1、 **mysql 事物的特性:**
1 原子性:就是所有操作都完成,如果有中止,則操作回到之 前狀態
2 一致性:確保數據庫狀態改變之后,成功提交事務
3 隔離性:事務之間彼此獨立 透明
4 持久性:確保提交的事務結果在出現故障的情況下仍然存在
2、 **緊接著上面 面試官會問到你【事務的隔離級別】**
1 讀未提交:客戶端a 修改數據,未提交,客戶端b就可以讀到數據,一旦a因為某種原因回滾,那所有操作都會被撤銷,客戶端b讀的數據就是臟數據,也就是臟讀
2 讀已提交:客戶端a修改數據,未提交,客戶端b是查詢不到a更新的數據的,解決了臟讀問題。但是 當客戶端a 事務提交了,客戶端b執行上一步相同的查詢,結果是與上一步不一致 即產生了 不可重復讀現象
3 可重復讀: 客戶端b事務提交之前 查詢數據,同時客戶端a修改數據并提交,客戶端b查詢到的數據和第一次查詢數據是一致的,沒有出現不可重復讀的現象
4 串行化
Mysql默認事務的隔離級別:可重復讀 。 這時候檢索條件命中索引的時候會默認鎖住next\_key ,如果檢索沒有索引,更新數據時會鎖住整張表。一個事務被加了鎖,其他事務是不能在這個間隙插入記錄的,這樣可以防止幻讀
沒有絕對的 根據需求來設置隔離級別 如果對數據的完整性和一致性要求越高 那就選擇更高的隔離級別。但是會影響并發性能
3、 **不出意外面試官會問你【mysql索引都有哪些】**
1 普通索引
2 唯一索引:索引的列的值必須唯一。允許有空值
3 主鍵索引:只有一個主鍵并且不能為空
4 聯合索引:多個字段組合創建索引,注意 組合索引遵循最左原則
5 全文索引:fulltext 雖然會大大提高查詢速度但是會降低更新表的速度
聯合索引例子:創建了(a,b,c)這樣的索引 那么 可以支持 a | a,b | a.b.c 。
b,c 這樣子是不支持的。這就是最左原則
什么情況下建索引:
1 表的字段唯一 這時候可以建唯一索引
2 直接條件查詢的字段 where a =
3 字段作為了其他表的外鍵
4 查詢中排序、統計、分組 的字段
索引字段要在where里,where條件中or索引不會起作用
什么時候不建議用索引:
1 表的數據太少
2 經常插入、修改、刪除的表
3 數據重復項很多的字段
4 經常和主字段一起查詢,但是主字段索引值比較多的字段
Like “%aaaa%”不會用到索引 ;not in 也不會用到索引
4、Mysql索引結構
常見的MySQL主要有兩種結構:Hash索引和B+ Tree索引,我們使用的是InnoDB引擎,默認的是B+樹
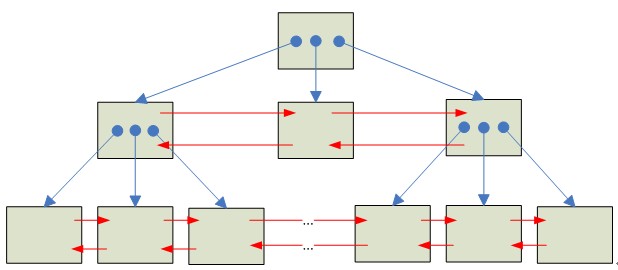
葉子節點:B樹層次為0的頁面,存儲記錄的所有內容。
非葉子節點:B樹層次大于0的頁面,只存儲索引鍵和頁面指針。
相同層次的頁面是用一個雙向鏈表連接起來的。
一般情況下,從樹的最左邊葉子節點開始,一直向右掃描,就能得到樹的從小到的的所有數據。所以 頁內的數據都是按索引鍵排序的、后右面的索引值不會小于他左側兄弟的任何節點的值
MYSQL
MYSQL