
## 題目
假設有一個超長的切片,切片的元素類型為 int,切片中的元素為亂序排序。限時 5 秒,使用多個 goroutine 查找切片中是否存在給定的值,在查找到目標值或者超時后立刻結束所有 goroutine 的執行。
比如,切片`[23,32,78,43,76,65,345,762,......915,86]`,查找目標值為 345 ,如果切片中存在,則目標值輸出`"Found it!"`并立即取消仍在執行查詢任務的`goroutine`。
如果在超時時間未查到目標值程序,則輸出`"Timeout!Not Found"`,同時立即取消仍在執行的查找任務的`goroutine`。
## 解析
首先題目里提到了**在找到目標值或者超時后立刻結束所有goroutine的執行**,完成這兩個功能需要借助計時器、通道和`context`才行。我能想到的第一點就是要用`context.WithCancel`創建一個上下文對象傳遞給每個執行任務的`goroutine`,外部在滿足條件后(找到目標值或者已超時)通過調用上下文的取消函數來通知所有`goroutine`停止工作。
~~~
func?main()?{????timer?:=?time.NewTimer(time.Second?*?5)????ctx,?cancel?:=?context.WithCancel(context.Background())????resultChan?:=?make(chan?bool)??......????select?{????case?<-timer.C:????????fmt.Fprintln(os.Stderr,?"Timeout!?Not?Found")????????cancel()????case?<-?resultChan:????????fmt.Fprintf(os.Stdout,?"Found?it!\n")????????cancel()????}}
~~~
執行任務的`goroutine`們如果找到目標值后需要通知外部等待任務執行的主`goroutine`,這個工作是典型的應用通道的場景,上面代碼也已經看到了,我們創建了一個接收查找結果的通道,接下來要做的就是把它和上下文對象一起傳遞給執行任務的`goroutine`。
~~~
func?SearchTarget(ctx?context.Context,?data?[]int,?target?int,?resultChan?chan?bool)?{????for?_,?v?:=?range?data?{????????select?{????????case?<-?ctx.Done():????????????fmt.Fprintf(os.Stdout,?"Task?cancelded!?\n")????????????return????????default:????????}????????//?模擬一個耗時查找,這里只是比對值,真實開發中可以是其他操作????????fmt.Fprintf(os.Stdout,?"v:?%d?\n",?v)????????time.Sleep(time.Millisecond?*?1500)????????if?target?==?v?{????????????resultChan?<-?true????????????return????????}????}}
~~~
在執行查找任務的`goroutine`里接收上下文的取消信號,為了不阻塞查找任務,我們使用了`select`語句加`default`的組合:
~~~
select?{case?<-?ctx.Done():????fmt.Fprintf(os.Stdout,?"Task?cancelded!?\n")????returndefault:}
~~~
在`goroutine`里面如果找到了目標值,則會通過發送一個`true`值給`resultChan`,讓外面等待的主`goroutine`收到一個已經找到目標值的信號。
~~~
resultChan?<-?true
~~~
這樣通過上下文的`Done`通道和`resultChan`通道,`goroutine`們就能相互通信了。
> Go 語言中最常見的、也是經常被人提及的設計模式 — 不要通過共享內存的方式進行通信,而是應該通過通信的方式共享內存
完整的源代碼如下:
~~~
package?mainimport?(????"context"????"fmt"????"os"????"time")func?main()?{????timer?:=?time.NewTimer(time.Second?*?5)????data?:=?[]int{1,?2,?3,?10,?999,?8,?345,?7,?98,?33,?66,?77,?88,?68,?96}????dataLen?:=?len(data)????size?:=?3????target?:=?345????ctx,?cancel?:=?context.WithCancel(context.Background())????resultChan?:=?make(chan?bool)????for?i?:=?0;?i?<?dataLen;?i?+=?size?{????????end?:=?i?+?size????????if?end?>=?dataLen?{????????????end?=?dataLen?-?1????????}????????go?SearchTarget(ctx,?data[i:end],?target,?resultChan)????}????select?{????case?<-timer.C:????????fmt.Fprintln(os.Stderr,?"Timeout!?Not?Found")????????cancel()????case?<-?resultChan:????????fmt.Fprintf(os.Stdout,?"Found?it!\n")????????cancel()????}????time.Sleep(time.Second?*?2)}func?SearchTarget(ctx?context.Context,?data?[]int,?target?int,?resultChan?chan?bool)?{????for?_,?v?:=?range?data?{????????select?{????????case?<-?ctx.Done():????????????fmt.Fprintf(os.Stdout,?"Task?cancelded!?\n")????????????return????????default:????????}????????//?模擬一個耗時查找,這里只是比對值,真實開發中可以是其他操作????????fmt.Fprintf(os.Stdout,?"v:?%d?\n",?v)????????time.Sleep(time.Millisecond?*?1500)????????if?target?==?v?{????????????resultChan?<-?true????????????return????????}????}}
~~~
為了打印演示結果所以加了幾處`time.Sleep`,這個程序更多的是提供思路框架,所以細節的地方沒有考慮。有幾位讀者把他們的答案發給了我,其中有一位的提供的答案在代碼實現上考慮的更全面,這個我們放到文末再說。
上面程序的執行結果如下:
~~~
v:?1?v:?88?v:?33?v:?10?v:?345?Found?it!v:?2?v:?999?Task?cancelded!?v:?68?Task?cancelded!?Task?cancelded!?
~~~
因為是并發程序所以每次打印的結果的順序是不一樣的,這個你們可以自己試驗一下。而且也并不是先開啟的`goroutine`就一定會先執行,主要還是看調度器先調度哪個。
### Go語言調度器
所有應用程序都是運行在操作系統上,真正用來干活(計算)的是`CPU`。所以談到`Go`語言調度器,我們也繞不開操作系統、進程與線程這些概念。線程是操作系統調度時的最基本單元,而 Linux 在調度器并不區分進程和線程的調度,它們在不同操作系統上也有不同的實現,但是在大多數的實現中線程都屬于進程。
多個線程可以屬于同一個進程并共享內存空間。因為多線程不需要創建新的虛擬內存空間,所以它們也不需要內存管理單元處理上下文的切換,線程之間的通信也正是基于共享的內存進行的,與重量級的進程相比,線程顯得比較輕量。
雖然線程比較輕量,但是在調度時也有比較大的額外開銷。每個線程會都占用 1 兆以上的內存空間,在對線程進行切換時不止會消耗較多的內存,恢復寄存器中的內容還需要向操作系統申請或者銷毀對應的資源。
大量的線程出現了新的問題
* 高內存占用
* 調度的CPU高消耗
然后工程師們就發現,其實一個線程分為"內核態"線程和"用戶態"線程。
一個`用戶態線程`必須要綁定一個`內核態線程`,但是CPU并不知道有`用戶態線程`的存在,它只知道它運行的是一個`內核態線程`(Linux的PCB進程控制塊)。這樣,我們再去細化分類,內核線程依然叫線程(thread),用戶線程叫協程(co-routine)。既然一個協程可以綁定一個線程,那么也可以通過實現協程調度器把多個協程與一個或者多個線程進行綁定。
`Go`語言的`goroutine`來自協程的概念,讓一組可復用的函數運行在一組線程之上,即使有協程阻塞,該線程的其他協程也可以被`runtime`調度,轉移到其他可運行的線程上。最關鍵的是,程序員看不到這些底層的細節,這就降低了編程的難度,提供了更容易的并發。
`Go`中,協程被稱為`goroutine`,它非常輕量,一個`goroutine`只占幾KB,并且這幾KB就足夠`goroutine`運行完,這就能在有限的內存空間內支持大量`goroutine`,支持了更多的并發。雖然一個`goroutine`的棧只占幾KB,但實際是可伸縮的,如果需要更多內存,`runtime`會自動為`goroutine`分配。
既然我們知道了`goroutine`和系統線程的關系,那么最關鍵的一點就是實現協程調度器了。
`Go`目前使用的調度器是2012年重新設計的,因為之前的調度器性能存在問題,所以使用4年就被廢棄了。重新設計的調度器使用`G-M-P`模型并一直沿用至今。
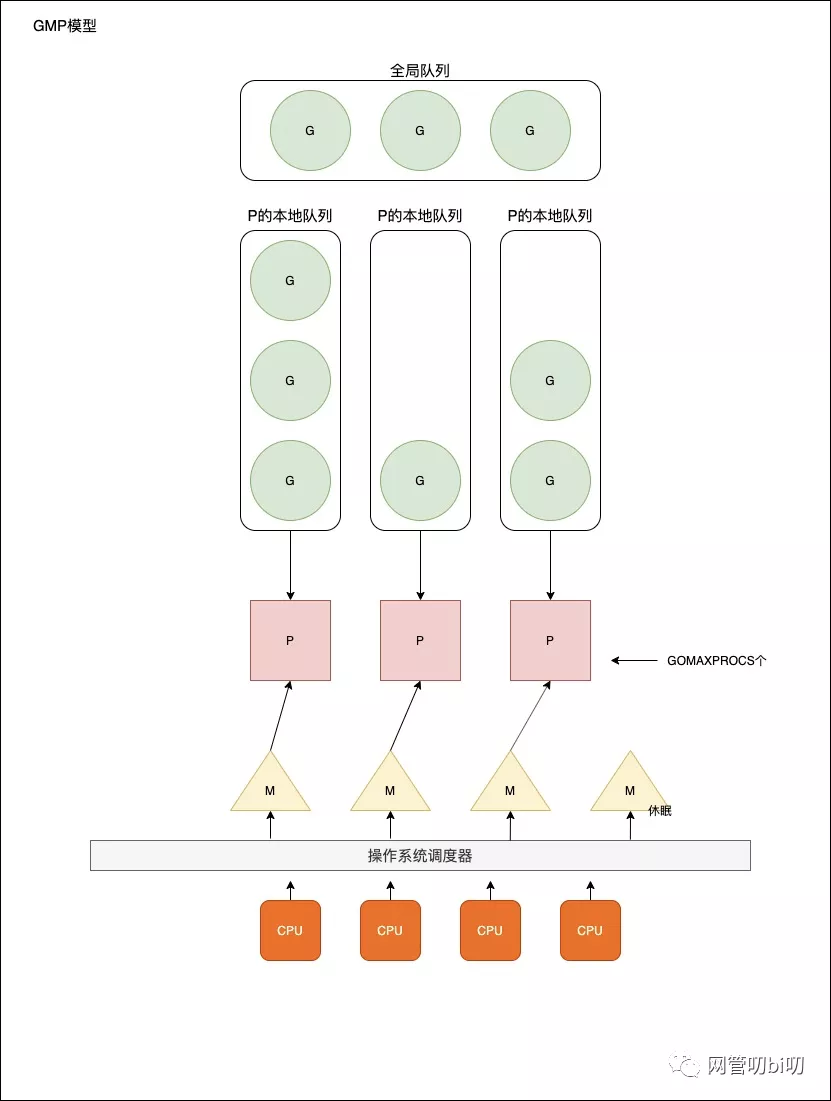
調度器G-M-P模型
* G — 表示 goroutine,它是一個待執行的任務;
* M — 表示操作系統的線程,它由操作系統的調度器調度和管理;
* P — 表示處理器,它可以被看做運行在線程上的本地調度器;
### G
`gorotuine`?就是`Go`語言調度器中待執行的任務,它在運行時調度器中的地位與線程在操作系統中差不多,但是它占用了更小的內存空間,也降低了上下文切換的開銷。
`goroutine`只存在于`Go`語言的運行時,它是`Go`語言在用戶態提供的線程,作為一種粒度更細的資源調度單元,如果使用得當能夠在高并發的場景下更高效地利用機器的`CPU`。
### M
`Go`語言并發模型中的`M`是操作系統線程。調度器最多可以創建 10000 個線程,但是其中大多數的線程都不會執行用戶代碼(可能陷入系統調用),最多只會有?`GOMAXPROCS`?個活躍線程能夠正常運行。
在默認情況下,運行時會將?`GOMAXPROCS`?設置成當前機器的核數,我們也可以使用?`runtime.GOMAXPROCS`?來改變程序中最大的線程數。一個四核機器上會創建四個活躍的操作系統線程,每一個線程都對應一個運行時中的?`runtime.m`?結構體。
在大多數情況下,我們都會使用`Go`的默認設置,也就是活躍線程數等于`CPU`個數,在這種情況下不會觸發操作系統的線程調度和上下文切換,所有的調度都會發生在用戶態,由`Go`語言調度器觸發,能夠減少非常多的額外開銷。
操作系統線程在`Go`語言中會使用私有結構體?`runtime.m`?來表示
~~~
type?m?struct?{????g0???*g?????curg?*g????...}
~~~
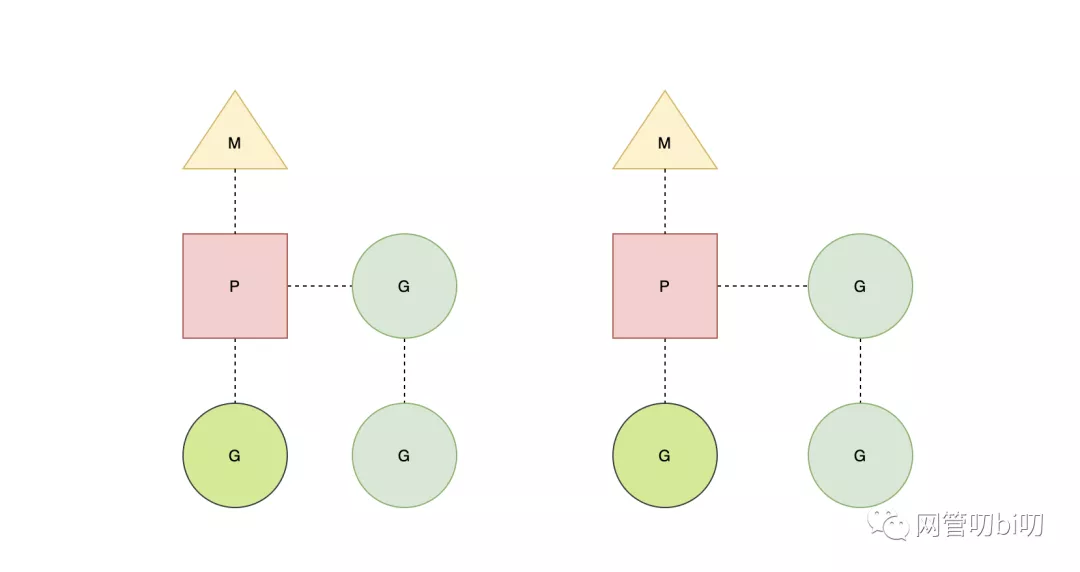
其中`g0`是持有調度棧的`goroutine`,`curg`?是在當前線程上運行的用戶`goroutine`,用戶`goroutine`執行完后,線程切換回`g0`上,`g0`會從線程`M`綁定的`P`上的等待隊列中獲取`goroutine`交給線程。
### P
調度器中的處理器`P`是線程和`goroutine`?的中間層,它能提供線程需要的上下文環境,也會負責調度線程上的等待隊列,通過處理器`P`的調度,每一個內核線程都能夠執行多個?`goroutine`,它能在`goroutine`?進行一些?`I/O`?操作時及時切換,提高線程的利用率。因為調度器在啟動時就會創建?`GOMAXPROCS`?個處理器,所以`Go`語言程序的處理器數量一定會等于?`GOMAXPROCS`,這些處理器會綁定到不同的內核線程上并利用線程的計算資源運行`goroutine`。
此外在調度器里還有一個全局等待隊列,當所有P本地的等待隊列被占滿后,新創建的`goroutine`會進入全局等待隊列。`P`的本地隊列為空后,`M`也會從全局隊列中拿一批待執行的`goroutine`放到`P`本地的等待隊列中。
### GMP模型圖示
GMP模型圖示
* 全局隊列:存放等待運行的G。
* P的本地隊列:同全局隊列類似,存放的也是等待運行的G,存的數量有限,不超過256個。新建G時,G優先加入到P的本地隊列,如果隊列已滿,則會把本地隊列中一半的G移動到全局隊列。
* P列表:所有的P都在程序啟動時創建,并保存在數組中,最多有GOMAXPROCS(可配置)個。
* M:線程想運行任務就得獲取P,從P的本地隊列獲取G,P隊列為空時,M也會嘗試從全局隊列拿一批G放到P的本地隊列,或從其他P的本地隊列偷一半放到自己P的本地隊列。M運行G,G執行之后,M會從P獲取下一個G,不斷重復下去。
* `goroutine`調度器和OS調度器是通過M結合起來的,每個M都代表了1個內核線程,OS調度器負責把內核線程分配到CPU上執行。
### 調度器的策略
調度器的一個策略是盡可能的復用現有的活躍線程,通過以下兩個機制提高線程的復用:
1. work stealing機制,當本線程無可運行的G時,嘗試從其他線程綁定的P偷取G,而不是銷毀線程。
2. hand off機制,當本線程因為G進行系統調用阻塞時,線程釋放綁定的P,把P轉移給其他空閑的線程執行。
`Go`的運行時并不具備操作系統內核級的硬件中斷能力,基于工作竊取的調度器實現,本質上屬于先來先服務的協作式調度,為了解決響應時間可能較高的問題,目前運行時實現了協作式調度和搶占式調度兩種不同的調度策略,保證在大部分情況下,不同的 G 能夠獲得均勻的`CPU`時間片。
協作式調度依靠被調度方主動棄權,系統監控到一個`goroutine`運行超過10ms會通過?`runtime.Gosched`?調用主動讓出執行機會。搶占式調度則依靠調度器強制將被調度方被動中斷。
推薦其他博主的一篇文章[Golang調度器GMP原理與調度全分析](https://mp.weixin.qq.com/s?__biz=MzA5MjA2NTY5MA==&mid=2453248415&idx=1&sn=08cdb7ab4dd8d7c563d6eaffe834c4a9&scene=21#wechat_redirect),里面用幾十張圖詳細展示了全場景的調度策略解析,讓我們更容易理解調度器的`GMP`模型和它的工作原理。
如果想從Go的源碼層面了解調度器的實現,可以看看下面鏈接這個博主的系列文章。
https://changkun.de/golang/zh-cn/part2runtime/ch06sched/
回到文章第一部分說的并發題的解決方案,讀者@CDS給出了一個更通用的實現版本,把`goroutine`相互通信這部分邏輯抽象了出來,遇到與思考題相似的同類問題后只需要實現執行具體任務的`worker`即可。由于代碼的復雜度以及占用的篇幅太長,不太適合放到文章里解釋題目的解題思路,在征得他同意后我把他的實現方案的GitHub倉庫鏈接放到了閱讀原文里,感興趣的可以克隆下來看看。
- Golnag常見面試題目解析
- 交替打印數組和字母
- 判斷字符串中字符是否全都不同
- 翻轉字符串
- 判斷兩個給定的字符串排序后是否一致
- 字符串替換問題
- 機器人坐標計算
- 語法題目一
- 語法題目二
- goroutine和channel使用一
- 實現阻塞讀的并發安全Map
- 定時與 panic 恢復
- 高并發下的鎖與map讀寫問題
- 為 sync.WaitGroup 中Wait函數支持 WaitTimeout 功能.
- 七道語法找錯題目
- golang 并發題目測試
- 記一道字節跳動的算法面試題
- 多協程查詢切片問題
- 對已經關閉的的chan進行讀寫,會怎么樣?為什么?
- 簡單聊聊內存逃逸?
- 字符串轉成byte數組,會發生內存拷貝嗎?
- http包的內存泄漏