
[TOC]
# 概述
PHP(本文所述案例PHP版本均為7.1.3)作為一門動態腳本語言,其在zend虛擬機執行過程為:
讀入腳本程序字符串,
經由詞法分析器將其轉換為單詞符號,
接著語法分析器從中發現語法結構后生成抽象語法樹,
再經靜態編譯器生成opcode,
最后經解釋器模擬機器指令來執行每一條opcode。
在上述整個環節中,生成的opcode可以應用編譯優化技術如死代碼刪除、條件常量傳播、函數內聯等各種優化來精簡opcode,達到提高代碼的執行性能的目的。
PHP擴展opcache,針對生成的opcode基于共享內存支持了緩存優化。在此基礎上又加入了opcode的靜態編譯優化。這里所述優化通常采用優化器(Optimizer)來管理,編譯原理中,一般用優化遍(Opt pass)來描述每一個優化。
詞法分析中,有正則表達式,自動機兩個概念.
描敘程序設計語言中的單詞的工具有三種.(正則表達式,正則文法,自動機)
php自帶函數token_get_all 就是個詞法分析
整體上說,優化遍分兩種:
* 一種是分析pass,是提供數據流、控制流分析信息為轉換pass提供輔助信息;
* 一種是轉換pass,它會改變生成代碼,包括增刪指令、改變替換指令、調整指令順序等,通常每一個pass前后可dump出生成代碼的變化。
本文基于編譯原理,結合opcache擴展提供的優化器,以PHP編譯基本單位op_array、PHP執行最小單位opcode為出發點。介紹編譯優化技術在Zend虛擬機中的應用,梳理各個優化遍是如何一步步優化opcode來提高代碼執行性能的。最后結合PHP語言虛擬機執行給出幾點展望
# 幾個概念說明
## 靜態編譯/解釋執行/即時編譯
靜態編譯(static compilation),也稱事前編譯(ahead-of-time compilation),簡稱AOT。即把源代碼編譯成目標代碼,執行時在支持目標代碼的平臺上運行。
動態編譯(dynamic compilation),相對于靜態編譯而言,指”在運行時進行編譯”。通常情況下采用解釋器(interpreter)編譯執行,它是指一條一條的解釋執行源語言。
JIT編譯(just-in-time compilation),即即時編譯,狹義指某段代碼即將第一次被執行時進行編譯,而后則不用編譯直接執行,它為動態編譯的一種特例。
上述三類不同編譯執行流程,可大體如下圖來描述:

## JIT
JIT是什么?為什么是JIT?
鳥哥并沒有做過多的解釋。我就談一些我的膚淺認識,給phper們提供些參考。
首先JIT(just in time)并非是新技術,一大批語言如java早已實現。JIT的思想很簡單,即在程序運行時動態對程序進行編譯,生成平臺相關的機器碼,從而加快程序運行速度。
php文件的執行流程大致是首先引擎加載php文件,解釋器逐條解釋執行代碼。引入JIT后,前面一樣,重點是JIT編譯器會根據Runtime信息對熱點代碼進行動態編譯生成機器碼,然后這部分代碼以后就可以直接執行了,而不需要解釋器逐條解釋執行了,運行效率便得到了提升
看到這里不知道大家是否和我有一樣的疑問,既然編譯為機器碼執行的效率那么高,為何不在項目正式部署前全部進行編譯,何必在運行時編譯?要知道運行時編譯也會增加程序的執行時間的。我在查閱了一些資料和一番思考后,有以下一些淺見
代碼發布前先編譯,是比JIT更早的通用辦法,稱為AOT(ahead of time),c語言便是這種執行模式。關于這兩種模式孰優孰劣,學術界一直爭論不休,目前也沒有定論。但JIT相比AOT有這樣幾個優點
發布速度快。不用每次都編譯,發布速度自然快
優化效率更好。因為JIT是基于Runtime信息,比AOT更“了解”代碼,優化的效率更好。比如分析Runtime得知某個變量雖然聲明是10個字節,但運行過程中一直是1個字節,那么就可以減小程序內存消耗;再比如某段代碼始終未被執行,JIT則可以直接將其忽略
粒度更精細。JIT可以只針對hotspot(熱點)進行編譯,熱點可能是一個函數或者只是一個代碼段
對碼農透明。JIT無須碼農自己對程序根據不同平臺進行編譯發布,只需要寫高級代碼即可
基于以上幾個優點,再結合php一貫的簡單易用原則,我想JIT確實是不錯的選擇。不過php也是支持AOT的,有興趣的同學可以查一下。
但JIT技術也絕不是靈丹妙藥,即便是編譯也是需要時間的,當代碼編譯的時間消耗大于運行收益時,程序反而會變慢!會有這種情況嗎?有的,比如某個項目中,熱點并不明顯,JIT編譯的代碼執行次數都很少,那么編譯帶來的收益是有可能小于編譯本身的消耗的
**我認為Jit的本質是猜測數據類型,因為機器碼的本質就是寄存器和內存的運算,解釋語言慢的本質是類型不明確**
## 數據流/控制流
編譯優化需要從程序中獲取足夠多的信息,這是所有編譯優化的根基。
編譯器前端產生的結果可以是語法樹亦可以是某種低級中間代碼。但無論結果什么形式,它對程序做什么、如何做仍然沒有提供多少信息。編譯器將發現每一個過程內控制流層次結構的任務留給控制流分析,將確定與數據處理有關的全局信息任務留給數據流分析。
* 控制流 是獲取程序控制結構信息的形式化分析方法,它為數據流分析、依賴分析的基礎。控制的一個基本模型是控制流圖(Control Flow Graph,CFG)。單一過程的控制流分析有使用必經結點找循環、區間分析兩種途徑。
* 數據流 從程序代碼中收集程序的語義信息,并通過代數的方法在編譯時確定變量的定義和使用。數據的一個基本模型是數據流圖(Data Flow Graph,DFG)。通常的數據流分析是基于控制樹的分析(Control-tree-based data-flow analysis),算法分為區間分析與結構分析兩種。
## op_array
類似于C語言的棧幀(stack frame)概念,即一個運行程序的基本單位(一幀),一般為一次函數調用的基本單位。此處,一個函數或方法、整個PHP腳本文件、傳給eval表示PHP代碼的字符串都會被編譯成一個op_array。
實現上op_array為一個包含程序運行基本單位的所有信息的結構體,當然opcode數組為該結構最為重要的字段,不過除此之外還包含變量類型、注釋信息、異常捕獲信息、跳轉信息等。
## opcode
解釋器執行(ZendVM)過程即是執行一個基本單位op_array內的最小優化opcode,按順序遍歷執行,執行當前opcode,會預取下一條opcode,直到最后一個RETRUN這個特殊的opcode返回退出。
這里的opcode某種程度也類似于靜態編譯器里的中間表示(類似于LLVM IR),通常也采用三地址碼的形式,即包含一個操作符,兩個操作數及一個運算結果。其中兩個操作數均包含類型信息。此處類型信息有五種,分別為:
* 編譯變量(Compiled Variable,簡稱CV),編譯時變量即為php腳本中定義的變量。
* 內部可重用變量(VAR),供ZendVM使用的臨時變量,可與其它opcode共用。
* 內部不可重用變量(TMP_VAR),供ZendVM使用的臨時變量,不可與其它opcode共用。
* 常量(CONST),只讀常量,值不可被更改。
* 無用變量(UNUSED)。由于opcode采用三地址碼,不是每一個opcode均有操作數字段,缺省時用該變量補齊字段。
類型信息與操作符一起,供執行器匹配選擇特定已編譯好的C函數庫模板,模擬生成機器指令來執行。
opcode在ZendVM中以zend_op結構體來表征,其主體結構如下:

# opcache optimizer優化器
PHP腳本經過詞法分析、語法分析生成抽象語法樹結構后,再經靜態編譯生成opcode。它作為向不同的虛擬機執行指令的公共平臺,依賴不同的虛擬機具體實現(然對于PHP來說,大部分是指ZendVM)。
在虛擬機執行opcode之前,如果對opcode進行優化可得到執行效率更高的代碼,pass的作用就是優化opcode,它作用于opcde、處理opcode、分析opcode、尋找優化的機會并修改opcode產生更高執行效率的代碼。
## ZendVM優化器簡介
在Zend虛擬機(ZendVM)中,opcache的靜態代碼優化器即為zend opcode optimization。
為觀察優化效果及便于調試,它也提供了優化與調試選項:
* optimizationlevel (opcache.optimizationlevel=0xFFFFFFFF) 優化級別,缺省打開大部分優化遍,用戶亦通過傳入命令行參數控制關閉
* optdebuglevel (opcache.optdebuglevel=-1) 調試級別,缺省不打開,但提供了各優化前后opcode的變換過程
執行靜態優化所需的腳本上下文信息則封裝在結構zend_script中,如下:
~~~
typedef struct _zend_script {
zend_string *filename; //文件名
zend_op_array main_op_array; //棧幀
HashTable function_table; //函數單位符號表信息
HashTable class_table; //類單位符號表信息
} zend_script;
~~~
上述三個內容信息即作為輸入參數傳遞給優化器供其分析優化。當然與通常的PHP擴展類似,它與opcode緩存模塊一起(zend_accel)構成了opcache擴展。其在緩存加速器內嵌入了三個內部API:
* zendoptimizerstartup 啟動優化器
* zendoptimizescript 優化器實現優化的主邏輯
* zendoptimizershutdown 優化器產生的資源清理
關于opcode緩存,也是opcode非常重要的優化。其基本應用原理是大體如下:
雖然PHP作為動態腳本語言,它并不會直接調用GCC/LLVM這樣的整套編譯器工具鏈,也不會調用Javac這樣的純前端編譯器。但每次請求執行PHP腳本時,都經歷過詞法、語法、編譯為opcode、VM執行的完整生命周期。
除去執行外的前三個步驟基本就是一個前端編譯器的完整過程,然而這個編譯過程并不會快。假如反復執行相同的腳本,前三個步驟編譯耗時將嚴重制約運行效率,而每次編譯生成的opcode則沒有變化。因此可在第一次編譯時把opcode緩存到某一個地方,opcache擴展即是將其緩存到共享內存(Java則是保存到文件中),下次執行相同腳本時直接從共享內存中獲取opcode,從而省去編譯時間。
opcache擴展的opcode 緩存流程大致如下:

由于本文主要集中討論靜態優化遍,關于緩存優化的具體實現此處不展開。
## ZendVM優化器原理
依“鯨書”(《高級編譯器設計與實現》)所述,一個優化編譯器較為合理的優化遍順序如下:
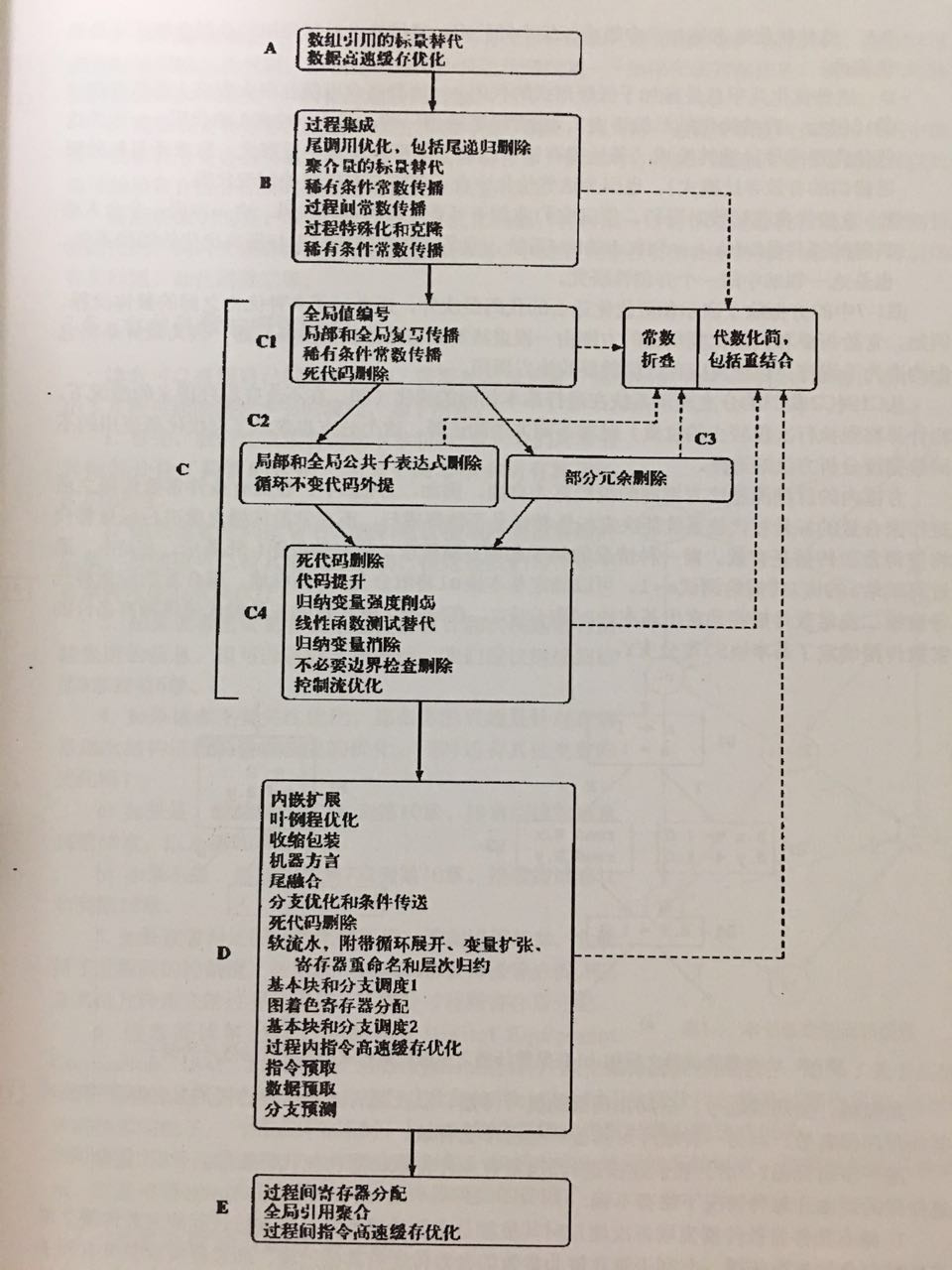
上圖中涉及的優化從簡單的常量、死代碼到循環、分支跳轉,從函數調用到過程間優化,從預取、緩存到軟流水、寄存器分配,當然也包含數據流、控制流分析。
當然,當前opcode優化器并沒有實現上述所有優化遍,而且也沒有必要實現機器相關的低層中間表示優化如寄存器分配。
opcache優化器接收到上述腳本參數信息后,找到最小編譯單位。以此為基礎,根據優化pass宏及其對應的優化級別宏,即可實現對某一個pass的注冊控制。
注冊的優化中,按一定順序組織串聯各優化,包含常量優化、冗余nop刪除、函數調用優化的轉換pass,及數據流分析、控制流分析、調用關系分析等分析pass。
zendoptimizescript及實際的優化注冊zend_optimize流程如下:
~~~
zend_optimize_script(zend_script *script,
zend_long optimization_level, zend_long debug_level)
|zend_optimize_op_array(&script->main_op_array, &ctx);
遍歷二元操作符的常量操作數,由運行時轉化為編譯時(反向pass2)
實際優化pass,zend_optimize
遍歷二元操作符的常量操作數,由編譯時轉化為運行時(pass2)
|遍歷op_array內函數zend_optimize_op_array(op_array, &ctx);
|遍歷類內非用戶函數zend_optimize_op_array(op_array, &ctx);
(用戶函數設static_variables)
|若使用DFA pass & 調用圖pass & 構建調用圖成功
遍歷二元操作符的常量操作數,由運行時轉化為編譯時(反向pass2)
設置函數返回值信息,供SSA數據流分析使用
遍歷調用圖的op_array,做DFA分析zend_dfa_analyze_op_array
遍歷調用圖的op_array,做DFA優化zend_dfa_optimize_op_array
若開調試,遍歷dump調用圖的每一個op_array(優化變換后)
若開棧矯正優化,矯正棧大小adjust_fcall_stack_size_graph
再次遍歷調用圖內的的所有op_array,
針對DFA pass變換后新產生的常量場景,常量優化pass2再跑一遍
調用圖op_array資源清理
|若開棧矯正優化
矯正棧大小main_op_array
遍歷矯正棧大小op_array
|清理資源
~~~
該部分主要調用了SSA/DFA/CFG這幾類用于opcode分析pass,涉及的pass有BB塊、CFG、DFA(CFG、DOMINATORS、LIVENESS、PHI-NODE、SSA)。
用于opcode轉換的pass則集中在函數zend_optimize內,如下:
~~~
zend_optimize
|op_array類型為ZEND_EVAL_CODE,不做優化
|開debug, 可dump優化前內容
|優化pass1, 常量替換、編譯時常量操作變換、簡單操作轉換
|優化pass2 常量操作轉換、條件跳轉指令優化
|優化pass3 跳轉指令優化、自增轉換
|優化pass4 函數調用優化(主要為函數調用優化)
|優化pass5 控制流圖(CFG)優化
|構建流圖
|計算數據依賴
|劃分BB塊(basic block,簡稱BB,數據流分析基本單位)
|BB塊內基于數據流分析優化
|BB塊間跳轉優化
|不可到達BB塊刪除
|BB塊合并
|BB塊外變量檢查
|重新構建優化后的op_array(基于CFG)
|析構CFG
|優化pass6/7 數據流分析優化
|數據流分析(基于靜態單賦值SSA)
|構建SSA
|構建CFG 需要找到對應BB塊序號、管理BB塊數組、計算BB塊后繼BB、標記可到達BB塊、計算BB塊前驅BB
|計算Dominator樹
|標識循環是否可簡化(主要依賴于循環回邊)
|基于phi節點構建完SSA def集、phi節點位置、SSA構造重命名
|計算use-def鏈
|尋找不當依賴、后繼、類型及值范圍值推斷
|數據流優化 基于SSA信息,一系列BB塊內opcode優化
|析構SSA
|優化pass9 臨時變量優化
|優化pass10 冗余nop指令刪除
|優化pass11 壓縮常量表優化
~~~
還有其他一些優化遍如下:
~~~
優化pass12 矯正棧大小
優化pass15 收集常量信息
優化pass16 函數調用優化,主要是函數內聯優化
~~~
除此之外,pass 8/13/14可能為預留pass id。由此可看出當前提供給用戶選項控制的opcode轉換pass有13個。但是這并不計入其依賴的數據流/控制流的分析pass。
## 函數內聯pass的實現
通常在函數調用過程中,由于需要進行不同棧幀間切換,因此會有開辟棧空間、保存返回地址、跳轉、返回到調用函數、返回值、回收棧空間等一系列函數調用開銷。因此對于函數體適當大小情況下,把整個函數體嵌入到調用者(Caller)內部,從而不實際調用被調用者(Callee)是一個提升性能的利器。
由于函數調用與目標機的應用二進制接口(ABI)強相關,靜態編譯器如GCC/LLVM的函數內聯優化基本是在指令生成之前完成。
ZendVM的內聯則發生在opcode生成后的FCALL指令的替換優化,pass id為16,其原理大致如下:
~~~
| 遍歷op_array中的opcode,找到DO_XCALL四個opcode之一
| opcode ZEND_INIT_FCALL
| opcode ZEND_INIT_FCALL_BY_NAMEZ
| 新建opcode,操作碼置為ZEND_INIT_FCALL,計算棧大小,
更新緩存槽位,析構常量池字面量,替換當前opline的opcode
| opcode ZEND_INIT_NS_FCALL_BY_NAME
| 新建opcode,操作碼置為ZEND_INIT_FCALL,計算棧大小,
更新緩存槽位,析構常量池字面量,替換當前opline的opcode
| 嘗試函數內聯
| 優化條件過濾 (每個優化pass通常有較多限制條件,某些場景下
由于缺乏足夠信息不能優化或出于代價考慮而排除)
| 方法調用ZEND_INIT_METHOD_CALL,直接返回不內聯
| 引用傳參,直接返回不內聯
| 缺省參數為命名常量,直接返回不內聯
| 被調用函數有返回值,添加一條ZEND_QM_ASSIGN賦值opcode
| 被調用函數無返回值,插入一條ZEND_NOP空opcode
| 刪除調用被內聯函數的call opcode(即當前online的前一條opcode)
~~~
如下示例代碼,當調用fname()時,使用字符串變量名fname來動態調用函數foo,而沒有使用直接調用的方式。此時可通過VLD擴展查看其生成的opcode,或打開opcache調試選項(opcache.optdebuglevel=0xFFFFFFFF)亦可查看。
~~~
function foo() { }
$fname = 'foo';
~~~
開啟debug后dump可看出,發生函數調用優化前opcode序列(僅截取片段)為:
~~~
ASSIGN CV0($fname) string("foo")
INIT_FCALL_BY_NAME 0 CV0($fname)
DO_FCALL_BY_NAME
~~~
INIT_FCALL_BY_NAME這條opcode執行邏輯較為復雜,當開啟激進內聯優化后,可將上述指令序列直接合并成一條DO_FCALL string("foo")指令,省去間接調用的開銷。這樣也恰好與直接調用生成的opcode一致。
## 如何為opcache opt添加一個優化pass
根據以上描述,可見向當前優化器加入一個pass并不會太難,大體步驟如下:
先向zend_optimize優化器注冊一個pass宏(例如添加pass17),并決定其優化級別。
在優化管理器某個優化pass前后調用加入的pass(例如添加一個尾遞歸優化pass),建議在DFA/SSA分析pass之后添加,因為此時獲得的優化信息更多。
實現新加入的pass,進行定制代碼轉換(例如zendoptimizefunc_calls實現一個尾遞歸優化)。針對當前已有pass,主要添加轉換pass,這里一般也可利用SSA/DFA的信息。不同于靜態編譯優化一般是在貼近于機器相關的低層中間表示優化,這里主要是在opcode層的opcode/operand相應的一些轉換。
實現pass前,與函數內聯類似,通常首先收集優化所需信息,然后排除掉不適用該優化的一些場景(如非真正的尾不遞歸調用、參數問題無法做優化等)。實現優化后,可dump優化前后生成opcode結構的變化是否優化正確、是否符合預期(如尾遞歸優化最終的效果是變換函數調用為forloop的形式)
# 一點思考
以下是對基于動態的PHP腳本程序執行的一些看法,僅供參考。
由于LLVM從前端到后端,從靜態編譯到jit整個工具鏈框架的支持,使得許多語言虛擬機都嘗試整合。當前PHP7時代的ZendVM官方還沒采用,原因之一虛擬機opcode承載著相當復雜的分析工作。相比于靜態編譯器的機器碼每一條指令通常只干一件事情(通常是CPU指令時鐘周期),opcode的操作數(operand)由于類型不固定,需要在運行期間做大量的類型檢查、轉換才能進行運算,這極度影響了執行效率。即使運行時采用jit,以byte code為單位編譯,編譯出的字節碼也會與現有解釋器一條一條opcode處理類似,類型需要處理、也不能把zval值直接存在寄存器。
以函數調用為例,比較現有的opcode執行與靜態編譯成機器碼執行的區別,如下圖

# 類型推斷
在不改變現有opcode設計的前提下,加強類型推斷能力,進而為opcode的執行提供更多的類型信息,是提高執行性能的可選方法之一。
# 多層opcode
既然opcode承擔如此復雜的分析工作,能否將其分解成多層的opcode歸一化中間表示( intermediate representation, IR)。各優化可選擇應用哪一層中間表示,傳統編譯器的中間表示依據所攜帶信息量、從抽象的高級語言到貼近機器碼,分成高級中間表示(HIR) 、中級中間表示(MIR)、低級中間表示(LIR)。
# pass管理
關于opcode的優化pass管理,如前文鯨書圖所述,應該尚有改進空間。雖然當前分析依賴的有數據流/控制流分析,但仍缺少諸如過程間的分析優化,pass管理如運行順序、運行次數、注冊管理、復雜pass分析的信息dump等相對于llvm等成熟框架仍有較大差距。
# JIT
ZendVM實現大量的zval值、類型轉換等操作,這些可借助LLVM編譯成機器碼用于運行時,但代價是編譯時間極速膨脹。當然也可采用libjit
- OAuth
- 簡介
- 步驟
- 單點登錄
- .user.ini
- 時間轉換為今天昨天前天幾天前
- 獲取ip接口
- 協程
- 概念
- yield-from && return-values
- 協程與阻塞的思考
- 中間件
- mysqli異步與php的協程
- 代碼片段
- pdo 執行的sql語句
- 二進制安全
- 捕捉異常中斷
- global
- 利用cookie模擬登陸
- 解析非正常json
- 簡單的對稱加密算法
- RSA 加密
- 過濾掉emoji表情
- 判斷遠程圖片是否存在
- 一分鐘限制請求100次
- 文件處理
- 多文件上傳
- 顯示所有文件
- 文件下載和上面顯示所有文件配合
- 文件的刪除,統計,存數組等
- 圖片處理
- 簡介
- 驗證碼
- 圖片等比縮放
- 批量添加水印
- beanstalkd
- 安裝
- 使用
- RabbitMQ
- 簡介
- debain安裝
- centos安裝
- 常用方法
- 入門
- 工作隊列
- 訂閱,發布
- 路由
- 主題
- 遠程調用RPC
- 消息中間件的選型
- .htaccess
- isset、empty、if區別以及0、‘’、null
- php各版本
- php7.2 不向后兼容的改動
- php中的各種坑
- php7改變
- php慢日志
- 郵件
- PHPMailer實現發郵件
- 驗證郵件地址真實性
- 文件下載
- FastCgi 與 PHP-fpm 之間的關系
- openssl 加解密
- 反射
- 鉤子方法
- 查找插件
- opcode
- opcache使用
- opcache優化
- 分布式一致性hash算法
- 概念
- 哈希算法好壞的四個定義
- php實現
- java實現
- 數組
- jwt
- jwt簡介
- 單點登錄
- phpize
- GeoIP擴展
- php無法獲得https網頁內容的解決方案
- homestead運行的腳本
- Unicode和Utf-8轉換
- php優化
- kafka
- fpm配置
- configure配置詳解