## **簡介**
Laravel 為我們提供了多種工具實現對數據庫的增刪改查,在我們使用 Laravel 提供的這些數據庫工具之前,首先要連接到數據庫。
## **數據庫連接配置**
數據庫的連接配置文件位于`config/database.php`,默認情況下,Laravel為支持的每一種數據庫都定義了一個連接配置項,你自行決定將哪個「連接」作為默認連接:
~~~
'connections' => [
'sqlite' => [
'driver' => 'sqlite',
'url' => env('DATABASE_URL'),
'database' => env('DB_DATABASE', database_path('database.sqlite')),
'prefix' => '',
'foreign_key_constraints' => env('DB_FOREIGN_KEYS', true),
],
'mysql' => [
'driver' => 'mysql',
'url' => env('DATABASE_URL'),
'host' => env('DB_HOST', '127.0.0.1'),
'port' => env('DB_PORT', '3306'),
'database' => env('DB_DATABASE', 'forge'),
'username' => env('DB_USERNAME', 'forge'),
'password' => env('DB_PASSWORD', ''),
'unix_socket' => env('DB_SOCKET', ''),
'charset' => 'utf8mb4',
'collation' => 'utf8mb4_unicode_ci',
'prefix' => '',
'prefix_indexes' => true,
'strict' => true,
'engine' => null,
'options' => extension_loaded('pdo_mysql') ? array_filter([
PDO::MYSQL_ATTR_SSL_CA => env('MYSQL_ATTR_SSL_CA'),
]) : [],
],
'pgsql' => [
'driver' => 'pgsql',
'url' => env('DATABASE_URL'),
'host' => env('DB_HOST', '127.0.0.1'),
'port' => env('DB_PORT', '5432'),
'database' => env('DB_DATABASE', 'forge'),
'username' => env('DB_USERNAME', 'forge'),
'password' => env('DB_PASSWORD', ''),
'charset' => 'utf8',
'prefix' => '',
'prefix_indexes' => true,
'schema' => 'public',
'sslmode' => 'prefer',
],
'sqlsrv' => [
'driver' => 'sqlsrv',
'url' => env('DATABASE_URL'),
'host' => env('DB_HOST', 'localhost'),
'port' => env('DB_PORT', '1433'),
'database' => env('DB_DATABASE', 'forge'),
'username' => env('DB_USERNAME', 'forge'),
'password' => env('DB_PASSWORD', ''),
'charset' => 'utf8',
'prefix' => '',
'prefix_indexes' => true,
],
],
~~~
這里包括了 SQLite、MySQL、PostgresSQL、SQL Server,一般我們默認使用的都是 MySQL:
~~~
'default' => env('DB_CONNECTION', 'mysql'),
~~~
當然默認數據庫連接、數據庫名稱以及數據庫用戶名和密碼等敏感信息都保存到`.env`文件中了,我們平時修改數據庫連接信息的話修改這里就好了。
### **配置多個數據連接**
有時候,我們的應用用到的不止一個數據庫,或者做項目遷移的時候要做新老數據庫之間的數據遷移,這個時候我們就可以配置多個數據庫連接,如果我們的新老數據庫使用的都是 MySQL 的話,可以在`config/database.php`的`connections`配置項中新增一個 MySQL 連接:
~~~
'mysql_old' => [
'driver' => 'mysql',
'host' => env('DB_HOST_OLD', '127.0.0.1'),
'port' => env('DB_PORT_OLD', '3306'),
'database' => env('DB_DATABASE_OLD', 'forge'),
'username' => env('DB_USERNAME_OLD', 'forge'),
'password' => env('DB_PASSWORD_OLD', ''),
'unix_socket' => env('DB_SOCKET_OLD', ''),
'charset' => 'utf8mb4',
'collation' => 'utf8mb4_unicode_ci',
'prefix' => '',
'strict' => true,
'engine' => null,
],
~~~
然后在`.env`中新增對應配置項:
~~~
DB_CONNECTION_OLD=mysql
DB_HOST_OLD=mysql
DB_PORT_OLD=3306
DB_DATABASE_OLD=laravel56
DB_USERNAME_OLD=root
DB_PASSWORD_OLD=root
~~~
接下來,我們要怎樣連上這個實例呢?默認情況下,我們通過Laravel提供的數據庫工具(DB 門面、查詢構建器、Eloquent模型)連接數據庫的時候,都沒有顯式指定連接,因為我們在配置文件中指定了默認的連接因為我們在配置文件中指定了默認的連接`mysql`。所以要連接上其它連接很簡單,在查詢的時候指定這個新的連接就好了,如果你使用的是`DB`門面執行原生 SQL 查詢,可以這么連接老的數據庫:
~~~
$users = DB::connection('mysql_old')->select(...);
DB::connection('mysql_old')->insert(...);
~~~
如果你使用的 Eloquent 模型類,可以在對應模型類中設置`$connection`屬性:
~~~
protected $connection = 'mysql_old';
~~~
這樣,在模型類上執行查詢、插入等操作時都會使用這個`mysql_old`數據庫連接。
### **配置數據庫讀寫分離連接**
隨著應用訪問量的增長,對數據庫進行讀寫分離可以有效的提升應用整體性能,Laravel也對此進行了單獨支持(僅討論從應用層面如何在 Laravel 項目中配置讀寫分離連接)。Laravel 框架數據庫底層代碼對數據庫讀寫分離進行了支持,所以我們需要遵循底層實現進行讀寫分離配置:
~~~
'mysql' => [
'driver' => 'mysql',
'read' => [
'host' => env('DB_HOST_READ', '127.0.0.1'),
//當讀寫數據庫的用戶名、密碼等不一樣時,將username、password等對應字 段移至此處即可
],
'write' => [
'host' => env('DB_HOST_WRITE', '127.0.0.1'),
],
'port' => env('DB_PORT', '3306'),
'database' => env('DB_DATABASE', 'forge'),
'username' => env('DB_USERNAME', 'forge'),
'password' => env('DB_PASSWORD', ''),
'unix_socket' => env('DB_SOCKET', ''),
'charset' => 'utf8mb4',
'collation' => 'utf8mb4_unicode_ci',
'prefix' => '',
'strict' => true,
'engine' => null,
],
~~~
`read`項配置的是「讀」連接,`write`項配置的是「寫」連接。然后在`.env`中新增`DB_HOST_READ`和`DB_HOST_WRITE`配置項。當然,對于 Web 應用而言,大多是讀多寫少,所以你還可以配置多個`read`主機,Laravel 底層的負載均衡機制是隨機從配置的 IP 中挑一個連接:
~~~
'read' => [
'host' => [env('DB_HOST_READ_1'), env('DB_HOST_READ_2')],
],
~~~
針對讀寫分離數據庫的連接,Laravel 數據庫底層會自動判斷,如果是查詢語句會使用讀連接,如果是數據庫插入、更新、刪除等操作會使用寫連接。
#### **讀寫分離配置中的`sticky`配置項**
在讀寫分離配置中,我們注意到新增了一個`sticky`配置項,這個是用來干嘛的呢?
我們配置數據庫讀寫分離的時候,會配置讀數據庫(從庫)從寫數據庫(主庫)同步數據,由于不同主機之間數據同步是需要時間的,雖然這個時間很短,但是對于并發量很大的應用,還是可能出現寫入寫數據庫的數據不能立即從讀數據庫讀取到的情況,`sticky`配置項在這個時候就派上用場了。如果該配置項設置為`true`的話,在同一個請求生命周期中,寫入的數據會被立刻讀取到,底層原理其實就是讀操作也從寫數據庫讀取,因為寫數據庫始終是最新數據,從而避免主從同步延遲導致的數據不一致。
## **通過遷移文件定義數據表結構**
在諸如 Laravel 這種現代框架中,數據表的每次變動(創建、修改、刪除)都對應一個遷移文件。這些遷移文件位于`database/migrations`目錄下,以日期時間為條件確定執行的先后順序。每個遷移文件中包含一個遷移類,這個遷移類有兩部分組成:負責執行數據庫遷移的`up`方法,以及負責回滾此次遷移的`down`方法。以 Laravel 自帶的`users`表遷移文件為例,代碼如下所示:
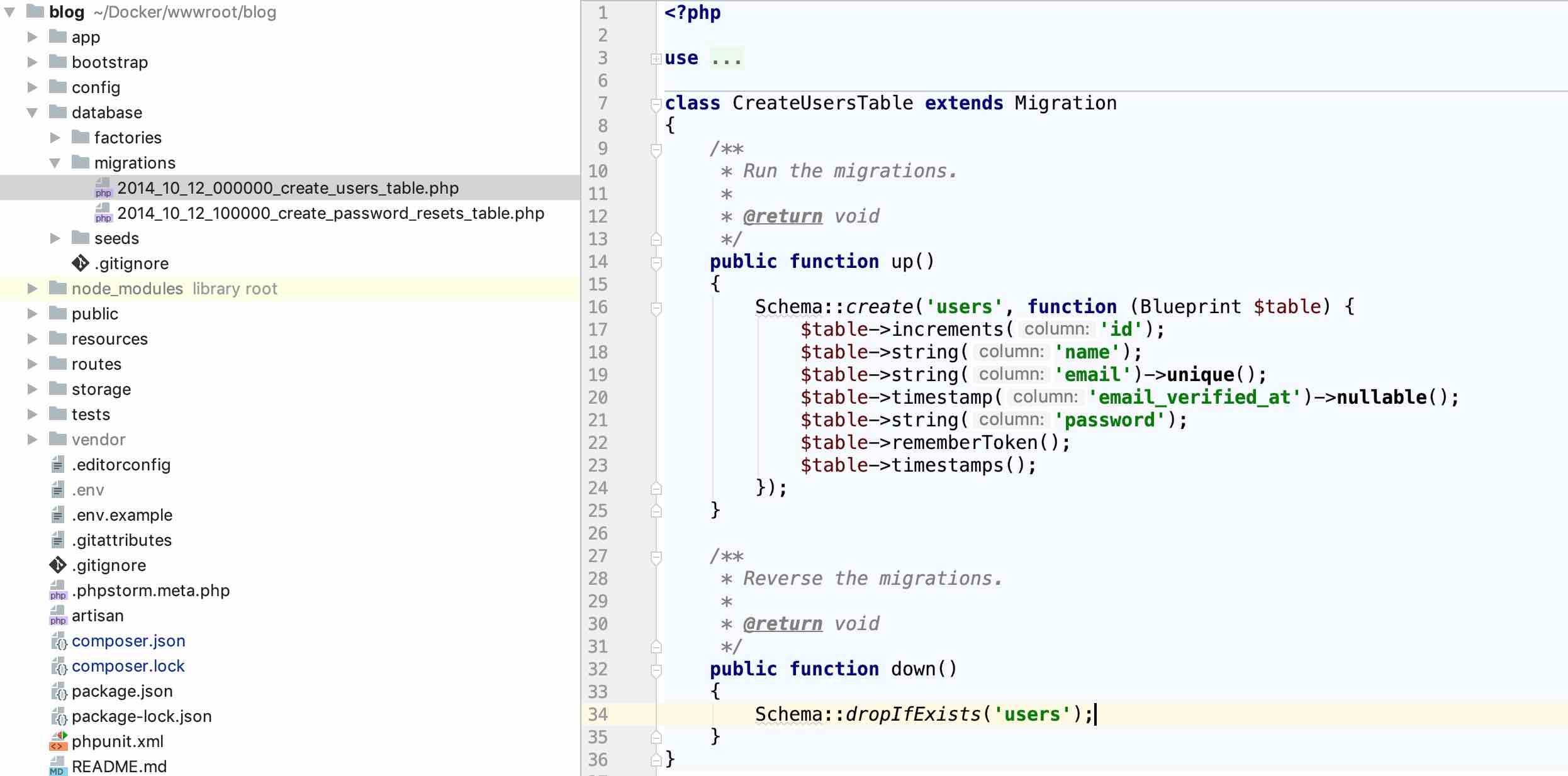
當我們遷移數據庫時,系統獲取所有數據庫遷移文件(包括`database/migrations`目錄下和擴展包中注冊的),然后按照文件名中包含的日期時間排序,從最早的遷移文件開始,依次執行每個遷移類中的`up`方法,最后完成數據庫遷移;反之,當我們回滾數據庫時,按照日期時間排序,從最晚的遷移文件開始,依次執行每個遷移類的`down`方法,最后完成數據庫回滾,如果指定回滾其中某幾步的話,回滾到對應的遷移文件即終止。
### **創建遷移文件**
Laravel 提供了一個 Artisan 命令`make:migration`幫助我們快速生成數據庫遷移文件,該命名包含一個參數,就是要創建的遷移的名稱,比如要創建`users`表對應遷移文件,可以通過`php artisan make:migration create_users_table`命令來完成。
此外,這個 Artisan 命令還支持兩個可選的選項,`--create=`用于指定要創建的數據表名稱,以及`--table=`用于指定要修改的數據表名稱,前者在定義創建數據表遷移文件時使用,后者在定義更新數據表遷移文件時使用,比如我們還是以`users`表為例:
~~~
php artisan make:migration create_users_table --create=users #創建數據表遷移
php artisan make:migration alter_users_add_nickname --table=users # 更新數據表遷移
~~~
有了遷移文件后,就可以在遷移文件對應遷移類的`up`方法中編寫創建數據表的邏輯了,以`create_users_table`遷移為例:
~~~
public function up()
{
Schema::create('users', function (Blueprint $table) {
$table->increments('id');
$table->string('name');
$table->string('email')->unique();
$table->timestamp('email_verified_at')->nullable();
$table->string('password');
$table->rememberToken();
$table->timestamps();
});
}
~~~
我們對數據庫的遷移操作都是基于`Schema`門面來完成(底層對應的類是`Illuminate\Database\Schema\Builder`),比如創建數據表,需要調用該門面的`create`方法,該方法的第一個參數是要創建的數據表的名稱,第二個參數是一個閉包,其中定義的是新增數據表的所有字段信息。
### **運行遷移**
接下來,我們來運行上面定義的遷移文件執行數據庫變更,常見的操作有兩種:執行變更和回滾變更。
執行變更很簡單,通過`php artisan migrate `就可以按照遷移文件生成時間的先后順序依次執行所有的數據庫遷移。
回滾要稍微復雜點,Laravel 支持多種形式的回滾,如果只回滾最后一個遷移文件的變更,可以通過:`php artisan migrate:rollback`來實現,如果要回滾多個遷移文件的變更,可以通過`--step=`指定步數(按照遷移文件生成時間逆序執行):
~~~
php artisan migrate:rollback --step=5
~~~
如果是要回滾所有遷移文件的變更,將數據庫恢復到初始狀態,需要運行以下命令:
~~~
php artisan migrate:reset
~~~
## **通過填充器快速填充測試數據**
在Laravel框架中,我們可以借助其提供的填充器功能非常方便地為不同數據表快速填充測試數據。
### **填充器的運行**
在應用根目錄的`database/seeds`目錄下,默認包含一個`DatabaseSeeder.php`文件。這就是 Laravel 自帶的一個填充器示例文件,該填充器類提供了一個`run`方法,當我們運行填充命令時,就會調用該方法執行數據庫填充。
Laravel 提供了兩種方式來運行填充器:
- 獨立的填充命令:
~~~
//以`DatabaseSeeder`為入口類,調用該類的`run`方法,你可以將所有對其他填充器的調用定義在該方法中
php artisan db:seed
//通過`--class=`選項指定運行某個填充器類的`run`方法
php artisan db:seed --class=UsersTableSeeder
~~~
- 在運行遷移命令時通過指定標識選項在創建數據表時填充(尤其是在初始化一些演示項目的時候):
~~~
//執行遷移命令時運行填充器類`DatabaseSeeder`填充數據
php artisan migrate --seed
//回滾所有遷移并重新運行遷移同時填充初始化數據
php artisan migrate:refresh --seed
~~~
### **編寫填充器類**
知道了如何運行填充器,是時候來編寫第一個填充器類了。我們可以通過如下 Artisan 命令為`users`表快速創建一個填充器類`UsersTableSeeder`:
~~~
php artisan make:seeder UsersTableSeeder
~~~
該命令會在`database/seeds`目錄下創建一個`UsersTableSeeder`填充器類,
我們可以將填充邏輯編寫到`run`方法里:
~~~
public function run()
{
DB::table('users')->insert([
'name' => str_random(10),
'email' => str_random(10).'@gmail.com',
'password' => bcrypt('secret'),
]);
}
~~~
這里我們借助了查詢構建器來插入數據,指定用戶名和郵箱為長度不大于10的隨機字符串,郵箱后綴是`@gmail.com`,密碼是對`secret`字符串進行加密后的字符串。接下來,我們可以通過指定填充器類的方式將這條記錄插入到數據庫:
~~~
php artisan db:seed --class=UsersTableSeeder
~~~
當然,你還可以在`DatabaseSeeder`類的`run`方法中運行這個填充器類:
~~~
public function run()
{
$this->call(UsersTableSeeder::class);
}
~~~
如果有多個填充器類,想要一次性運行,可以將它們都放到這個方法中調用。
### **通過模型工廠填充數據**
以上編寫填充器類填充數據到數據庫雖然已經很方便了,但是每次插入一條記錄都要編寫一條語句或者手動指定插入數據,如果需要填充的測試數據有成千上萬條,那不是要崩潰掉。有沒有一種機制可以一次定義填充規則,在每次具體運行時自行決定填充多少條記錄呢?模型工廠的概念應運而生:我們在一個 Eloquent 模型類(后續學習)上定義一個工廠方法,通過指定規則批量插入填充數據。
模型工廠位于`database/factories`目錄下,Laravel 自帶了一個用于填充`User`模型的模型工廠`UserFactory.php`:
~~~
<?php
use Faker\Generator as Faker;
/*
|--------------------------------------------------------------------------
| Model Factories
|--------------------------------------------------------------------------
|
| This directory should contain each of the model factory definitions for
| your application. Factories provide a convenient way to generate new
| model instances for testing / seeding your application's database.
|
*/
$factory->define(App\User::class, function (Faker $faker) {
return [
'name' => $faker->name,
'email' => $faker->unique()->safeEmail,
'email_verified_at' => now(),
'password' => '$2y$10$TKh8H1.PfQx37YgCzwiKb.KjNyWgaHb9cbcoQgdIVFlYg7B77UdFm', // secret
'remember_token' => str_random(10),
];
});
~~~
在模型工廠文件中,我們通過`$factory->define`方法來定義`User`模型的模型工廠,該方法的第一個參數是模型類,第二個參數是一個匿名函數,在該匿名函數中我們通過[Faker](https://github.com/fzaninotto/Faker)類庫提供的方法來定義字段規則,Faker 類庫提供了豐富的字段規則幫助我們生成偽造字段值,這些規則可以在[官方文檔](https://github.com/fzaninotto/Faker)中查看,這里,我們使用`$faker->name`生成用戶名,`$faker->unique()->safeEmail`生成唯一的郵箱地址,最后再將這些字段模型返回。
#### **調用模型工廠**
在調用這些模型工廠的時候,需要借助 Laravel 提供的全局輔助函數`factory()`,比如我們在`UsersTableSeeder`的`run`方法中通過模型工廠改寫數據填充方法:
~~~
public function run()
{
/*DB::table('users')->insert([
'name' => str_random(10),
'email' => str_random(10).'@gmail.com',
'password' => bcrypt('secret'),
]);*/
factory(\App\User::class, 5)->create();
}
~~~
由于我們在`UserFactory.php`中全局定義了`User`模型的模型工廠,所以在這里只需調用`factory(...)->create()`方法,傳入對應模型類和要填充的記錄數即可,當然,最后還是通過運行`php artisan db:seed`命令來填充數據到數據庫。
