
# Stream API (下)
# Stream API 下
## Collector 收集
收集器用來將經過篩選、映射的流進行最后的整理,可以使得最后的結果以不同的形式展現。
`collect`方法即為收集器,它接收`Collector`接口的實現作為具體收集器的收集方法。
`Collector`接口提供了很多默認實現的方法,我們可以直接使用它們格式化流的結果;也可以自定義`Collector`接口的實現,從而定制自己的收集器。
### 歸約
流由一個個元素組成,歸約就是將一個個元素“折疊”成一個值,如求和、求最值、求平均值都是歸約操作。
### 一般性歸約
若你需要自定義一個歸約操作,那么需要使用`Collectors.reducing`函數,該函數接收三個參數:
* 第一個參數為歸約的初始值
* 第二個參數為歸約操作進行的字段
* 第三個參數為歸約操作的過程
## 匯總
Collectors類專門為匯總提供了一個工廠方法:`Collectors.summingInt`。
它可接受一 個把對象映射為求和所需int的函數,并返回一個收集器;該收集器在傳遞給普通的`collect`方法后即執行我們需要的匯總操作。
### 分組
數據分組是一種更自然的分割數據操作,分組就是將流中的元素按照指定類別進行劃分,類似于SQL語句中的`GROUPBY`。
### 多級分組
多級分組可以支持在完成一次分組后,分別對每個小組再進行分組。
使用具有兩個參數的`groupingBy`重載方法即可實現多級分組。
* 第一個參數:一級分組的條件
* 第二個參數:一個新的`groupingBy`函數,該函數包含二級分組的條件
**Collectors 類的靜態工廠方法**
待添加。。。
### 轉換類型
有一些收集器可以生成其他集合。比如前面已經見過的`toList`,生成了`java.util.List`類的實例。
還有`toSet`和`toCollection`,分別生成`Set`和`Collection`類的實例。
到目前為止, 我已經講了很多流上的鏈式操作,但總有一些時候,需要最終生成一個集合——比如:
* 已有代碼是為集合編寫的,因此需要將流轉換成集合傳入;
* 在集合上進行一系列鏈式操作后,最終希望生成一個值;
* 寫單元測試時,需要對某個具體的集合做斷言。
使用`toCollection`,用定制的集合收集元素
~~~
stream.collect(toCollection(TreeSet::new));
~~~
還可以利用收集器讓流生成一個值。`maxBy`和`minBy`允許用戶按某種特定的順序生成一個值。
### 數據分區
分區是分組的特殊情況:由一個斷言(返回一個布爾值的函數)作為分類函數,它稱分區函數。
分區函數返回一個布爾值,這意味著得到的分組`Map`的鍵類型是`Boolean`,于是它最多可以分為兩組: true是一組,false是一組。
分區的好處在于保留了分區函數返回true或false的兩套流元素列表。
### 并行流
并行流就是一個把內容分成多個數據塊,并用不不同的線程分別處理每個數據塊的流。最后合并每個數據塊的計算結果。
將一個順序執行的流轉變成一個并發的流只要調用`parallel()`方法
~~~
public static long parallelSum(long n){
return Stream.iterate(1L, i -> i +1).limit(n).parallel().reduce(0L,Long::sum);
}
~~~
將一個并發流轉成順序的流只要調用`sequential()`方法
~~~
stream.parallel().filter(...).sequential().map(...).parallel().reduce();
~~~
這兩個方法可以多次調用,只有最后一個調用決定這個流是順序的還是并發的。
并發流使用的默認線程數等于你機器的處理器核心數。
通過這個方法可以修改這個值,這是全局屬性。
~~~
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "12");
~~~
并非使用多線程并行流處理數據的性能一定高于單線程順序流的性能,因為性能受到多種因素的影響。
如何高效使用并發流的一些建議:
1. 如果不確定, 就自己測試。
2. 盡量使用基本類型的流 IntStream, LongStream, DoubleStream
3. 有些操作使用并發流的性能會比順序流的性能更差,比如limit,findFirst,依賴元素順序的操作在并發流中是極其消耗性能的。findAny的性能就會好很多,應為不依賴順序。
4. 考慮流中計算的性能(Q)和操作的性能(N)的對比, Q表示單個處理所需的時間,N表示需要處理的數量,如果Q的值越大, 使用并發流的性能就會越高。
5. 數據量不大時使用并發流,性能得不到提升。
6. 考慮數據結構:并發流需要對數據進行分解,不同的數據結構被分解的性能時不一樣的。
**流的數據源和可分解性**
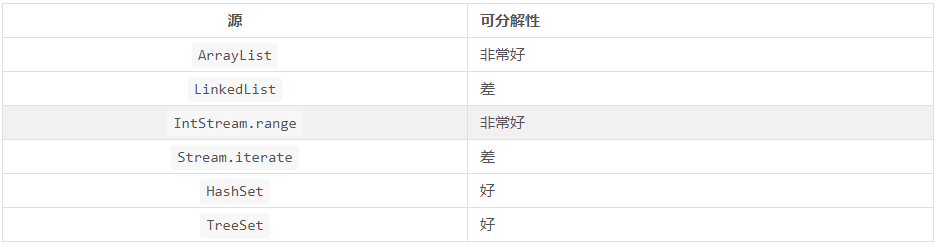
**流的特性以及中間操作對流的修改都會對數據對分解性能造成影響。 比如固定大小的流在任務分解的時候就可以平均分配,但是如果有filter操作,那么流就不能預先知道在這個操作后還會剩余多少元素。**
**考慮終端操作的性能:如果終端操作在合并并發流的計算結果時的性能消耗太大,那么使用并發流提升的性能就會得不償失。**
- 序
- 快速開始
- 環境要求
- 環境準備
- 工程導入
- 工程運行
- 技術基礎
- Java8
- Lambda
- Lambda 受檢異常處理
- Stream 簡介
- Stream API 一覽
- Stream API(上)
- Stream API(下)
- Optional 干掉空指針
- 函數式接口
- 新的日期 API
- Lombok
- SpringMVC
- Swagger
- Mybaties
- Mybaties-plus
- 開發初探
- 新建微服務工程
- 第一個API
- API鑒權
- API響應結果
- Redis 緩存
- 第一個CRUD
- 建表
- 建Entity
- 建Service和Mapper
- 新增API
- 修改API
- 刪除API
- 查詢API
- 單條查詢
- 多條查詢
- 分頁
- 微服務遠程調用
- 聲明式服務調用Feign
- 熔斷機制 Hystrix
- 開發進階