## **什么是線程池?**
線程池可以理解為執行特點數量線程的管理容器
## **線程池作用**
* **降低資源消耗**
通過重復利用已創建的線程降低線程創建和銷毀造成的消耗。
* **提高響應速度**
當任務到達時,任務可以不需要等到線程創建就能立即執行。
* **提高線程的可管理性**
使用線程池可以進行統一分配、調優和監控
## **線程池的創建方式**
Java通過Executors(jdk1.5并發包)提供四種線程池
* newCachedThreadPool
創建一個相對無限大可緩存線程池,如果線程池長度超過處理需要,可靈活回收空閑線程,若無可回收,則新建線程
```
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int temp = i;
newCachedThreadPool.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + ",i:" + temp);
}
});
}
```
源碼分析
```
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
```
newCachedThreadPool方法只是對ThreadPoolExecutor方法做了簡單的封裝,其中
1.corePoolSize:核心線程數為0
2.maximumPoolSize:最大線程數為最大整數值Integer.MAX\_VALUE,可以理解為無限大
3.keepAliveTime:空閑等待銷毀時間為60S
4.workQueue:線程緩存隊列采用的是SynchronousQueue單元素阻塞隊列
總結:核心線程數小于最大線程數且為0,所以任務完成后60S所有線程都會銷毀,因為采用的是SynchronousQueue單元素阻塞隊列,隊列無法緩存多個任務,所以多任務時會不停的創建線程。
* newFixedThreadPool
創建一個固定長度的線程池,可控制線程最大并發數,超出的線程會在隊列中等待
```
ExecutorService newFixedThreadPool = Executors.newFixedThreadPool(3);
for (int i = 0; i < 10; i++) {
final int temp = i;
newFixedThreadPool.execute(new Runnable() {
@Override
public void run() {
...
Thread.sleep(100);
...
System.out.println(Thread.currentThread().getName() + ",i:" + temp);
}
});
}
```
執行結果如下、并且程序不會退出
```
pool-1-thread-1,i:0
pool-1-thread-2,i:1
pool-1-thread-3,i:2
pool-1-thread-1,i:3
pool-1-thread-2,i:4
pool-1-thread-3,i:5
pool-1-thread-1,i:6
pool-1-thread-2,i:7
pool-1-thread-3,i:8
pool-1-thread-1,i:9
```
源碼分析
```
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
```
newFixedThreadPool方法也只是對ThreadPoolExecutor方法做了簡單的封裝,其中
1.corePoolSize:核心線程數為用戶設定的值
2.maximumPoolSize:最大線程數為等于核心線程數
3.keepAliveTime:空閑等待銷毀時間為0S
4.workQueue:線程緩存隊列采用的是LinkedBlockingQueue隊列
總結:核心線程數等于最大線程數、所以線程池在創建三個線程后會一直維持,等待的任務保存在LinkedBlockingQueue隊列中,任務完成后線程池維持3個線程等待任務,剩余其他線程銷毀。
* newScheduledThreadPool
創建一個定長線程池,支持定時及周期性任務執行
```
ScheduledExecutorService newScheduledThreadPool = Executors.newScheduledThreadPool(3);
for (int i = 0; i < 10; i++) {
final int temp = i;
newScheduledThreadPool.schedule(new Runnable() {
@Override
public void run() {
...
Thread.sleep(100);
...
System.out.println(Thread.currentThread().getName() + ",i:" + temp);
}
}, 3, TimeUnit.SECONDS);
}
```
表示延遲3秒處理
源碼分析
```
public class ScheduledThreadPoolExecutor
extends ThreadPoolExecutor
implements ScheduledExecutorService {
...
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
...
}
```
ScheduledThreadPoolExecutor也是繼承ThreadPoolExecutor了方法,其中
1.corePoolSize:核心線程數為用戶設定的值
2.maximumPoolSize:最大線程數為最大整數值Integer.MAX\_VALUE,可以理解為無限大
3.keepAliveTime:空閑等待銷毀時間為0S
4.workQueue:線程緩存隊列采用的是專門的DelayedWorkQueue隊列
總結:線程可無限創建,但是當任務數量小于核心線程數時,多余的線程都會第一時間被銷毀,只保留核心線程數量值的線程。
* newSingleThreadExecutor
創建一個單線程化的線程池,它只會用唯一的工作線程來執行任務,保證所有任務按照指定順序(FIFO, LIFO, 優先級)執行
```
ExecutorService newSingleThreadExecutor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
final int temp = i;
newSingleThreadExecutor.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + ",i:" + temp);
}
});
}
```
源碼分析
```
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
```
底層使用的還是ThreadPoolExecutor的構造方法,其中
1.corePoolSize:核心線程數為1
2.maximumPoolSize:最大線程數為1
3.keepAliveTime:空閑等待銷毀時間為0S
4.workQueue:緩存隊列采用的是LinkedBlockingQueue隊列
總結:只創建并且保持一個線程在執行任務,所有等待任務保存在LinkedBlockingQueue隊列中
總結上面4中創建線程池的方法,似乎發現最終執行的還是ThreadPoolExecutor的構造方法,只是構造參數不同而已
* corePoolSize
核心池的大小。 當有任務來之后,就會創建一個線程去執行任務,當線程池中的線程數目達到corePoolSize后,就會把到達的任務放到緩存隊列當中
* maximumPoolSize
線程池最大線程數,它表示在線程池中最多能創建多少個線程
* keepAliveTime
最大連接數大于核心線程數時,空閑等待的線程待銷毀的時間
* workQueue
緩存隊列,線程池中線程數量大于核心線程數時,任務存入次隊列中
## **線程池原理分析**
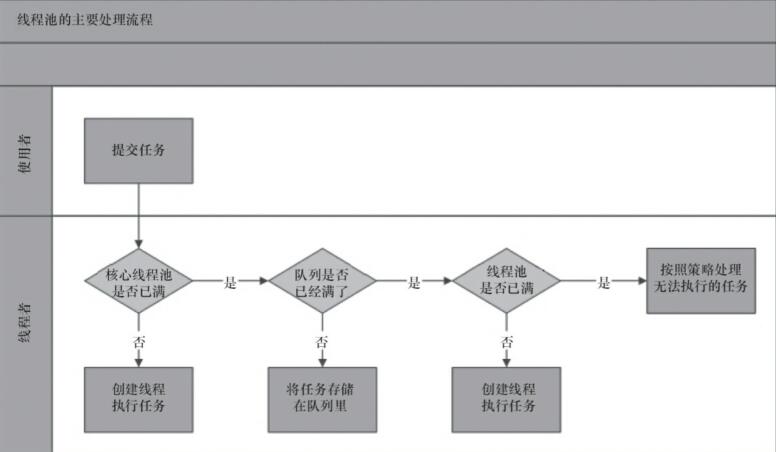
線程池的處理流程
## **自定義線程池**
創建線程任務
```
class TaskThread implements Runnable {
private String name;
public TaskThread(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + name);
}
}
```
自定義線程池
```
class test {
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 2,
60L, TimeUnit.SECONDS, new ArrayBlockingQueue<>(5));
for (int i = 0; i < 10; i++) {
executor.execute(new TaskThread("任務" + i));
}
executor.shutdown();
}
}
```
自定義線程中
1.corePoolSize:核心線程數為1
2.maximumPoolSize:最大線程數為2
3.keepAliveTime:空閑等待銷毀時間為60S
4.workQueue:緩存隊列采用的是ArrayBlockingQueue長度為5的有界隊列
執行結果
```
java.util.concurrent.RejectedExecutionException...
pool-1-thread-2任務6
pool-1-thread-2任務1
pool-1-thread-2任務2
pool-1-thread-2任務3
pool-1-thread-2任務4
pool-1-thread-2任務5
pool-1-thread-1任務0
```
最終執行了7次的任務,最后拋出RejectedExecutionException異常警告,那就來分析一下原因吧。
根據線程池的執行流程可分析
1.核心線程數為1,線程池會創建一個線程執行一個任務任務
2.當任務數量大于核心線程數量時,線程池會將未被分配執行的任務保存待緩存隊列中,因為緩存隊列是初始化長度為5的有界隊列,所有只能緩存5個任務。
3.緩存隊列存儲滿了之后,線程池判斷最大線程數,發現最大線程數為2,因為當前只創建了1個線程,所有線程池會再去創建一個線程去執行一個任務。
4.到最后線程池發現最大的線程數已經滿了,但是還是有任務需要執行,于似乎直接拒絕處理拋出異常。
## **合理配置線程池**
需要根據任務的特性來分析
1. 任務的性質:CPU密集型、IO密集型和混雜型
2. 任務的優先級:高中低
3. 任務執行的時間:長中短
4. 任務的依賴性:是否依賴數據庫或者其他系統資源
* CPU密集型任務應配置盡可能小的線程,如配置CPU個數+1的線程數
* IO密集型任務應配置盡可能多的線程,因為IO操作不占用CPU,不要讓CPU閑下來,應加大線程數量,如配置兩倍CPU個數+1
* 混合型的任務,如果可以拆分,拆分成IO密集型和CPU密集型分別處理,前提是兩者運行的時間是差不多的,如果處理時間相差很大,則沒必要拆分了
* 前人總結的 最佳線程數=((線程等待時間+線程CPU時間)/線程CPU時間 )\* CPU數目
