## **簡介:什么是Http超文本傳輸協議**
### 協議
* 協議是?種約定,規定好?種信息的格式,如果發送?按照這種請求格式發送信息,那么接 收端就要按照這樣的格式解析數據,這就是協議
* json協議
~~~
{ “name”:"jack", ? "age":23}
~~~
* xml協議
~~~
?<user>
<name> jack </name>
<age> 234 </age>
</user>?
~~~
* http超文本傳輸協議
### 什么是http協議
* 即超?本傳送協議(Hypertext Transfer Protocol ),是Web聯?的基礎,也是?機PC聯?常?的協議之?,HTTP協議是建?在TCP協議之上的?種應?
* HTTP連接最顯著的特點是客戶端發送的每次請求都需要服務器回送響應,從建?連接到關閉連接的過程稱為“?次連接”
* HTTP請求-HTTP響應
* 響應碼:
* 1xx:信息
* 2xx:成功 200 OK,請求正常
* 3xx:重定向
* 4xx:客戶端錯誤 404 Not Found 服務器?法找到被請求的??
* 5xx:服務器錯誤 503 Service Unavailable,服務器掛了或者不 可?
* 發展歷史
* http0.9-》http1.0-》http1.1-》http2.0
* 不多優化協議,增加更多功能
* 和https的關系
* Hyper Text Transfer Protocol over SecureSocket Layer
* 主要由兩部分組成:HTTP + SSL / TLS
* 比 HTTP 協議安全,可防止數據在傳輸過程中不被竊取、改變,確保數據的完整性,增加破解成本
* 缺點:相同網絡環境下,HTTPS 協議會使頁面的加載時間延長近 50%,增加額外的計算資源消耗,增加 10%到 20%的耗電等;不過利大于弊,所以Https是趨勢,相關資源損耗也在持續下降
* 如果做軟件壓測:直接壓測內網ip,通過壓測公網域名,不管是http還是https,都會帶來額外的損耗導致結果不準確
### 什么是URL(統?資源定位符,獲取服務器資源的一種)
* 標準格式: 協議://服務器IP:端?/路徑1/路徑N ? key1=value1 & key2=value2
* 協議:不同的協議有不同的解析?式
* 服務器ip: ?絡中存在?數的主機,要訪問的哪?臺, 通過公?ip區分
* 端?: ?臺主機上運?著很多的進程,為了區分不同進程,?個端?對應?個進程,http默認的端?是80
* 路徑: 資源N多種,為了更進?步區分資源所在的路徑(后端接?,?般稱為 “接?路徑”,“接?”)
### 超文本傳輸協議Http消息體拆分講解
* 請求協議
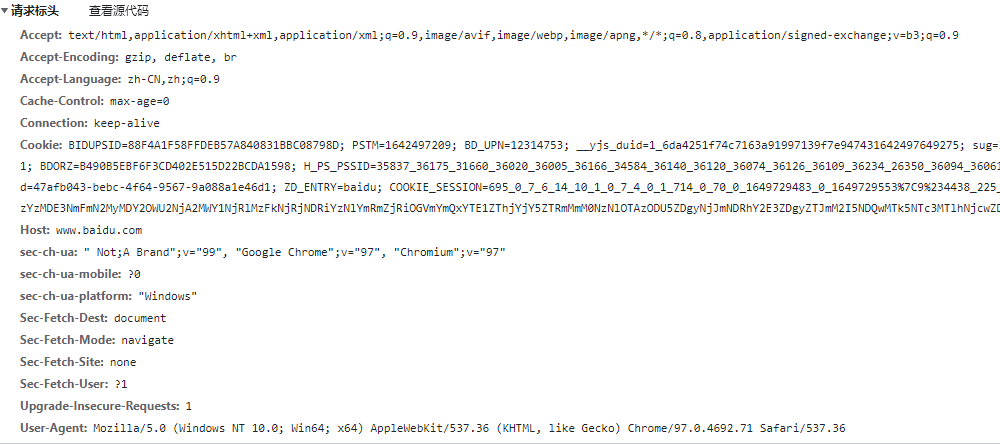
>[info] http請求分為三部分:請求行,請求頭, 請求體
* 請求頭
* 報文頭包含若干個屬性 格式為“屬性名:屬性值”,
* 服務端據此獲取客戶端的基本信息
* 常見的請求頭
* Accept: 覽器支持的 MIME 媒體類型, 比如 text/html,application/json,image/webp,*/*等
* Accept-Encoding: 瀏覽器發給服務器,聲明瀏覽器支持的編碼類型,gzip, deflate
* Accept-Language: 客戶端接受的語言格式,比如 zh-CN
* Connection: keep-alive , 開啟HTTP持久連接
* Host:服務器的域名
* Origin:告訴服務器請求從哪里發起的,僅包括協議和域名 CORS跨域請求中可以看到response有對應的header,Access-Control-Allow-Origin
* Referer:告訴服務器請求的原始資源的URI,其用于所有類型的請求,并且包括:協議+域名+查詢參數; 很多搶購服務會用這個做限制,必須通過某個入來進來才有效
* User-Agent: 服務器通過這個請求頭判斷用戶的軟件的應用類型、操作系統、軟件開發商以及版本號、瀏覽器內核信息等; 風控系統、反作弊系統、反爬蟲系統等基本會采集這類信息做參考
* Cookie: 表示服務端給客戶端傳的http請求狀態,也是多個key=value形式組合,比如登錄后的令牌等
* Content-Type: HTTP請求提交的內容類型,一般只有post提交時才需要設置,比如文件上傳,表單提交等
* 響應協議
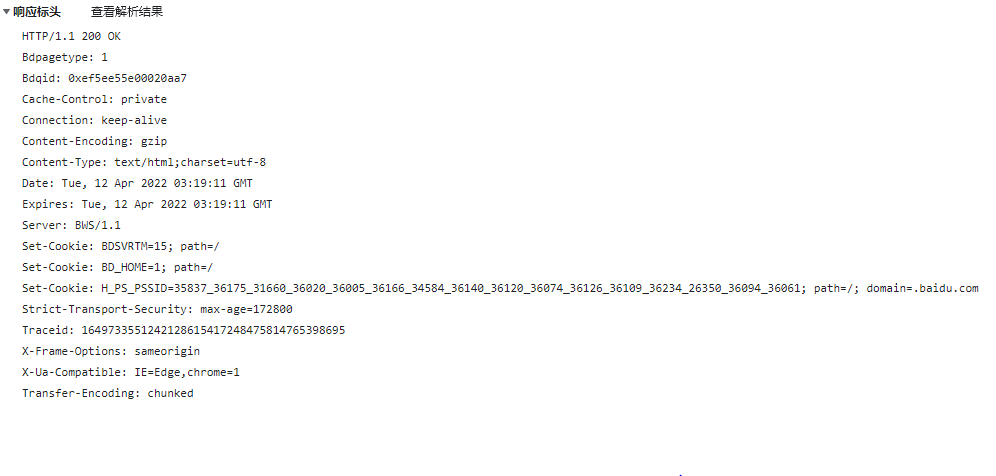
* Http響應消息結構
* 響應行
* 報文協議及版本、狀態碼
* 響應頭
* 報文頭包含若干個屬性 格式為“屬性名:屬性值”
* 響應正文
* 響應報文體,我們需要的內容,多種形式比如html、json、圖片、視頻文件等
* 響應頭
* 報文頭包含若干個屬性 格式為“屬性名:屬性值”
* 常見的響應頭
* Allow: 服務器支持哪些請求方法
* Content-Length: 響應體的字節長度
* Content-Type: 響應體的MIME類型
* Content-Encoding: 設置數據使用的編碼類型
* Date: 設置消息發送的日期和時間
* Expires: 設置響應體的過期時間,一個GMT時間,表示該緩存的有效時間
* cache-control: Expires的作用一致,都是指明當前資源的有效期, 控制瀏覽器是否直接從瀏覽器緩存取數據還是重新發請求到服務器取數據,優先級高于Expires,控制粒度更細,如max-age=240,即4分鐘
* Location:表示客戶應當到哪里去獲取資源,一般同時設置狀態代碼為3xx
* Server: 服務器名稱
* Transfer-Encoding:chunked 表示輸出的內容長度不能確定,靜態網頁一般沒,基本出現在動態網頁里面
* Access-Control-Allow-Origin: 定哪些站點可以參與跨站資源共享
**Http里面的content-type媒體類型講解**
* Content-type: 用來指定不同格式的請求響應信息,俗稱 MIME媒體類型
* 常見的取值
text/html :HTML格式 text/plain :純文本格式
text/xml : XML格式
image/gif :gif圖片格式 image/jpeg :jpg圖片格式 image/png:png圖片格式
application/json:JSON數據格式 application/pdf :pdf格式 application/octet-stream :二進制流數據,一般是文件下載
application/x-www-form-urlencoded:form表單默認的提交數據的格式,會編碼成key=value格式
multipart/form-data: 表單中需要上傳文件的文件格式類型
* Http知識加深文檔:[https://developer.mozilla.org/zh-CN/docs/Web/HTTP](https://developer.mozilla.org/zh-CN/docs/Web/HTTP)
### http常見的請求方法和使用
* http1.0定義了三種:
* GET: 向服務器獲取資源,比如常見的查詢請求
* POST: 向服務器提交數據而發送的請求
* Head: 和get類似,返回的響應中沒有具體的內容,用于獲取報頭
* http1.1定義了六種
* PUT:一般是用于更新請求,比如更新個人信息、商品信息全量更新
* PATCH:PUT 方法的補充,更新指定資源的部分數據
* DELETE:用于刪除指定的資源
* OPTIONS: 獲取服務器支持的HTTP請求方法,服務器性能、跨域檢查等
* CONNECT: 方法的作用就是把服務器作為跳板,讓服務器代替用戶去訪問其它網頁,之后把數據原原本本的返回給用戶,網頁開發基本不用這個方法,如果是http代理就會使用這個,讓服務器代理用戶去訪問其他網頁,類似中介
* TRACE:回顯服務器收到的請求,主要用于測試或診斷
## Http常見的響應狀態碼講解
* 瀏覽器向服務器請求時,服務端響應的消息頭里面有狀態碼,表示請求結果的狀態
* 分類
* 1XX: 收到請求,需要請求者繼續執行操作,比較少用
* 2XX: 請求成功,常用的 200
* 3XX: 重定向,瀏覽器在拿到服務器返回的這個狀態碼后會自動跳轉到一個新的URL地址,這個地址可以從響應的Location首部中獲取;
* 好處:網站改版、域名遷移等,多個域名指向同個主站導流
* 必須記住: 301:永久性跳轉,比如域名過期,換個域名 302:臨時性跳轉
* 4XX: 客服端出錯,請求包含語法錯誤或者無法完成請求
* 必須記住: 400: 請求出錯,比如語法協議 403: 沒權限訪問 404: 找不到這個路徑對應的接口或者文件 405: 不允許此方法進行提交,Method not allowed,比如接口一定要POST方式,而你是用了GET
* 5XX: 服務端出錯,服務器在處理請求的過程中發生了錯誤
* 必須記住: 500: 服務器內部報錯了,完成不了這次請求 503: 服務器宕機
