# 使用OQL分析虛擬機內存
本章作為書第一章的補充,較為詳細說明了如何進行內存分析以解決因為內存使用過多導致的性能降低以及內存溢出現象。有些非內存故障問題,頁可以通過OQL來分析對象在內存中使用情況,查看對象運行時刻的屬性值。
## 獲取內存鏡像文件
當應用系統性能不佳的時候,我們在第一章介通過 jvisualvm的抽樣器定位性能瓶頸外,系統性能不佳還可能是虛擬機頻繁的全局垃圾回收導致。
導入本節附帶工程OQL后,可以直接運行OutMemoryCase1方法,該方法會不斷的向Map里添加User實例,直到內存用滿為止
~~~java
public class OutMemoryCase1 {
static Map<Long,User> map = new HashMap<>();
static long idBase = 0;
static Config config = new Config();
static public void test() {
config.setMax(1000);
config.setSleep(100);
for(int i=0;i<config.getMax();i++){
User user = new User();
user.setId((long)idBase);
user.setName("user"+idBase);
user.setDepartId((long)idBase);
map.put(user.getId(),user);
idBase++;
}
}
public static void main(String[] ags) throws InterruptedException {
while(true){
test();
Thread.sleep(config.getSleep());
System.out.println(config.getMessage()+idBase);
}
}
}
~~~
test方法會循環運行1萬次,像類變量map添加User實例,main方法則不斷循環運行test,每循環一次,會打印idBase變量。
User對象是一個POJO,包含了id,departId,和name屬性,定義如下
~~~java
public class User {
private Long id ;
private Long departId ;
private String name;
//忽略getter和setter
}
~~~
Config對象如下定義,包含了循環,休眠等配置信息
~~~java
public class Config {
private int max =100;
private int sleep = 10;
private String message = ">";
//忽略getter和setter
}
~~~
運行OutMemoryCase1方法后,我們可以使用jdk命令jps 獲取進程編號
~~~
>jps -ml
914 com.ibeetl.code.OutMemoryCase1
957 sun.tools.jps.Jps -ml
~~~
然后我們使用jdk的jstat命令觀察內存使用情況
~~~
jstat -gcutil -h 20 914 2000 0
~~~
- -gcutil 表示輸出內存使用匯總信息。
- -h 表示沒輸出20行,再打印一次表頭
- 914是我們需要監控的虛擬機進程ID,使用需要用實際進程id代替
- 2000表示每2000毫秒輸出一行信息
- 最后一個參數 0 表示一直輸出,如果填寫其他數字n,則最多輸出n行
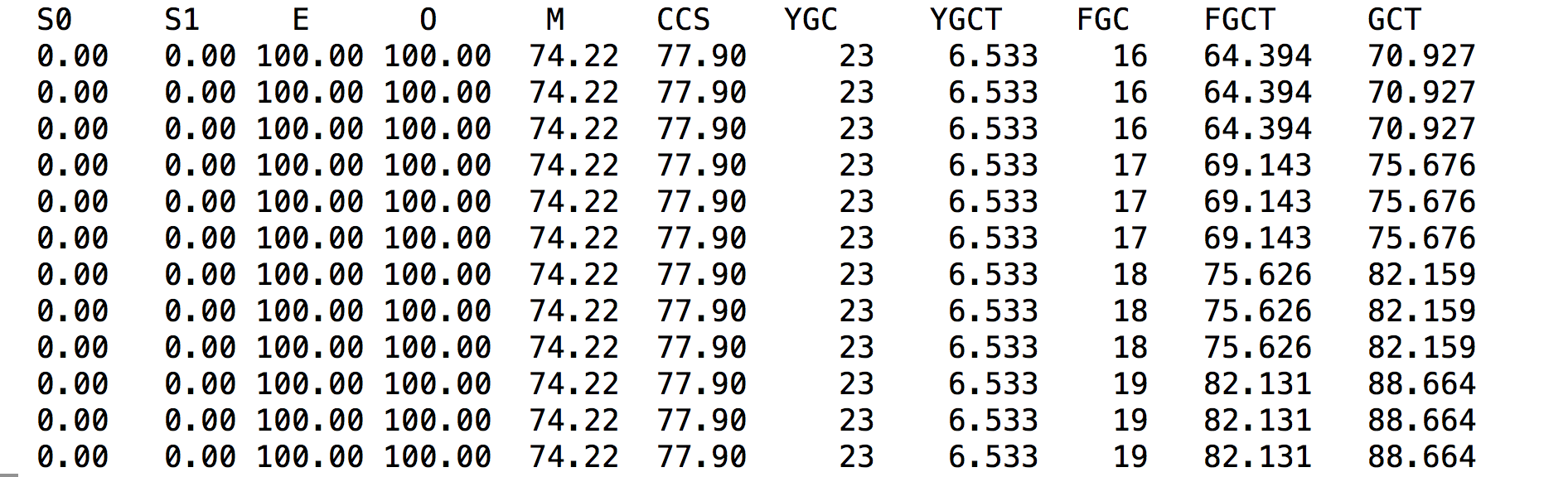
上圖顯示了虛擬機各個代的使用情況,描述了堆內存的各個占比和垃圾回收次數以及占用時間
* S0,第一個幸存區使用比率
* S1,第二個幸存區的使用率
* E,伊甸園區的使用比率
* O 老年代
* M 方法區,元空間使用率
* CCS,壓縮使用比率
* YGC 年輕代垃圾回收次數
* YGCT 年紀帶垃圾回收占用時間
* FGC 全局垃圾回收次數,這對性能影響至關重要
* FGCT 全局垃圾回收的消耗時間
* GCT 總得垃圾回收時間
關于虛擬機的內部結構和垃圾回收機制,超出了本書的范疇,這里做一些簡要描述,我們只需要關注一些異常情況。
Java虛擬機中,對象的生命周期有長有短,大部分對象的生命周期很短,只有少部分的對象才會在內存中存留較長時間,因此可以依據對象生命周期的長短將它們放在不同的區域。在采用分代收集算法的Java虛擬機堆中,一般分為三個區域,用來分別儲存這三類對象:
新生代 - 剛創建的對象,在代碼運行時一般都會持續不斷地創建新的對象,這些新創建的對象有很多是局部變量,很快就會變成垃圾對象。這些對象被放在一塊稱為新生代的內存區域。新生代的特點是垃圾對象多,存活對象少。
在新生代區域中,按照8:1:1的比例分為了Eden、SurvivorA、SurvivorB三個區域。其中Eden意為伊甸園,形容有很多新生對象在里面創建;Survivor區則為幸存者,即經歷GC后仍然存活下來的對象。
Eden區對外提供堆內存。當Eden區快要滿了,則進行Minor GC(新生代GC),把存活對象放入SurvivorA區,清空Eden區;
Eden區被清空后,繼續對外提供堆內存;
當Eden區再次被填滿,此時對Eden區和SurvivorA區同時進行Minor GC(新生代GC),把存活對象放入SurvivorB區,此時同時清空Eden區和SurvivorA區;
Eden區繼續對外提供堆內存,并重復上述過程,即在 Eden 區填滿后,把Eden區和某個Survivor區的存活對象放到另一個Survivor區;
當某個Survivor區被填滿,且仍有對象未被復制完畢時,或者某些對象在反復Survive 15次左右時,則把這部分剩余對象放到老年代區域;當老年區也被填滿時,進行Major GC(老年代GC),對老年代區域進行垃圾回收。
老年代 - 一些對象很早被創建了,經歷了多次GC也沒有被回收,而是一直存活下來。這些對象被放在一塊稱為老年代的區域。老年代的特點是存活對象多,垃圾對象少。
永久代 - 一些伴隨虛擬機生命周期永久存在的對象,比如一些靜態對象,常量等。這些對象被放在一塊稱為永久代的區域。永久代的特點是這些對象一般不需要垃圾回收,會在虛擬機運行過程中一直存活。(在Java1.7之前,方法區中存儲的是永久代對象,Java1.7方法區的永久代對象移到了堆中,而在Java1.8永久代已經從堆中移除了,這塊內存給了元空間。
從jstat的輸出可以看到,老年代已經使用了99.9%,FGC一直在不停的增長,說明內存幾乎已經占滿,正常情況應該很難觀察到一次FGC發生。從控制臺的打印輸出來看
~~~
.......
9320000
9330000
9340000
~~~
系統輸出已經停滯在9340000值(在此是作者本人機器上運行結果,實際結果不一定是這個值),這代表此時系統執行已經非常緩慢了,這就是因為虛擬機頻繁的全局垃圾回收導致的。
如果你不了解oql工程,沒有看過代碼OutMemoryCase1 如何診斷此時系統是哪一處代碼出問題了呢,思路實獲取內存的dump文件,然后通過OQL,一種類似SQL的分析語句分析內存dump文件,定位問題代碼。
有多種方式獲取到內存dump文件:
通過jmap?命令主動獲取到
~~~
jmap -dump:format=b,file=filename.hprof pid
~~~
實際系統會有2G到8G內存,此命令會導致虛擬機暫停1-3秒時間,并生成指定filename的dump文件
還有一種是被動獲取方式,當虛擬機出現內存溢出的時候,會主動dump內存文件。添加虛擬機啟動參數
~~~
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof
~~~
會有如下輸出
~~~
>9454000
>9455000
java.lang.OutOfMemoryError: Java heap space
Dumping heap to heapdump.hprof ...
~~~
通過打開jvisualvm也可以獲取到堆dump文件,在左側進程列表里找到該進程,右鍵,點擊選項“堆 dump”,保存內存鏡像文件
無論那種方式,我們都會獲取到內存dump文件,我們下一節,將使用jvisualvm分析,主要使用OQL功能分析內存使用情況,定位系統問題
## OQL 查詢語言
打開jvisualvm工具,選擇菜單File,點擊裝入,選擇我們保存過的dump文件,這時候jvisualvm面板會打開內存鏡像文件。打開較大的內存鏡像文件需要較長的時間,需要耐心等候
有一個“類按鈕”可以進入類實例使用匯總頁面,一個OQL控制臺會進入OQL功能,我們點擊OQL直接進入OQL控制臺
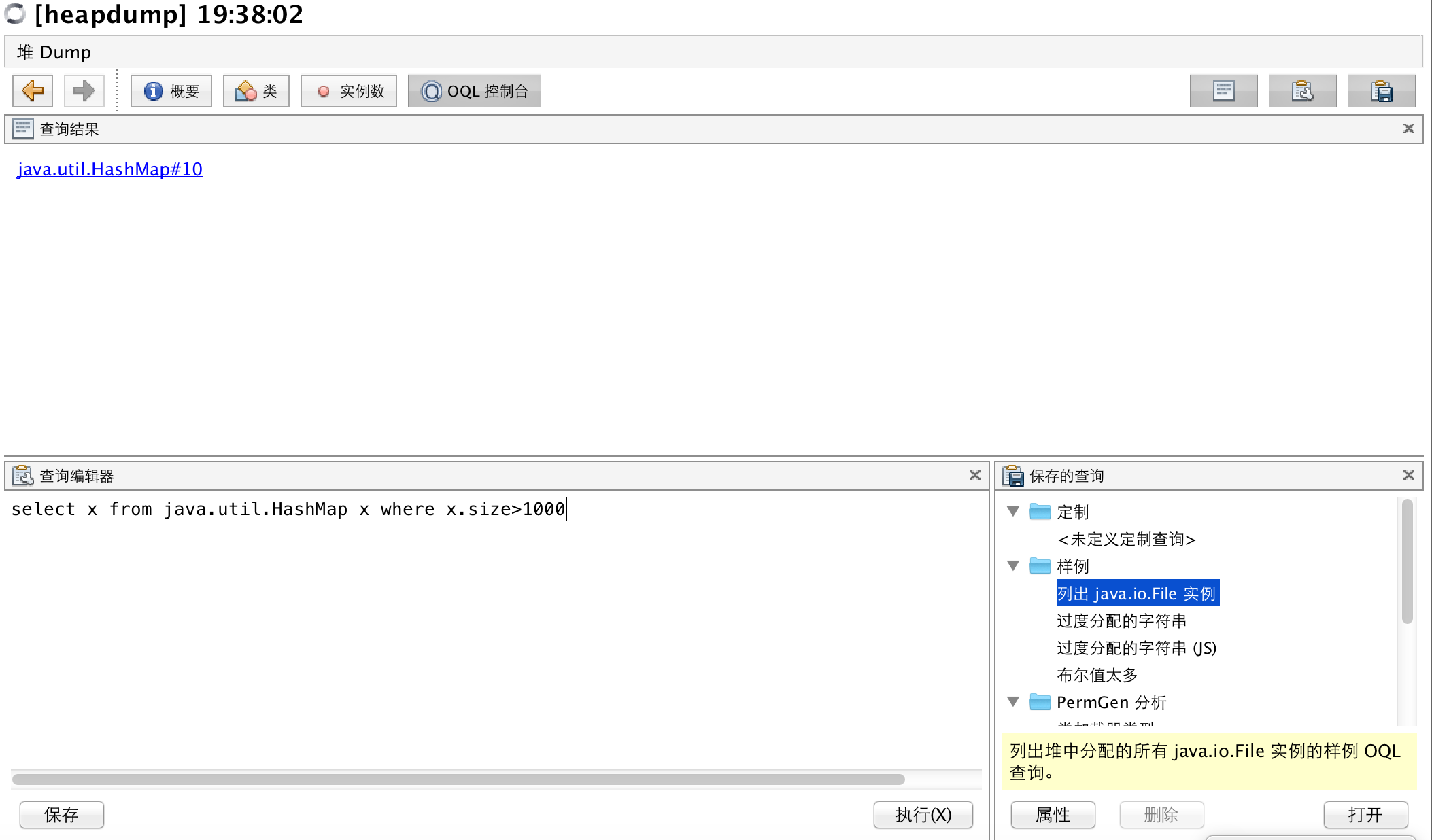
如面板所示,左下角的查詢編輯器可以輸入OQL語句,從內存中查詢,我們輸入
~~~
select x from java.util.HashMap x where x.size>1000
~~~
這個OQL語句查詢出所有HashMap實例,且其屬性size大于1000的,查詢結果顯示在面板上方。可以點擊每個實例進入詳情面板,如下圖
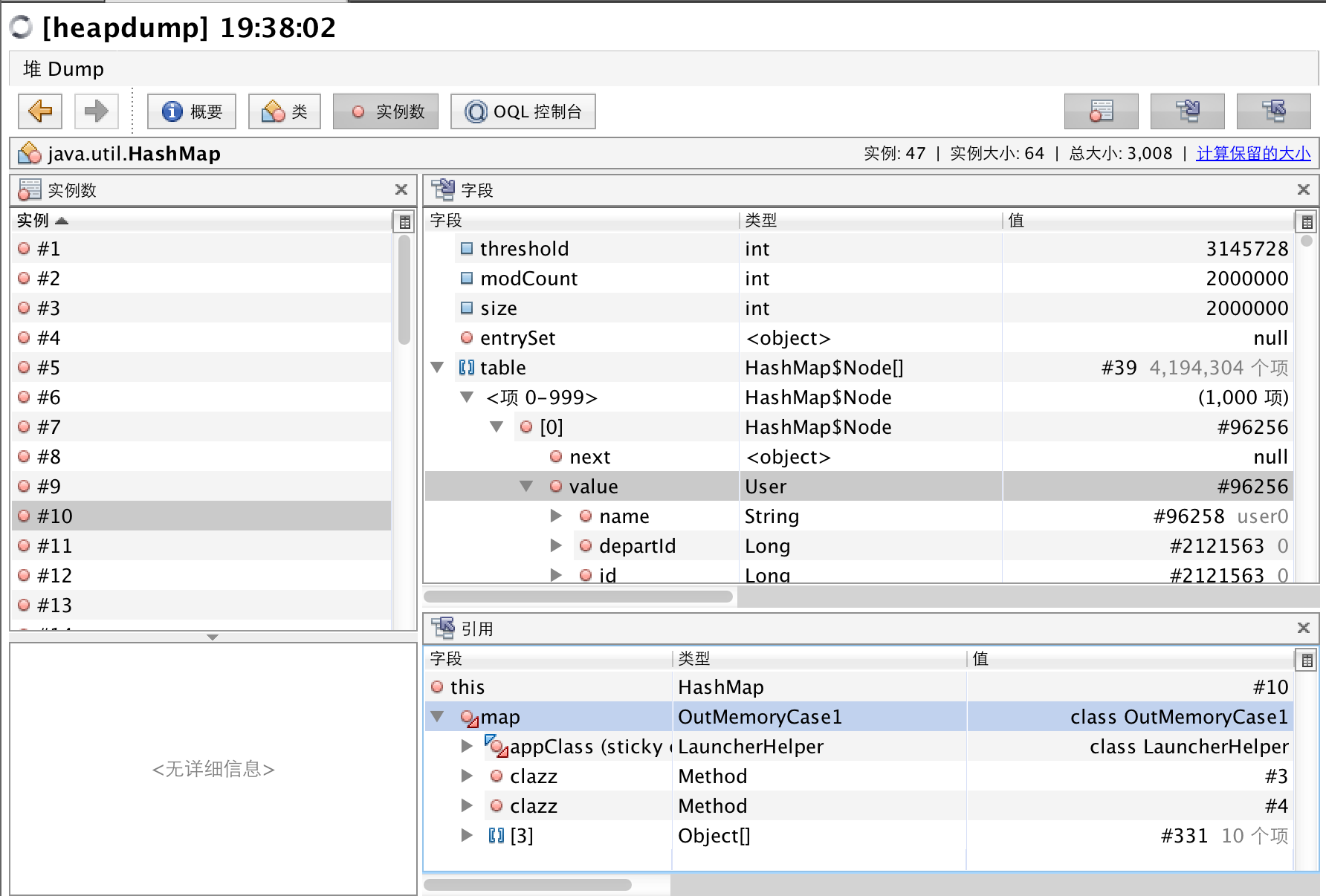
右上面板是字段面板,包含了選中實例的的所有屬性,可以看到,size屬性為2百萬,是個非常大的數,這代表此時HashMap包含了2百萬個對象,如果熟悉HashMap代碼,我們知道table屬性保存了所有的元素,我們可以點擊table屬性,向下鉆取,可以看到存放的正是User對象。
右下面板是引用面板,根節點為this,表示了我們查詢出來的這個HashMap實例,該面板節點每個子節點表示了所屬關系,我們可以看到這個HashMap實例的名字是map,屬于OutMemoryCase1類。
截至到目前為止,我們已經使用一條OQL語句找到了內存的溢出的原因,且定位到代碼位置為OutMemoryCase1。我們下面學習更多的OQL語法,這有助于幫助我們分析內存
OQL語法類似SQL和Javascript結合體,javascript用于表達式和方法調用,格式如下
~~~
select <JavaScript expression to select>
[ from [instanceof] <class name> <identifier>
[ where <JavaScript boolean expression to filter> ] ]
~~~
* class name是java類的完全限定名,如:java.lang.String, java.util.ArrayList, [C是char數組, [Ljava.io.File是java.io.File[],依此類推,insatnceof 關鍵字用上,表示將查詢其子類
* from和where子句都是可選的
* 可以使用identifier.fieldName語法訪問Java字段,并且可以使用array [index]語法形式訪問數組元素。
* OQL使用的是JS表達式,因此使用&&和||,不要使用and or
比如查找超長的字符串,這里的10000是一個任意指定的值,如下OQL語句查找字符串長度超過1萬的。
~~~java
select s from java.lang.String s where s.value.length >= 10000
~~~
這里s表示String,查看java.lang.String有個名字為value的char[] 類型的數組,因此filter是s.value.length >= 10000
針對OutMemoryCase1,比如我們要查找user對象中departId為15的User對象,并輸出其name屬性
~~~java
select u.name from com.ibeetl.code.User u where u.departId.value==15
~~~
需要注意的事,User對象的departId類型Long,并非原始類型,因此需要使用Long對象的value屬性來比較。另外在OQL里任意實例的都有屬性id,是在OQL分配的對象唯一標識,因此,如下OQL語句在jvisualvm執行得不到期望的結果
~~~
//錯誤的OQL語句,id屬性是內存分配的唯一id,并非用戶的id屬性
select u.name from com.ibeetl.code.User u where u.id.value==15
~~~
如下查詢包含key為"abc"的Map,value為"edf",注意需要使用toString才能比較字符串
```sql
select m from java.util.Map$Entry m where m.key.toString()='abc'&&m.value.toString()='edf'
```
通過size函數獲取實例本身占用的空間,rsize函數獲取實例占用的shallow空間,實際使用空間
~~~
select sizeof(x) from java.util.HashMap x where x.size>1000
select rsizeof(x) from java.util.HashMap x where x.size>1000
~~~
rsizeof 會計算對象下每一個對象占用空間,因此執行該語句需要較長時間,sizeof僅僅計算此對象屬性占用空間。查詢出來的對象可以通過objectid函數得到一個16進制編號,可以記住這個唯一編號,在用函數heap.findObject直接定位到該實例
~~~sql
select objectid(x) from com.ibeetl.code.Config
//查詢返回"31150212072",可以記住下次再分析的時候直接查詢該Config對象
select heap.findObject(31150212072)
~~~
OQL提供了一系列的heap方法,用于查找實例,由于附錄并非專門講解OQL,因此列出重要的方法并還是以OutMemoryCase1為例子,說明如何使用
* heap.forEachClass - 為每個Java類調用一個回調函數
~~~
heap.forEachClass(callback);
~~~
* heap.forEachObject - 為每個Java對象調用回調函數
~~~
heap.forEachObject(callback, clazz, includeSubtypes);
~~~
如果clazz未指定,則是默認的java.lang.Object,includeSubtypes表示查找子類,如果未指定,默認是true,callback是一個類似JS的回掉函數.
* heap.findClass - 查找給定名稱的Java類
* heap.findObject 根據對象標識查詢對象
* heap.objects 返回Java對象的枚舉
~~~
heap.objects(clazz, [includeSubtypes], [filter])
~~~
比如,我們需要查找某個User對象,其name屬性的值是“user1“結尾,我們可以使用js正則表達式查詢
~~~
heap.objects("com.ibeetl.code.User", false, "/user1$/.test(it.name)")
//或者
heap.objects ("com.ibeetl.code.User",false,"it.name.toString()=='user1'")
~~~
* heap.livepaths 返回給定對象存活的路徑數組。此方法接受可選的第二個參數,它是一個布爾標志。此標志指示是否包含弱引用的路徑。默認情況下,不包括具有弱引用的路徑。
~~~
select heap.livepaths(config) from com.ibeetl.code.Config config
~~~
會有如下輸出,我們可以看到Config對象被OutMemoryCase1引用
~~~
com.ibeetl.code.Config#1->com.ibeetl.code.OutMemoryCase1->sun.launcher.LauncherHelper
~~~
OQL提供了一些對集合操作的方法,允許查詢出來的結果集,進行過濾和加工,一些常用的函數如下
* filter
filter函數返回一個數組/枚舉,其中包含滿足給定布爾表達式的輸入數組/枚舉的元素。布爾表達式代碼可以引用以下內置變量。it - >目前訪問過的元,index - >當前元素的索,array - >正在迭代的數組/枚舉,result - > result array / enumeration
如查詢User對象,name屬性為“user1”
~~~
select filter(heap.objects ("com.ibeetl.code.User"), "it.name.toString()=='user1'")
~~~
或者使用回調函數
~~~javascript
select filter(heap.objects ("com.ibeetl.code.User"), function(it){
if(it.name.toString()=='user1'){
return true;
}else{
return false;
}
})
~~~
* map
通過評估每個元素上的給定代碼來轉換給定的數組/枚舉。評估的代碼可以引用以下內置變量。it - >目前訪問過的元,index - >當前元素的索,array - >正在迭代的數組/枚舉,result - > result array / enumeration
map函數返回通過在輸入數組/枚舉的每個元素上重復調用代碼而創建的值的數組/枚舉。
~~~javascript
select map(heap.objects('com.ibeetl.code.User'),
function (it) {
var res = objectid(it);
res+=">"+toHtml(it);
return res ;
})
~~~
此例子通過heap.objects查詢所有的User實例,返回數組,并傳入map方法,map將每個User實例 轉化為一個字符串,包含了User實例的唯一編號,toHtml方法是OQL自帶的一個方法,接受一個對象實例,輸出帶有類名和順序號的字符串。運行語句,有如下輸出
~~~
31138521288>com.ibeetl.code.User#1
31138521456>com.ibeetl.code.User#2
31138521624>com.ibeetl.code.User#3
........
~~~
* max函數,返回給定數組/枚舉的最大元素。接受表達式以比較數組的元素。默認情況下使用數字比較。比較表達式可以使用以下內置變量:lhs - >左側元素進行比較,rhs - >右側元素進行比較
如查詢容量最大的Map,這有可能是內存溢出發生的地方。
~~~
select max(map(heap.objects('java.util.HashMap'), 'it.size'))
// 或者
select max(heap.objects('java.util.HashMap'), 'lhs.size> rhs.size')
~~~
* min函數,同max,返回給定數組/枚舉的最小元素
* sort函數,給出數組/枚舉的排序。(可選)接受代碼表達式以比較數組的元素。默認情況下使用數字比較。比較表達式可以使用以下內置變量:lhs 代表左側元素,rhs - >代表右側元素
~~~
select sort(heap.objects('[C'), 'sizeof(lhs) - sizeof(rhs)')
~~~
查詢所有字符串數組,并按照大小升序排序。
附錄A介紹了JDK自帶的OQL,許多商業的內存分析器提供了更多的內置的分析功能以及OQL功能擴展,如果有條件,建議使用這些商業內存分析器和參考他們的OQL使用文檔介紹。在我的內存故障解決里,基本上使用自帶的OQL就能找到問題所在了,需要耐心的分析和查找問題。
- 內容介紹
- 第一章 Java系統優化
- 1.1 可優化的代碼
- 1.2 性能監控
- 1.3 JMH
- 1.3.1 使用JMH
- 1.3.2 JMH常用設置
- 1.3.3 注意事項
- 1.3.4 單元測試
- 第二章 字符串和數字
- 2 字符串和數字操作
- 2.1 構造字符串
- 2.2 字符串拼接
- 2.3 字符串格式化
- 2.4 字符串查找
- 2.6 intern方法
- 2.7 UUID
- 2.8 StringUtils類
- 2.9 前綴樹過濾
- 2.10 數字裝箱
- 2.11 BigDecimal
- 第三章 并發和異步編程
- 3.1 不安全的代碼
- 3.2 Java并發編程
- 3.2.1 volatile
- 3.2.2 synchronized
- 3.2.3 Lock
- 3.2.4 Condition
- 3.2.5 讀寫鎖
- 3.2.6 semaphore
- 3.2.7 柵欄
- 3.3 Java并發工具
- 3.3.1 原子變量
- 3.3.2 Queue
- 3.3.3 Future
- 3.4 Java線程池
- 3.5 異步編程
- 3.5.1 創建異步任務
- 3.5.2 完成時回調
- 3.5.3 串行執行
- 3.5.4 并行執行
- 3.5.5 接收任務處理結果
- 第四章 代碼性能優化
- 4.1 int 轉 String
- 4.2 使用Native 方法
- 4.3 日期格式化
- 4.4 switch 優化
- 4.5 優先用局部變量
- 4.6 預處理
- 4.7 預分配
- 4.8 預編譯
- 4.9 預先編碼
- 4.10 謹慎使用Exception
- 4.11 批處理
- 4.12 展開循環
- 4.13 靜態方法調用
- 4.14 高速Map存取
- 4.15 位運算
- 4.16 反射
- 4.17 壓縮
- 4.18 可變數組
- 4.19 System.nanoTime()
- 4.20 ThreadLocalRandom
- 4.21 Base64
- 4.22 辨別重量級對象
- 4.23 池化技術
- 4.24 實現hashCode
- 4.25 錯誤優化策略
- 4.25.1 final無法幫助內聯
- 4.25.2 subString 內存泄露
- 4.25.3 循環優化
- 4.25.4 循環中捕捉異常
- 4.25.5 StringBuffer性能不如StringBuilder高
- 第五章 高性能工具
- 5.1 高速緩存 caffeine
- 5.1.1 安裝
- 5.1.2 caffeine 基本使用
- 5.1.3 淘汰策略
- 5.1.4 statistics 功能
- 5.1.5 caffeine高命中率
- 5.1.6 卓越性能
- 5.2 selma映射工具
- 5.3 Json工具 Jackson
- 5.3.1 Jackson三種使用方式
- 5.3.3 對象綁定
- 5.3.2 Jackson 樹遍歷
- 5.3.4 流式操作
- 5.3.6 自定義 JsonSerializer
- 5.3.7 集合的反序列化
- 5.3.8 性能提升和優化
- 5.4 HikariCP
- 5.4.1 HikariCP安裝
- 5.4.3 HikariCP 性能測試
- 5.4.4 性能優化說明
- 5.5 文本處理Beetl
- 5.5.1 安裝和配置
- 5.5.2 腳本引擎
- 5.5.3 特點
- 5.5.4 性能優化
- 5.6 MessagePack
- 5.7 ReflectASM
- 第六章 Java注釋
- 6.1 JavaDoc
- 6.2 Tag
- 6.2.1 {@link}
- 6.2.2 @deprecated
- 6.2.3 {@literal}
- 6.2.4 {@code}
- 6.2.5 {@value}
- 6.2.6 @author
- 6.2.7 @param 和 @return
- 6.2.8 @throws
- 6.2.9 @see
- 6.2.10 自動拷貝
- 6.3 Package-Info
- 6.4 HTML生成
- 6.5 Markdown-doclet
- 第七章 可讀性代碼
- 7.1 精簡注釋
- 7.2 變量
- 7.2.1 變量命名
- 7.2.2 變量的位置
- 7.2.3 中間變量
- 7.3 方法
- 7.3 .1 方法簽名
- 7.3.2 小方法
- 7.3.3 單一職責
- 7.3.3 小類
- 7.4 分支
- 7.4.1 if else
- 7.4.2 switch case
- 7.5 發現對象
- 7.3.1 不要用String
- 7.3.2 不要用數組,Map
- 7.6 checked異常
- 7.7 其他
- 7.7.1 避免自動格式化
- 7.7.2 關于Null
- 第八章 JIT優化
- 8.1 解釋和編譯
- 8.2 C1和C2
- 8.3 代碼緩存
- 8.4 JITWatch
- 8.5 內聯
- 8.6 虛方法調用
- 第九章 代碼審查
- 9.1 ConcurrentHashMap陷阱
- 9.2 字符串搜索
- 9.3 IO輸出
- 9.4 字符串拼接
- 9.5 方法的入參和出參
- 9.6 RPC調用定義的返回值
- 9.7 Integer使用
- 9.8 排序
- 9.9 判斷特殊的ID
- 9.10 優化if結構
- 9.11 文件COPY
- 9.12 siwtch優化
- 9.13 Encoder
- 9.14一個JMH例子
- 9.15 注釋
- 9.16 完善注釋
- 9.17 方法抽取
- 9.18 遍歷Map
- 9.19 日期格式化
- 9.20 日志框架設計的問題
- 9.21 持久化到數據庫
- 9.22 某個RPC框架
- 9.23 循環調用
- 9.24 Lock使用
- 9.25 字符集
- 9.26 處理枚舉值
- 9.27 任務執行
- 9.28 開關判斷
- 9.29 JDBC操作
- 9.30 Controller代碼
- 9.31 停止任務
- 9.32 log框架
- 9.33 縮短UUID
- 9.34 Dubbo ThreadPool設置
- 9.35 壓縮設備信息
- 第十章 ASM運行時增強
- 10.1 Java字節碼
- 10.1.1 基礎知識
- 10.1.2 class文件格式
- 10.2 Java方法的執行
- 10.2.1 方法在內存的表示
- 10.2.3 方法在class文件中的表示
- 10.2.3 指令的分類
- 10.2.4 操作數棧的變化分析
- 10.3 Bytecode Outline插件
- 10.4 ASM入門
- 10.4.1 生成類名及構造函數
- 10.4.2 生成main方法
- 10.4.3 調用生成的代碼
- 10.5 ASM增強代碼
- 10.5.1 使用反射實現
- 10.5.2 使用ASM生成輔助類
- 10.5.3 switch語句的分類
- 10.5.4 獲取bean中的property
- 10.5.5 switch語句的實現
- 10.5.6 性能對比
- 第十一章 JSR269編譯時增強
- 11.1 Java編譯的過程
- 11.2 注解處理器入門
- 11.3 相關概念介紹
- 11.3.1 AbstractProcessor
- 11.3.2 Element與TypeMirror
- 11.4 注解處理器進階
- 11.4.1 JsonWriter注解
- 11.4.2 處理器與生成輔助類
- 11.4.3 使用生成的Mapper類
- 11.4.4 注解處理器的使用
- 11.5 調試注解處理器
- 11.5.1 Eclipse中調試注解處理器
- 11.5.2 Idea中調試注解處理
- 附錄A OQL分析JVM內存(免費)
- 附錄B 7行代碼的9種性能優化方法(免費)
- 附錄 C CPUCacheTest更多討論(免費)