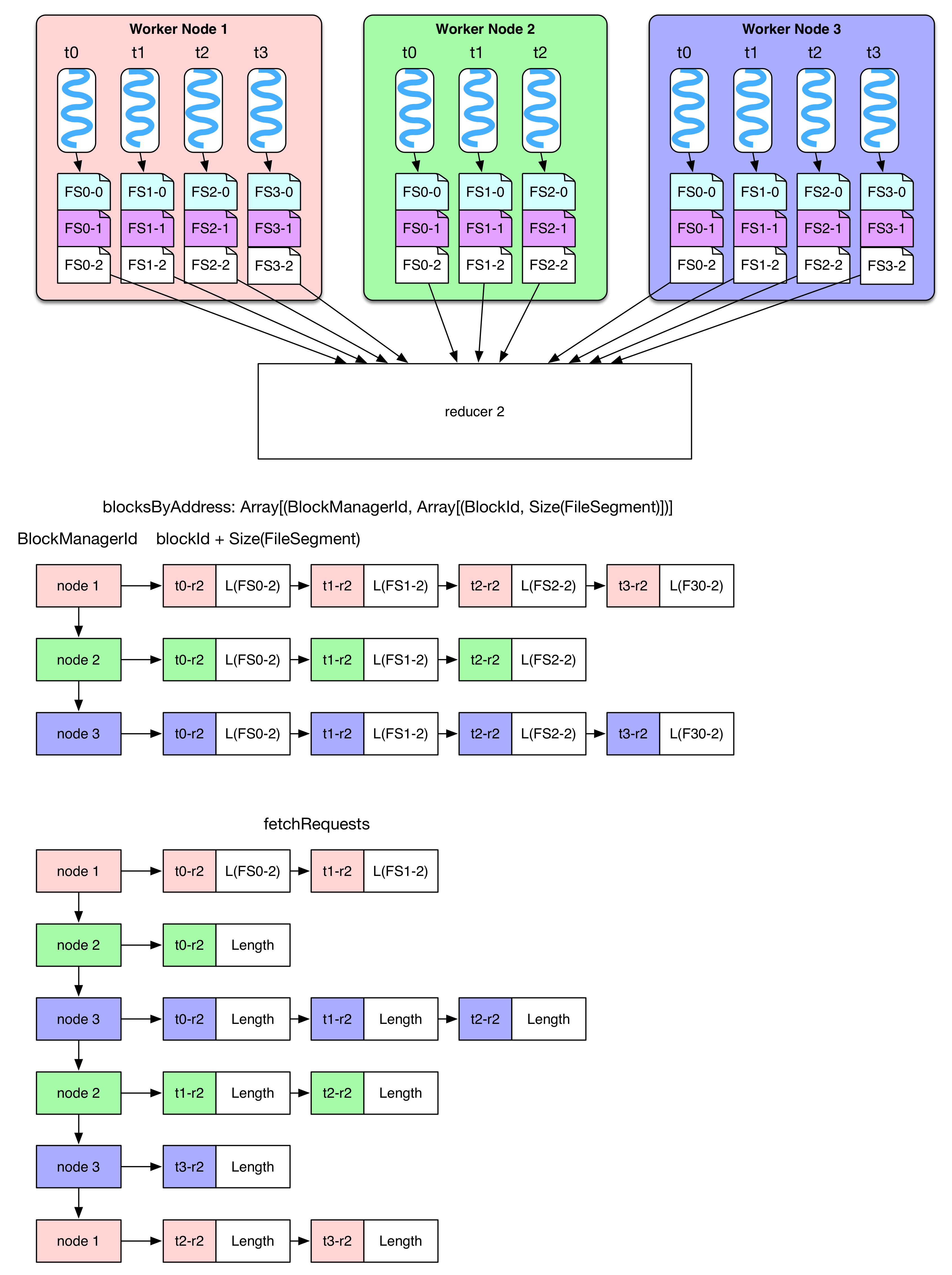
basicBlockFetcherIterator 收到獲取數據的任務后,會生成一個個 fetchRequest,**每個 fetchRequest 包含去某個節點獲取若干個 FileSegments 的任務。**圖中展示了 reducer-2 需要從三個 worker node 上獲取所需的白色 FileSegment (FS)。總的數據獲取任務由 blocksByAddress 表示,要從第一個 node 獲取 4 個,從第二個 node 獲取 3 個,從第三個 node 獲取 4 個。
為了加快任務獲取過程,顯然要將總任務劃分為子任務(fetchRequest),然后為每個任務分配一個線程去 fetch。Spark 為每個 reducer 啟動 5 個并行 fetch 的線程(Hadoop 也是默認啟動 5 個)。由于 fetch 來的數據會先被放到內存作緩沖,因此一次 fetch 的數據不能太多,Spark 設定不能超過`spark.reducer.maxMbInFlight=48MB`。**注意這 48MB 的空間是由這 5 個 fetch 線程共享的**,因此在劃分子任務時,盡量使得 fetchRequest 不超過`48MB / 5 = 9.6MB`。如圖在 node 1 中,Size(FS0-2) + Size(FS1-2) 9.6MB,因此要在 t1-r2 和 t2-r2 處斷開,所以圖中有兩個 fetchRequest 都是要去 node 1 fetch。**那么會不會有 fetchRequest 超過 9.6MB?**當然會有,如果某個 FileSegment 特別大,仍然需要一次性將這個 FileSegment fetch 過來。另外,如果 reducer 需要的某些 FileSegment 就在本節點上,那么直接進行 local read。最后,將 fetch 來的 FileSegment 進行 deserialize,將里面的 records 以 iterator 的形式提供給 rdd.compute(),整個 shuffle read 結束。
~~~
In basicBlockFetcherIterator:
// generate the fetch requests
=> basicBlockFetcherIterator.initialize()
=> remoteRequests = splitLocalRemoteBlocks()
=> fetchRequests ++= Utils.randomize(remoteRequests)
// fetch remote blocks
=> sendRequest(fetchRequests.dequeue()) until Size(fetchRequests) > maxBytesInFlight
=> blockManager.connectionManager.sendMessageReliably(cmId,
blockMessageArray.toBufferMessage)
=> fetchResults.put(new FetchResult(blockId, sizeMap(blockId)))
=> dataDeserialize(blockId, blockMessage.getData, serializer)
// fetch local blocks
=> getLocalBlocks()
=> fetchResults.put(new FetchResult(id, 0, () => iter))
~~~
下面再討論一些細節問題:
**reducer 如何將 fetchRequest 信息發送到目標節點?目標節點如何處理 fetchRequest 信息,如何讀取 FileSegment 并回送給 reducer?**
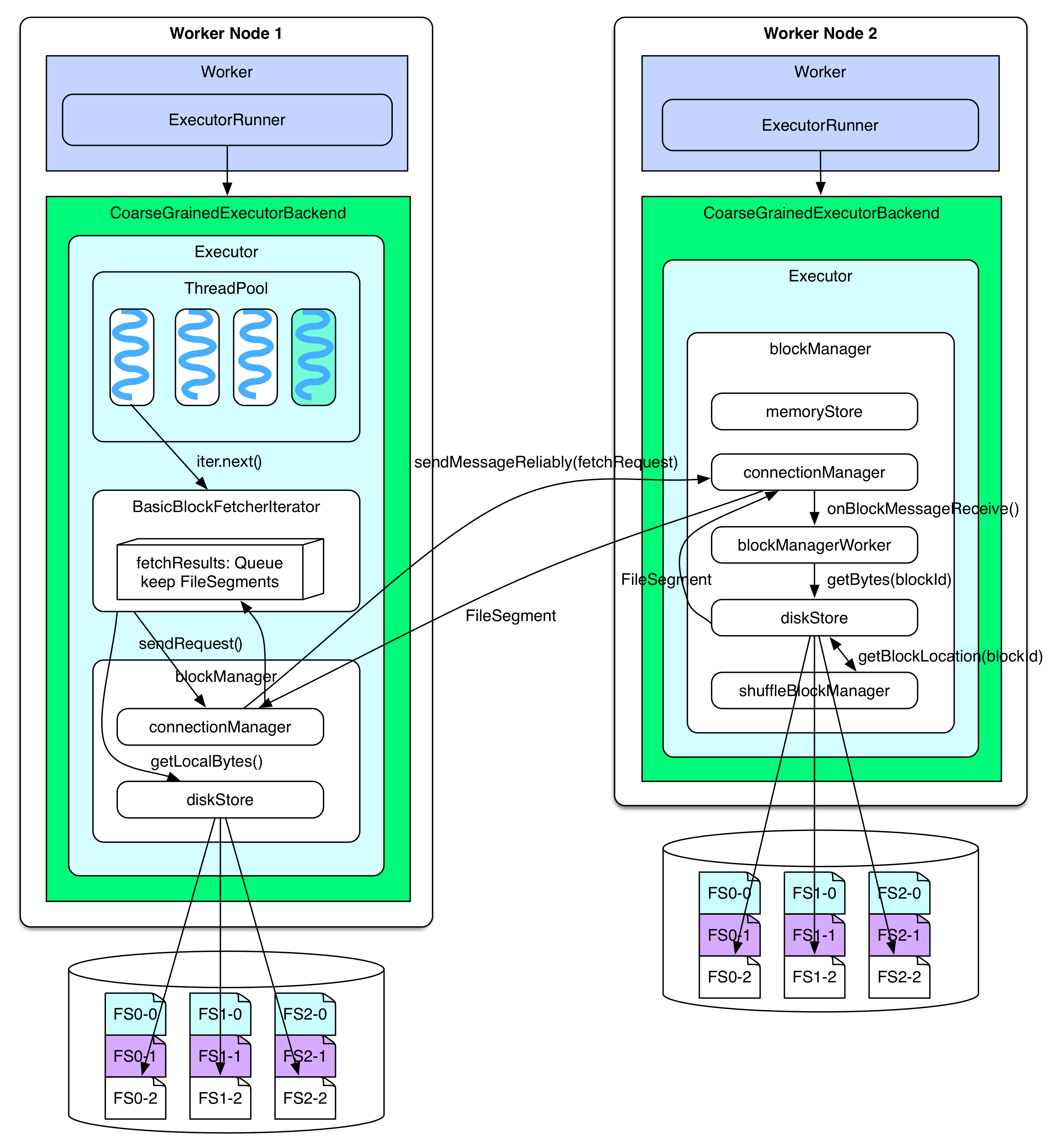
rdd.iterator() 碰到 ShuffleDependency 時會調用 BasicBlockFetcherIterator 去獲取 FileSegments。BasicBlockFetcherIterator 使用 blockManager 中的 connectionManager 將 fetchRequest 發送給其他節點的 connectionManager。connectionManager 之間使用 NIO 模式通信。其他節點,比如 worker node 2 上的 connectionManager 收到消息后,會交給 blockManagerWorker 處理,blockManagerWorker 使用 blockManager 中的 diskStore 去本地磁盤上讀取 fetchRequest 要求的 FileSegments,然后仍然通過 connectionManager 將 FileSegments 發送回去。如果使用了 FileConsolidation,diskStore 還需要 shuffleBlockManager 來提供 blockId 所在的具體位置。如果 FileSegment 不超過`spark.storage.memoryMapThreshold=8KB`?,那么 diskStore 在讀取 FileSegment 的時候會直接將 FileSegment 放到內存中,否則,會使用 RandomAccessFile 中 FileChannel 的內存映射方法來讀取 FileSegment(這樣可以將大的 FileSegment 加載到內存)。
當 BasicBlockFetcherIterator 收到其他節點返回的 serialized FileSegments 后會將其放到 fetchResults: Queue 里面,并進行 deserialization,所以?**fetchResults: Queue 就相當于在 Shuffle details 那一章提到的 softBuffer。**如果 BasicBlockFetcherIterator 所需的某些 FileSegments 就在本地,會通過 diskStore 直接從本地文件讀取,并放到 fetchResults 里面。最后 reducer 一邊從 FileSegment 中邊讀取 records 一邊處理。
~~~
After the blockManager receives the fetch request
=> connectionManager.receiveMessage(bufferMessage)
=> handleMessage(connectionManagerId, message, connection)
// invoke blockManagerWorker to read the block (FileSegment)
=> blockManagerWorker.onBlockMessageReceive()
=> blockManagerWorker.processBlockMessage(blockMessage)
=> buffer = blockManager.getLocalBytes(blockId)
=> buffer = diskStore.getBytes(blockId)
=> fileSegment = diskManager.getBlockLocation(blockId)
=> shuffleManager.getBlockLocation()
=> if(fileSegment < minMemoryMapBytes)
buffer = ByteBuffer.allocate(fileSegment)
else
channel.map(MapMode.READ_ONLY, segment.offset, segment.length)
~~~
每個 reducer 都持有一個 BasicBlockFetcherIterator,一個 BasicBlockFetcherIterator 理論上可以持有 48MB 的 fetchResults。每當 fetchResults 中有一個 FileSegment 被讀取完,就會一下子去 fetch 很多個 FileSegment,直到 48MB 被填滿。
~~~
BasicBlockFetcherIterator.next()
=> result = results.task()
=> while (!fetchRequests.isEmpty &&
(bytesInFlight == 0 || bytesInFlight + fetchRequests.front.size <= maxBytesInFlight)) {
sendRequest(fetchRequests.dequeue())
}
=> result.deserialize()
~~~
## Discussion
這一章寫了三天,也是我這個月來心情最不好的幾天。Anyway,繼續總結。
架構部分其實沒有什么好說的,就是設計時盡量功能獨立,模塊獨立,松耦合。BlockManager 設計的不錯,就是管的東西太多(數據塊、內存、磁盤、通信)。
這一章主要探討了系統中各個模塊是怎么協同來完成 job 的生成、提交、運行、結果收集、結果計算以及 shuffle 的。貼了很多代碼,也畫了很多圖,雖然細節很多,但遠沒有達到源碼的細致程度。如果有地方不明白的,請根據描述閱讀一下源碼吧。
如果想進一步了解 blockManager,可以參閱 Jerry Shao 寫的?[Spark源碼分析之-Storage模塊](http://jerryshao.me/architecture/2013/10/08/spark-storage-module-analysis/)。
