**目錄**
* [一、數據庫概要](https://www.cnblogs.com/best/p/6517755.html#_label0)
* [1.1、發展歷史](https://www.cnblogs.com/best/p/6517755.html#_lab2_0_0)
* [1.1.1、人工處理階段](https://www.cnblogs.com/best/p/6517755.html#_label3_0_0_0)
* [1.1.2、文件系統](https://www.cnblogs.com/best/p/6517755.html#_label3_0_0_1)
* [1.1.3、數據庫管理系統](https://www.cnblogs.com/best/p/6517755.html#_label3_0_0_2)
* [1.2、常見數據庫技術品牌、服務與架構](https://www.cnblogs.com/best/p/6517755.html#_lab2_0_1)
* [1.3、數據庫分類](https://www.cnblogs.com/best/p/6517755.html#_lab2_0_2)
* [1.3.1、關系型數據庫](https://www.cnblogs.com/best/p/6517755.html#_label3_0_2_0)
* [1.3.2、非關系型數據庫](https://www.cnblogs.com/best/p/6517755.html#_label3_0_2_1)
* [1.4、數據庫規范化](https://www.cnblogs.com/best/p/6517755.html#_lab2_0_3)
* [1.4.1. 什么是范式](https://www.cnblogs.com/best/p/6517755.html#_label3_0_3_0)
* [1.4.2. 三大范式](https://www.cnblogs.com/best/p/6517755.html#_label3_0_3_1)
* [1.4.3. 范式與效率](https://www.cnblogs.com/best/p/6517755.html#_label3_0_3_2)
* [二、MySQL介紹](https://www.cnblogs.com/best/p/6517755.html#_label1)
* [2.1、MySQL概要](https://www.cnblogs.com/best/p/6517755.html#_lab2_1_0)
* [2.2、系統特性](https://www.cnblogs.com/best/p/6517755.html#_lab2_1_1)
* [2.3、存儲引擎](https://www.cnblogs.com/best/p/6517755.html#_lab2_1_2)
* [三、快速安裝運行MySQL數據庫](https://www.cnblogs.com/best/p/6517755.html#_label2)
* [3.1、使用綠色版](https://www.cnblogs.com/best/p/6517755.html#_lab2_2_0)
* [3.1.1、設置mysql遠程訪問](https://www.cnblogs.com/best/p/6517755.html#_label3_2_0_0)
* [3.1.2、修改mysql用戶密碼](https://www.cnblogs.com/best/p/6517755.html#_label3_2_0_1)
* [3.1.2、安裝服務](https://www.cnblogs.com/best/p/6517755.html#_label3_2_0_2)
* [3.2、使用安裝版](https://www.cnblogs.com/best/p/6517755.html#_lab2_2_1)
* [四、使用GUI操作MySQL](https://www.cnblogs.com/best/p/6517755.html#_label3)
* [4.1、關系型數據庫的典型概念](https://www.cnblogs.com/best/p/6517755.html#_lab2_3_0)
* [4.2、登錄數據庫](https://www.cnblogs.com/best/p/6517755.html#_lab2_3_1)
* [4.3、創建數據庫](https://www.cnblogs.com/best/p/6517755.html#_lab2_3_2)
* [4.4、創建表](https://www.cnblogs.com/best/p/6517755.html#_lab2_3_3)
* [4.5、管理數據](https://www.cnblogs.com/best/p/6517755.html#_lab2_3_4)
* [4.5.1、添加數據](https://www.cnblogs.com/best/p/6517755.html#_label3_3_4_0)
* [4.5.2、刪除數據](https://www.cnblogs.com/best/p/6517755.html#_label3_3_4_1)
* [4.5.3、修改表結構](https://www.cnblogs.com/best/p/6517755.html#_label3_3_4_2)
* [4.5.4、外鍵](https://www.cnblogs.com/best/p/6517755.html#_label3_3_4_3)
* [4.5.5、唯一鍵](https://www.cnblogs.com/best/p/6517755.html#_label3_3_4_4)
* [4.6、上機練習](https://www.cnblogs.com/best/p/6517755.html#_lab2_3_5)
* [五、使用SQL訪問MySQL數據庫](https://www.cnblogs.com/best/p/6517755.html#_label4)
* [5.0、定義學生表Stu、商品類型與商品表](https://www.cnblogs.com/best/p/6517755.html#_lab2_4_0)
* [5.0.1、新建數據庫](https://www.cnblogs.com/best/p/6517755.html#_label3_4_0_0)
* [5.0.2、新建表](https://www.cnblogs.com/best/p/6517755.html#_label3_4_0_1)
* [5.0.3、新建查詢](https://www.cnblogs.com/best/p/6517755.html#_label3_4_0_2)
* [5.1、增加數據](https://www.cnblogs.com/best/p/6517755.html#_lab2_4_1)
* [5.2、查詢數據](https://www.cnblogs.com/best/p/6517755.html#_lab2_4_2)
* [5.2.1、表達式與條件查詢](https://www.cnblogs.com/best/p/6517755.html#_label3_4_2_0)
* [5.2.2、聚合函數](https://www.cnblogs.com/best/p/6517755.html#_label3_4_2_1)
* [5.3、刪除數據](https://www.cnblogs.com/best/p/6517755.html#_lab2_4_3)
* [5.4、更新數據](https://www.cnblogs.com/best/p/6517755.html#_lab2_4_4)
* [5.5、修改表](https://www.cnblogs.com/best/p/6517755.html#_lab2_4_5)
* [5.5.1、添加列](https://www.cnblogs.com/best/p/6517755.html#_label3_4_5_0)
* [5.5.2、修改列](https://www.cnblogs.com/best/p/6517755.html#_label3_4_5_1)
* [5.5.3、刪除列](https://www.cnblogs.com/best/p/6517755.html#_label3_4_5_2)
* [5.5.4、重命名表](https://www.cnblogs.com/best/p/6517755.html#_label3_4_5_3)
* [5.5.5、刪除表](https://www.cnblogs.com/best/p/6517755.html#_label3_4_5_4)
* [5.5.6、刪除數據庫](https://www.cnblogs.com/best/p/6517755.html#_label3_4_5_5)
* [5.5.7、一千行MySQL筆記](https://www.cnblogs.com/best/p/6517755.html#_label3_4_5_6)
* [5.5.8、常用的SQL](https://www.cnblogs.com/best/p/6517755.html#_label3_4_5_7)
* [5.6、MySQL與SQLServer的區別](https://www.cnblogs.com/best/p/6517755.html#_lab2_4_6)
* [5.6.1、區別一](https://www.cnblogs.com/best/p/6517755.html#_label3_4_6_0)
* [5.6.2、區別二](https://www.cnblogs.com/best/p/6517755.html#_label3_4_6_1)
* [六、使用JDBC訪問MySQL](https://www.cnblogs.com/best/p/6517755.html#_label5)
* [6.1、下載驅動](https://www.cnblogs.com/best/p/6517755.html#_lab2_5_0)
* [6.2、JDBC訪問MySQL](https://www.cnblogs.com/best/p/6517755.html#_lab2_5_1)
* [七、下載程序、幫助、視頻](https://www.cnblogs.com/best/p/6517755.html#_label6)
* [八、作業](https://www.cnblogs.com/best/p/6517755.html#_label7)
* [8.1、使用javascript實現身份證校驗與信息提取。](https://www.cnblogs.com/best/p/6517755.html#_lab2_7_0)
* [8.2、SQL強化練習,請點擊進入](https://www.cnblogs.com/best/p/6517755.html#_lab2_7_1)
隨著移動互聯網的結束與人工智能的到來大數據變成越來越重要,下一個成功者應該是擁有海量數據的,數據與數據庫你應該知道。
# 一、數據庫概要
數據庫(Database)是存儲與管理數據的軟件系統,就像一個存入數據的物流倉庫。
在商業領域,信息就意味著商機,取得信息的一個非常重要的途徑就是對數據進行分析處理,這就催生了各種專業的數據管理軟件,數據庫就是其中的一種。當然,數據庫管理系統也不是一下子就建立起來,它也是經過了不斷的豐富和發展,才有了今天的模樣。

## 1.1、發展歷史
### 1.1.1、人工處理階段
在20世紀50年代中期以前的計算機誕生初期,其處理能力很有限,只能夠完成一些簡單的運算,數據處理能力也很有限,這使得當時的計算機只能夠用于科學和工程計算。計算機上沒有專用的管理數據的軟件,數據由計算機或處理它的程序自行攜帶。當數據的存儲格式、讀寫路徑或方法發生變化的時候,其處理程序也必須要做出相應的改變以保持程序的正確性。
### 1.1.2、文件系統
20世紀50年代后期到60年代中期,隨著硬件和軟件技術的發展,計算機不僅用于科學計算,還大量用于商業管理中。在這一時期,數據和程序在存儲位置上已經完全分開,數據被單獨組織成文件保存到外部存儲設備上,這樣數據文件就可以為多個不同的程序在不同的時間所使用。
雖然程序和數據在存儲位置上分開了,而且操作系統也可以幫助我們對完成了數據的存儲位置和存取路徑的管理,但是程序設計仍然受到數據存儲格式和方法的影響,不能夠完全獨立于數據,而且數據的冗余較大。
### 1.1.3、數據庫管理系統
從20世紀70年代以來,計算機軟硬件技術取得了飛躍式的發展,這一時期最主要的發展就是產生了真正意義上的數據庫管理系統,它使得應用程序和數據之間真正的實現的接口統一、數據共享等,這樣應用程序都可以按照統一的方式直接操作數據,也就是應用程序和數據都具有了高度的獨立性。

## 1.2、常見數據庫技術品牌、服務與架構
?發展了這么多年市場上出現了許多的數據庫系統,最強的個人認為是Oracle,當然還有許多如:DB2、Microsoft SQL Server、MySQL、SyBase等,下圖列出常見數據庫技術品牌、服務與架構。

## 1.3、數據庫分類
數據庫通常分為層次式數據庫、網絡式數據庫和關系式數據庫三種。
而不同的數據庫是按不同的數據結構來聯系和組織的。
而在當今的互聯網中,最常見的數據庫模型主要是兩種,即關系型數據庫和非關系型數據庫。
### 1.3.1、關系型數據庫
當前在成熟應用且服務與各種系統的主力數據庫還是關系型數據庫。

代表:Oracle、SQL Server、MySQL
### 1.3.2、非關系型數據庫
隨著時代的進步與發展的需要,非關系型數據庫應運而生。
代表:Redis、Mongodb
NoSQL數據庫在存儲速度與靈活性方面有優勢,也常用于緩存。
## 1.4、數據庫規范化
經過一系列的步驟,我們現在終于將客戶的需求轉換為數據表并確立這些表之間的關系,那么是否我們現在就可以在開發中使用呢?答案否定的,為什么呢!同一個項目,很多人參與了需求的分析,數據庫的設計,不同的人具有不同的想法,不同的部門具有不同的業務需求,我們以此設計的數據庫將不可避免的包含大量相同的數據,在結構上也有可能產生沖突,在開發中造成不便。
### 1.4.1. 什么是范式
要設計規范化的數據庫,就要求我們根據數據庫設計范式――也就是數據庫設計的規范原則來做。范式可以指導我們更好地設計數據庫的表結構,減少冗余的數據,借此可以提高數據庫的存儲效率,數據完整性和可擴展性。
設計關系數據庫時,遵從不同的規范要求,設計出合理的關系型數據庫,這些不同的規范要求被稱為不同的范式,各種范式呈遞次規范,越高的范式數據庫冗余越小。目前關系數據庫有六種范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴德斯科范式(BCNF)、第四范式(4NF)和第五范式(5NF,又稱完美范式)。滿足最低要求的范式是第一范式(1NF)。在第一范式的基礎上進一步滿足更多規范要求的稱為第二范式(2NF),其余范式以次類推。一般說來,數據庫只需滿足第三范式(3NF)就行了。
### 1.4.2. 三大范式
**第一范式(1NF)**
所謂第一范式(1NF)是指在關系模型中,對列添加的一個規范要求,所有的列都應該是原子性的,即數據庫表的每一列都是不可分割的原子數據項,而不能是集合,數組,記錄等非原子數據項。即實體中的某個屬性有多個值時,必須拆分為不同的屬性。在符合第一范式(1NF)表中的每個域值只能是實體的一個屬性或一個屬性的一部分。簡而言之,第一范式就是無重復的域。
例如:表1-1中,其中”工程地址”列還可以細分為省份,城市等。在國外,更多的程序把”姓名”列也分成2列,即”姓”和“名”。
雖然第一范式要求各列要保存原子性,不能再分,但是這種要求和我們的需求是相關聯的,如上表中我們對”工程地址”沒有省份,城市這樣方面的查詢和應用需求,則不需拆分,”姓名”列也是同樣如此。
表1-1?? 原始表
工程號工程名稱工程地址員工編號員工名稱薪資待遇職務P001港珠澳大橋廣東珠海E0001Jack6000/月工人P001港珠澳大橋廣東珠海E0002Join7800/月工人P001港珠澳大橋廣東珠海E0003Apple8000/月高級技工P002南海航天海南三亞E0001Jack5000/月工人
**第二范式(2NF)**
在1NF的基礎上,非Key屬性必須完全依賴于主鍵。第二范式(2NF)是在第一范式(1NF)的基礎上建立起來的,即滿足第二范式(2NF)必須先滿足第一范式(1NF)。第二范式(2NF)要求數據庫表中的每個實例或記錄必須可以被唯一地區分。選取一個能區分每個實體的屬性或屬性組,作為實體的唯一標識。
第二范式(2NF)要求實體的屬性完全依賴于主關鍵字。所謂完全依賴是指不能存在僅依賴主關鍵字一部分的屬性,如果存在,那么這個屬性和主關鍵字的這一部分應該分離出來形成一個新的實體,新實體與原實體之間是一對多的關系。為實現區分通常需要為表加上一個列,以存儲各個實例的唯一標識。簡而言之,第二范式就是在第一范式的基礎上屬性完全依賴于主鍵。
例如:表1-1中,一個表描述了工程信息,員工信息等。這樣就造成了大量數據的重復。按照第二范式,我們可以將表1-1拆分成表1-2和表1-3:
l? 工程信息表:(工程編號,工程名稱,工程地址):
表1-2?? 工程信息表
工程編號工程名稱工程地址P001港珠澳大橋廣東珠海P002南海航天海南三亞
l? 員工信息表(員工編號,員工名稱,職務,薪資水平):
表1-3?? 員工信息表
員工編號員工姓名職務薪資水平E0001Jack工人3000/月E0002Join工人3000/月E0003Apple高級技工6000/月
這樣,表1-1就變成了兩張表,每個表只描述一件事,清晰明了。
**第三范式(3NF)**
第三范式是在第二范式基礎上,更進一層,第三范式的目標就是確保表中各列與主鍵列直接相關,而不是間接相關。即各列與主鍵列都是一種直接依賴關系,則滿足第三范式。
第三范式要求各列與主鍵列直接相關,我們可以這樣理解,假設張三是李四的兵,王五則是張三的兵,這時王五是不是李四的兵呢?從這個關系中我們可以看出,王五也是李四的兵,因為王五依賴于張三,而張三是李四的兵,所以王五也是。這中間就存在一種間接依賴的關系而非我們第三范式中強調的直接依賴。
現在我們來看看在第二范式的講解中,我們將表1-1拆分成了兩張表。這兩個表是否符合第三范式呢。在員工信息表中包含:”員工編號”、”員工名稱”、”職務”、”薪資水平”,而我們知道,薪資水平是有職務決定,這里”薪資水平”通過”職務”與員工相關,則不符合第三范式。我們需要將員工信息表進一步拆分,如下:
l? 員工信息表:員工編號,員工名稱,職務
l? 職務表:職務編號,職務名稱,薪資水平
現在我們已經了解了數據庫規范化設計的三大范式,下面我們再來看看對表1-1優化后的數據表:
員工信息表(Employee)
員工編號員工姓名職務編號E0001Jack1E0002Join1E0003Apple2
工程信息表(ProjectInfo)
工程編號工程名稱工程地址P001港珠澳大橋廣東珠海P002南海航天海南三亞
職務表(Duty)
職務編號職務名稱工資待遇1工人3000/月2高級技工6000/月
工程參與人員記錄表(Project\_ Employee\_info)
編號工程編號人員編號1P001E00012P001E00023P002E0003
通過對比我們發現,表多了,關系復雜了,查詢數據變的麻煩了,編程中的難度也提高了,但是各個表中內容更清晰了,重復的數據少了,更新和維護變的更容易了,哪么如何平衡這種矛盾呢?
### 1.4.3. 范式與效率
在我們設計數據庫時,設計人員、客戶、開發人員通常對數據庫的設計有一定的矛盾,客戶更喜歡方便,清晰的結果,開發人員也希望數據庫關系比較簡單,降低開發難度,而設計人員則需要應用三大范式對數據庫進行嚴格規范化,減少數據冗余,提高數據庫可維護性和擴展性。由此可以看出,為了滿足三大范式,我們數據庫設計將會與客戶、開發人員產生分歧,所以在實際的數據庫設計中,我們不能一味的追求規范化,既要考慮三大范式,減少數據冗余和各種數據庫操作異常,又要充分考慮到數據庫的性能問題,允許適當的數據庫冗余。
# 二、MySQL介紹
## 2.1、MySQL概要
MySQL是一個關系型數據庫管理系統,由瑞典MySQL AB 公司開發,目前屬于 Oracle 旗下產品。MySQL 是最流行的關系型數據庫管理系統之一,在 WEB 應用方面,MySQL是最好的 RDBMS (Relational Database Management System,關系數據庫管理系統) 應用軟件之一。

MySQL是一種關系數據庫管理系統,關系數據庫將數據保存在不同的表中,而不是將所有數據放在一個大倉庫內,這樣就增加了速度并提高了靈活性。
MySQL所使用的 SQL 語言是用于訪問數據庫的最常用標準化語言。MySQL 軟件采用了雙授權政策,分為社區版和商業版,由于其體積小、速度快、總體擁有成本低,尤其是開放源碼這一特點,一般中小型網站的開發都選擇 MySQL 作為網站數據庫。
MySQL官網:[https://www.mysql.com/](https://www.mysql.com/)
MySQL下載:[https://www.mysql.com/downloads/](https://www.mysql.com/downloads/)
## 2.2、系統特性
1.使用 C和 C++編寫,并使用了多種編譯器進行測試,保證了源代碼的可移植性。
2.支持 AIX、FreeBSD、HP-UX、Linux、Mac OS、NovellNetware、OpenBSD、OS/2 Wrap、Solaris、Windows等多種操作系統。
3.為多種編程語言提供了 API。這些編程語言包括 C、C++、Python、Java、Perl、PHP、Eiffel、Ruby,.NET和 Tcl 等。
4.支持多線程,充分利用 CPU 資源。
5.優化的 SQL查詢算法,有效地提高查詢速度。
6.既能夠作為一個單獨的應用程序應用在客戶端服務器網絡環境中,也能夠作為一個庫而嵌入到其他的軟件中。
7.提供多語言支持,常見的編碼如中文的 GB 2312、BIG5,日文的 Shift\_JIS等都可以用作數據表名和數據列名。
8.提供 TCP/IP、ODBC 和 JDBC等多種數據庫連接途徑。
9.提供用于管理、檢查、優化數據庫操作的管理工具。
10.支持大型的數據庫。可以處理擁有上千萬條記錄的大型數據庫。
11.支持多種存儲引擎。
12.MySQL 是開源的,所以你不需要支付額外的費用。
13.MySQL 使用標準的 SQL數據語言形式。
14.MySQL 對 PHP 有很好的支持,PHP是目前最流行的 Web 開發語言。
15.MySQL是可以定制的,采用了 GPL協議,你可以修改源碼來開發自己的 MySQL 系統。
16.在線 DDL/更改功能,數據架構支持動態應用程序和開發人員靈活性(5.6新增)
17.復制全局事務標識,可支持自我修復式集群(5.6新增)
18.復制無崩潰從機,可提高可用性(5.6新增)
19.復制多線程從機,可提高性能(5.6新增)
20.3倍更快的性能(5.7新增)
21.新的優化器(5.7新增)
22.原生JSON支持(5.7新增)
23.多源復制(5.7新增)
24.GIS的空間擴展(5.7新增)
## 2.3、存儲引擎
MySQL數據庫根據應用的需要準備了不同的引擎,不同的引擎側重點不一樣,區別如下:
MyISAM MySQL 5.0 之前的默認數據庫引擎,最為常用。擁有較高的插入,查詢速度,但不支持事務
InnoDB 事務型數據庫的首選引擎,支持ACID事務,支持行級鎖定, MySQL 5.5 起成為默認數據庫引擎
BDB源 自 Berkeley DB,事務型數據庫的另一種選擇,支持Commit 和Rollback 等其他事務特性
Memory 所有數據置于內存的存儲引擎,擁有極高的插入,更新和查詢效率。但是會占用和數據量成正比的內存空間。并且其內容會在 MySQL 重新啟動時丟失
Merge 將一定數量的 MyISAM 表聯合而成一個整體,在超大規模數據存儲時很有用\\
Archive 非常適合存儲大量的獨立的,作為歷史記錄的數據。因為它們不經常被讀取。Archive 擁有高效的插入速度,但其對查詢的支持相對較差
Federated 將不同的 MySQL 服務器聯合起來,邏輯上組成一個完整的數據庫。非常適合分布式應用
Cluster/NDB 高冗余的存儲引擎,用多臺數據機器聯合提供服務以提高整體性能和安全性。適合數據量大,安全和性能要求高的應用
CSV 邏輯上由逗號分割數據的存儲引擎。它會在數據庫子目錄里為每個數據表創建一個 .csv 文件。這是一種普通文本文件,每個數據行占用一個文本行。CSV 存儲引擎不支持索引。
BlackHole 黑洞引擎,寫入的任何數據都會消失,一般用于記錄 binlog 做復制的中繼
EXAMPLE 存儲引擎是一個不做任何事情的存根引擎。它的目的是作為 MySQL 源代碼中的一個例子,用來演示如何開始編寫一個新存儲引擎。同樣,它的主要興趣是對開發者。EXAMPLE 存儲引擎不支持編索引。
另外,MySQL 的存儲引擎接口定義良好。有興趣的開發者可以通過閱讀文檔編寫自己的存儲引擎。

# 三、快速安裝運行MySQL數據庫
MySQL以前一直是開源免費的,被Oracle收購后有些變化:以前的版本都是免費的,社區版按GPL協議開源免費,商業版提供更加豐富的功能,但收費。
社區版的下載地址:[https://dev.mysql.com/downloads/](https://dev.mysql.com/downloads/)?(免費)
企業版的下載地址:[https://www.mysql.com/downloads/](https://www.mysql.com/downloads/)(收費)
## 3.1、使用綠色版
為了方便快捷的使用MySQL我已經準備好了一個綠化了的MySQL,解壓后就可以直接使用,不需要任何配置。
下載地址1:[https://pan.baidu.com/s/1K08GU-E4CyEKKIseBYwRYA](https://pan.baidu.com/s/1K08GU-E4CyEKKIseBYwRYA)密碼: e59m
下載地址2:[http://download.csdn.net/detail/zhangguo5/9773842](http://download.csdn.net/detail/zhangguo5/9773842)
下載后直接解壓:
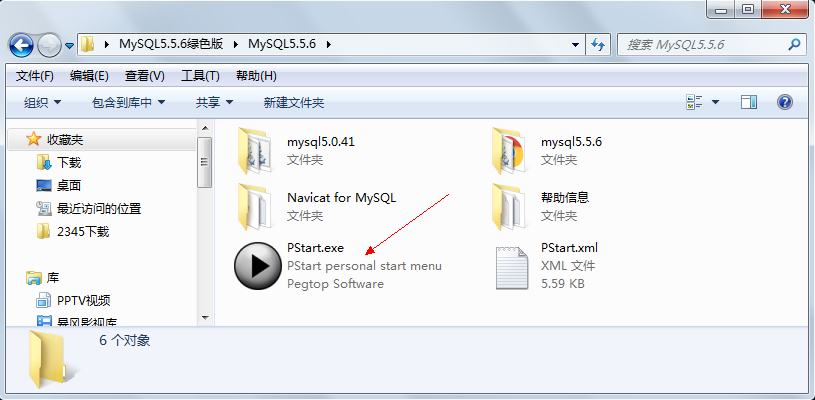
點擊啟動PStart.exe這是一個自定義菜單的小工具,為了整理資源用的。
里面有兩個MySQL的綠色版軟件5.0,5.5
Navicat for MySQL是一個數據庫客戶端管理工具
點擊啟動PStart.exe后的結果如下:

點擊啟動MySQL服務,運行Navicat for MySQL即可。
\*注意:上面的PStart只是一個整理文檔資料的工具,并非必要,如果啟動時有錯誤或為空時,可以直接關閉,直接啟動MySQL服務,如:

mysql\_start.bat用于啟動MySql數據庫,mysql\_stop.bat用于關閉MySql數據庫。
開發工具的啟動方式也一樣,如下所示:
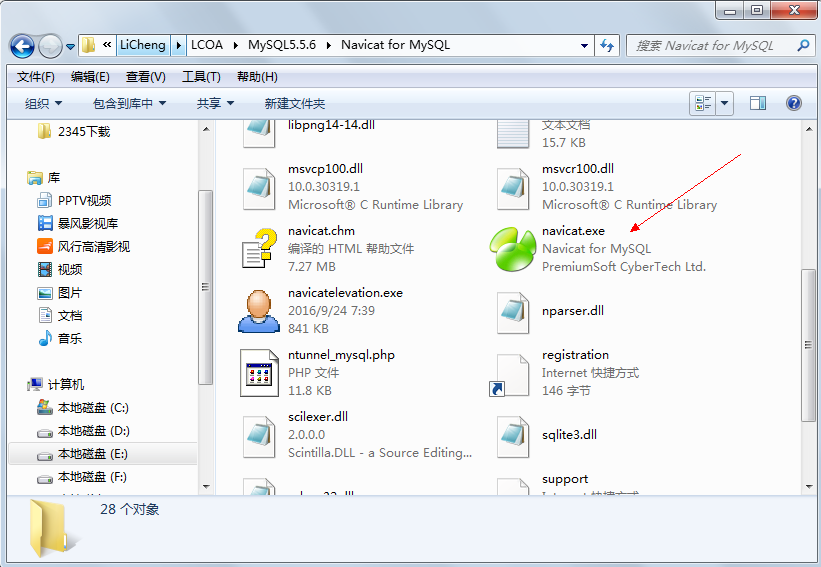
navicat.exe用于啟動Navicat數據庫客戶端,最好發送快捷方式到桌面,省去每次打開文件夾的麻煩。
### 3.1.1、設置mysql遠程訪問
執行mysql 命令進入mysql 命令模式,執行如下SQL代碼?
~~~
mysql> use mysql;
mysql> GRANT ALL ON *.* TO admin@'%' IDENTIFIED BY 'admin' WITH GRANT OPTION;
~~~
#這句話的意思 ,允許任何IP地址(上面的 % 就是這個意思)的電腦 用admin帳戶 和密碼(admin)來訪問這個MySQL Server
#必須加類似這樣的帳戶,才可以遠程登陸。 root帳戶是無法遠程登陸的,只可以本地登陸
### 3.1.2、修改mysql用戶密碼
**1.mysqladmin命令**
格式如下(其中,USER為用戶名,PASSWORD為新密碼):
~~~
mysqladmin -u USER -p password PASSWORD
~~~
該命令之后會提示輸入原密碼,輸入正確后即可修改。
例如,設置root用戶的密碼為123456,則
~~~
mysqladmin -u root -p password 123456
~~~
**2.UPDATE user 語句**
這種方式必須是先用root帳戶登入mysql,然后執行:
~~~
UPDATE user SET password=PASSWORD('123456') WHERE user='root';
FLUSH PRIVILEGES;
~~~
**3.SET PASSWORD 語句**
這種方式也需要先用root命令登入mysql,然后執行:
~~~
SET PASSWORD FOR root=PASSWORD('123456');
~~~
**4.root密碼丟失的情況**
使用 MySQL 自帶的一個工具"MySQL GUI Tools",我一直用的是5.0版本的。 在安裝目錄中運行一個程序 MySQLSystemTrayMonitor.exe,運行完后在系統托盤會出現圖標。如果MySQL服務尚未安裝,則不會出現,可先通過Action>Manage MySQL Instances 先配置和安裝服務。如果已經安裝服務,鼠標右鍵點擊后,會出現"Configure Instance"的菜單。點擊后出現如下MySQL Administrator窗口:
假如原來的服務配置都正常的情況下,選中左側列表中的“啟動變量”,并在相應的右側標簽中選擇“安全”,勾選“禁用grant表”,然后“應用更改”。
并回到左側的“服務器控制”,和右側相應的“開始/停止服務”標簽,點擊啟動服務。此時,連接mysql已經不需要用戶名和密碼了,你可以修改root密碼。
### 3.1.2、安裝服務
首先我們先進入mysql的安裝目錄下的bin目錄、之后打開DOS命令窗口,進入該目錄下(一定要進入該目錄,否則操作錯誤)

執行DOS命令:
輸入命令:mysqld --install,之后出現如下界面。提示安裝服務成功。

注意是mysqld --install不是mysql --install
如果要卸載服務,可以輸入如下命令:mysqld --remove。出現如下界面。提示移除服務成功。

## 3.2、使用安裝版
MySQL5.5.27\_64位安裝包下載地址1:[https://pan.baidu.com/s/1minwz1m](https://pan.baidu.com/s/1minwz1m)密碼: ispn
MySQL5.5.27\_64位安裝包下載地址2:?[http://download.csdn.net/detail/zhangguo5/9775460](http://download.csdn.net/detail/zhangguo5/9775460)
MySQL5.7.17安裝包官網下載地址:?[https://dev.mysql.com/downloads/windows/installer/](https://dev.mysql.com/downloads/windows/installer/)
選擇自定義:

安裝的組件信息:
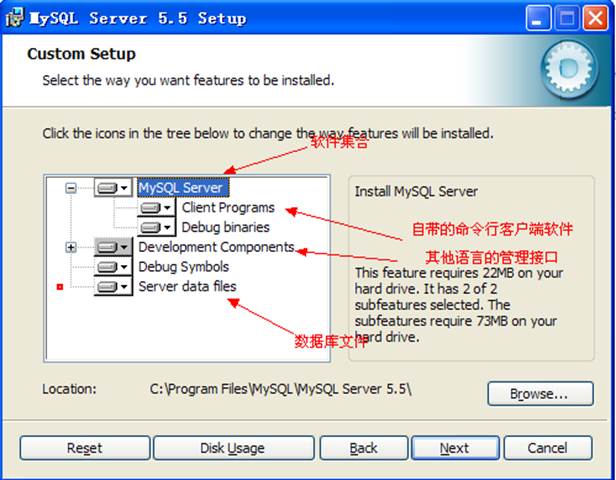
服務器軟件目錄:
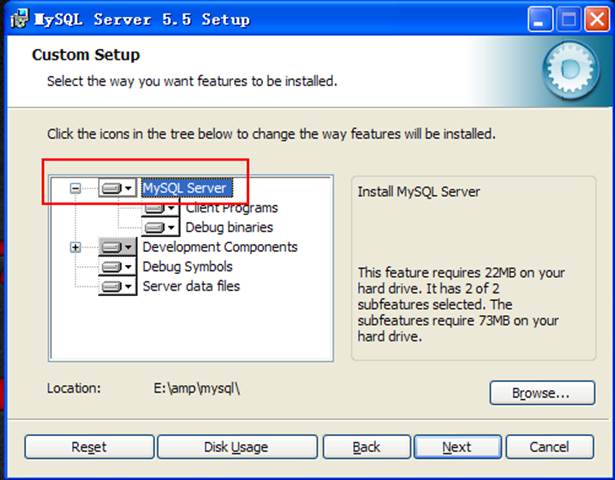
數據目錄:
點擊install安裝即可:

配置:


機器類型

是否支持事務功能:

innodb表空間:
連接數量:
字符集設定:

配置windows管理相關:

配置安全選項,設置管理員的用戶名與密碼:
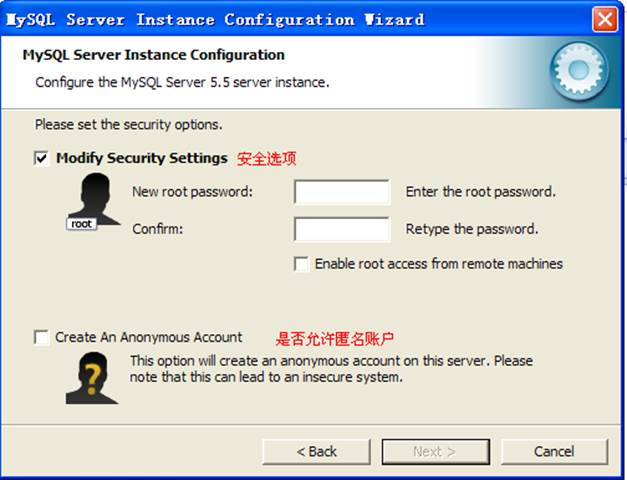
最后執行配置即可:
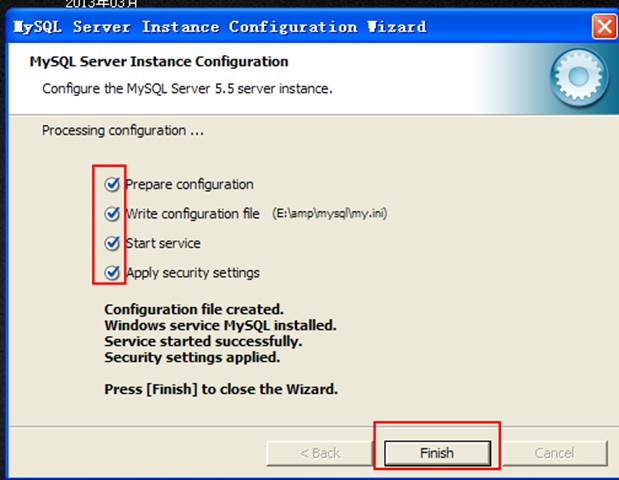
配置后,會啟動服務。
新版的MySQL安裝包大了很多,安裝過程也有些不一樣。
# 四、使用GUI操作MySQL
## 4.1、關系型數據庫的典型概念
數據庫 databse:數據的倉庫

表 table:數據是保存在表內,保存在一個表內的數據,應該具有相同的數據格式
行:行用于記錄數據
記錄:行內的數據
列:列用于規定數據格式
字段:數據的某個列
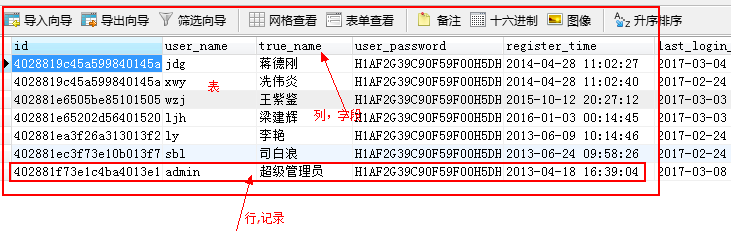
SQL:用來管理數據的語言。結構化查詢語言(SQL,Structured Query Language)
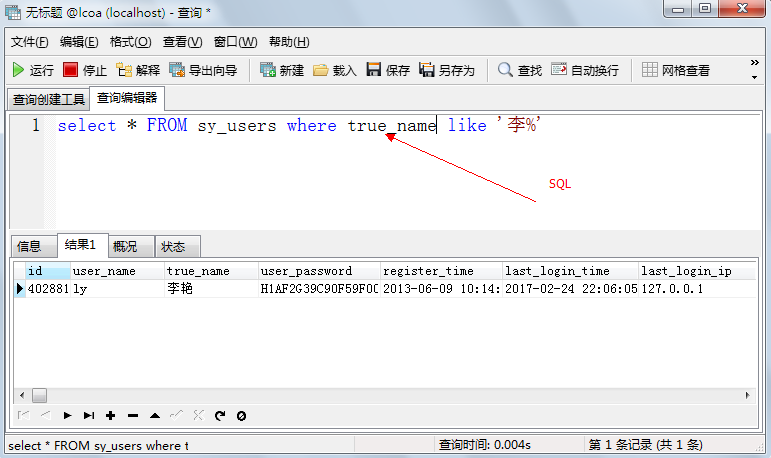
主鍵:唯一地標識表中的某一條記錄,不能空,不能重復
## 4.2、登錄數據庫

\*連接本地數據庫時需要啟動服務

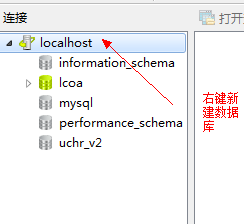
## 4.3、創建數據庫
?

## 4.4、創建表
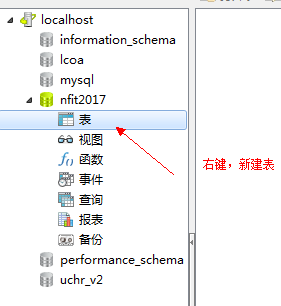

列的類型:

數字類型
整數: tinyint、smallint、mediumint、int、bigint
浮點數: float、double、real、decimal
日期和時間: date、time、datetime、timestamp、year
字符串類型
字符串: char、varchar
文本: tinytext、text、mediumtext、longtext
二進制(可用來存儲圖片、音樂等): tinyblob、blob、mediumblob、longblob
列的約束:

## 4.5、管理數據
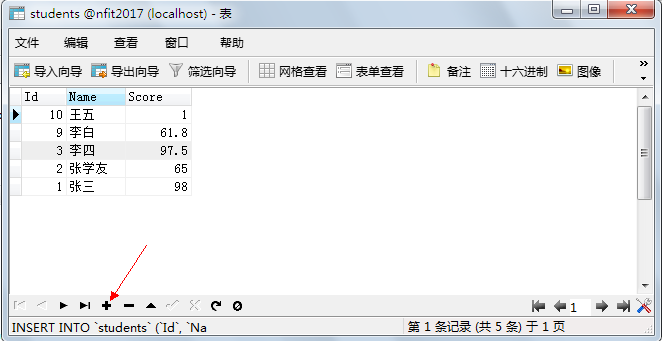
### 4.5.1、添加數據
雙擊新建好的表名,打開表,就可以添加數據了。
### 4.5.2、刪除數據

### 4.5.3、修改表結構
如果想向現有的表中添加一列,則可以修改表結構:

### 4.5.4、外鍵
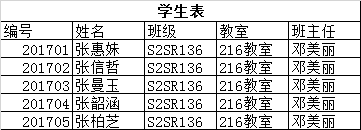
上面這個學生表是有些問題的:
a)、不便于修改,比如教室換成了305教室,則每個學員都要修改
b)、數據冗余,大量的重復數據
將表拆分成兩個,分解后問題解決,如下圖所示:

這里的班級編號就是外鍵,可以空,但不為空時他的值一定在要引用表中存在。如果學生表中的編號是主鍵這里就不應該重復,外鍵則可以重復也允許為空。
添加外鍵:
班級表:

學生表:

添加外鍵:
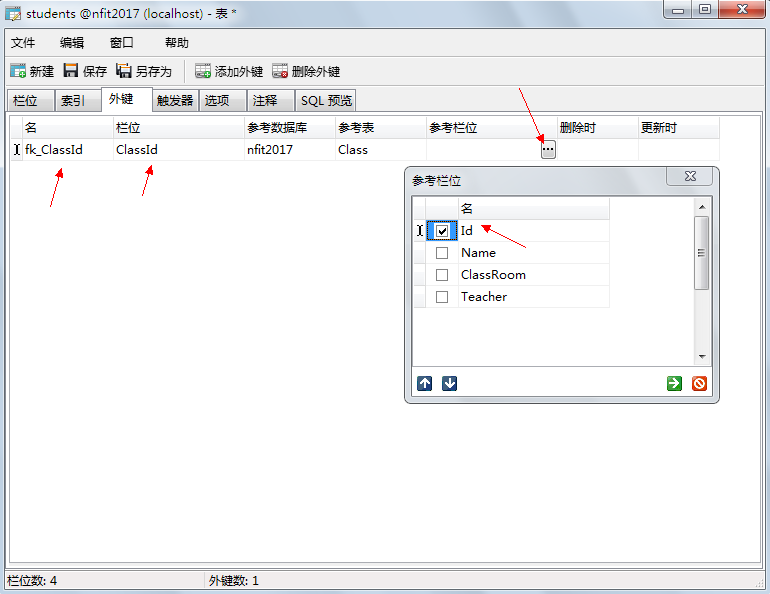
刪除與更新時可以實現級聯更新與刪除,當更新設置為CASCADE時主鍵變化引用主鍵的表也會一起變化,當刪除設置為CASCADE時刪除主鍵表,引用的記錄都將被刪除。
[](javascript:void(0); "復制代碼")
~~~
create table s_orderform(
o_id int auto_increment primary key,
o_buyer_id int,
o_seller_id int,
o_totalprices double,
o_state varchar(50),
o_information varchar(200),
foreign key(o_buyer_id) references s_user(u_id), #外鏈到s_user表的u_id字段
foreign key(o_seller_id) references s_user(u_id) #外鏈到s_user表的u_id字段
)
~~~
[](javascript:void(0); "復制代碼")
### 4.5.5、唯一鍵
唯一鍵,也稱(唯一約束),和主鍵的區別是可以為有多個唯一鍵并且值可以為NULL,但NULL也不能重復,也就是說只能有一行的值為NULL。它會隱式的創建唯一索引。
設置方法:索引 --> 添加索引 --> ?欄位名 添加你想設置唯一約束的列 --> 索引類型選擇 Unique?

[](javascript:void(0); "復制代碼")
~~~
#查詢
select id,name from yuangong
select * from yuangong
select * from yuangong where salary>5000
#增加
INSERT into yuangong(name,salary,bumenId,mobile) value('張為劍',2190.6,2,19889007867);
INSERT into yuangong(name,salary,bumenId,mobile) value('張娜拉',9871.6,1,19889007777);
#修改
update yuangong set salary=salary+1 where id=7
#刪除
INSERT into yuangong(name,salary,bumenId,mobile) value('張拉拉',9871.6,1,19889007777);
delete from yuangong where id=8
~~~
[](javascript:void(0); "復制代碼")
## 4.6、上機練習
1、請創建一個新的數據庫叫HR,在HR數據庫中添加EMP表,EMP表的表結構如下所示
EMP表:員工信息
№名稱類型描述1EMPNOint雇員的編號,主鍵,自動增長2ENAMEVARCHAR(10)雇員的姓名,由10位字符所組成,不為空,唯一鍵3JOBVARCHAR(9)雇員的職位4MGRint雇員對應的領導編號,領導也是雇員,可空(可刪除這一列)5HIREDATETimeStamp雇員的雇傭日期,默認為當前日期6SALNumeric(7,2)基本工資,其中有兩位小數,五位整數,一共是七位7COMMNumeric(7,2)獎金,傭金8DEPTNOint雇員所在的部門編號,可空,外鍵fk_deptno9DETAILText備注,可空
Dept:部門表
№名稱類型描述1DeptNOint部門的編號,主鍵,自動增長2DNAMEVARCHAR(10)部門名,由50位字符所組成,不為空,唯一鍵3DTelVARCHAR(10)電話,可空
2、根據上面的表結構完成表的創建,表名為emp
3、在表中添加5條以上的數據
4、完成下列查詢要求
4.1查詢所有員工信息
4.2查詢所有工資介于2000-5000間的員工姓名、職位與工資
4.3查詢所有姓“張”的員工
4.4 按工資降序查詢出2014年到2015年間入職的員工
4.5、將工資普遍上調20%
4.6、將工資低于3000元的員工獎金修改為工資的2.8倍
4.7、刪除編號為5或者姓“王”的員工
# 五、使用SQL訪問MySQL數據庫
## 5.0、定義學生表Stu、商品類型與商品表
(id編號,name姓名,sex性別,age年齡,...)
腳本:
[](javascript:void(0); "復制代碼")
~~~
#創建商品類型表
CREATE TABLE `category` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '編號',
`name` varchar(128) NOT NULL COMMENT '類型名稱',
`parentId` int(11) unsigned DEFAULT NULL COMMENT '父節點編號',
PRIMARY KEY (`id`),
UNIQUE KEY `un_category_name` (`name`),
KEY `fk_category_parentId` (`parentId`),
CONSTRAINT `fk_category_parentId` FOREIGN KEY (`parentId`) REFERENCES `category` (`id`) ON DELETE CASCADE ON UPDATE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8 COMMENT='商品分類';
#創建商品表
drop table if exists goods; #刪除表
create table if not exists goods
(
`id` int not null primary key auto_increment comment '編號',
`title` varchar(128) not null unique key comment '商品名稱',
`category_id` int unsigned COMMENT '商品類型編號',
`add_date` TIMESTAMP default now() comment '上貨時間',
`picture` varchar(64) comment '圖片',
`state` int default 1 comment '狀態',
FOREIGN key (`category_id`) REFERENCES category(`id`)
)COMMENT='商品'
#修改表,增加列
ALTER table goods add details text COMMENT '詳細介紹';
ALTER table goods add price DECIMAL(11,2) COMMENT '價格';
#添加記錄,單行
insert into goods(title,category_id,picture,price,details,state)
VALUES('魅族魅藍note1 ',4,'pic(1).jpg',999,'好手機',default);
#添加記錄,多行
insert into goods(title,category_id,picture,price,details)
select '魅族魅藍note2',4,'pic(2).jpg',889,'好手機' UNION
select 'iphone X',4,'pic(3).jpg',5889,'好手機' UNION
select '龍蝦',1,'pic(4).jpg',9.85,'好吃'
#查詢
select * from goods
#備份
SELECT
goods.id,
goods.title,
goods.category_id,
goods.add_date,
goods.picture,
goods.state,
goods.details,
goods.price
FROM
goods
select SYSDATE();
SELECT now();
~~~
[](javascript:void(0); "復制代碼")
### 5.0.1、新建數據庫

### 5.0.2、新建表

### 5.0.3、新建查詢

## 5.1、增加數據
insert 語句可以用來將一行或多行數據插到數據庫表中, 使用的一般形式如下:
Insert into 表名(字段列表) values (值列表);
insert \[into\] 表名 \[(列名1, 列名2, 列名3, ...)\] values (值1, 值2, 值3, ...);
insert into students values(NULL, "張三", "男", 20, "18889009876");
有時我們只需要插入部分數據, 或者不按照列的順序進行插入, 可以使用這樣的形式進行插入:
insert into students (name, sex, age) values("李四", "女", 21);


[](javascript:void(0); "復制代碼")
~~~
#1、添加數據
insert into stu(name,sex,age) values('張學友','男',18);
insert into stu(name,sex,age) values('張娜拉','女',73);
insert into stu(name,sex,age) values('張家輝','男',23);
insert into stu(name,sex,age) values('張匯美','女',85);
insert into stu(name,sex,age) values('張鐵林','男',35);
~~~
[](javascript:void(0); "復制代碼")
## 5.2、查詢數據
select 語句常用來根據一定的查詢規則到數據庫中獲取數據, 其基本的用法為:
select 字段名 from 表名稱 \[查詢條件\];
查詢學生表中的所有信息:select \* from students;
查詢學生表中所有的name與age信息:select name, age from students;
也可以使用通配符 \* 查詢表中所有的內容, 語句: select \* from students;
[](javascript:void(0); "復制代碼")
~~~
#1、添加數據
insert into stu(name,sex,age) values('張學友','男',18);
insert into stu(name,sex,age) values('張娜拉','女',73);
insert into stu(name,sex,age) values('張家輝','男',23);
insert into stu(name,sex,age) values('張匯美','女',85);
insert into stu(name,sex,age) values('張鐵林','男',35);
insert into stu(name,sex,age) values('張國立','男',99);
#2、查詢數據
#2.1、查詢所有學生
select id,name,sex,age from stu;
#2.2、查詢年齡大于80歲女學生
select id,name,sex,age from stu where age>80 and sex='女';
~~~
[](javascript:void(0); "復制代碼")
結果:

### 5.2.1、表達式與條件查詢
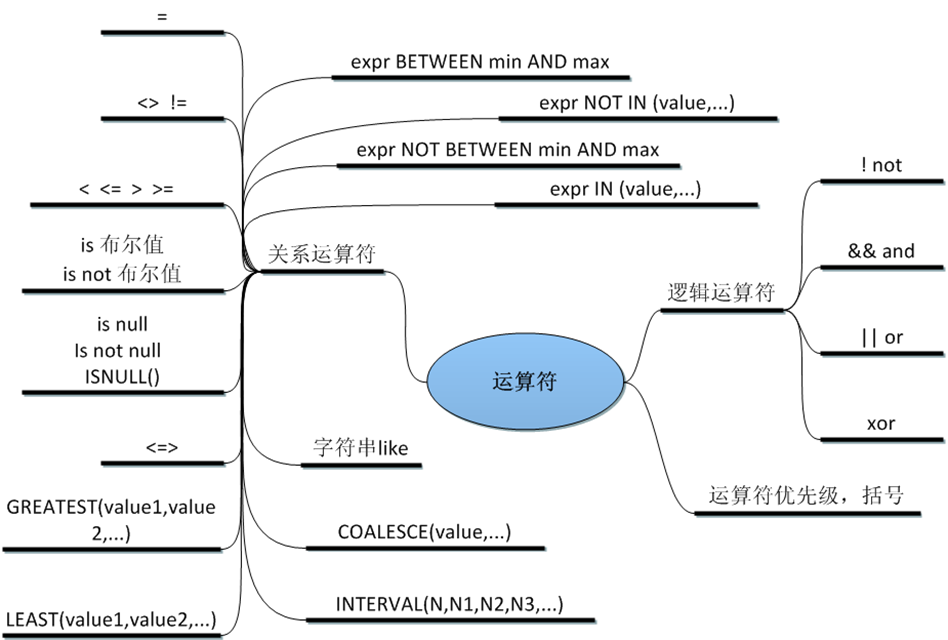
where 關鍵詞用于指定查詢條件, 用法形式為: select 列名稱 from 表名稱 where 條件;
以查詢所有性別為女的信息為例, 輸入查詢語句: select \* from students where sex="女";
where 子句不僅僅支持 "where 列名 = 值" 這種名等于值的查詢形式, 對一般的比較運算的運算符都是支持的, 例如 =、>、=、<、!= 以及一些擴展運算符 is \[not\] null、in、like 等等。 還可以對查詢條件使用 or 和 and 進行組合查詢, 以后還會學到更加高級的條件查詢方式, 這里不再多做介紹。
示例:
查詢年齡在21歲以上的所有人信息: select \* from students where age > 21;
查詢名字中帶有 "王" 字的所有人信息: select \* from students where name like "%王%";
查詢id小于5且年齡大于20的所有人信息: select \* from students where id20;
### 5.2.2、聚合函數
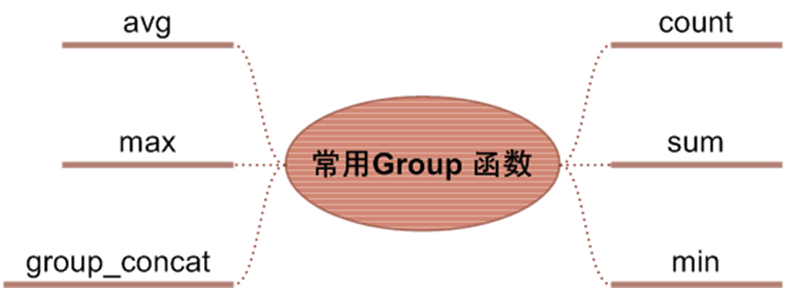
獲得學生總人數:select count(\*) from students
獲得學生平均分:select avg(mark) from students
獲得最高成績:select max(mark) from students
獲得最低成績:select min(mark) from students
獲得學生總成績:select sum(mark) from students
## 5.3、刪除數據
delete from 表名 \[刪除條件\];
刪除表中所有數據:delete from students;
刪除id為10的行: delete from students where id=10;
刪除所有年齡小于88歲的數據: delete from students where age<88;
[](javascript:void(0); "復制代碼")
~~~
#1、添加數據-----
insert into stu(name,sex,age) values('張學友','男',18);
insert into stu(name,sex,age) values('張娜拉','女',73);
insert into stu(name,sex,age) values('張家輝','男',23);
insert into stu(name,sex,age) values('張匯美','女',85);
insert into stu(name,sex,age) values('張鐵林','男',35);
insert into stu(name,sex,age) values('張國立','男',99);
#2、查詢數據-----
#2.1、查詢所有學生
select id,name,sex,age from stu;
#2.2、查詢年齡大于80歲女學生
select id,name,sex,age from stu where age>80 and sex='女';
#2.3、查詢平均年齡
select AVG(age) from stu where sex='女';
#3、修改數據-----
#3.1、將編號為1的學生年齡加大1歲
update stu set age=age+1 where id=1;
#3.2、將80歲以上的女學生年齡修改為90歲且將姓名后增加“老人”
#CONCAT(str1,str2,...) 連接字符串
update stu set age=90,name=CONCAT(name,'(老人)') where age>=80 and sex='女';
#3.3、將編號4的學生名字修改為張匯美
update stu set name='張匯美' where id=4;
#4、刪除數據-----
#4.1、刪除年齡大于70歲的學生
delete from stu where age>70;
#4.2、刪除所有學生
delete from stu;
~~~
[](javascript:void(0); "復制代碼")
## 5.4、更新數據
update 語句可用來修改表中的數據, 基本的使用形式為:
update 表名稱 set 列名稱=新值 where 更新條件;
Update 表名?set 字段=值 列表 更新條件
使用示例:
將id為5的手機號改為默認的"-": update students set tel=default where id=5;
將所有人的年齡增加1: update students set age=age+1;
將手機號為 13723887766 的姓名改為 "張果", 年齡改為 19: update students set name="張果", age=19 where tel="13723887766";
## 5.5、修改表
alter table 語句用于創建后對表的修改, 基礎用法如下:
### 5.5.1、添加列
基本形式: alter table 表名 add 列名 列數據類型 \[after 插入位置\];
示例:
在表的最后追加列 address: alter table students add address char(60);
在名為 age 的列后插入列 birthday: alter table students add birthday date after age;
### 5.5.2、修改列
基本形式: alter table 表名 change 列名稱 列新名稱 新數據類型;
示例:
將表 tel 列改名為 phone: alter table students change tel phone char(12) default "-";
將 name 列的數據類型改為 char(9): alter table students change name name char(9) not null;
### 5.5.3、刪除列
基本形式: alter table 表名 drop 列名稱;
示例:
刪除 age 列: alter table students drop age;
### 5.5.4、重命名表
基本形式: alter table 表名 rename 新表名;
示例:
重命名 students 表為temp: alter table students rename temp;
### 5.5.5、刪除表
基本形式: drop table 表名;
示例: 刪除students表: drop table students;
### 5.5.6、刪除數據庫
基本形式: drop database 數據庫名;
示例: 刪除lcoa數據庫: drop database lcoa;
### 5.5.7、一千行MySQL筆記
[](javascript:void(0); "復制代碼")
~~~
/* 啟動MySQL */
net start mysql
/* 連接與斷開服務器 */
mysql -h 地址 -P 端口 -u 用戶名 -p 密碼
/* 跳過權限驗證登錄MySQL */
mysqld --skip-grant-tables
-- 修改root密碼
密碼加密函數password()
update mysql.user set password=password('root');
SHOW PROCESSLIST -- 顯示哪些線程正在運行
SHOW VARIABLES --
/* 數據庫操作 */ ------------------
-- 查看當前數據庫
select database();
-- 顯示當前時間、用戶名、數據庫版本
select now(), user(), version();
-- 創建庫
create database[ if not exists] 數據庫名 數據庫選項
數據庫選項:
CHARACTER SET charset_name
COLLATE collation_name
-- 查看已有庫
show databases[ like 'pattern']
-- 查看當前庫信息
show create database 數據庫名
-- 修改庫的選項信息
alter database 庫名 選項信息
-- 刪除庫
drop database[ if exists] 數據庫名
同時刪除該數據庫相關的目錄及其目錄內容
/* 表的操作 */ ------------------
-- 創建表
create [temporary] table[ if not exists] [庫名.]表名 ( 表的結構定義 )[ 表選項]
每個字段必須有數據類型
最后一個字段后不能有逗號
temporary 臨時表,會話結束時表自動消失
對于字段的定義:
字段名 數據類型 [NOT NULL | NULL] [DEFAULT default_value] [AUTO_INCREMENT] [UNIQUE [KEY] | [PRIMARY] KEY] [COMMENT 'string']
-- 表選項
-- 字符集
CHARSET = charset_name
如果表沒有設定,則使用數據庫字符集
-- 存儲引擎
ENGINE = engine_name
表在管理數據時采用的不同的數據結構,結構不同會導致處理方式、提供的特性操作等不同
常見的引擎:InnoDB MyISAM Memory/Heap BDB Merge Example CSV MaxDB Archive
不同的引擎在保存表的結構和數據時采用不同的方式
MyISAM表文件含義:.frm表定義,.MYD表數據,.MYI表索引
InnoDB表文件含義:.frm表定義,表空間數據和日志文件
SHOW ENGINES -- 顯示存儲引擎的狀態信息
SHOW ENGINE 引擎名 {LOGS|STATUS} -- 顯示存儲引擎的日志或狀態信息
-- 數據文件目錄
DATA DIRECTORY = '目錄'
-- 索引文件目錄
INDEX DIRECTORY = '目錄'
-- 表注釋
COMMENT = 'string'
-- 分區選項
PARTITION BY ... (詳細見手冊)
-- 查看所有表
SHOW TABLES[ LIKE 'pattern']
SHOW TABLES FROM 表名
-- 查看表機構
SHOW CREATE TABLE 表名 (信息更詳細)
DESC 表名 / DESCRIBE 表名 / EXPLAIN 表名 / SHOW COLUMNS FROM 表名 [LIKE 'PATTERN']
SHOW TABLE STATUS [FROM db_name] [LIKE 'pattern']
-- 修改表
-- 修改表本身的選項
ALTER TABLE 表名 表的選項
EG: ALTER TABLE 表名 ENGINE=MYISAM;
-- 對表進行重命名
RENAME TABLE 原表名 TO 新表名
RENAME TABLE 原表名 TO 庫名.表名 (可將表移動到另一個數據庫)
-- RENAME可以交換兩個表名
-- 修改表的字段機構
ALTER TABLE 表名 操作名
-- 操作名
ADD[ COLUMN] 字段名 -- 增加字段
AFTER 字段名 -- 表示增加在該字段名后面
FIRST -- 表示增加在第一個
ADD PRIMARY KEY(字段名) -- 創建主鍵
ADD UNIQUE [索引名] (字段名)-- 創建唯一索引
ADD INDEX [索引名] (字段名) -- 創建普通索引
ADD
DROP[ COLUMN] 字段名 -- 刪除字段
MODIFY[ COLUMN] 字段名 字段屬性 -- 支持對字段屬性進行修改,不能修改字段名(所有原有屬性也需寫上)
CHANGE[ COLUMN] 原字段名 新字段名 字段屬性 -- 支持對字段名修改
DROP PRIMARY KEY -- 刪除主鍵(刪除主鍵前需刪除其AUTO_INCREMENT屬性)
DROP INDEX 索引名 -- 刪除索引
DROP FOREIGN KEY 外鍵 -- 刪除外鍵
-- 刪除表
DROP TABLE[ IF EXISTS] 表名 ...
-- 清空表數據
TRUNCATE [TABLE] 表名
-- 復制表結構
CREATE TABLE 表名 LIKE 要復制的表名
-- 復制表結構和數據
CREATE TABLE 表名 [AS] SELECT * FROM 要復制的表名
-- 檢查表是否有錯誤
CHECK TABLE tbl_name [, tbl_name] ... [option] ...
-- 優化表
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
-- 修復表
REPAIR [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... [QUICK] [EXTENDED] [USE_FRM]
-- 分析表
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
/* 數據操作 */ ------------------
-- 增
INSERT [INTO] 表名 [(字段列表)] VALUES (值列表)[, (值列表), ...]
-- 如果要插入的值列表包含所有字段并且順序一致,則可以省略字段列表。
-- 可同時插入多條數據記錄!
REPLACE 與 INSERT 完全一樣,可互換。
INSERT [INTO] 表名 SET 字段名=值[, 字段名=值, ...]
-- 查
SELECT 字段列表 FROM 表名[ 其他子句]
-- 可來自多個表的多個字段
-- 其他子句可以不使用
-- 字段列表可以用*代替,表示所有字段
-- 刪
DELETE FROM 表名[ 刪除條件子句]
沒有條件子句,則會刪除全部
-- 改
UPDATE 表名 SET 字段名=新值[, 字段名=新值] [更新條件]
/* 字符集編碼 */ ------------------
-- MySQL、數據庫、表、字段均可設置編碼
-- 數據編碼與客戶端編碼不需一致
SHOW VARIABLES LIKE 'character_set_%' -- 查看所有字符集編碼項
character_set_client 客戶端向服務器發送數據時使用的編碼
character_set_results 服務器端將結果返回給客戶端所使用的編碼
character_set_connection 連接層編碼
SET 變量名 = 變量值
set character_set_client = gbk;
set character_set_results = gbk;
set character_set_connection = gbk;
SET NAMES GBK; -- 相當于完成以上三個設置
-- 校對集
校對集用以排序
SHOW CHARACTER SET [LIKE 'pattern']/SHOW CHARSET [LIKE 'pattern'] 查看所有字符集
SHOW COLLATION [LIKE 'pattern'] 查看所有校對集
charset 字符集編碼 設置字符集編碼
collate 校對集編碼 設置校對集編碼
/* 數據類型(列類型) */ ------------------
1. 數值類型
-- a. 整型 ----------
類型 字節 范圍(有符號位)
tinyint 1字節 -128 ~ 127 無符號位:0 ~ 255
smallint 2字節 -32768 ~ 32767
mediumint 3字節 -8388608 ~ 8388607
int 4字節
bigint 8字節
int(M) M表示總位數
- 默認存在符號位,unsigned 屬性修改
- 顯示寬度,如果某個數不夠定義字段時設置的位數,則前面以0補填,zerofill 屬性修改
例:int(5) 插入一個數'123',補填后為'00123'
- 在滿足要求的情況下,越小越好。
- 1表示bool值真,0表示bool值假。MySQL沒有布爾類型,通過整型0和1表示。常用tinyint(1)表示布爾型。
-- b. 浮點型 ----------
類型 字節 范圍
float(單精度) 4字節
double(雙精度) 8字節
浮點型既支持符號位 unsigned 屬性,也支持顯示寬度 zerofill 屬性。
不同于整型,前后均會補填0.
定義浮點型時,需指定總位數和小數位數。
float(M, D) double(M, D)
M表示總位數,D表示小數位數。
M和D的大小會決定浮點數的范圍。不同于整型的固定范圍。
M既表示總位數(不包括小數點和正負號),也表示顯示寬度(所有顯示符號均包括)。
支持科學計數法表示。
浮點數表示近似值。
-- c. 定點數 ----------
decimal -- 可變長度
decimal(M, D) M也表示總位數,D表示小數位數。
保存一個精確的數值,不會發生數據的改變,不同于浮點數的四舍五入。
將浮點數轉換為字符串來保存,每9位數字保存為4個字節。
2. 字符串類型
-- a. char, varchar ----------
char 定長字符串,速度快,但浪費空間
varchar 變長字符串,速度慢,但節省空間
M表示能存儲的最大長度,此長度是字符數,非字節數。
不同的編碼,所占用的空間不同。
char,最多255個字符,與編碼無關。
varchar,最多65535字符,與編碼有關。
一條有效記錄最大不能超過65535個字節。
utf8 最大為21844個字符,gbk 最大為32766個字符,latin1 最大為65532個字符
varchar 是變長的,需要利用存儲空間保存 varchar 的長度,如果數據小于255個字節,則采用一個字節來保存長度,反之需要兩個字節來保存。
varchar 的最大有效長度由最大行大小和使用的字符集確定。
最大有效長度是65532字節,因為在varchar存字符串時,第一個字節是空的,不存在任何數據,然后還需兩個字節來存放字符串的長度,所以有效長度是64432-1-2=65532字節。
例:若一個表定義為 CREATE TABLE tb(c1 int, c2 char(30), c3 varchar(N)) charset=utf8; 問N的最大值是多少? 答:(65535-1-2-4-30*3)/3
-- b. blob, text ----------
blob 二進制字符串(字節字符串)
tinyblob, blob, mediumblob, longblob
text 非二進制字符串(字符字符串)
tinytext, text, mediumtext, longtext
text 在定義時,不需要定義長度,也不會計算總長度。
text 類型在定義時,不可給default值
-- c. binary, varbinary ----------
類似于char和varchar,用于保存二進制字符串,也就是保存字節字符串而非字符字符串。
char, varchar, text 對應 binary, varbinary, blob.
3. 日期時間類型
一般用整型保存時間戳,因為PHP可以很方便的將時間戳進行格式化。
datetime 8字節 日期及時間 1000-01-01 00:00:00 到 9999-12-31 23:59:59
date 3字節 日期 1000-01-01 到 9999-12-31
timestamp 4字節 時間戳 19700101000000 到 2038-01-19 03:14:07
time 3字節 時間 -838:59:59 到 838:59:59
year 1字節 年份 1901 - 2155
datetime “YYYY-MM-DD hh:mm:ss”
timestamp “YY-MM-DD hh:mm:ss”
“YYYYMMDDhhmmss”
“YYMMDDhhmmss”
YYYYMMDDhhmmss
YYMMDDhhmmss
date “YYYY-MM-DD”
“YY-MM-DD”
“YYYYMMDD”
“YYMMDD”
YYYYMMDD
YYMMDD
time “hh:mm:ss”
“hhmmss”
hhmmss
year “YYYY”
“YY”
YYYY
YY
4. 枚舉和集合
-- 枚舉(enum) ----------
enum(val1, val2, val3...)
在已知的值中進行單選。最大數量為65535.
枚舉值在保存時,以2個字節的整型(smallint)保存。每個枚舉值,按保存的位置順序,從1開始逐一遞增。
表現為字符串類型,存儲卻是整型。
NULL值的索引是NULL。
空字符串錯誤值的索引值是0。
-- 集合(set) ----------
set(val1, val2, val3...)
create table tab ( gender set('男', '女', '無') );
insert into tab values ('男, 女');
最多可以有64個不同的成員。以bigint存儲,共8個字節。采取位運算的形式。
當創建表時,SET成員值的尾部空格將自動被刪除。
/* 選擇類型 */
-- PHP角度
1. 功能滿足
2. 存儲空間盡量小,處理效率更高
3. 考慮兼容問題
-- IP存儲 ----------
1. 只需存儲,可用字符串
2. 如果需計算,查找等,可存儲為4個字節的無符號int,即unsigned
1) PHP函數轉換
ip2long可轉換為整型,但會出現攜帶符號問題。需格式化為無符號的整型。
利用sprintf函數格式化字符串
sprintf("%u", ip2long('192.168.3.134'));
然后用long2ip將整型轉回IP字符串
2) MySQL函數轉換(無符號整型,UNSIGNED)
INET_ATON('127.0.0.1') 將IP轉為整型
INET_NTOA(2130706433) 將整型轉為IP
/* 列屬性(列約束) */ ------------------
1. 主鍵
- 能唯一標識記錄的字段,可以作為主鍵。
- 一個表只能有一個主鍵。
- 主鍵具有唯一性。
- 聲明字段時,用 primary key 標識。
也可以在字段列表之后聲明
例:create table tab ( id int, stu varchar(10), primary key (id));
- 主鍵字段的值不能為null。
- 主鍵可以由多個字段共同組成。此時需要在字段列表后聲明的方法。
例:create table tab ( id int, stu varchar(10), age int, primary key (stu, age));
2. unique 唯一索引(唯一約束)
使得某字段的值也不能重復。
3. null 約束
null不是數據類型,是列的一個屬性。
表示當前列是否可以為null,表示什么都沒有。
null, 允許為空。默認。
not null, 不允許為空。
insert into tab values (null, 'val');
-- 此時表示將第一個字段的值設為null, 取決于該字段是否允許為null
4. default 默認值屬性
當前字段的默認值。
insert into tab values (default, 'val'); -- 此時表示強制使用默認值。
create table tab ( add_time timestamp default current_timestamp );
-- 表示將當前時間的時間戳設為默認值。
current_date, current_time
5. auto_increment 自動增長約束
自動增長必須為索引(主鍵或unique)
只能存在一個字段為自動增長。
默認為1開始自動增長。可以通過表屬性 auto_increment = x進行設置,或 alter table tbl auto_increment = x;
6. comment 注釋
例:create table tab ( id int ) comment '注釋內容';
7. foreign key 外鍵約束
用于限制主表與從表數據完整性。
alter table t1 add constraint `t1_t2_fk` foreign key (t1_id) references t2(id);
-- 將表t1的t1_id外鍵關聯到表t2的id字段。
-- 每個外鍵都有一個名字,可以通過 constraint 指定
存在外鍵的表,稱之為從表(子表),外鍵指向的表,稱之為主表(父表)。
作用:保持數據一致性,完整性,主要目的是控制存儲在外鍵表(從表)中的數據。
MySQL中,可以對InnoDB引擎使用外鍵約束:
語法:
foreign key (外鍵字段) references 主表名 (關聯字段) [主表記錄刪除時的動作] [主表記錄更新時的動作]
此時需要檢測一個從表的外鍵需要約束為主表的已存在的值。外鍵在沒有關聯的情況下,可以設置為null.前提是該外鍵列,沒有not null。
可以不指定主表記錄更改或更新時的動作,那么此時主表的操作被拒絕。
如果指定了 on update 或 on delete:在刪除或更新時,有如下幾個操作可以選擇:
1. cascade,級聯操作。主表數據被更新(主鍵值更新),從表也被更新(外鍵值更新)。主表記錄被刪除,從表相關記錄也被刪除。
2. set null,設置為null。主表數據被更新(主鍵值更新),從表的外鍵被設置為null。主表記錄被刪除,從表相關記錄外鍵被設置成null。但注意,要求該外鍵列,沒有not null屬性約束。
3. restrict,拒絕父表刪除和更新。
注意,外鍵只被InnoDB存儲引擎所支持。其他引擎是不支持的。
/* 建表規范 */ ------------------
-- Normal Format, NF
- 每個表保存一個實體信息
- 每個具有一個ID字段作為主鍵
- ID主鍵 + 原子表
-- 1NF, 第一范式
字段不能再分,就滿足第一范式。
-- 2NF, 第二范式
滿足第一范式的前提下,不能出現部分依賴。
消除符合主鍵就可以避免部分依賴。增加單列關鍵字。
-- 3NF, 第三范式
滿足第二范式的前提下,不能出現傳遞依賴。
某個字段依賴于主鍵,而有其他字段依賴于該字段。這就是傳遞依賴。
將一個實體信息的數據放在一個表內實現。
/* select */ ------------------
select [all|distinct] select_expr from -> where -> group by [合計函數] -> having -> order by -> limit
a. select_expr
-- 可以用 * 表示所有字段。
select * from tb;
-- 可以使用表達式(計算公式、函數調用、字段也是個表達式)
select stu, 29+25, now() from tb;
-- 可以為每個列使用別名。適用于簡化列標識,避免多個列標識符重復。
- 使用 as 關鍵字,也可省略 as.
select stu+10 as add10 from tb;
b. from 子句
用于標識查詢來源。
-- 可以為表起別名。使用as關鍵字。
select * from tb1 as tt, tb2 as bb;
-- from子句后,可以同時出現多個表。
-- 多個表會橫向疊加到一起,而數據會形成一個笛卡爾積。
select * from tb1, tb2;
c. where 子句
-- 從from獲得的數據源中進行篩選。
-- 整型1表示真,0表示假。
-- 表達式由運算符和運算數組成。
-- 運算數:變量(字段)、值、函數返回值
-- 運算符:
=, <=>, <>, !=, <=, <, >=, >, !, &&, ||,
in (not) null, (not) like, (not) in, (not) between and, is (not), and, or, not, xor
is/is not 加上ture/false/unknown,檢驗某個值的真假
<=>與<>功能相同,<=>可用于null比較
d. group by 子句, 分組子句
group by 字段/別名 [排序方式]
分組后會進行排序。升序:ASC,降序:DESC
以下[合計函數]需配合 group by 使用:
count 返回不同的非NULL值數目 count(*)、count(字段)
sum 求和
max 求最大值
min 求最小值
avg 求平均值
group_concat 返回帶有來自一個組的連接的非NULL值的字符串結果。組內字符串連接。
e. having 子句,條件子句
與 where 功能、用法相同,執行時機不同。
where 在開始時執行檢測數據,對原數據進行過濾。
having 對篩選出的結果再次進行過濾。
having 字段必須是查詢出來的,where 字段必須是數據表存在的。
where 不可以使用字段的別名,having 可以。因為執行WHERE代碼時,可能尚未確定列值。
where 不可以使用合計函數。一般需用合計函數才會用 having
SQL標準要求HAVING必須引用GROUP BY子句中的列或用于合計函數中的列。
f. order by 子句,排序子句
order by 排序字段/別名 排序方式 [,排序字段/別名 排序方式]...
升序:ASC,降序:DESC
支持多個字段的排序。
g. limit 子句,限制結果數量子句
僅對處理好的結果進行數量限制。將處理好的結果的看作是一個集合,按照記錄出現的順序,索引從0開始。
limit 起始位置, 獲取條數
省略第一個參數,表示從索引0開始。limit 獲取條數
h. distinct, all 選項
distinct 去除重復記錄
默認為 all, 全部記錄
/* UNION */ ------------------
將多個select查詢的結果組合成一個結果集合。
SELECT ... UNION [ALL|DISTINCT] SELECT ...
默認 DISTINCT 方式,即所有返回的行都是唯一的
建議,對每個SELECT查詢加上小括號包裹。
ORDER BY 排序時,需加上 LIMIT 進行結合。
需要各select查詢的字段數量一樣。
每個select查詢的字段列表(數量、類型)應一致,因為結果中的字段名以第一條select語句為準。
/* 子查詢 */ ------------------
- 子查詢需用括號包裹。
-- from型
from后要求是一個表,必須給子查詢結果取個別名。
- 簡化每個查詢內的條件。
- from型需將結果生成一個臨時表格,可用以原表的鎖定的釋放。
- 子查詢返回一個表,表型子查詢。
select * from (select * from tb where id>0) as subfrom where id>1;
-- where型
- 子查詢返回一個值,標量子查詢。
- 不需要給子查詢取別名。
- where子查詢內的表,不能直接用以更新。
select * from tb where money = (select max(money) from tb);
-- 列子查詢
如果子查詢結果返回的是一列。
使用 in 或 not in 完成查詢
exists 和 not exists 條件
如果子查詢返回數據,則返回1或0。常用于判斷條件。
select column1 from t1 where exists (select * from t2);
-- 行子查詢
查詢條件是一個行。
select * from t1 where (id, gender) in (select id, gender from t2);
行構造符:(col1, col2, ...) 或 ROW(col1, col2, ...)
行構造符通常用于與對能返回兩個或兩個以上列的子查詢進行比較。
-- 特殊運算符
!= all() 相當于 not in
= some() 相當于 in。any 是 some 的別名
!= some() 不等同于 not in,不等于其中某一個。
all, some 可以配合其他運算符一起使用。
/* 連接查詢(join) */ ------------------
將多個表的字段進行連接,可以指定連接條件。
-- 內連接(inner join)
- 默認就是內連接,可省略inner。
- 只有數據存在時才能發送連接。即連接結果不能出現空行。
on 表示連接條件。其條件表達式與where類似。也可以省略條件(表示條件永遠為真)
也可用where表示連接條件。
還有 using, 但需字段名相同。 using(字段名)
-- 交叉連接 cross join
即,沒有條件的內連接。
select * from tb1 cross join tb2;
-- 外連接(outer join)
- 如果數據不存在,也會出現在連接結果中。
-- 左外連接 left join
如果數據不存在,左表記錄會出現,而右表為null填充
-- 右外連接 right join
如果數據不存在,右表記錄會出現,而左表為null填充
-- 自然連接(natural join)
自動判斷連接條件完成連接。
相當于省略了using,會自動查找相同字段名。
natural join
natural left join
natural right join
select info.id, info.name, info.stu_num, extra_info.hobby, extra_info.sex from info, extra_info where info.stu_num = extra_info.stu_id;
/* 導入導出 */ ------------------
select * into outfile 文件地址 [控制格式] from 表名; -- 導出表數據
load data [local] infile 文件地址 [replace|ignore] into table 表名 [控制格式]; -- 導入數據
生成的數據默認的分隔符是制表符
local未指定,則數據文件必須在服務器上
replace 和 ignore 關鍵詞控制對現有的唯一鍵記錄的重復的處理
-- 控制格式
fields 控制字段格式
默認:fields terminated by '\t' enclosed by '' escaped by '\\'
terminated by 'string' -- 終止
enclosed by 'char' -- 包裹
escaped by 'char' -- 轉義
-- 示例:
SELECT a,b,a+b INTO OUTFILE '/tmp/result.text'
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
FROM test_table;
lines 控制行格式
默認:lines terminated by '\n'
terminated by 'string' -- 終止
/* insert */ ------------------
select語句獲得的數據可以用insert插入。
可以省略對列的指定,要求 values () 括號內,提供給了按照列順序出現的所有字段的值。
或者使用set語法。
insert into tbl_name set field=value,...;
可以一次性使用多個值,采用(), (), ();的形式。
insert into tbl_name values (), (), ();
可以在列值指定時,使用表達式。
insert into tbl_name values (field_value, 10+10, now());
可以使用一個特殊值 default,表示該列使用默認值。
insert into tbl_name values (field_value, default);
可以通過一個查詢的結果,作為需要插入的值。
insert into tbl_name select ...;
可以指定在插入的值出現主鍵(或唯一索引)沖突時,更新其他非主鍵列的信息。
insert into tbl_name values/set/select on duplicate key update 字段=值, …;
/* delete */ ------------------
DELETE FROM tbl_name [WHERE where_definition] [ORDER BY ...] [LIMIT row_count]
按照條件刪除
指定刪除的最多記錄數。Limit
可以通過排序條件刪除。order by + limit
支持多表刪除,使用類似連接語法。
delete from 需要刪除數據多表1,表2 using 表連接操作 條件。
/* truncate */ ------------------
TRUNCATE [TABLE] tbl_name
清空數據
刪除重建表
區別:
1,truncate 是刪除表再創建,delete 是逐條刪除
2,truncate 重置auto_increment的值。而delete不會
3,truncate 不知道刪除了幾條,而delete知道。
4,當被用于帶分區的表時,truncate 會保留分區
/* 備份與還原 */ ------------------
備份,將數據的結構與表內數據保存起來。
利用 mysqldump 指令完成。
-- 導出
1. 導出一張表
mysqldump -u用戶名 -p密碼 庫名 表名 > 文件名(D:/a.sql)
2. 導出多張表
mysqldump -u用戶名 -p密碼 庫名 表1 表2 表3 > 文件名(D:/a.sql)
3. 導出所有表
mysqldump -u用戶名 -p密碼 庫名 > 文件名(D:/a.sql)
4. 導出一個庫
mysqldump -u用戶名 -p密碼 -B 庫名 > 文件名(D:/a.sql)
可以-w攜帶備份條件
-- 導入
1. 在登錄mysql的情況下:
source 備份文件
2. 在不登錄的情況下
mysql -u用戶名 -p密碼 庫名 < 備份文件
/* 視圖 */ ------------------
什么是視圖:
視圖是一個虛擬表,其內容由查詢定義。同真實的表一樣,視圖包含一系列帶有名稱的列和行數據。但是,視圖并不在數據庫中以存儲的數據值集形式存在。行和列數據來自由定義視圖的查詢所引用的表,并且在引用視圖時動態生成。
視圖具有表結構文件,但不存在數據文件。
對其中所引用的基礎表來說,視圖的作用類似于篩選。定義視圖的篩選可以來自當前或其它數據庫的一個或多個表,或者其它視圖。通過視圖進行查詢沒有任何限制,通過它們進行數據修改時的限制也很少。
視圖是存儲在數據庫中的查詢的sql語句,它主要出于兩種原因:安全原因,視圖可以隱藏一些數據,如:社會保險基金表,可以用視圖只顯示姓名,地址,而不顯示社會保險號和工資數等,另一原因是可使復雜的查詢易于理解和使用。
-- 創建視圖
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW view_name [(column_list)] AS select_statement
- 視圖名必須唯一,同時不能與表重名。
- 視圖可以使用select語句查詢到的列名,也可以自己指定相應的列名。
- 可以指定視圖執行的算法,通過ALGORITHM指定。
- column_list如果存在,則數目必須等于SELECT語句檢索的列數
-- 查看結構
SHOW CREATE VIEW view_name
-- 刪除視圖
- 刪除視圖后,數據依然存在。
- 可同時刪除多個視圖。
DROP VIEW [IF EXISTS] view_name ...
-- 修改視圖結構
- 一般不修改視圖,因為不是所有的更新視圖都會映射到表上。
ALTER VIEW view_name [(column_list)] AS select_statement
-- 視圖作用
1. 簡化業務邏輯
2. 對客戶端隱藏真實的表結構
-- 視圖算法(ALGORITHM)
MERGE 合并
將視圖的查詢語句,與外部查詢需要先合并再執行!
TEMPTABLE 臨時表
將視圖執行完畢后,形成臨時表,再做外層查詢!
UNDEFINED 未定義(默認),指的是MySQL自主去選擇相應的算法。
/* 事務(transaction) */ ------------------
事務是指邏輯上的一組操作,組成這組操作的各個單元,要不全成功要不全失敗。
- 支持連續SQL的集體成功或集體撤銷。
- 事務是數據庫在數據晚自習方面的一個功能。
- 需要利用 InnoDB 或 BDB 存儲引擎,對自動提交的特性支持完成。
- InnoDB被稱為事務安全型引擎。
-- 事務開啟
START TRANSACTION; 或者 BEGIN;
開啟事務后,所有被執行的SQL語句均被認作當前事務內的SQL語句。
-- 事務提交
COMMIT;
-- 事務回滾
ROLLBACK;
如果部分操作發生問題,映射到事務開啟前。
-- 事務的特性
1. 原子性(Atomicity)
事務是一個不可分割的工作單位,事務中的操作要么都發生,要么都不發生。
2. 一致性(Consistency)
事務前后數據的完整性必須保持一致。
- 事務開始和結束時,外部數據一致
- 在整個事務過程中,操作是連續的
3. 隔離性(Isolation)
多個用戶并發訪問數據庫時,一個用戶的事務不能被其它用戶的事物所干擾,多個并發事務之間的數據要相互隔離。
4. 持久性(Durability)
一個事務一旦被提交,它對數據庫中的數據改變就是永久性的。
-- 事務的實現
1. 要求是事務支持的表類型
2. 執行一組相關的操作前開啟事務
3. 整組操作完成后,都成功,則提交;如果存在失敗,選擇回滾,則會回到事務開始的備份點。
-- 事務的原理
利用InnoDB的自動提交(autocommit)特性完成。
普通的MySQL執行語句后,當前的數據提交操作均可被其他客戶端可見。
而事務是暫時關閉“自動提交”機制,需要commit提交持久化數據操作。
-- 注意
1. 數據定義語言(DDL)語句不能被回滾,比如創建或取消數據庫的語句,和創建、取消或更改表或存儲的子程序的語句。
2. 事務不能被嵌套
-- 保存點
SAVEPOINT 保存點名稱 -- 設置一個事務保存點
ROLLBACK TO SAVEPOINT 保存點名稱 -- 回滾到保存點
RELEASE SAVEPOINT 保存點名稱 -- 刪除保存點
-- InnoDB自動提交特性設置
SET autocommit = 0|1; 0表示關閉自動提交,1表示開啟自動提交。
- 如果關閉了,那普通操作的結果對其他客戶端也不可見,需要commit提交后才能持久化數據操作。
- 也可以關閉自動提交來開啟事務。但與START TRANSACTION不同的是,
SET autocommit是永久改變服務器的設置,直到下次再次修改該設置。(針對當前連接)
而START TRANSACTION記錄開啟前的狀態,而一旦事務提交或回滾后就需要再次開啟事務。(針對當前事務)
/* 鎖表 */
表鎖定只用于防止其它客戶端進行不正當地讀取和寫入
MyISAM 支持表鎖,InnoDB 支持行鎖
-- 鎖定
LOCK TABLES tbl_name [AS alias]
-- 解鎖
UNLOCK TABLES
/* 觸發器 */ ------------------
觸發程序是與表有關的命名數據庫對象,當該表出現特定事件時,將激活該對象
監聽:記錄的增加、修改、刪除。
-- 創建觸發器
CREATE TRIGGER trigger_name trigger_time trigger_event ON tbl_name FOR EACH ROW trigger_stmt
參數:
trigger_time是觸發程序的動作時間。它可以是 before 或 after,以指明觸發程序是在激活它的語句之前或之后觸發。
trigger_event指明了激活觸發程序的語句的類型
INSERT:將新行插入表時激活觸發程序
UPDATE:更改某一行時激活觸發程序
DELETE:從表中刪除某一行時激活觸發程序
tbl_name:監聽的表,必須是永久性的表,不能將觸發程序與TEMPORARY表或視圖關聯起來。
trigger_stmt:當觸發程序激活時執行的語句。執行多個語句,可使用BEGIN...END復合語句結構
-- 刪除
DROP TRIGGER [schema_name.]trigger_name
可以使用old和new代替舊的和新的數據
更新操作,更新前是old,更新后是new.
刪除操作,只有old.
增加操作,只有new.
-- 注意
1. 對于具有相同觸發程序動作時間和事件的給定表,不能有兩個觸發程序。
-- 字符連接函數
concat(str1[, str2,...])
-- 分支語句
if 條件 then
執行語句
elseif 條件 then
執行語句
else
執行語句
end if;
-- 修改最外層語句結束符
delimiter 自定義結束符號
SQL語句
自定義結束符號
delimiter ; -- 修改回原來的分號
-- 語句塊包裹
begin
語句塊
end
-- 特殊的執行
1. 只要添加記錄,就會觸發程序。
2. Insert into on duplicate key update 語法會觸發:
如果沒有重復記錄,會觸發 before insert, after insert;
如果有重復記錄并更新,會觸發 before insert, before update, after update;
如果有重復記錄但是沒有發生更新,則觸發 before insert, before update
3. Replace 語法 如果有記錄,則執行 before insert, before delete, after delete, after insert
/* SQL編程 */ ------------------
--// 局部變量 ----------
-- 變量聲明
declare var_name[,...] type [default value]
這個語句被用來聲明局部變量。要給變量提供一個默認值,請包含一個default子句。值可以被指定為一個表達式,不需要為一個常數。如果沒有default子句,初始值為null。
-- 賦值
使用 set 和 select into 語句為變量賦值。
- 注意:在函數內是可以使用全局變量(用戶自定義的變量)
--// 全局變量 ----------
-- 定義、賦值
set 語句可以定義并為變量賦值。
set @var = value;
也可以使用select into語句為變量初始化并賦值。這樣要求select語句只能返回一行,但是可以是多個字段,就意味著同時為多個變量進行賦值,變量的數量需要與查詢的列數一致。
還可以把賦值語句看作一個表達式,通過select執行完成。此時為了避免=被當作關系運算符看待,使用:=代替。(set語句可以使用= 和 :=)。
select @var:=20;
select @v1:=id, @v2=name from t1 limit 1;
select * from tbl_name where @var:=30;
select into 可以將表中查詢獲得的數據賦給變量。
-| select max(height) into @max_height from tb;
-- 自定義變量名
為了避免select語句中,用戶自定義的變量與系統標識符(通常是字段名)沖突,用戶自定義變量在變量名前使用@作為開始符號。
@var=10;
- 變量被定義后,在整個會話周期都有效(登錄到退出)
--// 控制結構 ----------
-- if語句
if search_condition then
statement_list
[elseif search_condition then
statement_list]
...
[else
statement_list]
end if;
-- case語句
CASE value WHEN [compare-value] THEN result
[WHEN [compare-value] THEN result ...]
[ELSE result]
END
-- while循環
[begin_label:] while search_condition do
statement_list
end while [end_label];
- 如果需要在循環內提前終止 while循環,則需要使用標簽;標簽需要成對出現。
-- 退出循環
退出整個循環 leave
退出當前循環 iterate
通過退出的標簽決定退出哪個循環
--// 內置函數 ----------
-- 數值函數
abs(x) -- 絕對值 abs(-10.9) = 10
format(x, d) -- 格式化千分位數值 format(1234567.456, 2) = 1,234,567.46
ceil(x) -- 向上取整 ceil(10.1) = 11
floor(x) -- 向下取整 floor (10.1) = 10
round(x) -- 四舍五入去整
mod(m, n) -- m%n m mod n 求余 10%3=1
pi() -- 獲得圓周率
pow(m, n) -- m^n
sqrt(x) -- 算術平方根
rand() -- 隨機數
truncate(x, d) -- 截取d位小數
-- 時間日期函數
now(), current_timestamp(); -- 當前日期時間
current_date(); -- 當前日期
current_time(); -- 當前時間
date('yyyy-mm-dd hh:ii:ss'); -- 獲取日期部分
time('yyyy-mm-dd hh:ii:ss'); -- 獲取時間部分
date_format('yyyy-mm-dd hh:ii:ss', '%d %y %a %d %m %b %j'); -- 格式化時間
unix_timestamp(); -- 獲得unix時間戳
from_unixtime(); -- 從時間戳獲得時間
-- 字符串函數
length(string) -- string長度,字節
char_length(string) -- string的字符個數
substring(str, position [,length]) -- 從str的position開始,取length個字符
replace(str ,search_str ,replace_str) -- 在str中用replace_str替換search_str
instr(string ,substring) -- 返回substring首次在string中出現的位置
concat(string [,...]) -- 連接字串
charset(str) -- 返回字串字符集
lcase(string) -- 轉換成小寫
left(string, length) -- 從string2中的左邊起取length個字符
load_file(file_name) -- 從文件讀取內容
locate(substring, string [,start_position]) -- 同instr,但可指定開始位置
lpad(string, length, pad) -- 重復用pad加在string開頭,直到字串長度為length
ltrim(string) -- 去除前端空格
repeat(string, count) -- 重復count次
rpad(string, length, pad) --在str后用pad補充,直到長度為length
rtrim(string) -- 去除后端空格
strcmp(string1 ,string2) -- 逐字符比較兩字串大小
-- 流程函數
case when [condition] then result [when [condition] then result ...] [else result] end 多分支
if(expr1,expr2,expr3) 雙分支。
-- 聚合函數
count()
sum();
max();
min();
avg();
group_concat()
-- 其他常用函數
md5();
default();
--// 存儲函數,自定義函數 ----------
-- 新建
CREATE FUNCTION function_name (參數列表) RETURNS 返回值類型
函數體
- 函數名,應該合法的標識符,并且不應該與已有的關鍵字沖突。
- 一個函數應該屬于某個數據庫,可以使用db_name.funciton_name的形式執行當前函數所屬數據庫,否則為當前數據庫。
- 參數部分,由"參數名"和"參數類型"組成。多個參數用逗號隔開。
- 函數體由多條可用的mysql語句,流程控制,變量聲明等語句構成。
- 多條語句應該使用 begin...end 語句塊包含。
- 一定要有 return 返回值語句。
-- 刪除
DROP FUNCTION [IF EXISTS] function_name;
-- 查看
SHOW FUNCTION STATUS LIKE 'partten'
SHOW CREATE FUNCTION function_name;
-- 修改
ALTER FUNCTION function_name 函數選項
--// 存儲過程,自定義功能 ----------
-- 定義
存儲存儲過程 是一段代碼(過程),存儲在數據庫中的sql組成。
一個存儲過程通常用于完成一段業務邏輯,例如報名,交班費,訂單入庫等。
而一個函數通常專注與某個功能,視為其他程序服務的,需要在其他語句中調用函數才可以,而存儲過程不能被其他調用,是自己執行 通過call執行。
-- 創建
CREATE PROCEDURE sp_name (參數列表)
過程體
參數列表:不同于函數的參數列表,需要指明參數類型
IN,表示輸入型
OUT,表示輸出型
INOUT,表示混合型
注意,沒有返回值。
/* 存儲過程 */ ------------------
存儲過程是一段可執行性代碼的集合。相比函數,更偏向于業務邏輯。
調用:CALL 過程名
-- 注意
- 沒有返回值。
- 只能單獨調用,不可夾雜在其他語句中
-- 參數
IN|OUT|INOUT 參數名 數據類型
IN 輸入:在調用過程中,將數據輸入到過程體內部的參數
OUT 輸出:在調用過程中,將過程體處理完的結果返回到客戶端
INOUT 輸入輸出:既可輸入,也可輸出
-- 語法
CREATE PROCEDURE 過程名 (參數列表)
BEGIN
過程體
END
/* 用戶和權限管理 */ ------------------
用戶信息表:mysql.user
-- 刷新權限
FLUSH PRIVILEGES
-- 增加用戶
CREATE USER 用戶名 IDENTIFIED BY [PASSWORD] 密碼(字符串)
- 必須擁有mysql數據庫的全局CREATE USER權限,或擁有INSERT權限。
- 只能創建用戶,不能賦予權限。
- 用戶名,注意引號:如 'user_name'@'192.168.1.1'
- 密碼也需引號,純數字密碼也要加引號
- 要在純文本中指定密碼,需忽略PASSWORD關鍵詞。要把密碼指定為由PASSWORD()函數返回的混編值,需包含關鍵字PASSWORD
-- 重命名用戶
RENAME USER old_user TO new_user
-- 設置密碼
SET PASSWORD = PASSWORD('密碼') -- 為當前用戶設置密碼
SET PASSWORD FOR 用戶名 = PASSWORD('密碼') -- 為指定用戶設置密碼
-- 刪除用戶
DROP USER 用戶名
-- 分配權限/添加用戶
GRANT 權限列表 ON 表名 TO 用戶名 [IDENTIFIED BY [PASSWORD] 'password']
- all privileges 表示所有權限
- *.* 表示所有庫的所有表
- 庫名.表名 表示某庫下面的某表
-- 查看權限
SHOW GRANTS FOR 用戶名
-- 查看當前用戶權限
SHOW GRANTS; 或 SHOW GRANTS FOR CURRENT_USER; 或 SHOW GRANTS FOR CURRENT_USER();
-- 撤消權限
REVOKE 權限列表 ON 表名 FROM 用戶名
REVOKE ALL PRIVILEGES, GRANT OPTION FROM 用戶名 -- 撤銷所有權限
-- 權限層級
-- 要使用GRANT或REVOKE,您必須擁有GRANT OPTION權限,并且您必須用于您正在授予或撤銷的權限。
全局層級:全局權限適用于一個給定服務器中的所有數據庫,mysql.user
GRANT ALL ON *.*和 REVOKE ALL ON *.*只授予和撤銷全局權限。
數據庫層級:數據庫權限適用于一個給定數據庫中的所有目標,mysql.db, mysql.host
GRANT ALL ON db_name.*和REVOKE ALL ON db_name.*只授予和撤銷數據庫權限。
表層級:表權限適用于一個給定表中的所有列,mysql.talbes_priv
GRANT ALL ON db_name.tbl_name和REVOKE ALL ON db_name.tbl_name只授予和撤銷表權限。
列層級:列權限適用于一個給定表中的單一列,mysql.columns_priv
當使用REVOKE時,您必須指定與被授權列相同的列。
-- 權限列表
ALL [PRIVILEGES] -- 設置除GRANT OPTION之外的所有簡單權限
ALTER -- 允許使用ALTER TABLE
ALTER ROUTINE -- 更改或取消已存儲的子程序
CREATE -- 允許使用CREATE TABLE
CREATE ROUTINE -- 創建已存儲的子程序
CREATE TEMPORARY TABLES -- 允許使用CREATE TEMPORARY TABLE
CREATE USER -- 允許使用CREATE USER, DROP USER, RENAME USER和REVOKE ALL PRIVILEGES。
CREATE VIEW -- 允許使用CREATE VIEW
DELETE -- 允許使用DELETE
DROP -- 允許使用DROP TABLE
EXECUTE -- 允許用戶運行已存儲的子程序
FILE -- 允許使用SELECT...INTO OUTFILE和LOAD DATA INFILE
INDEX -- 允許使用CREATE INDEX和DROP INDEX
INSERT -- 允許使用INSERT
LOCK TABLES -- 允許對您擁有SELECT權限的表使用LOCK TABLES
PROCESS -- 允許使用SHOW FULL PROCESSLIST
REFERENCES -- 未被實施
RELOAD -- 允許使用FLUSH
REPLICATION CLIENT -- 允許用戶詢問從屬服務器或主服務器的地址
REPLICATION SLAVE -- 用于復制型從屬服務器(從主服務器中讀取二進制日志事件)
SELECT -- 允許使用SELECT
SHOW DATABASES -- 顯示所有數據庫
SHOW VIEW -- 允許使用SHOW CREATE VIEW
SHUTDOWN -- 允許使用mysqladmin shutdown
SUPER -- 允許使用CHANGE MASTER, KILL, PURGE MASTER LOGS和SET GLOBAL語句,mysqladmin debug命令;允許您連接(一次),即使已達到max_connections。
UPDATE -- 允許使用UPDATE
USAGE -- “無權限”的同義詞
GRANT OPTION -- 允許授予權限
/* 表維護 */
-- 分析和存儲表的關鍵字分布
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE 表名 ...
-- 檢查一個或多個表是否有錯誤
CHECK TABLE tbl_name [, tbl_name] ... [option] ...
option = {QUICK | FAST | MEDIUM | EXTENDED | CHANGED}
-- 整理數據文件的碎片
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
/* 雜項 */ ------------------
1. 可用反引號(`)為標識符(庫名、表名、字段名、索引、別名)包裹,以避免與關鍵字重名!中文也可以作為標識符!
2. 每個庫目錄存在一個保存當前數據庫的選項文件db.opt。
3. 注釋:
單行注釋 # 注釋內容
多行注釋 /* 注釋內容 */
單行注釋 -- 注釋內容 (標準SQL注釋風格,要求雙破折號后加一空格符(空格、TAB、換行等))
4. 模式通配符:
_ 任意單個字符
% 任意多個字符,甚至包括零字符
單引號需要進行轉義 \'
5. CMD命令行內的語句結束符可以為 ";", "\G", "\g",僅影響顯示結果。其他地方還是用分號結束。delimiter 可修改當前對話的語句結束符。
6. SQL對大小寫不敏感
7. 清除已有語句:\c
~~~
[](javascript:void(0); "復制代碼")
### 5.5.8、常用的SQL
[](javascript:void(0); "復制代碼")
~~~
/*==============================================================*/
/* DBMS name: MySQL 5.0 */
/* Created on: 2017/3/5 10:29:05 */
/*==============================================================*/
drop table if exists Address;
drop table if exists ArticleComment;
drop table if exists ArticleType;
drop table if exists Articles;
drop table if exists DictSub;
drop table if exists DictTop;
drop table if exists OrderPdt;
drop table if exists Orders;
drop table if exists ProductComment;
drop table if exists Products;
drop table if exists Users;
/*==============================================================*/
/* Table: Address */
/*==============================================================*/
create table Address
(
`AddressId` int not null auto_increment comment '收貨地址編號',
`UserId` int not null comment '用戶編號',
`Province` varchar(50) not null comment '省',
`City` varchar(50) not null comment '市',
`County` varchar(50) not null comment '縣/區',
`Street` varchar(300) not null comment '詳細地址',
`RevName` varchar(30) not null comment '收貨人姓名',
`PostCode` varchar(20) comment '郵政編碼',
`Mobile` varchar(50) not null comment '手機',
`Phone` varchar(50) comment '電話',
`IsDefault` bool comment '是否為默認地址',
primary key (AddressId)
);
alter table Address comment '收貨地址';
/*==============================================================*/
/* Table: ArticleComment */
/*==============================================================*/
create table ArticleComment
(
`ArticleCommentId` int not null auto_increment comment '文章評論編號',
`ArticleId` int not null comment '文章編號',
`UserId` int not null comment '用戶編號',
`ArticleCommentContent` varchar(4000) not null comment '文章評論內容',
`ArticleCommentDate` timestamp default CURRENT_TIMESTAMP comment '文章評論時間',
`ArticleCommentState` int default 1 comment '狀態',
`ArticleRemark` int comment '打分',
`ArticleCommentReserver1` varchar(4000) comment '備用1',
`ArticleCommentReserver2` varchar(4000) comment '備用2',
primary key (ArticleCommentId)
);
alter table ArticleComment comment '文章評論';
/*==============================================================*/
/* Table: ArticleType */
/*==============================================================*/
create table ArticleType
(
`ArticleTypeId` int not null auto_increment comment '文章欄目編號',
`ArticleTypeName` varchar(200) comment '文章欄目名稱',
`ArticleTypeState` int default 1 comment '狀態',
`ArticleTypeDesc` varchar(4000) comment '文章欄目描述',
`ArticleTypePicture` varchar(400) comment '文章欄目圖片',
`ArticleTypeReserve1` varchar(4000) comment '備用1',
`ArticleTypeReserve2` varchar(4000) comment '備用2',
primary key (ArticleTypeId)
);
alter table ArticleType comment '文章欄目';
/*==============================================================*/
/* Table: Articles */
/*==============================================================*/
create table Articles
(
`ArticleId` int not null auto_increment comment '文章編號',
`ArticleTypeId` int not null comment '文章欄目編號',
`ArticleTitle` varchar(400) not null comment '文章標題',
`ArticleContent` text comment '文章內容',
`ArticleDate` timestamp default CURRENT_TIMESTAMP comment '文章發布時間',
`ArticleAuthor` varchar(200) comment '文章發布者',
`ArticleFileName` varchar(100) comment '靜態文件名',
`ArticleThumbNail` varchar(200) comment '縮略圖片',
`ArticleAddition` varchar(200) comment '附件名稱',
`ArticleLevel` int comment '顯示的優先級',
`ArticleIsAllowComment` integer default 1 comment '是否允許評論',
`ArticleState` int default 1 comment '狀態',
`ArticleHotCount` int comment '點擊次數',
`ArticleReserve1` varchar(4000) comment '備用1',
`ArticleReserve2` varchar(4000) comment '備用2',
`ArticleReserve3` numeric(8,0) comment '備用3',
primary key (ArticleId)
);
alter table Articles comment '文章';
/*==============================================================*/
/* Table: DictSub */
/*==============================================================*/
create table DictSub
(
`SubId` int not null auto_increment comment '子項編號',
`DictId` int not null comment '字典編號',
`SubName` varchar(200) not null comment '子項名稱',
`SubDesc` varchar(4000) comment '子項描述',
`SubReserve1` varchar(4000) comment '保留備用1',
primary key (SubId)
);
alter table DictSub comment '字典子項';
/*==============================================================*/
/* Table: DictTop */
/*==============================================================*/
create table DictTop
(
`DictId` int not null auto_increment comment '字典編號',
`DictName` varchar(100) not null comment '字典名稱',
`DictDesc` varchar(4000) comment '字典描述',
`DictReserve1` varchar(4000) comment '保留備用',
primary key (DictId)
);
alter table DictTop comment '字典';
/*==============================================================*/
/* Table: OrderPdt */
/*==============================================================*/
create table OrderPdt
(
`OrderPdtId` int not null auto_increment comment '訂單商品編號',
`Id` int not null comment '編號',
`UserId` int not null comment '用戶編號',
`OrderId` int comment '訂單號',
`PdtAmount` int comment '訂購數量',
`PdtPrice` decimal comment '單價',
`PdtReserve1` varchar(2000) comment '備用1',
`PdtReserve2` varchar(4000) comment '備用2',
primary key (OrderPdtId)
);
alter table OrderPdt comment '訂單商品';
/*==============================================================*/
/* Table: Orders */
/*==============================================================*/
create table Orders
(
`OrderId` int not null auto_increment comment '訂單號',
`AddressId` int not null comment '收貨地址編號',
`OrderState` int default 1 comment '訂單狀態',
`ExpressNO` varchar(50) comment '快遞編號',
`ExpressName` varchar(50) comment '快遞名稱',
`PayMoney` decimal comment '應支付',
`PayedMoney` decimal comment '已支付',
`SendInfo` varchar(300) comment '發貨人信息',
`BuyDate` timestamp default CURRENT_TIMESTAMP comment '下單時間',
`PayDate` datetime comment '支付時間',
`SendDate` datetime comment '發貨時間',
`ReceivDate` datetime comment '收貨時間',
`OrderMessage` varchar(4000) comment '附言',
`UserId` integer comment '用戶編號',
`OrderReserve1` varchar(4000) comment '備用1',
`OrderReserve2` varchar(4000) comment '備用2',
`OrderReserve3` decimal comment '備用3',
primary key (OrderId)
);
alter table Orders comment '訂單';
/*==============================================================*/
/* Table: ProductComment */
/*==============================================================*/
create table ProductComment
(
`ProductCommentId` int not null auto_increment comment '商品評論編號',
`ProductId` int not null comment '商品編號',
`UserId` int not null comment '用戶編號',
`ProductCommentContent` varchar(4000) comment '商品評論內容',
`ProductCommentDate` timestamp default CURRENT_TIMESTAMP comment '商品評論時間',
`ProductCommentState` int comment '狀態',
`ProductCommentRemark` int comment '打分',
`ProductCommentReserve1` varchar(4000) comment '備用1',
`ProductCommentReserve2` varchar(4000) comment '備用2',
primary key (ProductCommentId)
);
alter table ProductComment comment '商品評論';
/*==============================================================*/
/* Table: Products */
/*==============================================================*/
create table Products
(
`Id` int not null auto_increment comment '編號',
`Name` varchar(200) not null comment '名稱',
`SubIdColor` int not null comment '所屬顏色',
`SubIdBrand` int not null comment '所屬品牌',
`SubIdInlay` int not null comment '所屬鑲嵌',
`SubIdMoral` int not null comment '所屬寓意',
`SubIdMaterial` int not null comment '所屬種水',
`SubIdTopLevel` int not null comment '一級分類編號',
`MarketPrice` decimal comment '市場參考價',
`MyPrice` decimal not null comment '玉源直銷價',
`Discount` decimal default 1 comment '折扣',
`Picture` varchar(200) comment '圖片',
`Amount` int comment '庫存量',
`Description` text comment '詳細描述',
`State` int default 1 comment '狀態',
`AddDate` timestamp default CURRENT_TIMESTAMP comment '上貨日期',
`Hang` int comment '掛件',
`RawStone` int comment '賭石',
`Size` varchar(200) comment '尺寸',
`ExpressageName` varchar(100) comment '快遞名稱',
`Expressage` decimal comment '快遞費',
`AllowComment` int default 1 comment '是否允許評論',
`Reserve1` varchar(4000) comment '保留備用1',
`Reserve2` varchar(4000) comment '保留備用2',
`Reserve3` decimal(0) comment '保留備用3',
primary key (Id)
);
alter table Products comment '商品';
/*==============================================================*/
/* Table: Users */
/*==============================================================*/
create table Users
(
`UserId` int not null auto_increment comment '用戶編號',
`UserName` varchar(200) not null comment '用戶名',
`Password` varchar(512) not null comment '密碼',
`Email` varchar(100) not null comment '郵箱',
`Sex` varchar(10) comment '性別',
`State` int default 1 comment '狀態',
`RightCode` int comment '權限狀態',
`RegDate` timestamp default CURRENT_TIMESTAMP comment '注冊時間',
`RegIP` varchar(200) comment '注冊IP',
`LastLoginDate` datetime comment '最近登錄時間',
`UserReserve1` varchar(4000) comment '保留備用1',
`UserReserve2` varchar(4000) comment '保留備用2',
`UserReserve3` varchar(4000) comment '保留備用3',
primary key (UserId)
);
alter table Users comment '用戶';
alter table Address add constraint FK_AddressBelongUser foreign key (UserId)
references Users (UserId) on delete restrict on update restrict;
alter table ArticleComment add constraint FK_ArticleCommentForArticle foreign key (ArticleId)
references Articles (ArticleId) on delete restrict on update restrict;
alter table ArticleComment add constraint FK_ArticleCommentForUser foreign key (UserId)
references Users (UserId) on delete restrict on update restrict;
alter table Articles add constraint FK_ArticleBelongType foreign key (ArticleTypeId)
references ArticleType (ArticleTypeId) on delete restrict on update restrict;
alter table DictSub add constraint FK_BelongDict foreign key (DictId)
references DictTop (DictId) on delete cascade on update cascade;
alter table OrderPdt add constraint FK_BelongOrder foreign key (OrderId)
references Orders (OrderId) on delete cascade on update cascade;
alter table OrderPdt add constraint FK_CartForUser foreign key (UserId)
references Users (UserId) on delete restrict on update restrict;
alter table OrderPdt add constraint FK_OrderDepProduct foreign key (Id)
references Products (Id) on delete restrict on update restrict;
alter table Orders add constraint FK_OrderBelongAddress foreign key (AddressId)
references Address (AddressId) on delete restrict on update restrict;
alter table ProductComment add constraint FK_ProductCommentBelongUsers foreign key (UserId)
references Users (UserId) on delete restrict on update restrict;
alter table ProductComment add constraint FK_ProductCommentForProduct foreign key (ProductId)
references Products (Id) on delete restrict on update restrict;
alter table Products add constraint FK_BelongBrand foreign key (SubIdMaterial)
references DictSub (SubId) on delete restrict on update restrict;
alter table Products add constraint FK_BelongColor foreign key (SubIdBrand)
references DictSub (SubId) on delete restrict on update restrict;
alter table Products add constraint FK_BelongInlay foreign key (SubIdInlay)
references DictSub (SubId) on delete restrict on update restrict;
alter table Products add constraint FK_BelongMaterial foreign key (SubIdColor)
references DictSub (SubId) on delete restrict on update restrict;
alter table Products add constraint FK_BelongMoral foreign key (SubIdTopLevel)
references DictSub (SubId) on delete restrict on update restrict;
alter table Products add constraint FK_BelongTopLevel foreign key (SubIdMoral)
references DictSub (SubId) on delete restrict on update restrict;
~~~
[](javascript:void(0); "復制代碼")
## 5.6、MySQL與SQLServer的區別
ER圖、分頁、差異、Java連接MySQL
SELECT \* FROM table LIMIT \[offset,\] rows | rows OFFSET offset
LIMIT 子句可以被用于強制 SELECT 語句返回指定的記錄數。LIMIT 接受一個或兩個數字參數。參數必須是一個整數常量。如果給定兩個參數,第一個參數指定第一個返回記錄行的偏移量,第二個參數指定返回記錄行的最大數目。初始記錄行的偏移量是 0(而不是 1): 為了與 PostgreSQL 兼容,MySQL 也支持句法: LIMIT # OFFSET #。
### 5.6.1、區別一
[](javascript:void(0); "復制代碼")
~~~
1 mysql支持enum,和set類型,sql server不支持
2 mysql不支持nchar,nvarchar,ntext類型
3 mysql的遞增語句是AUTO_INCREMENT,而mssql是identity(1,1)
4 msms默認到處表創建語句的默認值表示是((0)),而在mysql里面是不允許帶兩括號的
5 mysql需要為表指定存儲類型
6 mssql識別符是[],[type]表示他區別于關鍵字,但是mysql卻是 `,也就是按鍵1左邊的那個符號
7 mssql支持getdate()方法獲取當前時間日期,但是mysql里面可以分日期類型和時間類型,獲取當前日期是cur_date(),當前完整時間是 now()函數
8 mssql不支持replace into 語句,但是在最新的sql20008里面,也支持merge語法
9 mysql支持insert into table1 set t1 = ‘’, t2 = ‘’ ,但是mssql不支持這樣寫
10 mysql支持insert into tabl1 values (1,1), (1,1), (1,1), (1,1), (1,1), (1,1), (1,1)
11 mssql不支持limit語句,是非常遺憾的,只能用top 取代limt 0,N,row_number() over()函數取代limit N,M
12 mysql在創建表時要為每個表指定一個存儲引擎類型,而mssql只支持一種存儲引擎
13 mysql不支持默認值為當前時間的datetime類型(mssql很容易做到),在mysql里面是用timestamp類型
14 mssql里面檢查是否有這個表再刪除,需要這樣:
if exists (select * from dbo.sysobjects where id = object_id(N'uc_newpm') and OBJECTPROPERTY(id, N'IsUserTable') = 1)
但是在mysql里面只需要 DROP TABLE IF EXISTS cdb_forums;
15 mysql支持無符號型的整數,那么比不支持無符號型的mssql就能多出一倍的最大數存儲
16 mysql不支持在mssql里面使用非常方便的varchar(max)類型,這個類型在mssql里面既可做一般數據存儲,也可以做blob數據存儲
17 mysql創建非聚集索引只需要在創建表的時候指定為key就行,比如:KEY displayorder (fid,displayorder) 在mssql里面必須要:create unique nonclustered index index_uc_protectedmembers_username_appid on dbo.uc_protectedmembers
(username asc,appid asc)
18 mysql text字段類型不允許有默認值
19mysql的一個表的總共字段長度不超過65XXX。
20一個很表面的區別就是mysql的安裝特別簡單,而且文件大小才110M(非安裝版),相比微軟這個龐然大物,安裝進度來說簡直就是.....
21mysql的管理工具有幾個比較好的,mysql_front,和官方那個套件,不過都沒有SSMS的使用方便,這是mysql很大的一個缺點。
22mysql的存儲過程只是出現在最新的版本中,穩定性和性能可能不如mssql。
23 同樣的負載壓力,mysql要消耗更少的CPU和內存,mssql的確是很耗資源。
24php連接mysql和mssql的方式都差不多,只需要將函數的mysql替換成mssql即可。
25mysql支持date,time,year類型,mssql到2008才支持date和time。
~~~
[](javascript:void(0); "復制代碼")
### 5.6.2、區別二
[](javascript:void(0); "復制代碼")
~~~
一數據定義
1 數據庫操作基本命令
Mysql:
create database name; 創建數據庫
use databasename; 選擇數據庫
drop database name 直接刪除數據庫,不提醒 –
2 CREATE TABLE --創建一個數據庫表
2.1 PRIMARY KEY 約束(主鍵)區別解析:
2.1.1 創建primary key
Mysql:
CREATE TABLE Persons
(
Id_P int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (Id_P) //聲明主健寫在最后
)
SqlServer:
CREATE TABLE Persons
(
Id_P int NOT NULL PRIMARY KEY, //聲明主健 緊跟列后
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
但是如果表存在,之后給表加主健時:
Mysql 和SqlServer
ALTER TABLE Persons ADD PRIMARY KEY (Id_P)
2.1.2撤銷 PRIMARY KEY 約束
MySQL:
ALTER TABLE Persons DROP PRIMARY KEY
SQL Server
ALTER TABLE Persons DROP CONSTRAINT pk_PersonID
2.1.3 創建外健約束
MySQL:
CREATE TABLE Orders
(
O_Id int NOT NULL,
OrderNo int NOT NULL,
Id_P int,
PRIMARY KEY (O_Id),
FOREIGN KEY (Id_P) REFERENCES Persons(Id_P) //寫在最后
)
SQL Server
CREATE TABLE Orders
(
O_Id int NOT NULL PRIMARY KEY,
OrderNo int NOT NULL,
Id_P int FOREIGN KEY REFERENCES Persons(Id_P) //順序不同
)
如果在 "Orders" 表已存在的情況下為 "Id_P" 列創建 FOREIGN KEY 約束,請使用下面的 SQL:
MySQL / SQL Server
ALTER TABLE Orders ADD FOREIGN KEY (Id_P) REFERENCES Persons(Id_P)
2.1.4 撤銷外健約束
MySQL:
ALTER TABLE Orders DROP FOREIGN KEY f k_PerOrders
SQL Server
ALTER TABLE Orders DROP CONSTRAINT fk_PerOrders
2.2 UNIQUE 約束(唯一的,獨一無二的)區別解析
UNIQUE 約束唯一標識數據庫表中的每條記錄。
UNIQUE 和 PRIMARY KEY 約束均為列或列集合提供了唯一性的保證。
PRIMARY KEY 擁有自動定義的 UNIQUE 約束。
請注意,每個表可以有多個 UNIQUE 約束,但是每個表只能有一個 PRIMARY KEY 約束。
2.2.1 創建UNIQUE約束
MySQL:
CREATE TABLE Persons
(
Id_P int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
UNIQUE (Id_P) //寫在最后
)
SQL Server
CREATE TABLE Persons
(
Id_P int NOT NULL UNIQUE, //緊跟列后
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
2.2.2 撤銷 UNIQUE 約束
MySQL:
ALTER TABLE Persons DROP INDEX uc_PersonID
SQL Server
ALTER TABLE Persons DROP CONSTRAINT uc_PersonID
2.3 CHECK 約束
CHECK 約束用于限制列中的值的范圍。
如果對單個列定義 CHECK 約束,那么該列只允許特定的值。
如果對一個表定義 CHECK 約束,那么此約束會在特定的列中對值進行限制。
2.3.1 創建 CHECK約束
下面的 SQL 在 "Persons" 表創建時為 "Id_P" 列創建 CHECK 約束。CHECK 約束規定 "Id_P" 列必須只包含大于 0 的整數。
My SQL:
CREATE TABLE Persons
(
Id_P int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
CHECK (Id_P>0) //寫在最后
)
SQL Server
CREATE TABLE Persons
(
Id_P int NOT NULL CHECK (Id_P>0), //緊跟列后
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
如果需要命名 CHECK 約束,以及為多個列定義 CHECK 約束,請使用下面的 SQL 語法:
MySQL / SQL Server:
CREATE TABLE Persons
(
Id_P int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
CONSTRAINT chk_Person CHECK (Id_P>0 AND City='Sandnes') //多個條件
)
如果在表已存在的情況下為 "Id_P" 列創建 CHECK 約束,請使用下面的 SQL:
MySQL / SQL Server:
ALTER TABLE Persons ADD CHECK (Id_P>0)
2.3.2 撤銷 CHECK約束
Sqlserver:
ALTER TABLE Persons DROP CONSTRAINT chk_Person
Mysql我沒有找到怎么刪除。
2.4 DEFAULT 約束(系統默認值)
DEFAULT 約束用于向列中插入默認值。
如果沒有規定其他的值,那么會將默認值添加到所有的新紀錄。
2.4.1 創建DEFAULT約束
下面的 SQL 在 "Persons" 表創建時為 "City" 列創建 DEFAULT 約束:
My SQL / SQL Server:
CREATE TABLE Persons
(
Id_P int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255) DEFAULT 'Sandnes' //緊跟列后,默認值字符串Sandnes
)
通過使用類似 GETDATE() 這樣的函數,DEFAULT 約束也可以用于插入系統值:
CREATE TABLE Orders
(
Id_O int NOT NULL,
OrderNo int NOT NULL,
Id_P int,
OrderDate date DEFAULT GETDATE() //緊跟列后,函數
)
如果在表已存在的情況下為 "City" 列創建 DEFAULT 約束,請使用下面的 SQL:
MySQL:
ALTER TABLE Persons ALTER City SET DEFAULT 'SANDNES'
SQL Server:
ALTER TABLE Persons ALTER COLUMN City SET DEFAULT 'SANDNES'
2.4 .2 撤消DEFAULT約束
MySQL:
ALTER TABLE Persons ALTER City DROP DEFAULT
SQL Server:
ALTER TABLE Persons ALTER COLUMN City DROP DEFAULT
2.5 索引區別
CREATE INDEX 語句
CREATE INDEX 語句用于在表中創建索引。
在不讀取整個表的情況下,索引使數據庫應用程序可以更快地查找數據。
在表上創建一個簡單的索引。允許使用重復的值:
CREATE INDEX index_name ON table_name (column_name) //"column_name" 規定需要索引的列。
在表上創建一個唯一的索引。唯一的索引意味著兩個行不能擁有相同的索引值。
CREATE UNIQUE INDEX index_name ON table_name (column_name)
Mysql和SqlServer的創建索引都是一致的,但是在刪除索引方面卻有區別:
SqlServer: DROP INDEX table_name.index_name
Mysql: ALTER TABLE table_name DROP INDEX index_name
2.6 主鍵自動增加的區別
mySql的主鍵自動增加是用auto_increment字段,sqlServer的自動增加則是identity字段.
Auto-increment 會在新紀錄插入表中時生成一個唯一的數字。
我們通常希望在每次插入新紀錄時,自動地創建主鍵字段的值。
我們可以在表中創建一個 auto-increment 字段。
用于 MySQL 的語法
下列 SQL 語句把 "Persons" 表中的 "P_Id" 列定義為 auto-increment 主鍵:
CREATE TABLE Persons
(
P_Id int NOT NULL AUTO_INCREMENT,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (P_Id)
)
MySQL 使用 AUTO_INCREMENT 關鍵字來執行 auto-increment 任務。
默認地,AUTO_INCREMENT 的開始值是 1,每條新紀錄遞增 1。
要讓 AUTO_INCREMENT 序列以其他的值起始,請使用下列 SQL 語法:
ALTER TABLE Persons AUTO_INCREMENT=100
用于 SQL Server 的語法
下列 SQL 語句把 "Persons" 表中的 "P_Id" 列定義為 auto-increment 主鍵:
CREATE TABLE Persons
(
P_Id int PRIMARY KEY IDENTITY,或則是寫成P_id int primary key identity (1,1),
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
MS SQL 使用 IDENTITY 關鍵字來執行 auto-increment 任務。
默認地,IDENTITY 的開始值是 1,每條新紀錄遞增 1。
要規定 "P_Id" 列以 20 起始且遞增 10,請把 identity 改為 IDENTITY(20,10)
2.7 MySQL支持enum,和set類型,SQL Server不支持
2.7.1 枚舉enum
ENUM是一個字符串對象,其值來自表創建時在列規定中顯式枚舉的一列值.
枚舉最多可以有65,535個元素。
枚舉的簡單用法舉例:
mysql> create table meijut (f1 enum('1','2','3','4','5','6'));
mysql> desc meijut;
+-------+-------------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------------------------+------+-----+---------+-------+
| f1 | enum('1','2','3','4','5','6') | YES | | NULL | |
+-------+-------------------------------+------+-----+---------+-------+
mysql> insert into meijut values(8);
mysql> select * from meijut
-> ;
+------+
| f1 |
+------+
| |
+------+
這個情況說明如果你將一個非法值插入ENUM(也就是說,允許的值列之外的字符串),將插入空字符串以作為特殊錯誤值。該字符串與“普通”空字符串不同,該字符串有數值值0。
mysql> insert into meijut values('3');
mysql> insert into meijut values(3);
mysql> insert into meijut values('4');
mysql> insert into meijut values('5');
mysql> select * from meijut;
+------+
| f1 |
+------+
| |
| 3 |
| 3 |
| 4 |
| 5 |
+------+
改表
mysql> alter table meiju modify f1 enum("a","b","c","d","e","f");
可以自動將記錄當序號匹配成新的字段值
mysql> select * from meijut;
+------+
| f1 |
+------+
| |
| c |
| c |
| d |
| e |
+------+
2.7.2 集合set
mysql> create table jihe(f1 set('f','m'));
mysql> insert into jihe values('f');
可以按照序號輸入 注意序號為 1 2 4 8 16 32 ....
mysql> insert into jihe values('3');
mysql> select * from jihe;
+------+
| f1 |
+------+
| f |
| f,m |
+------+
其他字母不能插入
mysql> insert into jihe values("q");
ERROR 1265 (01000): Data truncated for column 'f1' at row 1
插入空
mysql> insert into jihe values("0");
Query OK, 1 row affected (0.11 sec)
超出序號之和不能插入
mysql> insert into jihe values("4");
ERROR 1265 (01000): Data truncated for column 'f1' at row 1
集合 和 枚舉的區別
1 集合可以有64個值 枚舉有65535個
2 集合的序號是 1 2 4 8 16 枚舉是 1 2 3 4 5 6
3 集合一個字段值可以有好幾個值
+-------+
| f1 |
+-------+
| f,m |
+-------+
2.8 MySQL不支持nchar,nvarchar,ntext類型
3 DROP TABLE –刪除一個數據庫表
Mysql判斷一個數據庫表是否存在并刪除的語句是:
drop table if exists jihe;
SqlServer判斷一個數據庫表是否存在并刪除的語句是:
if exists (select * from sysobjects where name='Sheet1$' and xtype='U')
drop table Sheet1$
其中jihe和Sheet1$指的均是數據庫表名
4 顯示庫表
Mysql:
Show tables;//顯示一個庫中的所有表
Desc table;/顯示一個表的表結構
mysql> desc meijut;
+-------+-------------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------------------------+------+-----+---------+-------+
| f1 | enum('a','b','c','d','e','f') | YES | | NULL | |
| f2 | int(11) | YES | | 0 | |
| f3 | text | YES | | NULL | |
+-------+-------------------------------+------+-----+---------+-------+
Show create table tablename;//顯示一個表的詳細創建信息
mysql> show create table meijut;
+--------+-------------------------------------------
-----------------------------------------------------
---+
| Table | Create Table
|
+--------+-------------------------------------------
-----------------------------------------------------
---+
| meijut | CREATE TABLE `meijut` (
`f1` enum('a','b','c','d','e','f') default NULL,
`f2` int(11) default '0',
`f3` text
) ENGINE=MyISAM DEFAULT CHARSET=utf8 |
5 alter 修改庫表
重命名表: -
mysql > alter table t1 rename t2;
添加一列
mysql> alter table meijut add column f2 int default 0 ;
修改一列
mysql> alter table meijut modify f2 text;
二 數據操作
2.1 limit和top
SQL SERVER : select top 8 * from table1
MYSQL: select * from table1 limit 5或則是 limit 0,5;
注意,在MySQL中的limit不能放在子查詢內,limit不同與top,它可以規定范圍 limit a,b——范圍a-b
2.2 ISNULL()函數
SqlServer:
select * from test where isnull(no,0)=0;
MySQL
MySQL 可以使用 ISNULL() 函數。不過它的工作方式與微軟的 ISNULL() 函數有點不同。
在 MySQL 中,我們可以使用 IFNULL() 函數,就像這樣:
mysql> select * from test where ifnull(no,0)=0;
+----+------+
| id | no |
+----+------+
| 3 | NULL |
+----+------+
1 row in set (0.03 sec)
2.3 select查詢
SELECT * FROM tablename
2.4 insert 插入
INSERT INTO table(col1,col2) values(value1,value2);
MySQL支持insert into table1 set t1 = ‘’, t2=‘’,但是MSSQL不支持這樣寫
2.6update 修改
Update tablename set col=”value”;
2.7 delete 刪除
Delete from tablename;
三 語法定義
3.1 注釋符區別
SqlServer的注釋符為--和/**/
MySql的注釋符為--和/**/和#
3.2 識別符的區別
MS SQL識別符是[],[type]表示他區別于關鍵字,但是MySQL卻是 `,也就是按鍵1左邊的那個符號
3.3存儲過程的區別(未經驗證,從網上找的)
(1) mysql的存儲過程中變量的定義去掉@;
(2) SQLServer存儲過程的AS在MySql中需要用begin .....end替換
(3) Mysql的Execute對應SqlServer的exec;
(注意:必須想下面這樣調用)
Set @cnt=’select * from 表名’;
Prepare str from @cnt;
Execute str;
(4) MySql存儲過程調用其他存儲過程用call
Call 函數名(即SQLServer的存儲過程名)(’參數1’,’參數2’,……)
(5) select @a=count(*) from VW_Action 在mySql中修改為:select count(*) from VW_Action into @a;
(6) MySQL視圖的FROM子句不允許存在子查詢,因此對于SQL Server中FROM子句帶有子查詢的視圖,需要手工進行遷移。可通過消除FROM子句中的子查詢,或將FROM子句中的子查詢重構為一個新的視圖來進行遷移。
(7) )MySql存儲過程中沒有return函數,在MySql中可以用循環和out參數代替
If EXISTS(SELECT * FROM T_Chance WHERE FCustID=CostomerID) return 0
改寫為:
(在參數中定義一個out變量:out temp varchar(100);)
BEGIN
Loop1:loop
SELECT count(*) FROM T_Chance WHERE FCustID=CostomerID int @cnt
If @cnt>0 then
begin
set temp=0;
leave loop1;
end;
end if
end loop loop1;
(8) mysql的uuid()對應sql的GUID();
(9) MySql的out對應SQLServer的output,且mysql 的out要放在變量的前面,SQLServer的output放在變量后面:
MySql out,in,inout的區別——
MySQL 存儲過程 “in” 參數:跟 C 語言的函數參數的值傳遞類似, MySQL 存儲過程內部可能會修改此參數,但對 in 類型參數的修改,對調用者(caller)來說是不可見的(not visible)。
MySQL 存儲過程 “out” 參數:從存儲過程內部傳值給調用者。在存儲過程內部,該參數初始值為 null,無論調用者是否給存儲過程參數設置值。
MySQL 存儲過程 inout 參數跟 out 類似,都可以從存儲過程內部傳值給調用者。不同的是:調用者還可以通過 inout 參數傳遞值給存儲過程。
3.4字符串連接
SQLServer: Temp=’select * from ’+’tablename’+…+…
MySql:Temp=concat(’select * from’, ’tablecname’,…,…)
四 函數和數據類型的區別
4.1 Date 函數
MySQL Date 函數
NOW() 返回當前的日期和時間
CURDATE() 返回當前的日期
CURTIME() 返回當前的時間
DATE() 提取日期或日期/時間表達式的日期部分
EXTRACT() 返回日期/時間按的單獨部分
DATE_ADD() 給日期添加指定的時間間隔
DATE_SUB() 從日期減去指定的時間間隔
DATEDIFF() 返回兩個日期之間的天數
DATE_FORMAT() 用不同的格式顯示日期/時間
SQL Server Date 函數
GETDATE() 返回當前日期和時間
DATEPART() 返回日期/時間的單獨部分
DATEADD() 在日期中添加或減去指定的時間間隔
DATEDIFF() 返回兩個日期之間的時間
CONVERT() 用不同的格式顯示日期/時間
SQL Date 數據類型
MySQL 使用下列數據類型在數據庫中存儲日期或日期/時間值:
DATE - 格式 YYYY-MM-DD
DATETIME - 格式: YYYY-MM-DD HH:MM:SS
TIMESTAMP - 格式: YYYY-MM-DD HH:MM:SS
YEAR - 格式 YYYY 或 YY
SQL Server 使用下列數據類型在數據庫中存儲日期或日期/時間值:
DATE - 格式 YYYY-MM-DD
DATETIME - 格式: YYYY-MM-DD HH:MM:SS
SMALLDATETIME - 格式: YYYY-MM-DD HH:MM:SS
TIMESTAMP - 格式: 唯一的數字
五性能比較
(1)一個很表面的區別就是MySQL的安裝特別簡單,而且文件大小才110M(非安裝版),相比微軟這個龐然大物,安裝進度來說簡直就是.....
(2)MySQL的管理工具有幾個比較好的,MySQL_front,和官方那個套件,不過都沒有SSMS的使用方便,這是MySQL很大的一個缺點。
(3)MySQL的存儲過程只是出現在最新的版本中,穩定性和性能可能不如MS SQL。
(4)同
樣的負載壓力,MySQL要消耗更少的CPU和內存,MS SQL的確是很耗資源。
1、把主鍵定義為自動增長標識符類型
MySql
在mysql中,如果把表的主鍵設為auto_increment類型,數據庫就會自動為主鍵賦值。例如:
create table customers(id int auto_increment primary key not null, name varchar(15));
最近在做mssql轉換成mysql的工作,總結了點經驗,跟大家分享一下。
同時這些也會在不斷更新。也希望大家補充。
1 mysql支持enum,和set類型,sql server不支持
2 mysql不支持nchar,nvarchar,ntext類型
3 mysql的遞增語句是AUTO_INCREMENT,而mssql是identity(1,1)
4 msms默認到處表創建語句的默認值表示是((0)),而在mysql里面是不允許帶兩括號的
5 mysql需要為表指定存儲類型
6 mssql識別符是[],[type]表示他區別于關鍵字,但是mysql卻是 `,也就是按鍵1左邊的那個符號
7 mssql支持getdate()方法獲取當前時間日期,但是mysql里面可以分日期類型和時間類型,獲取當前日期是cur_date(),當前完整時間是 now()函數
8 mssql不支持replace into 語句,但是在最新的sql20008里面,也支持merge語法
9 mysql支持insert into table1 set t1 = ‘’, t2 = ‘’ ,但是mssql不支持這樣寫
10 mysql支持insert into tabl1 values (1,1), (1,1), (1,1), (1,1), (1,1), (1,1), (1,1)
11 mssql不支持limit語句,是非常遺憾的,只能用top 取代limt 0,N,row_number() over()函數取代limit N,M
12 mysql在創建表時要為每個表指定一個存儲引擎類型,而mssql只支持一種存儲引擎
13 mysql不支持默認值為當前時間的datetime類型(mssql很容易做到),在mysql里面是用timestamp類型
14 mssql里面檢查是否有這個表再刪除,需要這樣:
if exists (select * from dbo.sysobjects where id = object_id(N'uc_newpm') and OBJECTPROPERTY(id, N'IsUserTable') = 1)
但是在mysql里面只需要 DROP TABLE IF EXISTS cdb_forums;
15 mysql支持無符號型的整數,那么比不支持無符號型的mssql就能多出一倍的最大數存儲
16 mysql不支持在mssql里面使用非常方便的varchar(max)類型,這個類型在mssql里面既可做一般數據存儲,也可以做blob數據存儲
17 mysql創建非聚集索引只需要在創建表的時候指定為key就行,比如:KEY displayorder (fid,displayorder) 在mssql里面必須要:create unique nonclustered index index_uc_protectedmembers_username_appid on dbo.uc_protectedmembers
(username asc,appid asc)
18 mysql text字段類型不允許有默認值
19mysql的一個表的總共字段長度不超過65XXX。
20一個很表面的區別就是mysql的安裝特別簡單,而且文件大小才110M(非安裝版),相比微軟這個龐然大物,安裝進度來說簡直就是.....
21mysql的管理工具有幾個比較好的,mysql_front,和官方那個套件,不過都沒有SSMS的使用方便,這是mysql很大的一個缺點。
22mysql的存儲過程只是出現在最新的版本中,穩定性和性能可能不如mssql。
23 同樣的負載壓力,mysql要消耗更少的CPU和內存,mssql的確是很耗資源。
24php連接mysql和mssql的方式都差不多,只需要將函數的mysql替換成mssql即可。
25mysql支持date,time,year類型,mssql到2008才支持date和time。
MySQL 的數值數據類型可以大致劃分為兩個類別,一個是整數,另一個是浮點數或小數。許多不同的子類型對這些類別中的每一個都是可用的,每個子類型支持不同大小的數據,并且 MySQL 允許我們指定數值字段中的值是否有正負之分或者用零填補。
表列出了各種數值類型以及它們的允許范圍和占用的內存空間。
類型 大小 范圍(有符號) 范圍(無符號) 用途
TINYINT 1 字節 (-128,127) (0,255) 小整數值
SMALLINT 2 字節 (-32 768,32 767) (0,65 535) 大整數值
MEDIUMINT 3 字節 (-8 388 608,8 388 607) (0,16 777 215) 大整數值
INT或INTEGER 4 字節 (-2 147 483 648,2 147 483 647) (0,4 294 967 295) 大整數值
BIGINT 8 字節 (-9 233 372 036 854 775 808,9 223 372 036 854 775 807) (0,18 446 744 073 709 551 615) 極大整數值
FLOAT 4 字節 (-3.402 823 466 E+38,1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) 0,(1.175 494 351 E-38,3.402 823 466 E+38) 單精度
浮點數值
DOUBLE 8 字節 (1.797 693 134 862 315 7 E+308,2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) 雙精度
浮點數值
DECIMAL 對DECIMAL(M,D) ,如果M>D,為M+2否則為D+2 依賴于M和D的值 依賴于M和D的值 小數值
INT 類型
在 MySQL 中支持的 5 個主要整數類型是 TINYINT,SMALLINT,MEDIUMINT,INT 和 BIGINT。這些類型在很大程度上是相同的,只有它們存儲的值的大小是不相同的。
MySQL 以一個可選的顯示寬度指示器的形式對 SQL 標準進行擴展,這樣當從數據庫檢索一個值時,可以把這個值加長到指定的長度。例如,指定一個字段的類型為 INT(6),就可以保證所包含數字少于 6 個的值從數據庫中檢索出來時能夠自動地用空格填充。需要注意的是,使用一個寬度指示器不會影響字段的大小和它可以存儲的值的范圍。
萬一我們需要對一個字段存儲一個超出許可范圍的數字,MySQL 會根據允許范圍最接近它的一端截短后再進行存儲。還有一個比較特別的地方是,MySQL 會在不合規定的值插入表前自動修改為 0。
UNSIGNED 修飾符規定字段只保存正值。因為不需要保存數字的正、負符號,可以在儲時節約一個“位”的空間。從而增大這個字段可以存儲的值的范圍。
ZEROFILL 修飾符規定 0(不是空格)可以用來真補輸出的值。使用這個修飾符可以阻止 MySQL 數據庫存儲負值。
FLOAT、DOUBLE 和 DECIMAL 類型
MySQL 支持的三個浮點類型是 FLOAT、DOUBLE 和 DECIMAL 類型。FLOAT 數值類型用于表示單精度浮點數值,而 DOUBLE 數值類型用于表示雙精度浮點數值。
與整數一樣,這些類型也帶有附加參數:一個顯示寬度指示器和一個小數點指示器。比如語句 FLOAT(7,3) 規定顯示的值不會超過 7 位數字,小數點后面帶有 3 位數字。
對于小數點后面的位數超過允許范圍的值,MySQL 會自動將它四舍五入為最接近它的值,再插入它。
DECIMAL 數據類型用于精度要求非常高的計算中,這種類型允許指定數值的精度和計數方法作為選擇參數。精度在這里指為這個值保存的有效數字的總個數,而計數方法表示小數點后數字的位數。比如語句 DECIMAL(7,3) 規定了存儲的值不會超過 7 位數字,并且小數點后不超過 3 位。
忽略 DECIMAL 數據類型的精度和計數方法修飾符將會使 MySQL 數據庫把所有標識為這個數據類型的字段精度設置為 10,計算方法設置為 0。
UNSIGNED 和 ZEROFILL 修飾符也可以被 FLOAT、DOUBLE 和 DECIMAL 數據類型使用。并且效果與 INT 數據類型相同。
字符串類型
MySQL 提供了 8 個基本的字符串類型,可以存儲的范圍從簡單的一個字符到巨大的文本塊或二進制字符串數據。
類型 大小 用途
CHAR 0-255字節 定長字符串
VARCHAR 0-255字節 變長字符串
TINYBLOB 0-255字節 不超過 255 個字符的二進制字符串
TINYTEXT 0-255字節 短文本字符串
BLOB 0-65 535字節 二進制形式的長文本數據
TEXT 0-65 535字節 長文本數據
MEDIUMBLOB 0-16 777 215字節 二進制形式的中等長度文本數據
MEDIUMTEXT 0-16 777 215字節 中等長度文本數據
LOGNGBLOB 0-4 294 967 295字節 二進制形式的極大文本數據
LONGTEXT 0-4 294 967 295字節 極大文本數據
CHAR 和 VARCHAR 類型
CHAR 類型用于定長字符串,并且必須在圓括號內用一個大小修飾符來定義。這個大小修飾符的范圍從 0-255。比指定長度大的值將被截短,而比指定長度小的值將會用空格作填補。
CHAR 類型可以使用 BINARY 修飾符。當用于比較運算時,這個修飾符使 CHAR 以二進制方式參于運算,而不是以傳統的區分大小寫的方式。
CHAR 類型的一個變體是 VARCHAR 類型。它是一種可變長度的字符串類型,并且也必須帶有一個范圍在 0-255 之間的指示器。CHAR 和 VARCHGAR 不同之處在于 MuSQL 數據庫處理這個指示器的方式:CHAR 把這個大小視為值的大小,不長度不足的情況下就用空格補足。而 VARCHAR 類型把它視為最大值并且只使用存儲字符串實際需要的長度(增加一個額外字節來存儲字符串本身的長度)來存儲值。所以短于指示器長度的 VARCHAR 類型不會被空格填補,但長于指示器的值仍然會被截短。
因為 VARCHAR 類型可以根據實際內容動態改變存儲值的長度,所以在不能確定字段需要多少字符時使用 VARCHAR 類型可以大大地節約磁盤空間、提高存儲效率。
VARCHAR 類型在使用 BINARY 修飾符時與 CHAR 類型完全相同。
TEXT 和 BLOB 類型
對于字段長度要求超過 255 個的情況下,MySQL 提供了 TEXT 和 BLOB 兩種類型。根據存儲數據的大小,它們都有不同的子類型。這些大型的數據用于存儲文本塊或圖像、聲音文件等二進制數據類型。
TEXT 和 BLOB 類型在分類和比較上存在區別。BLOB 類型區分大小寫,而 TEXT 不區分大小寫。大小修飾符不用于各種 BLOB 和 TEXT 子類型。比指定類型支持的最大范圍大的值將被自動截短。
日期和時間類型
在處理日期和時間類型的值時,MySQL 帶有 5 個不同的數據類型可供選擇。它們可以被分成簡單的日期、時間類型,和混合日期、時間類型。根據要求的精度,子類型在每個分類型中都可以使用,并且 MySQL 帶有內置功能可以把多樣化的輸入格式變為一個標準格式。
類型 大小
(字節) 范圍 格式 用途
DATE 3 1000-01-01/9999-12-31 YYYY-MM-DD 日期值
TIME 3 '-838:59:59'/'838:59:59' HH:MM:SS 時間值或持續時間
YEAR 1 1901/2155 YYYY 年份值
DATETIME 8 1000-01-01 00:00:00/9999-12-31 23:59:59 YYYY-MM-DD HH:MM:SS 混合日期和時間值
TIMESTAMP 8 1970-01-01 00:00:00/2037 年某時 YYYYMMDD HHMMSS 混合日期和時間值,時間戳
DATE、TIME 和 TEAR 類型
MySQL 用 DATE 和 TEAR 類型存儲簡單的日期值,使用 TIME 類型存儲時間值。這些類型可以描述為字符串或不帶分隔符的整數序列。如果描述為字符串,DATE 類型的值應該使用連字號作為分隔符分開,而 TIME 類型的值應該使用冒號作為分隔符分開。
需要注意的是,沒有冒號分隔符的 TIME 類型值,將會被 MySQL 理解為持續的時間,而不是時間戳。
MySQL 還對日期的年份中的兩個數字的值,或是 SQL 語句中為 TEAR 類型輸入的兩個數字進行最大限度的通譯。因為所有 TEAR 類型的值必須用 4 個數字存儲。MySQL 試圖將 2 個數字的年份轉換為 4 個數字的值。把在 00-69 范圍內的值轉換到 2000-2069 范圍內。把 70-99 范圍內的值轉換到 1970-1979 之內。如果 MySQL 自動轉換后的值并不符合我們的需要,請輸入 4 個數字表示的年份。
DATEYIME 和 TIMESTAMP 類型
除了日期和時間數據類型,MySQL 還支持 DATEYIME 和 TIMESTAMP 這兩種混合類型。它們可以把日期和時間作為單個的值進行存儲。這兩種類型通常用于自動存儲包含當前日期和時間的時間戳,并可在需要執行大量數據庫事務和需要建立一個調試和審查用途的審計跟蹤的應用程序中發揮良好作用。
如果我們對 TIMESTAMP 類型的字段沒有明確賦值,或是被賦與了 null 值。MySQL 會自動使用系統當前的日期和時間來填充它。
復合類型
MySQL 還支持兩種復合數據類型 ENUM 和 SET,它們擴展了 SQL 規范。雖然這些類型在技術上是字符串類型,但是可以被視為不同的數據類型。一個 ENUM 類型只允許從一個集合中取得一個值;而 SET 類型允許從一個集合中取得任意多個值。
ENUM 類型
ENUM 類型因為只允許在集合中取得一個值,有點類似于單選項。在處理相互排拆的數據時容易讓人理解,比如人類的性別。ENUM 類型字段可以從集合中取得一個值或使用 null 值,除此之外的輸入將會使 MySQL 在這個字段中插入一個空字符串。另外如果插入值的大小寫與集合中值的大小寫不匹配,MySQL 會自動使用插入值的大小寫轉換成與集合中大小寫一致的值。
ENUM 類型在系統內部可以存儲為數字,并且從 1 開始用數字做索引。一個 ENUM 類型最多可以包含 65536 個元素,其中一個元素被 MySQL 保留,用來存儲錯誤信息,這個錯誤值用索引 0 或者一個空字符串表示。
MySQL 認為 ENUM 類型集合中出現的值是合法輸入,除此之外其它任何輸入都將失敗。這說明通過搜索包含空字符串或對應數字索引為 0 的行就可以很容易地找到錯誤記錄的位置。
SET 類型
SET 類型與 ENUM 類型相似但不相同。SET 類型可以從預定義的集合中取得任意數量的值。并且與 ENUM 類型相同的是任何試圖在 SET 類型字段中插入非預定義的值都會使 MySQL 插入一個空字符串。如果插入一個即有合法的元素又有非法的元素的記錄,MySQL 將會保留合法的元素,除去非法的元素。
一個 SET 類型最多可以包含 64 項元素。在 SET 元素中值被存儲為一個分離的“位”序列,這些“位”表示與它相對應的元素。“位”是創建有序元素集合的一種簡單而有效的方式。并且它還去除了重復的元素,所以 SET 類型中不可能包含兩個相同的元素。
希望從 SET 類型字段中找出非法的記錄只需查找包含空字符串或二進制值為 0 的行。
~~~
[](javascript:void(0); "復制代碼")
# 六、使用JDBC訪問MySQL
## 6.1、下載驅動

## 6.2、JDBC訪問MySQL
?示例一:
[](javascript:void(0); "復制代碼")
~~~
package jdbctest;
import java.math.BigDecimal;
import java.sql.*;
import java.util.Scanner;
public class GoodsDao {
static {
try {
/*加載驅動*/
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
/**添加*/
insert();
/**查詢*/
select();
}
/**查詢*/
private static void select() {
try {
/**獲得連接對象*/
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/nfmall?useUnicode=true&characterEncoding=UTF-8", "root", "123");
/**創建sql命令對象*/
PreparedStatement statement=conn.prepareStatement("SELECT goods.id, goods.title, goods.category_id, goods.add_date, goods.picture, goods.state, goods.details, goods.price, category.`name`, category.parentId FROM goods INNER JOIN category ON goods.category_id = category.id where price>=?");
//設置參數
statement.setInt(1,1000);
//執行并獲得結果集
ResultSet result=statement.executeQuery();
//遍歷結果集
while (result.next()){
//在當前行根據列名獲得數據
String title=result .getString("title");
BigDecimal price=result.getBigDecimal("price");
System.out.println(title+"\t"+price);
}
//關閉
result.close();
statement.close();
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
/**添加*/
private static void insert() {
try {
//輸入用的掃描器
Scanner input=new Scanner(System.in);
/**獲得連接對象*/
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/nfmall?useUnicode=true&characterEncoding=UTF-8", "root", "123");
/**創建sql命令對象*/
PreparedStatement statement=conn.prepareStatement("insert into goods(title,category_id,picture,price,details,state) VALUES(?,?,?,?,?,default);");
System.out.print("名稱:");
String title=input.next();
System.out.print("類型:");
int cateId=input.nextInt();
System.out.print("圖片:");
String picture=input.next();
System.out.print("價格:");
BigDecimal price=input.nextBigDecimal();
System.out.print("詳細:");
String details=input.next();
//設置參數
statement.setString(1,title);
statement.setInt(2,cateId);
statement.setString(3,picture);
statement.setBigDecimal(4,price);
statement.setString(5,details);
//執行并獲得影響行數
int rows=statement.executeUpdate();
System.out.println("執行:"+(rows>0?"成功":"失敗"));
//關閉
statement.close();
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
~~~
[](javascript:void(0); "復制代碼")
結果:

JDBC工具類(帶簡單映射):
View Code
# 七、下載程序、幫助、視頻
MySQL綠色版下載地址1:[https://pan.baidu.com/s/1hrS5KUw](https://pan.baidu.com/s/1hrS5KUw)?密碼: sug9
MySQL綠色版下載地址2:[http://download.csdn.net/detail/zhangguo5/9773842](http://download.csdn.net/detail/zhangguo5/9773842)
MySQL文檔下載1:https://pan.baidu.com/s/1nuGQo57 密碼: 898h
MySQL文檔下載2:[http://download.csdn.net/detail/zhangguo5/9774115](http://download.csdn.net/detail/zhangguo5/9774115)
MySQL5.5.27\_64位安裝包下載地址1:?[https://pan.baidu.com/s/1minwz1m](https://pan.baidu.com/s/1minwz1m)?密碼: ispn
MySQL5.5.27\_64位安裝包下載地址2:?[http://download.csdn.net/detail/zhangguo5/9775460](http://download.csdn.net/detail/zhangguo5/9775460)
MySQL5.7.17安裝包官網下載地址:?[https://dev.mysql.com/downloads/windows/installer/](https://dev.mysql.com/downloads/windows/installer/)
視頻:[https://www.bilibili.com/video/av30777062/](https://www.bilibili.com/video/av30777062/)
文檔中沒有您可以查幫助:

# 八、作業
## 8.1、使用javascript實現身份證校驗與信息提取。
校驗:校驗身份證是否正確,如出生的年月日,最后一位校驗碼是否符合規則
信息提取:位置,生日,性別;位置信息存儲到MySQL數據庫中,使用ajax獲取


?[身份證位置sql數據下載](https://files.cnblogs.com/files/best/%E6%A0%B9%E6%8D%AE%E8%BA%AB%E4%BB%BD%E8%AF%81%E6%9F%A5%E8%AF%A2%E5%9C%B0%E5%9D%80%28sql%E6%96%87%E4%BB%B6%29.7z)
