awk是什么?awk是一個**報表生成器**,擁有強大的文本格式化的能力。我們可以利用awk來處理文本,整理成各種“表”的樣子。
awk 是由 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 三個創造者的姓氏的首個字母組成,早期應用于Unix上,所以我們現在使用的Linux版的awk其實是gawk,也就是GNU awk。
awk其實是一門腳本語言,它支持條件判斷、數組、循環等功能
事實上,grep 、sed、awk 被稱為 linux 中的 "三劍客"。
* grep 適合單純的查找或匹配文本
* sed 適合編輯匹配到的文本
* awk 適合格式化文本,對文本進行較復雜格式處理
## awk基礎
awk的基本語法如下,
~~~
awk [options] 'program' file1 , file2 , ……
~~~
其中program也可以細分為pattern和action,也就是說
~~~
awk [options] 'Pattern{Action}' file
~~~
action 指的就是動作,awk 擅長文本格式化,并且將格式化以后的文本輸出,所以 awk 最常用的動作就是 print 和 printf
比如testd文件中含有"ddd"三個字符
那么使用`awk '{print}' testd`,就會返回`ddd`
下面我們可以看另一個場景:
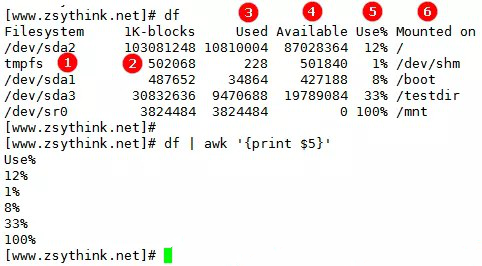
其中`awk '{print $5}'`表示輸出df信息的第5列,$5表示將當前行按照**分隔符**分隔后的第5列,默認指定空格為分隔符。
另外awk自動將**連續的**空格理解為一個分隔符。
awk是逐行處理的,也就是當awk處理一個文本的時候,會一行一行的處理,默認以“換行符”為標記。

> $0表示顯示整行,$NF表示當前行分割后的最后一列,NF表示當前行被分割開以后,一共有幾個字段。也就是說,如果一行文本給空格分成了7段,那么NF的值就是7,$NF的值就是$7,而$7表示當前行的第7個字段,也就是最后一列,那么倒數第二列就是$(NF-1)
我們也可以一次輸出多列,使用**逗號**進行隔開
~~~
awk '{print $1,$2}' test
~~~
如果某一行沒有第2列,則第2列不會有輸出。
除了輸出文本的列,我們還可以添加的字段,與文件中的列結合起來。

## Pattern
之前介紹了最常用的Action,也就是print。
下面我們來介紹一下Pattern,也就是模式。
AWK 包含兩種特殊的模式:BEGIN 和 END。
* BEGIN 模式:指定了處理文本之**前**需要執行的操作:
* END 模式:指定了處理完所有行之**后**所需要執行的操作:

也就是表示在處理test文件之前,先執行打印動作。既然還沒開始處理test中的文本,也可以不指定test文件
如果我們想awk先執行BEGIN指定的動作,然后再根據我們自定義的動作去操作文本,

上圖中先打印出了 "aaa bbb",當 BEGIN 模式對應的動作完成后,在使用后面的動作處理對應的文本,即打印 test 文件中的第一列與第二列
