# ElasticSearch基本概念
結合官網資料,做了更詳細的實際使用總結。
從單機版安裝到集群高可用生產環境搭建、基本概念(索引,分片,節點,倒排索引…)、DSL語法實踐、分詞器(內置+中文)、SpringBoot整合實戰。
## 1.簡介
Elasticsearch是一個基于Lucene的搜索服務器。提供了一個分布式多用戶能力的全文搜索引擎
* 基于Restful web接口。
* Java語言開發的
Elasticsearch的功能
* 分布式的文檔存儲引擎
* 分布式的搜索引擎和分析引擎
* 分布式,支持PB級數據
* 全文檢索,結構化檢索,數據分析
* 對海量數據進行近實時的處理
相關網站:
* 官網:[傳送門](https://www.elastic.co/)
* 官網文檔:[傳送門](https://www.elastic.co/guide/index.html)
* 中文手冊:[傳送門](https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html)
* 中文社區:[傳送門](https://elasticsearch.cn/)
* Jave-Client :[傳送門](https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.x/java-rest-high-create-index.html)
## 2.索引(Index)
索引是文檔(Document)的容器,可以理解為是文檔的集合。
* 索引相當于SQL中的一個數據庫(Database)
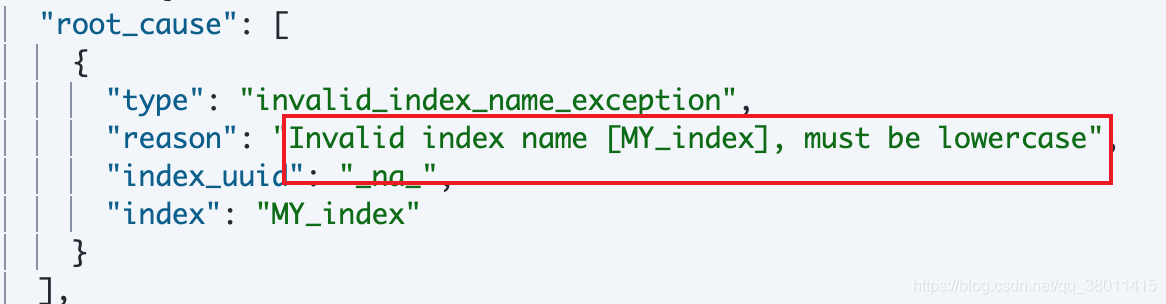
* 必須為全小寫字符
* 一個索引可以有多個文檔(Document)
下圖是包含大寫報錯提示
## 3.類型(Type)
* 類似為關系數據庫中Table
* 每個索引下可以建立多個類型,文檔存儲時需要指定index和type。
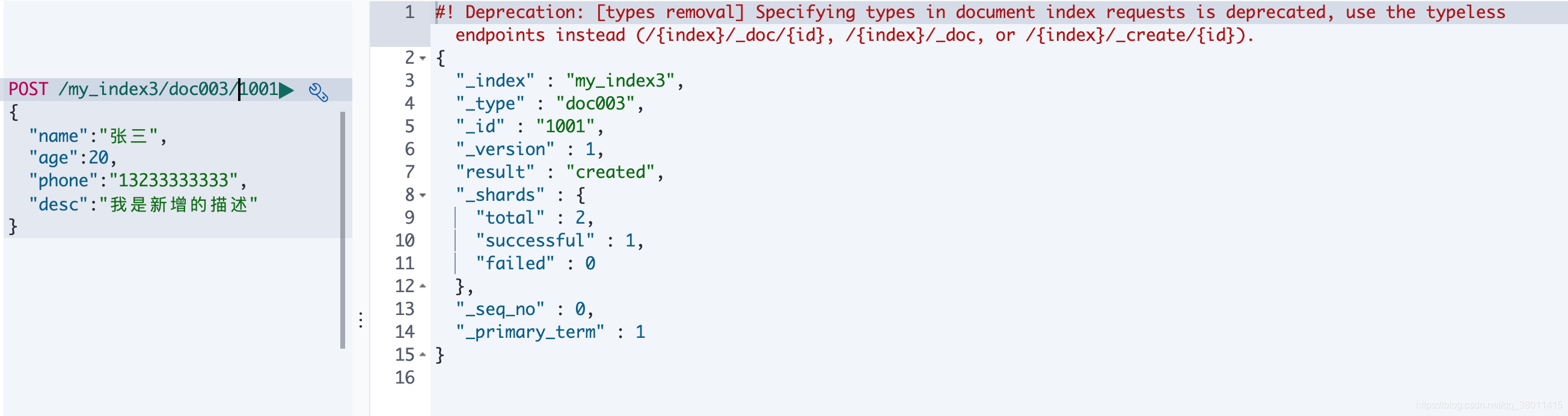
* 從6.0.0開始單個索引中只能有一個類型,7.0.0以后將將不建議使用,8.0.0 以后完全不支持。
下圖示例在7.x版本中創建一個有type
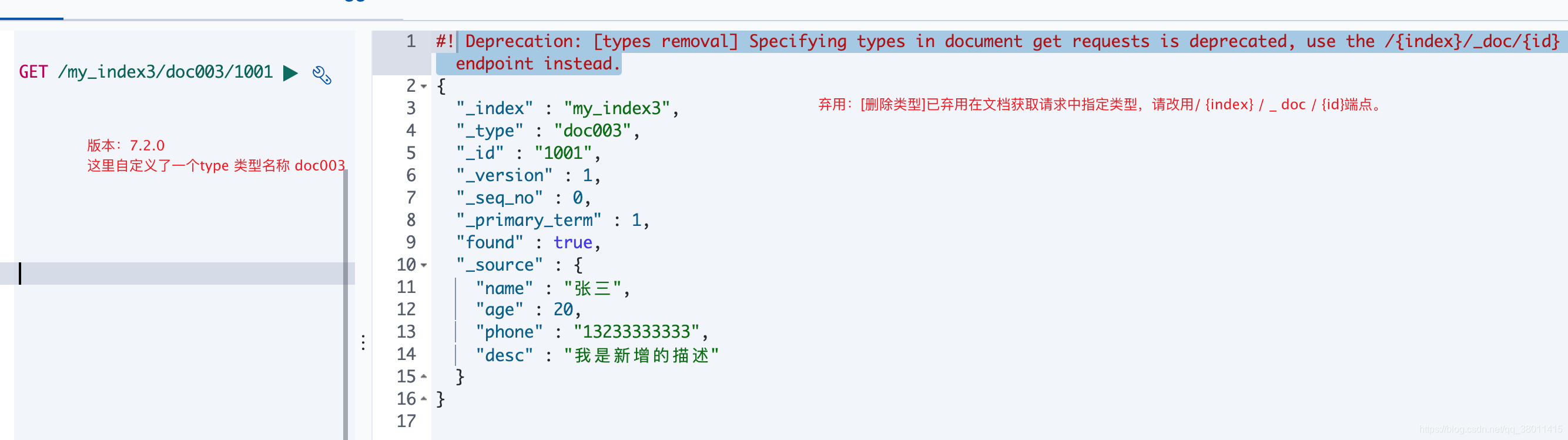
返回的錯誤提示大概含義是:
棄用:\[刪除類型\]不建議在文檔索引請求中指定類型,請改用無類型端點
(/ {index} / \_ doc / {id},/ {index} / \_ doc或/ {index} / \_ create / {id} )。
查詢的時候也會給提示
##### 棄用type原因:
一般把Index比作 SQL 的 Database,Type比作SQL的Table。
但這并不準確,因為如果在SQL中,Table 之前相互獨立,同名的字段在兩個表中毫無關系。
在ES中,同一個Index 下不同的 Type 如果有同名的字段,會被 Luecence 當作同一個字段 ,并且他們的定義必須相同。所以我覺得Index現在更像一個表,而Type字段并沒有多少意義。
目前Type已經被Deprecated,在7.0開始,一個索引只能建一個Type為`_doc`
## 4.文檔(Document)
索引Index里面單條的記錄稱為Document,等同于關系型數據庫表中的行。

*參數說明*
| **參數** | **含義** |
| --- | --- |
| \_index | 文檔所屬索引名稱 |
| \_type | 文檔所屬類型名 |
| \_id | 主鍵ID,可指定該值,若不指定則自動生成一個唯一的UUID |
| \_version | 文檔的版本信息,通過使用version來保證對文檔的變更能以正確的順序執行,避免亂序造成的數據丟失。 |
| \_seq\_no | 嚴格遞增的順序號,每個文檔一個Shard級別嚴格遞增,保證后寫入的Doc的\_seq\_no大于先寫入的Doc的\_seq\_no。可以理解為數據版本,可以用來控制并發修改 |
| \_primary\_term | 與\_seq\_no一樣是一個整數,每當Primary Shard發生重新分配時,比如重啟,Primary選舉等,\_primary\_term會遞增1 |
| found | 查到數據則為true, 查不到則為false |
| \_source | 文檔的原始JSON數據,存入的數據JSON化 |
## 5.分片(shard)
**為了解決什么?**
* 單臺機器即使存儲再大,達到一定程度后也會遇到瓶頸。分片(shard)是為了解決節點容量上限問題。
* 讓搜索和分析等操作分布到多臺服務器上執行,提升吞吐量和性能。
**如何解決?**
* ElasticSearch可以將一個索引中的數據切分為多個分片(shard),分布到多臺服務器上。
* 通過將index分為多個分片(默認是一個,也就是不分片)。
* 一個或多個node共同存儲該index的所有數據實現水平拓展(類似于關系型數據庫中的分表)
* 它們共同持有該索引的所有數據,默認通過hash(文檔id)決定數據的歸屬
索引分片(Sharding)是自動完成的,而且所有分片索引(Shard)是作為一個整體呈現給用戶的。
需要注意的是,盡管索引分片這個過程是自動的,但是在應用中需要事先調整好參數。因為集群中分片的數量需要在索引創建前配置好,而且服務器啟動后是無法修改的。
## 6.分片副本(replicas)
**存在的目的**
* **服務高可用**
* 若數據只有一份,若正好node節點掛了,那存在上面的數據就丟了。有了副本只要不是都掛了數據就不會丟
* 分片副本-不會與主分片在同一個節點上
* **提高吞吐量**
* 通過在多個replicas上并行搜索提高搜索性能,replicas上的數據都是近實時的(near realtime),因此所有replicas都能提供搜索功能,通過設置合理的replicas數量可以極高的提高搜索吞吐量
注:如果設置了replicas=2,那么一條數據共有三份,一份primary shard主分片,另外兩份replicas shard幅分片。這三個統一稱為副本組。
索引副本(Replica)機制的的思路很簡單:
* 為索引分片創建一份新的拷貝,支持像原來的主分片一樣處理用戶搜索請求。多節點備份也防止了數據的丟失,
* 索引副本可以隨時添加或者刪除,所以用戶也可以在需要的時候動態調整其數量,盡量提前預設好。防止擴充數據量越大的時候引起CPU負載過高。
## 7.分片設定
**前置設定很重要**
* 對于生產環境中分片的設定,需要提前做好容量規劃,
* 主分片數是在索引創建時預先設定的,后續無法修改。
**分片數設置過小問題**
* 導致后續無法增加節點進行水平擴展。
* 導致分片的數據量太大,數據在重新分配時耗時;
**分片數設置過大問題**
* 影響搜索結果的相關性打分,影響統計結果的準確性;
* 單個節點上過多的分片,會導致資源浪費,同時也會影響性能;
最大節點數建議公式
~~~bash
Max number of nodes = Number of shards * (number of replicas +1)
~~~
例如:如果你計劃用10個分片和2個分片副本,那么最大的節點數是30。
## 8.倒排索引
**ElasticSearch**的搜索功能是基于[lucene](https://so.csdn.net/so/search?q=lucene&spm=1001.2101.3001.7020)。
lucene搜索的基本原理就是倒敘索引,倒序排序的結果跟分詞的類型有關。
在**ElasticSearch**中,每個文檔都有一個對應的文檔 ID,文檔內容被表示為一系列關鍵詞的集合。
**例如:**
某文檔經過分詞,提取了 n 個關鍵詞,每個關鍵詞都會記錄它在文檔中出現的次數和出現位置。
**倒排索引:**
就是關鍵詞到文檔 ID 的映射,每個關鍵詞都對應著一系列的文件,這些文件中都出現了關鍵詞。
**案例:**
有如下3個文檔
| **文檔ID** | **文檔內容** |
| --- | --- |
| 1 | 我是張三 |
| 2 | 張三的成績單 |
| 3 | 張三的午餐 |
對文檔進行分詞后,得到倒排索引
注意:以下示例未嚴格按照字典順序排列,不同的分詞器,可能分的結果不一致,僅做示例參考
| **單詞ID** | **單詞內容(拆分的詞語)** | **文檔ID集** |
| --- | --- | --- |
| 1 | 我 | 1 |
| 2 | 是 | 1 |
| 3 | 張 | 1,2,3 |
| 4 | 三 | 1,2,3 |
| 5 | 的 | 2,3 |
| 6 | 成績單 | 2 |
| 8 | 午餐 | 3 |
實際ES的倒排索引還可以記錄更多的信息,比如
* 文檔頻率信息
* 在文檔集合中有多少個文檔包含某個單詞
有了倒排索引,搜索引擎可以很方便地響應用戶的查詢。
**例如:一次簡單的搜索流程,假設我們搜索"張三",搜索流程會是這樣**
* 分詞,分詞插件將句子分為2個term “張”,“三”
* 將這2個term拿到倒敘索引中去查找,如果匹配到了就拿對應的文檔id,獲得文檔內容,這些文檔就是提供給用戶的搜索結果。
**注:**
* 倒排索引中的所有詞項對應一個或多個文檔
* 倒排索引中的詞項根據字典順序升序排列
## 9.服務集群
**ElasticSearch集群的特性**
* 高可用性
* 在服務上允許有節點停止服務;
* 在數據上部分節點丟失,不會丟失數據;
* 可擴展性
* 隨著請求量的不斷提升,數據量的不斷增長,系統可以將數據分布到其他節點,實現水平擴展;
**ElasticSearch集群健康值**
* `綠色-green`:所有主分片和副本分片都可用
* `黃色-yellow`:所有主分片可用,部分副本分片都可用
* `紅色-red`:部分主分片可用
注:當集群狀態為 red,仍然可正常提供服務,會在現有存活分片中執行請求。需盡快修復故障分片,防止數據丟失
## 10.服務節點(Node)
* 節點是一個ElasticSearch的實例,其本質就是一個Java進程;
* 一臺機器上可以運行多個ElasticSearch實例,但是建議在生產環境中一臺機器上只運行一個ElasticSearch實
* Node 是組成集群的一個單獨的服務器,用于存儲數據并提供集群的搜索和索引功能。與集群一樣。
- 第一章 ElasticSearch基本概念
- 第二章 ElasticSearch7.x單機版安裝
- 第三章 ElasticSearch7.x高可用集群版搭建
- 第四章 Elasticsearch7.x配置文件詳解
- 第五章 Elasticsearch客戶端工具之kibana
- 第六章 Elasticsearch客戶端工具之ES-Head
- 6.1 es-head工具使用介紹
- 第七章 ElasticSearch7.x安全性之訪問密碼設置
- 第八章 Elasticsearch7.xDSL語法之索引管理
- 第九章 Elasticsearch7.xDSL語法之文檔管理
- 第十章 Elasticsearch7.xDSL語法之查詢
- 第十一章 Elasticsearch7.xDSL語法之分頁查詢
- 第十二章 Elasticsearch7.xDSL語法之聚合查詢
- 第十三章 Elasticsearch7.xDSL語法實踐手冊
- 第十四章 Elasticsearch7.xSQL語法查詢支持
- 第十五章 Elasticsearch插件之分詞器
- 15.1 ElasticSearch之IK中文分詞
- 第十六章 SpringBoot-starter-data整合Elasticsearch
- 第十七章 SpringBoot整合Elasticsearch(官方client)