計算機其實就是可以做數學計算的機器,所以計算機程序當然可以處理各種數值。任何一種語言最重要的就是他的數據結構。
在Python 里面常用的數據類型有
- 基本數據類型:包含整數、浮點數、布爾值,可以看成是單獨的數據
- 容器數據類型:單獨的數據放到一個容器里面就可以得到**容器類型**的數據,比如說字符串、元組、列表、字典、集合
> 可以使用 `dir(int)`這種類型的函數查看對象中可用的屬性和方法
# 基本數據類型
## 整數
## 浮點數
整數加上一個小數點,就可以創建float
## 布爾值
對與數值變量,0,0.0都可以認為是空的,對于容器變量,里面沒有元素就可以認為是空的。
## 空值
空值是 Python 里一個特殊的值,用 None 表示。None 不能理解為 0,因為 0 是有意義的,而 None 是一個特殊的空值。
# 容器數據類型
## 字符串
### 創建字符串
字符串是以單引號' 或雙引號 " 括起來的任意文本,比如'abc',"xyz" 等等。
注意,'' 或 "" 本身只是一種表示方式,不是字符串的一部分,因此,字符串'abc' 只有 a,b,c 這 3 個字符。
如果' 本身也是一個字符,那就可以用 "" 括起,比如 `"I'm OK"`
如果字符串內部既包含' 又包含 " 怎么辦?可以用轉義字符 \ 來標識,比如
```python
'I\'m \"OK\"'
```
如果字符串里面有很多字符都需要轉義,就需要加很多 \,為了簡化,Python 還允許用 r'' 表示'' 內部的字符串默認不轉義
|轉義字符|描述|
|:--|:--|
|\(在行尾時)|續行符|
|\\|反斜杠符號|
|\',\"|引號|
|\n|換行|
|\r|回車|
|\oyy|八進制數,yy 代表的字符,例如:\o12 代表換行,其中 o 是字母,不是數字 0。|
|\xyy|十六進制數,yy 代表的字符,例如:\x0a 代表換行|
```python
print (r'\\\t\\')
```
如果有很多換行,可以使用 `'''...'''`表示多行內容
```python
print ('''line1
line2
line3''')
```
多行字符串'''...''' 還可以在前面加上 r 使用
### 字符串編碼
我們知道計算機只能處理數字,如果要處理文本,需要將文本轉換成數字。
最早的計算機在設計時采用 8 個比特(bit)作為一個字節(byte),所以,一個字節能表示的最大的整數就是 255(二進制 11111111 = 十進制 255),如果要表示更大的整數,就必須用更多的字節。
由于計算機是美國人發明的,因此,最早只有 127 個字符被編碼到計算機里,也就是大小寫英文字母、數字和一些符號,這個編碼表被稱為 ASCII 編碼,比如大寫字母 A 的編碼是 65,小寫字母 z 的編碼是 122。
但是要處理中文顯然一個字節是不夠的,至少需要兩個字節,而且還不能和 ASCII 編碼沖突,所以,中國制定了 GB2312 編碼,用來把中文編進去。
于是各國有各國的標準,不可避免的會出現沖突。
所以Unicode應運而生,可以將所有的語言統一到一套編碼。
那么ASCII 編碼和 Unicode 編碼的主要區別在于:ASCII 編碼是 1 個字節,而 Unicode 編碼通常是 2 個字節。
不過新的問題在于,如果統一成 Unicode 編碼,亂碼問題從此消失了。但是,如果你寫的文本基本上全部是英文的話,用 Unicode 編碼比 ASCII 編碼需要多一倍的存儲空間,在存儲和傳輸上就十分不劃算。
又出現了把 Unicode 編碼轉化為 “可變長編碼” 的 UTF-8 編碼。
UTF-8 編碼把一個 Unicode 字符根據不同的數字大小編碼成 1-6 個字節,常用的英文字母被編碼成 1 個字節,漢字通常是 3 個字節,只有很生僻的字符才會被編碼成 4-6 個字節。如果你要傳輸的文本包含大量英文字符,用 UTF-8 編碼就能節省空間:
|字符|ASCII|Unicode|UTF-8|
|:--|:--|:--|:--|
|A|1000001|00000000 01000001|1000001|
|中|x|01001110 00101101|11100100 10111000 10101101|
搞清楚了 ASCII、Unicode 和 UTF-8 的關系,我們就可以總結一下現在計算機系統通用的字符編碼工作方式:
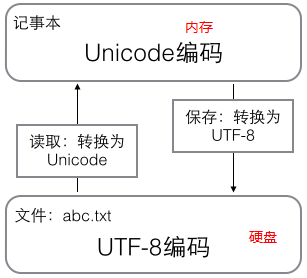
- 在計算機內存中,統一使用 Unicode 編碼,當需要保存到硬盤或者需要傳輸的時候,就轉換為 UTF-8 編碼。
- 用記事本編輯的時候,從文件讀取的 UTF-8 字符被轉換為 Unicode 字符到內存里,編輯完成后,保存的時候再把 Unicode 轉換為 UTF-8 保存到文件:
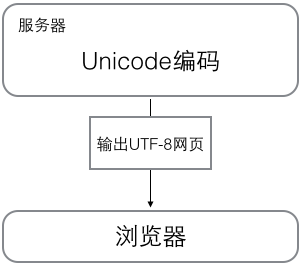
瀏覽網頁的時候,服務器會把動態生成的 Unicode 內容轉換為 UTF-8 再傳輸到瀏覽器:
### encode,decode
最新的 Python 3 版本中,字符串是以 Unicode 編碼的。
也就是說,Python 的字符串支持多語言,例如:
```python
>>> print('包含中文的str')
```
由于 Python 的字符串類型是 str,在內存中以 Unicode 表示,一個字符對應若干個字節。
如果要在網絡上傳輸,或者保存到磁盤上,就需要把 str 變為以**字節**為單位的 bytes。
Python 對 bytes 類型的數據用帶 b 前綴的單引號或雙引號表示,要注意區分'ABC' 和 b'ABC',前者是 str,后者雖然內容顯示得和前者一樣,但 bytes 的每個字符都只占用一個字節。
str可以通過 `encode()`編碼為指定的 `bytes`
比如
```python
'ABC'.encode('ascii')
'中文'.encode("utf-8")
```
> 含有中文的 str 無法用 ASCII 編碼,因為中文編碼的范圍超過了 ASCII 編碼的范圍,Python 會報錯。
如果我們從網絡或磁盤上讀取了字節流,那么讀到的數據就是 bytes。要把 bytes 變為 str,就需要用 decode() 方法
```python
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'
```
如果 bytes 中只有一小部分無效的字節,可以傳入 errors='ignore' 忽略錯誤的字節:
當 Python 解釋器讀取源代碼時,為了讓它按 UTF-8 編碼讀取,我們通常在文件開頭寫上這兩行:
```python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
```
### 格式化
一個常見的問題是如何輸出格式化的字符串
```python
>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
```
% 運算符就是用來格式化字符串的。在字符串內部,%s 表示用字符串替換,%d 表示用整數替換,有幾個 %? 占位符,后面就跟幾個變量或者值,順序要對應好。如果只有一個 %?,括號可以省略。
如果你不太確定應該用什么,%s 永遠起作用,它會把任何數據類型轉換為字符串
有些時候,字符串里面的 % 是一個普通字符怎么辦?這個時候就需要轉義,用 %% 來表示一個 %
另一種格式化字符串的方法是使用字符串的 format() 方法,它會用傳入的參數依次替換字符串內的占位符 {0}、{1}……,不過這種方式寫起來比 % 要麻煩得多:
```python
>>> 'Hello, {0}, 成績提升了 {1:.1f}%'.format('小明', 17.125)
'Hello, 小明, 成績提升了 17.1%'
```
### 索引和切片
Python 里面索引有三個特點
- 從 0 開始 ,不像 Matlab 從 1 開始。
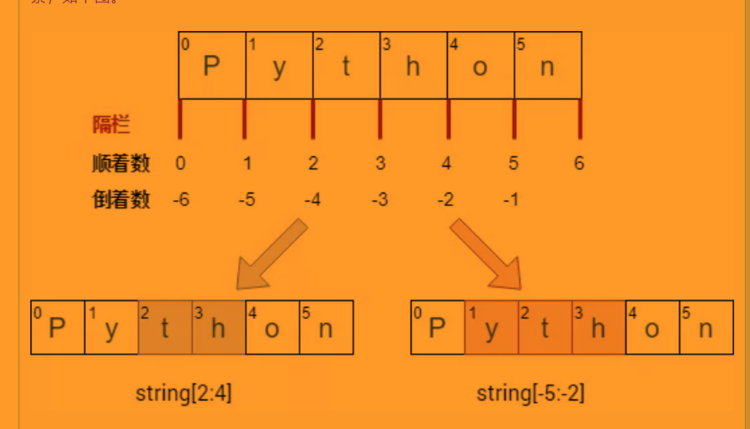
- 切片通常寫成 start:end 這種形式,包括「start 索引」對應的元素,但是不包括「end 索引」對應的元素。比如 s [2:4] 只獲取字符串第 3 個到第 4 個元素。
- 索引值可正可負,正索引從 0 開始,從左往右;負索引從 -1 開始,從右往左。使用負數索引的時候,會從最后一個元素開始計數,最后一個元素的位置編號是-1
技巧:可以想象將元素分開的隔欄,顯然 6 個元素需要 7 個隔欄,隔欄索引也是從 0 開始,這樣再看到 start:end 就認為是隔欄索引,那么獲取的元素就是「隔欄 start」和「隔欄 end」之間包含的元素。
- string [2:4] 就是「隔欄 2」和「隔欄 4」之間包含的元素,即 th
- string [-5:-2] 就是「隔欄 -5」和「隔欄 -2」之間包含的元素,即 yth
### 正則表達式
正則表達式 (regular expression) 主要用于識別字符串中符合某種模式的部分
```bash
input = """
'06/18/2019 13:00:00', 100, '1st';
'06/18/2019 13:30:00', 110, '2nd';
'06/18/2019 14:00:00', 120, '3rd'
"""
```
我們用下面這樣的模式
```bash
pattern = re.compile("'[0-9/:\s]+'")
```
里面符號的意思如下:
- 最外面的兩個單引號 ' 代表該模式以它們開始和結束
- 中括號 [] 用來概括該模式涵蓋的所有類型的字節
- 0-9 代表數字類的字節
- / 代表正斜線
- : 代表分號
- \s 代表空格
- [] 外面的加號 + 代表 [] 里面的字節出現至少 1 次
然后就可以把所有符合pattern的日期表達式都找出來
```bash
pattern.findall(input)
["'06/18/2019 13:00:00'",
"'06/18/2019 13:30:00'",
"'06/18/2019 14:00:00'"]
```
接下來就可以把 / 換成 -,或者用 datetime 里面的 striptime () 把日期里年、月、日、小時、分鐘和秒都獲取出來。
### 字符串運算符
|操作符|描述|實例|
|:--|:--|:--|
|+|字符串連接|a + b 輸出結果: HelloPython|
|*|重復輸出字符串|a*2 輸出結果:HelloHello|
|[ : ]|截取字符串中的一部分,遵循左閉右開原則,str [0,2] 是不包含第 3 個字符的。|a [1:4] 輸出結果 ell|
|in,not in|成員運算符|H' in a 輸出結果 True|
### 內建函數
#### len
要計算 str 包含多少個字符,可以用 len() 函數:
```python
>>> len('中文')
2
```
如果 len()里面傳入的是 `bytes`,將計算字節數
```python
>>> len('中文'.encode('utf-8'))
6
# 中文將被編碼為 b'\xe4\xb8\xad\xe6\x96\x87'
```
- capitalize ():大寫句首的字母
- split ():把句子分成單詞
- find (x):找到給定詞 x 在句中的索引,找不到返回 -1
- replace (x, y):把句中 x 替代成 y
- strip (x):刪除句首或句末含 x 的部分
比如說我們提取到字符類型的值之后,一般會使用 x.strip(" ")去除空格
|方法|描述|類型|實例|
|:--|:--|:--|:--|
|capitialize()|首字母大寫|替換||
|expandtabs(tabsize=8)|將tab轉為空格,默認空格數為8|替換||
|lower(),upper()|轉換為小寫|替換||
|replace(old, new [, max])|把 將字符串中的 str1 替換成 str2, 如果 max 指定,則替換不超過 max 次。|替換||
|count(str,beg=0,end=len(string))|返回str在string里面的次數,beg和end用于指定特定的范圍|判斷|str.count('run', 0, 10)|
|endswith(suffix,beg=0,end=(len(string))|檢查字符串是否以 obj 結束|判斷|Str.endswith(suffix, 0, 19)|
|isalnum(),isalpha(),isspace()|isalnum()表示至少有一個字符,并且所有字符都是字母或者數字,isalpha()表示至少有一個字符,并且所有字符都是字母|判斷||
|isdigit(),isnumeric(),isdecimal()|只包含數字或者數字字符,則返回True|判斷||
|islower(),isupper()|所有這些 (區分大小寫的) 字符都是小寫|判斷||
|lstrip(),rstrip()|截掉字符串左邊的空格或指定字符。|判斷||
|startswith(substr, beg=0,end=len(string))|檢查字符串是否是以指定子字符串 substr 開頭,|判斷||
|rfind(str, beg=0,end=len(string))|從右邊開找|查找||
|find(str,beg=0,end=(len(string))|檢測 str 是否包含在字符串中,若包含,則返回開始的索引值,否則返回-1|查找|str1.find(str2, 10)|
|index(str, beg=0, end=len(string))|跟 find () 方法一樣,但是如果 str 不在字符串中會報一個異常.|查找||
|max(str)|返回字符串 str 中最大的字母。|查找||
|swapcase()|將字符串中大寫轉換為小寫,小寫轉換為大寫|轉換||
|join(seq)|以指定字符串作為分隔符,將 seq 中所有的元素 合并|重組||
|split(str="", num=string.count(str))|num=string.count (str)) 以 str 為分隔符截取字符串,如果 num 有指定值,則僅截取 num+1 個子字符串|重組||
|splitlines([keepends])|按照行 ('\r', '\r\n', \n') 分隔,返回一個包含各行作為元素的列表,如果參數 keepends 為 False,不包含換行符,如果為 True,則保留換行符。|重組||
|bytes.decode(encoding="utf-8", errors="strict")|Python3 中沒有 decode 方法,但我們可以使用 bytes 對象的 decode () 方法來解碼給定的 bytes 對象,這個 bytes 對象可以由 str.encode () 來編碼返回。|編碼||
|encode(encoding='UTF-8',errors='strict')|以 encoding 指定的編碼格式編碼字符串|編碼||
## 變量
變量在程序中就是用一個變量名表示了,變量名必須是大小寫英文、數字和_的組合,且不能用數字開頭
在 Python 中,等號 = 是賦值語句,可以把任意數據類型賦值給變量,同一個變量可以反復賦值,而且可以是不同類型的變量
這種變量本身類型不固定的語言稱之為 **動態語言**,與之對應的是靜態語言。
當我們寫a = 'ABC'
Python的解釋器做了兩件事:
- 在內存中,創建 'ABC'字符串
- 在內存中創建了一個名為 `a`的變量,并指向 `'ABC'`
比如如下代碼
```python
a = 'ABC'
b = a
a = 'XYZ'
print(b)
```
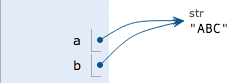
執行 a = 'ABC',解釋器創建了字符串'ABC' 和變量 a,并把 a 指向'ABC':

執行 b = a,解釋器創建了變量 b,并把 b 指向 a 指向的字符串'ABC':
?
執行 a = 'XYZ',解釋器創建了字符串 'XYZ',并把 a 的指向改為'XYZ',但 b 并沒有更改:
?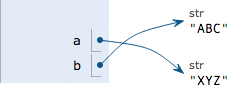
所以,最后打印變量 b 的結果自然是'ABC' 了。
## list
list是一種有序的集合,可以隨時添加和刪除其中的元素。
### 創建list
```python
classmates = ['Michael', 'Bob', 'Tracy']
```
list元素也可以是另外一個list
```python
s = ['python', 'java', ['asp', 'php'], 'scheme']
```
注意s只有4個元素,其中 `s[2]`又是一個list。
### 索引和切片
```python
classmates[-3]
```
L[0:3] 表示,從索引 0 開始取,直到索引 3 為止,但不包括索引 3。即索引 0,1,2,正好是 3 個元素。
如果第一個索引是 0,還可以省略
- 取前10個數: L[:10]
- 后10個數:L[-10:]
- 前11~20個數:L[10:20]
- 所有數每5個取一個:L[::5]
### 內置方法
- 追加: classmates.append('Adam')
- 插入到指定的位置: classmates.insert(1,'Jack')
- 刪除list末尾的元素:classmates.pop()
- 更新或者替換元素: classmates[1] = 'Sarah'
### 迭代
我們可以通過 `for`循環來遍歷list或者tuple
Python主要使用 `for ... in `來完成迭代,而Java是使用下標完成
所以Python的抽象程度高于java的for循環。
for循環不僅可以作用于list上,還可以用在其他可迭代的對象里面。
如果要實現類似于Java那樣的下標循環,可以使用 `enumerate`把一個list變成索引-元素對
```python
for i , value in enumerate (['A','B','C']):
print (i , value)
```
### 列表生成式
如果要生成從1 到10的列表可以使用
```python
list(range(1, 11))
```
如果要生成 [1x1, 2x2, 3x3, ..., 10x10] 怎么做?
```python
[x * x for x in range(1, 11)]
```
還可以加上 if 判斷,這樣我們就可以篩選出僅偶數的平方:
```python
>>> [x * x for x in range(1, 11) if x % 2 == 0]
[4, 16, 36, 64, 100]
```
還可以使用兩層循環,可以生成全排列:
```python
>>> [m + n for m in 'ABC' for n in 'XYZ']
['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']
```
還可以通過一行代碼列出當前目錄下的所有文件和目錄名
```python
import os
[d for d in os.listdir('.')]
```
把一個 list 中所有的字符串變成小寫:
```python
>>> L = ['Hello', 'World', 'IBM', 'Apple']
>>> [s.lower() for s in L]
```
### 生成器
通過列表生成式倒是可以直接創建一個列表,但是如果列表特別的大,需要占用的存儲空間自然非常多。
所以能不能讓列表元素通過某種算法推算出來。
在 Python 中,這種一邊循環一邊計算的機制,稱為生成器:generator。
要創建一個generator,第一種方法就是把一個列表生成式的 [] 改成 (),就創建了一個 generator
```python
g = (x*x for x in range(10))
```
那么如何把下一個返回值打印出來
```python
next (g)
```
generator 保存的是算法,每次調用 next(g),就計算出 g 的下一個元素的值,直到計算到最后一個元素,沒有更多的元素時,拋出 StopIteration 的錯誤。
其實正確的方法應該是通過 `for`循環,因為generator也是可迭代對象
```python
g = (x * x for x in range(10))
for n in g :
print (n)
```
比如Fibonacci數列,除第一個和第二個數外,任意一個數都可以由前兩個數相加得到
```python
def fib(max):
n , a , b = 0 , 0 , 1
while n < max:
print (b)
a , b = b , a + b
n = n + 1
return 'done'
```
注意,賦值語句:
a, b = b, a + b
相當于:
```python
t = (b, a + b) # t是一個tuple
a = t[0]
b = t[1
```
可以看出,fib 函數實際上是定義了斐波拉契數列的推算規則,可以從第一個元素開始,推算出后續任意的元素,這種邏輯其實非常類似 generator。
要把fib函數變成generator,只需要把 print(b)改為 yield b
```python
def fib (max):
n , a , b = 0 , 0 , 1
while n < max:
yield b
a , b = b , a + b
n = n + 1
return 'done'
```
如果一個函數定義中包含 yield 關鍵字,那么這個函數就不再是一個普通函數,而是一個 generator:
generator 和函數的執行流程不一樣。函數是順序執行,遇到 return 語句或者最后一行函數語句就返回。
而變成 generator 的函數,在每次調用 next() 的時候執行,遇到 yield 語句返回,再次執行時從上次返回的 yield 語句處繼續執行。
舉個簡單的例子,定義一個 generator,依次返回數字 1,3,5:
```python
def odd():
print('step 1')
yield 1
print('step 2')
yield(3)
print('step 3')
yield(5)
```
調用該generator時,首先要生成一個generator對象,然后用next()獲得下一個返回值
```python
o = odd()
next(o)
```
可以看到,odd 不是普通函數,而是 generator,在執行過程中,遇到 yield 就中斷,下次又繼續執行。執行 3 次 yield 后,已經沒有 yield 可以執行了,所以,第 4 次調用 next(o) 就報錯。
同樣的,把函數改成 generator 后,我們基本上從來不會用 next() 來獲取下一個返回值,而是直接使用 for 循環來迭代
## tuple
另外一種有序列表叫元組:tuple
tuple與list非常相似,但是tuple一旦初始化不能修改
```python
>>> classmates = ('Michael', 'Bob', 'Tracy')
```
不過tuple不能改變,所以沒有 append,insert這樣的方法
不可變的tuple有什么意義呢?
因為tuple不可變,所以代碼更安全。
需要注意的是,當定義一個tuple的時候,其元素就必須確定下來。
如果要定義只有一個元素的tuple需要
```python
t = (1,)
```
因為括號 () 既可以表示 tuple,又可以表示數學公式中的
如果tuple中有一個元素是列表,這個列表其實是可以賦值的,。
```python
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'
>>> t[2][1] = 'Y'
>>> t
('a', 'b', ['X', 'Y'])
```
如下是tuple包含的三個元素:
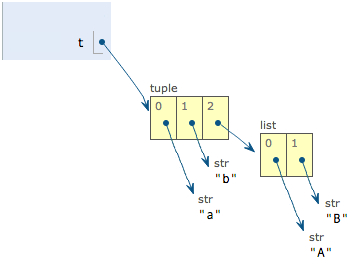
如果把 A和B修改為X和Y,tuple變為
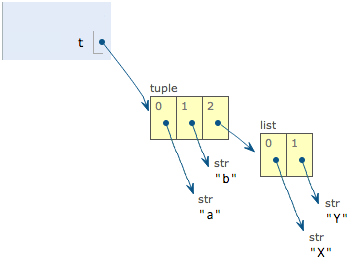
表面上看, tuple的元素確實變了,但是變的其實不是tuple的元素,而是list的元素。
所謂tuple不變,指的是tuple的每個元素,指向永遠的變。但是指向的這個list本身是可變的。
## dict
dict使用 key -value這種鍵值對進行存儲,查找速度極快。
為什么dict查找速度這么快?
假設我們正在查字典,如果要查某一個漢字,第一種方法是從第一頁往后面翻,直到找到,這就是list查找元素的方法。
第二種方法是建立一個索引表,查這個字對應的頁碼,然后直接翻到相應的頁數。
這樣無論是找哪一個字,速度都非常快,而且還不會隨著字典大小增加而增加。
dict就是采用的第二種方法,現在給定一個名字,就可以在內部算出這個名字對應的頁碼,也就是存放數值的內存地址。速度自然非常塊。
同樣,在放入數據的時候,也需要根據key算出value存放的位置。這樣才能根據key直接拿到value
### 創建dict
可以使用兩 種方法創建dict
- 初始化的時候指定
```python
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
```
- 通過key放入
```python
>>> d['Adam'] = 67
```
如果 key 不存在,dict 就會報錯,為了避免這個問題,可以使用 `in`來進行判斷
```python
'Thomas' in d
```
或者通過 dict 提供的 get() 方法
```python
d.get("Thomas")
```
如果不存在會返回None
> 注意:返回 None 的時候 Python 的交互環境不顯示結果。
### 刪除key
使用 `pop(key)`可以刪除key,對應的value也會刪除掉
### 注意
值得注意的是,dict內部存放的順序與key放入的順序沒有關系。
### 與list對比
和list相對比,dict具有如下特點
- 插入和查找的速度極快,而且不會隨著key增加而變慢
- 需要占用大量的內存,比較浪費
所以說dict是用空間來換時間的方法。
需要牢記一條就是dict的key必須是**不可變的對象**
因為dict需要根據key來算value存的地方,如果每次key不同,算出來的地址自然就亂了。
在 Python 中,字符串、整數等都是不可變的,
### 迭代
#### 迭代key
```python
>>> d = {'a': 1, 'b': 2, 'c': 3}
>>> for key in d:
... print(key)
...
a
c
b
```
因為 dict 的存儲不是按照 list 的方式順序排列,所以,迭代出的結果順序很可能不一樣。
#### 迭代 value
默認情況下,dict 迭代的是 key。如果要迭代 value,可以用 for value in d.values(),如果要同時迭代 key 和 value,可以用 for k, v in d.items()。
## set
set 和 dict 類似,也是一組 key 的集合,但不存儲 value。由于 key 不能重復,所以,在 set 中,沒有重復的 key。
### 創建
要創建一個set,需要提供一個list作為輸入集合
```python
s = set([1, 2, 3])
```
注意,傳入的參數 [1, 2, 3] 是一個 list,而顯示的 {1, 2, 3} 只是告訴你這個 set 內部有 1,2,3 這 3 個元素,顯示的順序也不表示 set 是有序的。。
重復元素在 set 中自動被過濾:
```js
>>> s = set([1, 1, 2, 2, 3, 3])
>>> s
{1, 2, 3}
```
### 添加刪除元素
通過 add(key) 方法可以添加元素到 set 中
通過 remove(key) 方法可以刪除元素:
set 可以看成數學意義上的無序和無重復元素的集合,因此,兩個 set 可以做數學意義上的交集、并集等操作:
```js
>>> s1 & s2
{2, 3}
>>> s1 | s2
{1, 2, 3, 4}
```
## 不可變對象
上面我們講了,str 是不變對象,而 list 是可變對象。
對于可變對象,比如 list,對 list 進行操作,list 內部的內容是會變化的
而對于不可變對象,比如 str,對 str 進行操作呢?雖然字符串有個 replace() 方法,也確實變出了'Abc',但變量 a 最后仍是'abc',應該怎么理解呢?
```js
>>> a = 'abc'
>>> b = a.replace('a', 'A')
>>> b
'Abc'
>>> a
'abc'
```
對象 a 的內容是'abc',但其實是指,a 本身是一個變量,它指向的對象的內容才是'abc'
當我們調用 a.replace('a', 'A') 時,實際上調用方法 replace 是作用在字符串對象'abc' 上的,而這個方法雖然名字叫 replace,但卻沒有改變字符串'abc' 的內容。
相反,replace 方法創建了一個新字符串'Abc' 并返回,如果我們用變量 b 指向該新字符串,就容易理解了,變量 a 仍指向原有的字符串'abc',但變量 b 卻指向新字符串'Abc' 了:
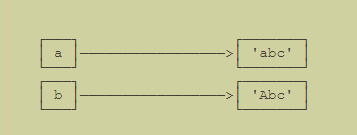
> 對于不變對象來說,調用對象自身的任意方法,**也不會**改變該對象自身的內容。相反,這些方法會**創建新的對象**并返回,這樣,就保證了不可變對象本身永遠是不可變的。
# 補充
## 可迭代對象
如何判斷一個對象是可迭代對象呢?方法是通過 collections 模塊的 Iterable 類型判斷:
```python
>>> from collections import Iterable
>>> isinstance('abc', Iterable) # str是否可迭代
True
>>> isinstance([1,2,3], Iterable) # list是否可迭代
True
>>> isinstance(123, Iterable) # 整數是否可迭代
False
```
如果要對 list 實現類似 Java 那樣的下標循環怎么辦?
Python 內置的 enumerate 函數可以把一個 list 變成索引 - 元素對,這樣就可以在 for 循環中同時迭代索引和元素本身:
```python
>>> for i, value in enumerate(['A', 'B', 'C']):
... print(i, value)
...
0 A
1 B
2 C
```
上面的 for 循環里,同時引用了兩個變量,在 Python 里是很常見的,比如下面的代碼:
```python
>>> for x, y in [(1, 1), (2, 4), (3, 9)]:
... print(x, y)
...
1 1
2 4
3 9
```
## 迭代器
可以直接作用于 for 循環的數據類型有以下幾種:
一類是集合數據類型,如 list、tuple、dict、set、str 等;
一類是 generator,包括生成器和帶 yield 的 generator function。
這些可以直接作用于 for 循環的對象統稱為可迭代對象:Iterable。
可以使用 isinstance() 判斷一個對象是否是 Iterable 對象:
```python
from collections import Iterable
isinstance ([], Iterable)
```
而生成器不但可以作用于 for 循環,還可以被 next() 函數不斷調用并返回下一個值,直到最后拋出 StopIteration 錯誤表示無法繼續返回下一個值了。
> 可以被 next() 函數調用并不斷返回下一個值的對象稱為迭代器:Iterator。
可以使用 isinstance() 判斷一個對象是否是 Iterator 對象:
```python
>>> from collections import Iterator
>>> isinstance((x for x in range(10)), Iterator)
True
>>> isinstance([], Iterator)
False
>>> isinstance({}, Iterator)
False
>>> isinstance('abc', Iterator)
False
```
list、dict、str 雖然是 Iterable,卻不是 Iterator。
生成器都是 Iterator對象
把 list、dict、str 等 Iterable 變成 Iterator 可以使用 iter() 函數
```python
>>> isinstance(iter([]), Iterator)
True
```
為什么 list、dict、str 等數據類型不是 Iterator?
這是因為 Python 的 Iterator 對象表示的是一個數據流,Iterator 對象可以被 next() 函數調用并不斷返回下一個數據,直到沒有數據時拋出 StopIteration 錯誤。
可以把這個數據流看做是一個有序序列,但我們卻不能提前知道序列的長度,只能不斷通過 next() 函數實現按需計算下一個數據,所以 Iterator 的計算是惰性的,只有在需要返回下一個數據時它才會計算。
Iterator 甚至可以表示一個無限大的數據流,例如全體自然數。而使用 list 是永遠不可能存儲全體自然數的。
凡是可作用于 for 循環的對象都是 Iterable 類型;
凡是可作用于 next() 函數的對象都是 Iterator 類型,它們表示一個惰性計算的序列;
集合數據類型如 list、dict、str 等是 Iterable 但不是 Iterator,不過可以通過 iter() 函數獲得一個 Iterator 對象。
Python 的 for 循環本質上就是通過不斷調用 next() 函數實現的,例如:
```python
for x in [1, 2, 3, 4, 5]:
pass
```
實際上完全等價于:
```python
# 首先獲得Iterator對象:
it = iter([1, 2, 3, 4, 5])
# 循環:
while True:
try:
# 獲得下一個值:
x = next(it)
except StopIteration:
# 遇到StopIteration就退出循環
break
```
