# 04 序列化介紹以及序列化協議選擇
## 1. 序列化和反序列化相關概念
### 1.1. 什么是序列化?什么是反序列化?
如果我們需要持久化Java對象比如將Java對象保存在文件中,或者在網絡傳輸Java對象,這些場景都需要用到序列化。
簡單來說:
- **序列化**: 將數據結構或對象轉換成二進制字節流的過程
- **反序列化**:將在序列化過程中所生成的二進制字節流的過程轉換成數據結構或者對象的過程
對于Java這種面向對象編程語言來說,我們序列化的都是對象(Object)也就是實例化后的類(Class),但是在C++這種半面向對象的語言中,struct(結構體)定義的是數據結構類型,而class 對應的是對象類型。
維基百科是如是介紹序列化的:
> **序列化**(serialization)在計算機科學的數據處理中,是指將數據結構或對象狀態轉換成可取用格式(例如存成文件,存于緩沖,或經由網絡中發送),以留待后續在相同或另一臺計算機環境中,能恢復原先狀態的過程。依照序列化格式重新獲取字節的結果時,可以利用它來產生與原始對象相同語義的副本。對于許多對象,像是使用大量引用的復雜對象,這種序列化重建的過程并不容易。面向對象中的對象序列化,并不概括之前原始對象所關系的函數。這種過程也稱為對象編組(marshalling)。從一系列字節提取數據結構的反向操作,是反序列化(也稱為解編組、deserialization、unmarshalling)。
綜上:**序列化的主要目的是通過網絡傳輸對象或者說是將對象存儲到文件系統、數據庫、內存中。**
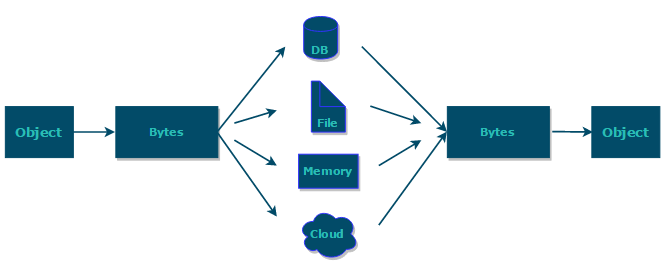
<p style="text-align:right;font-size:13px;color:gray">https://www.corejavaguru.com/java/serialization/interview-questions-1</p>
### 1.2. 實際開發中有哪些用到序列化和反序列化的場景
1. 對象在進行網絡傳輸(比如遠程方法調用RPC的時候)之前需要先被序列化,接收到序列化的對象之后需要再進行反序列化;
2. 將對象存儲到文件中的時候需要進行序列化,將對象從文件中讀取出來需要進行反序列化。
3. 將對象存儲到緩存數據庫(如 Redis)時需要用到序列化,將對象從緩存數據庫中讀取出來需要反序列化。
### 1.3. 序列化協議對應于TCP/IP 4層模型的哪一層?
我們知道網絡通信的雙方必須要采用和遵守相同的協議。TCP/IP 四層模型是下面這樣的,序列化協議屬于哪一層呢?
1. 應用層
2. 傳輸層
3. 網絡層
4. 網絡接口層
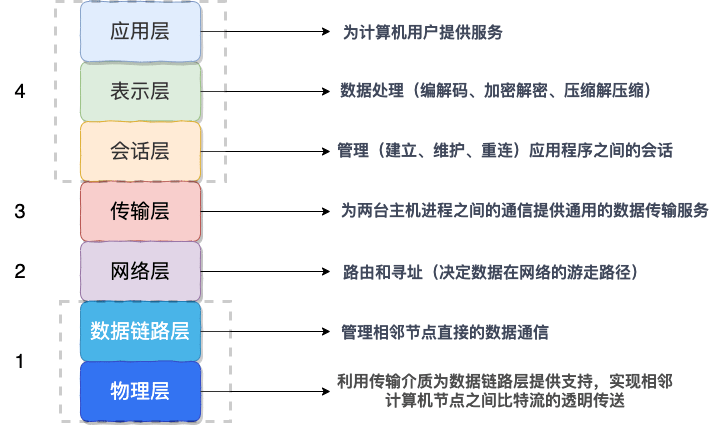
如上圖所示,OSI七層協議模型中,表示層做的事情主要就是對應用層的用戶數據進行處理轉換為二進制流。反過來的話,就是將二進制流轉換成應用層的用戶數據。這不就對應的是序列化和反序列化么?
因為,OSI七層協議模型中的應用層、表示層和會話層對應的都是TCP/IP 四層模型中的應用層,所以序列化協議屬于TCP/IP協議應用層的一部分。
## 2. 常見序列化協議對比
JDK自帶的序列化方式一般不會用 ,因為序列化效率低并且部分版本有安全漏洞。比較常用的序列化協議有 hessian、kyro、protostuff。
下面提到的都是基于二進制的序列化協議,像 JSON 和 XML這種屬于文本類序列化方式。雖然 JSON 和 XML可讀性比較好,但是性能較差,一般不會選擇。
### 2.1. JDK自帶的序列化方式
JDK 自帶的序列化,只需實現 `java.io.Serializable`接口即可。
```java
@AllArgsConstructor
@NoArgsConstructor
@Getter
@Builder
@ToString
public class RpcRequest implements Serializable {
private static final long serialVersionUID = 1905122041950251207L;
private String requestId;
private String interfaceName;
private String methodName;
private Object[] parameters;
private Class<?>[] paramTypes;
private RpcMessageTypeEnum rpcMessageTypeEnum;
}
```
> 序列化號 serialVersionUID 屬于版本控制的作用。序列化的時候serialVersionUID也會被寫入二級制序列,當反序列化時會檢查serialVersionUID是否和當前類的serialVersionUID一致。如果serialVersionUID不一致則會拋出 `InvalidClassException` 異常。強烈推薦每個序列化類都手動指定其 `serialVersionUID`,如果不手動指定,那么編譯器會動態生成默認的序列化號
我們很少或者說幾乎不會直接使用這個序列化方式,主要原因有兩個:
1. **不支持跨語言調用** : 如果調用的是其他語言開發的服務的時候就不支持了。
2. **性能差** :相比于其他序列化框架性能更低,主要原因是序列化之后的字節數組體積較大,導致傳輸成本加大。
### 2.2. kyro
Kryo是一個高性能的序列化/反序列化工具,由于其變長存儲特性并使用了字節碼生成機制,擁有較高的運行速度和較小的字節碼體積。
另外,Kryo 已經是一種非常成熟的序列化實現了,已經在Twitter、Groupon、Yahoo以及多個著名開源項目(如Hive、Storm)中廣泛的使用。
[guide-rpc-framework](https://github.com/Snailclimb/guide-rpc-framework) 就是使用的 kyro 進行序列化,序列化和反序列化相關的代碼如下:、
```java
/**
* Kryo序列化類,Kryo序列化效率很高,但是只兼容 Java 語言
*
* @author shuang.kou
* @createTime 2020年05月13日 19:29:00
*/
@Slf4j
public class KryoSerializer implements Serializer {
/**
* 由于 Kryo 不是線程安全的。每個線程都應該有自己的 Kryo,Input 和 Output 實例。
* 所以,使用 ThreadLocal 存放 Kryo 對象
*/
private final ThreadLocal<Kryo> kryoThreadLocal = ThreadLocal.withInitial(() -> {
Kryo kryo = new Kryo();
kryo.register(RpcResponse.class);
kryo.register(RpcRequest.class);
kryo.setReferences(true); //默認值為true,是否關閉注冊行為,關閉之后可能存在序列化問題,一般推薦設置為 true
kryo.setRegistrationRequired(false); //默認值為false,是否關閉循環引用,可以提高性能,但是一般不推薦設置為 true
return kryo;
});
@Override
public byte[] serialize(Object obj) {
try (ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
Output output = new Output(byteArrayOutputStream)) {
Kryo kryo = kryoThreadLocal.get();
// Object->byte:將對象序列化為byte數組
kryo.writeObject(output, obj);
kryoThreadLocal.remove();
return output.toBytes();
} catch (Exception e) {
throw new SerializeException("序列化失敗");
}
}
@Override
public <T> T deserialize(byte[] bytes, Class<T> clazz) {
try (ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(bytes);
Input input = new Input(byteArrayInputStream)) {
Kryo kryo = kryoThreadLocal.get();
// byte->Object:從byte數組中反序列化出對對象
Object o = kryo.readObject(input, clazz);
kryoThreadLocal.remove();
return clazz.cast(o);
} catch (Exception e) {
throw new SerializeException("反序列化失敗");
}
}
}
```
Github 地址:[https://github.com/EsotericSoftware/kryo](https://github.com/EsotericSoftware/kryo) 。
### 2.3. Protobuf
Protobuf出自于Google,性能還比較優秀,也支持多種語言,同時還是跨平臺的。就是在使用中過于繁瑣,因為你需要自己定義 IDL 文件和生成對應的序列化代碼。這樣雖然不然靈活,但是,另一方面導致protobuf沒有序列化漏洞的風險。
> Protobuf包含序列化格式的定義、各種語言的庫以及一個IDL編譯器。正常情況下你需要定義proto文件,然后使用IDL編譯器編譯成你需要的語言
一個簡單的 proto 文件如下:
```protobuf
// protobuf的版本
syntax = "proto3";
// SearchRequest會被編譯成不同的編程語言的相應對象,比如Java中的class、Go中的struct
message Person {
//string類型字段
string name = 1;
// int 類型字段
int32 age = 2;
}
```
Github地址:[https://github.com/protocolbuffers/protobuf](https://github.com/protocolbuffers/protobuf)。
### 2.4. ProtoStuff
由于Protobuf的易用性,它的哥哥 Protostuff 誕生了。
protostuff 基于Google protobuf,但是提供了更多的功能和更簡易的用法。雖然更加易用,但是不代表 ProtoStuff 性能更差。
Gihub地址:[https://github.com/protostuff/protostuff](https://github.com/protostuff/protostuff)。
### 2.5. hession
hessian 是一個輕量級的,自定義描述的二進制RPC協議。hessian是一個比較老的序列化實現了,并且同樣也是跨語言的。
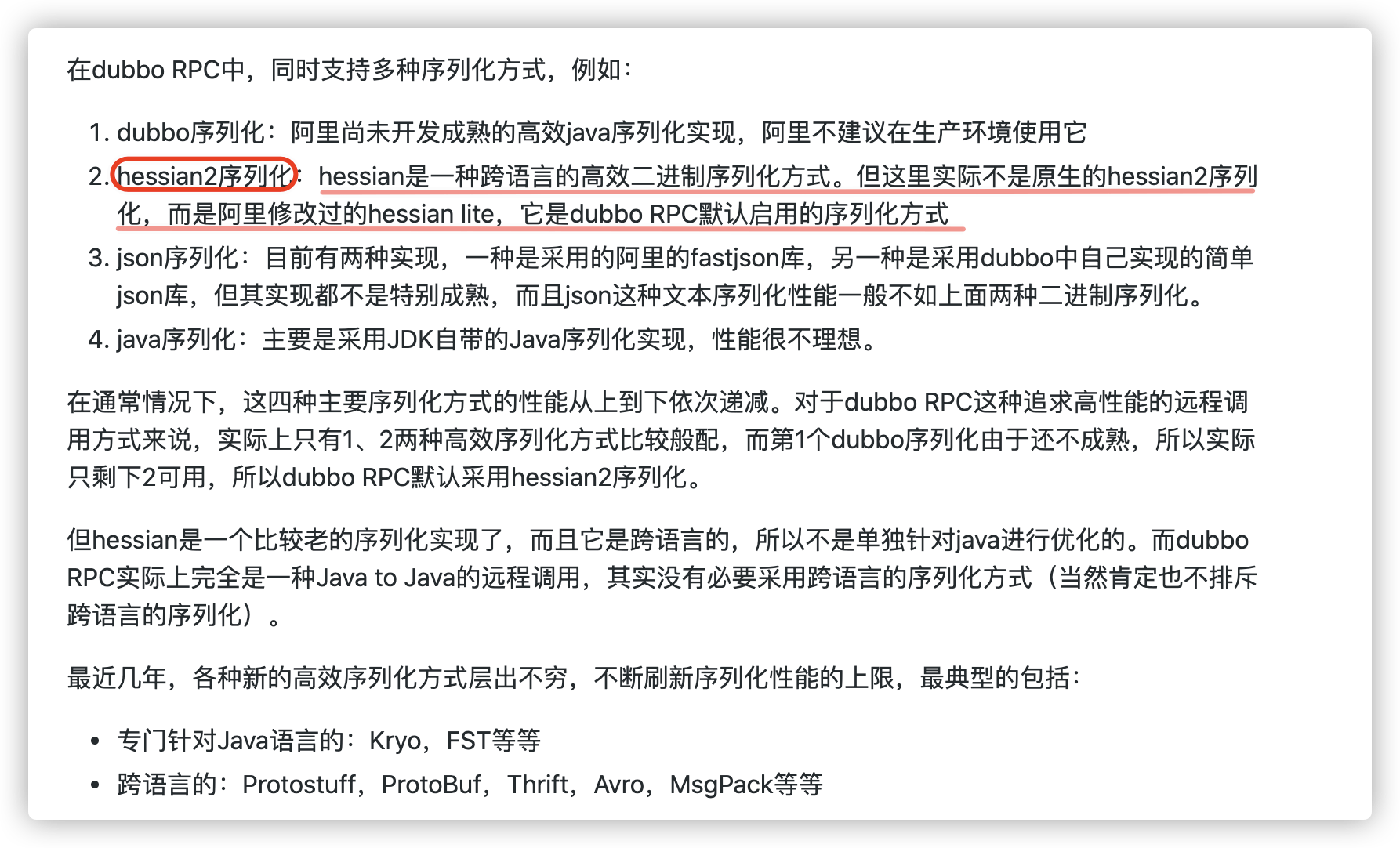
dubbo RPC默認啟用的序列化方式是 hession2 ,但是,Dubbo對hessian2進行了修改,不過大體結構還是差不多。
### 2.6. 總結
Kryo 是專門針對Java語言序列化方式并且性能非常好,如果你的應用是專門針對Java語言的話可以考慮使用,并且 Dubbo 官網的一篇文章中提到說推薦使用 Kryo 作為生產環境的序列化方式。(文章地址:[https://dubbo.apache.org/zh-cn/docs/user/serialization.html](https://dubbo.apache.org/zh-cn/docs/user/serialization.html))

像Protobuf、 ProtoStuff、hession這類都是跨語言的序列化方式,如果有跨語言需求的話可以考慮使用。
除了我上面介紹到的序列化方式的話,還有像 Thrift,Avro 這些。
## 3. 其他推薦閱讀
1. 美團技術團隊-序列化和反序列化:[https://tech.meituan.com/2015/02/26/serialization-vs-deserialization.html](https://tech.meituan.com/2015/02/26/serialization-vs-deserialization.html)
2. 在Dubbo中使用高效的Java序列化(Kryo和FST): [https://dubbo.apache.org/zh-cn/docs/user/serialization.html](https://dubbo.apache.org/zh-cn/docs/user/serialization.html)