
[TOC]
## 1 定義
Java 內存模型(JSR-133)的主要目的是定義程序中各種變量(Variables)的訪問規則
- Variables 包括實例字段(instance field),靜態字段(static field)和構成數組的元素(array element),不包括局部變量(local variable)與方法參數(method params),因為后者是線程私有的
- 所有的 Variables 都存儲在虛擬機中的主內存(Main Memory);每條線程有自己的工作內存(Working Memory),保存了 Variables 的主內存副本
- 線程對 Variables 的所有操作,都必須在 Working Memory 中完成,不同線程間不能相互訪問彼此的 Variables
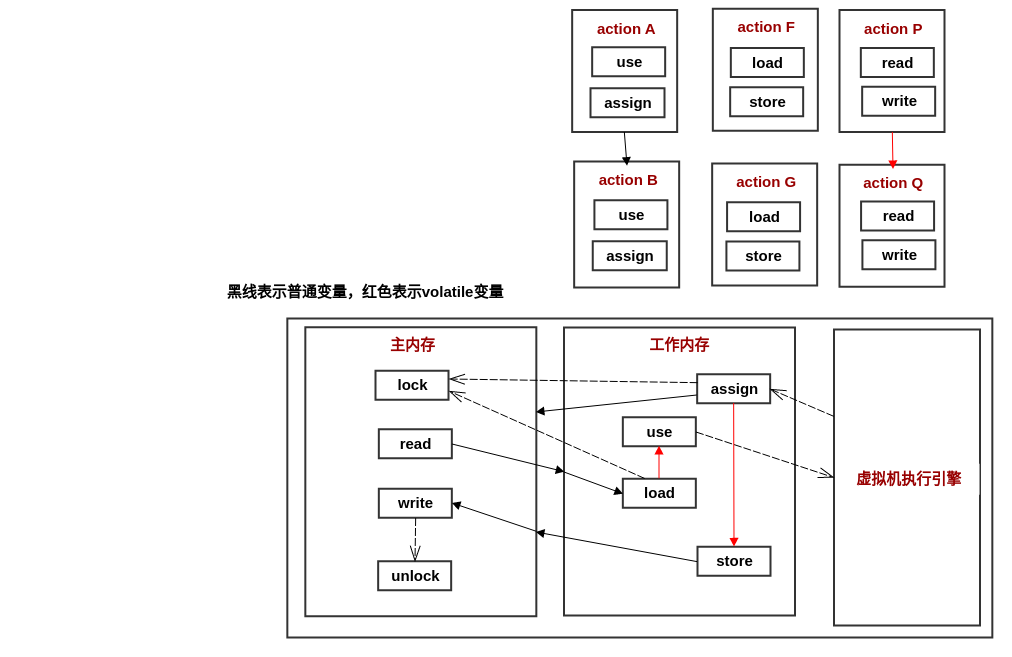
## 2 八種原子的內存間交互操作
Java 虛擬機實現時必須保證下面的每一種操作都是原子的:
名稱 | 簡稱 | 作用位置 | 功能
---- | ---- | ---- | ----
lock | 鎖定 | 主內存的變量 | 把一個變量標識為一條線程獨占的狀態
unlock | 解鎖 | 主內存的變量 | 把一個處于鎖定狀態的變量釋放 (釋放后的變量才可被鎖定)
read | 讀取 | 主內存的變量 | 將變量值從主內存傳輸到線程的工作內存中 (以便 load )
load | 載入 | 工作內存的變量 | 把 read 操作從主內存中得到的變量值放入工作內存的變量副本中
use | 使用 | 工作內存的變量 | 把工作內存中一個變量的值傳遞給執行引擎
assign | 賦值 | 工作內存的變量 | 把一個從執行引擎接收的值賦給工作內存的變量
store | 存儲 | 工作內存的變量 | 把變量值從傳輸到主內存 (以便 write)
write | 寫入 | 主內存的變量 | 把 store 操作從工作內存中得到的變量值放入主內存的變量中
Java 內存模型規定了在執行上述 8 種操作時必須滿足以下規則:
- (read 與 load) 或者 (store 與 write) 操作必須成對出現 (不允許主內存 read 后,工作內存不 load,或者工作內存 store 后,主內存不 write)
- 不允許一個線程丟棄它最近的 assign 操作 (變量在工作內存中改變了之后,必須同步回主內存)
- 不允許一個線程無原因地(沒有發生過任何 assign 操作)把數據從線程的工作內存同步回主內存
- 在對變量實施 use 、store 操作之前,必須先執行 load 和 assign操作 (新變量只能在主內存中創建,不允許工作內存使用未被初始化的變量)
- 一個變量在同一時刻只允許一條線程對其進行 lock ,但 lock 操作可以被同一條線程重復執行多次,多次執行 lock 后,只有執行相同次數的 unlock ,變量才會被解鎖
- 如果一個變量執行 lock 操作,將會清空工作內存中此變量的值,在執行引擎使用這個變量前,需要重新執行 load 或 assign 操作以初始化變量的值
- 一個線程不允許 unlock 一個未被 lock 或者被其他線程 lock 的變量
- 對一個變量執行 unlock 操作前,必須把此變量同步回主內存中(執行 store、write 操作)
## 3 volatile 變量
對 volatile 變量的 read、load、use、assign、store 和 write 操作,規定以下**規則**:
- 一個線程對 volatile 變量的 load、use 操作必須是連續的
- 一個線程對 volatile 變量的 assign、store、write 操作必須是連續的
- volatile 變量不會被指令重排序優化
當一個變量被 volatile 修飾后,將具備以下**特性**:
- 保證此變量對所有線程的可見性 (當一條線程修改了這個變量的值,新值對于其他線程來說是可以立即得知的)
- 當不符合以下兩條規則的運算場景中,仍然要通過加鎖保證 volatile 變量的線程安全:
- 運算結果并不依賴變量的當前值,或者能夠確保只有單一線程修改變量的值
- 變量不需要與其他狀態變量共同參與不變約束
- bad case 1,volatile修飾的變量i,在10個線程中進行(i++)操作后,i不一定會增加10
- bad case 2,32位機器中long和double類型的操作非原子性,使用時需要保證原子性
- 禁止指令重排序優化
- 64位long與double變量讀寫的原子性
> 以下示例中,假設 loaded 未使用 volatile 修飾,則指令重排序后可能出現在 loadCofig() 邏輯前,導致線程 2 使用了未加載的配置
```java
volatile loaded = false;
// 線程 1
loadConfig(); // 加載配置文件
loaded = true; // 設置加載狀態
// 線程 2
while (!loaded) {
sleep(); // 判斷是否加載配置完成
}
useConfig(); // 跳出循環后使用線程 1 的配置
```
> **雙重檢測鎖定形式的延遲初始化存在的問題**
>
> 設 new A() 分為:
> 1. 分配內存
> 2. 初始化對象
> 3. sInstance 指向內存地址
>
> 重排序后可能變為`1、3、2`的順序,導致雖然第一次的 `if (sInstance == null)` 返回了 false,但是對象并未被初始化,改為 `private static volatile A sInstance;` 禁止指令重排序即可。
```java
public class A {
private static A sInstance;
public static A getInstance() {
if (sInstance == null) {
synchronized (A.class) {
if (sInstance == null) {
sInstance = new A();
}
}
}
return sInstance;
}
}
```
## 4 final 域
對于 final 域,編譯器和處理器要遵守兩個重排序規則:
- 在構造方法內對一個 final 域的寫入,與隨后把這個被構造對象的引用賦值給一個引用變量,這個兩個操作之間不能重排序。
- 初次讀一個包含 final 域的對象的引用,與隨后初次讀這個 final 域,這兩個操作之間不能重排序。
## 5 原子性、可見性和有序性
**原子性**
- Java內存模型中保證原子性的操作包括:read、load、assign、use、write、store、write,如果需要更大范圍的,可以使用 lock 和 unlock
- lock 和 unlock 體現在字節碼層面是 monitorenter 和 monitorexit 指令,反映到代碼中就是 synchronized 或 Unsafe#monitorEnter 和 Unsafe#monitorExit 方法
**可見性**
- 一個線程對變量的 load、use 操作必須是連續的
- 一個線程對變量的 assign、store、write 操作必須是連續的
- synchronized、 volatile 、final 都可以保證可見性
**有序性**
- 在單個線程中觀察,所有操作都是有序的;在一個線程觀察另一個線程,所有操作都是無序的
- synchronized、volatile 可以保證有序性
## 6 先行發生原則
先行發生原則(Happens-Before)是判斷數據是否競爭,線程是否安全的重要手段。
> 先行發生原則示例:假設 A 線程的操作先行發生于 B 線程的操作,則 j 等于 1;假設無法保證 B 線程和 C 線程的先行發生關系,則 j 的值可能為 1,也可能為 2
```java
// A 線程執行
i = 1;
// B 線程執行
j = i;
// C 線程執行
i = 2
```
假設兩個操作,不滿足以下關系之一的,虛擬機可以對其隨意重排序(有且只有以下關系):
- **程序次序規則(Program Order Rule)**:在一個線程內,按照控制流順序,書寫在前的操作先行發生于書寫在后面的操作
- **管程鎖定規則(Monitor Lock Rule)**:一個 unlock 操作先行發生于后面(時間上)對同一個鎖的 lock 操作
- **volatile 變量規則(Volatile Variable Rule)**:對一個 volatile 變量的寫操作先行發生于后面(時間上)對這個變量的讀操作
- **線程啟動規則(Thread Start Rule)**:Thread 對象的start()方法先行發生于此線程的每一個動作
- **線程終止規則(Thread Stop Rule)**:線程中的所有操作都先行發生于對此線程的終止檢測,所以可以用 Thread#join Thread#isAlive 來檢測線程線程是否已經終止
- **線程中斷規則(Thread Interruption Rule)**:對線程 interrupt()方法的調用先行發生于被中斷線程的代碼檢測到中斷事件的發生,所以可以用 Thread#interrupted 方法檢測是否有中斷發生
- **對象終結規則(Finalizer Rule)**:一個對象的構造方法結束,先行發生于它的finalize()方法的開始
- **傳遞性規則(Transitivity)**:如果操作 A 先行發生于操作 B,操作 B 先行發生于操作 C,則操作 A 先行發生于操作 C
----
> 一個非線程安全的例子:假設有兩個線程,A線程(時間上)先調用了setValue(100),然后B線程調用了同一個對象的getValue(),則B線程收到的返回值可能為0也可能為100
```java
private int value = 0;
public void setValue(int value) {
this.value = value;
}
public int getValue() {
return value;
}
```
以上例子,根據先行發生原則進行分析:
- 不在一個線程中,不符合**程序次序規則**
- 沒有同步塊,不符合**管程鎖定規則**
- value 字段沒有被 volatile 修飾,不符合**volatile 變量規則**
- 和 **線程啟動規則**、**線程終止規則**、**線程中斷規則**、**對象終結規則** 沒關系
- 沒有先行發生原則 ,因此不符合**傳遞性規則**
保證線程安全的方案:
- 將 setValue 方法與 getValue 方法用 synchronized 修飾
- 或者將 value 字段使用 volatile 修飾
> 判斷并發安全問題的時候,不要受時間順序干擾,一切必須以**先行發生原則**為準
----
## 7 附錄 - volatile 變量的實現原理
volatile的兩條實現規則為:
- lock前綴指令會引起處理器緩存寫回到內存
- 一個處理器的緩存回寫到內存會導致其他處理器的緩存無效
如果對volatile變量執行寫操作,JVM會向處理器發送一條lock前綴的指令,將這個變量所在緩存行的數據寫回到系統內存;并且在多處理器間實現緩存一致性協議,當處理器感知緩存行對應的內存地址被修改,就會將當前處理器的緩存行設置成無效狀態
<pre>
instance = new Singletion(); // instance 是 volatile 變量
// 轉為匯編代碼
0x01a3de1d: movb $0×0,0×1104800(%esi);0x01a3de24: <b>lock</b> addl $0×0,(%esp);
</pre>
> CPU 的術語定義
術語 | 英文 | 描述
---- | ---- | ----
內存屏障 | memory barriers | 一組處理器**指令**,用于實現對內存操作的**順序限制**
緩沖行 | cache line | 緩存中可以分配的最小存儲單位。處理器填寫緩沖線時會加載整個緩存線,需要使用多個主內存讀周期
原子操作 | atomic operations | 不可中斷的一個或一系列操作
緩存行填充 | cache line fill | 當處理器識別到從內存中讀取操作數是可緩存的,處理器讀取整個緩存行到適當的緩存(L1, L2, L3或所有)
緩存命中 | cache hit | 如果進行告訴緩存行填充操作的內存位置仍然是下次處理器訪問的地址時,處理器從**緩存**中讀取操作數,而不是從內存讀取
寫命中 | write hit | 當處理器將操作數寫回到一個內存緩存的區域時,它首先會檢查這個緩存的內存地址是否在緩存行中。如果存在一個有效的緩存行,則處理器將這個操作數寫回到緩存,而不是寫回到內存,這個操作稱為寫命中
寫缺失 | write miss the cache | 一個有效的緩存行被寫入到不存在的內存區域
----
**volatile與緩存行填充優化**:
- JDK 7 的LinkedTransferQueue在使用volatile變量時,通過追加15個變量將(加上private volatile V value)對象的占用變為64字節(JDK 8 可以使用`@sun.misc.Contended`來填充緩存行),以提高并發編程效率
> 因為英特爾酷睿i7、酷睿、Atom和NetBurst,以及Core Solo和Pentium M處理器的L1、L2或L3緩存的高速緩存行是64個字節寬,不支持部分填充緩存行;如果LinkedTransferQueue的頭結點和尾結點都不足64字節,處理器會將它們讀到同一個高速緩存行;假如一個處理器試圖修改頭結點,則會將整個緩存行鎖定,導致其他處理器不能訪問自己高速緩存中的尾結點,嚴重影響LinkedTransferQueue的出隊和入隊操作
- 以下兩種場景不應該使用緩存行填充:**緩存行非64字節寬的處理器;共享變量不會被頻繁地寫**
----
** `volatile + CAS` 構成了 [Java并發包](http://wiki.baidu.com/pages/viewpage.action?pageId=1654188471) 的基石**
- 底層:volatile變量的讀/寫 + CAS(Unsafe類)
- 中層:AQS + 非阻塞數據結構 + 原子變量類
- 上層:Lock + 同步器 + 阻塞隊列 + Executor + 并發容器
## 8 附錄 - synchronized 域
**synchronized 的用法**
Java 中的每一個對象都可以作為鎖 —— 這是 synchronized 實現同步的基礎,具體表現為:
```java
static class A {
synchronized void m1(String key, Object value) { // 對于普通方法,鎖是 A.this
}
static synchronized void put(Map<String, Object> map, String key, Object value) { // 對于靜態方法,鎖是 A.class
}
static void get(Map<String, Object> map, String key) {
synchronized (map) { // 對于同步方法塊,鎖是 map
}
}
}
```
-----
**synchronized 的實現**
JVM 基于進入和退出Monitor對象來實現方法同步和代碼塊同步
- 代碼塊是使用monitorenter和monitorexit指令實現(monitorenter指令在編譯后插入到同步塊的開始位置,monitorexit插入到方法結束處和異常處)
- 方法同步也以使用monitorenter和monitorexit指令實現,但是JVM規范里沒有詳細說明
任何對象都有一個monitor,當一個monitor被持有后,將處于鎖定狀態;以下是對象頭的結構(數組類型使用3字寬(Word),非數組使用2字寬,32位虛擬機中,1字寬等于32bit)
- `Mark Word` 占1字寬,存儲對象的hashCode和鎖信息
- `Class Metadata Address` 占1字寬,存儲對象類型數據的指針
- `Array Length` 占1字寬(僅數組類型),存儲數組的長度
> Mark Word 的存儲結構
<pre style="font-family: 'Courier New','MONACO'">
鎖狀態 | 23bit | 2bit | 4bit | 1bit是否為偏向鎖 | 2bit 鎖標志位
--------------------------------------------------------------------------------------------------------------------------
無鎖狀態 | 對象的hashCode (25bit) | 對象的分代年齡 (4bit) | 0 (1bit) | 01 (2bit)
偏向鎖 | 線程ID (23bit) | Epoch (2bit) | 對象分代年齡 (4bit) | 1 (1bit) | 01 (2bit)
輕量級鎖 | 指向棧中鎖記錄的指針 (30bit) | 00 (2bit)
重量級鎖 | 執行互斥量(重量級鎖)的指針 (30bit) | 10 (2bit)
GC 標記 | 空 | 11 (2bit)
</pre>
-----
Java SE 1.6 為了減少獲得鎖和釋放鎖帶來的性能損耗,引入了`偏向鎖` 和 `輕量級鎖`,鎖的4種狀態會鎖著競爭情況而不斷升級(不能降級):無鎖、偏向鎖、輕量級鎖、重量級鎖
> 4種鎖狀態的優缺點對比
鎖狀態 | 優點 | 缺點 | 適用場景
---- | ---- | ---- | ----
偏向鎖 | 加鎖和解鎖不需要額外的消耗,和執行非同步方法相比僅存在納秒級的差距 | 如果線程間存在鎖競爭,會帶來額外的**鎖撤銷**的消耗 | 適用于只有一個線程訪問同步塊的場景
輕量級鎖 | 競爭的線程不會阻塞,提高了程序的響應速度 | 如果始終得不到鎖競爭的線程,使用**自旋**會消耗 CPU | 追求響應時間,同步塊執行速度非常塊
重量級鎖 | 線程競爭不使用自旋,不會消耗CPU | 線程阻塞,響應時間緩慢 | 追求吞吐量,同步塊執行時間較長
## 9 附錄 - 原子操作的實現原理
原子操作(atomic operation)表示不可中斷的一個或一系列操作
**處理器實現原子操作**
> CPU 術語定義
處理器提供總線鎖定和緩存鎖定兩個機制來保證復雜內存操作的原子性
- 總線鎖定:使用處理器提供的一個`lock#`信號,當一個處理器在總線上輸出此信號時,其他處理器的請求將被阻塞住,此時該處理器可以獨占共享內存
- 緩存鎖定:內存區域如果被緩存在處理器的緩存行中,并且在lock操作期間被鎖定,那么當它執行鎖操作寫回到內存時,處理器不在總線上聲明`lock#`信號,而是修改內部的內存地址,使緩存行無效
- 當操作的數據不能被緩存在處理器內部,或操作的數據跨多個緩存行時,處理器會使用總線鎖定
- 當處理器不支持緩存鎖定時,會調用總線鎖定
**Java 實現原子操作**
在 Java 中通過鎖或循環CAS來實現原子操作。CAS 存在三大問題
- ABA 問題(通過版本號解決)
- 循環時間長開銷大
- 只能保證一個共享變量的原子操作(通過將多種狀態用各個bit位表示來解決)
- 空白目錄
- 精簡版Spring的實現
- 0 前言
- 1 注冊和獲取bean
- 2 抽象工廠實例化bean
- 3 注入bean屬性
- 4 通過XML配置beanFactory
- 5 將bean注入到bean
- 6 加入應用程序上下文
- 7 JDK動態代理實現的方法攔截器
- 8 加入切入點和aspectj
- 9 自動創建AOP代理
- Redis原理
- 1 Redis簡介與構建
- 1.1 什么是Redis
- 1.2 構建Redis
- 1.3 源碼結構
- 2 Redis數據結構與對象
- 2.1 簡單動態字符串
- 2.1.1 sds的結構
- 2.1.2 sds與C字符串的區別
- 2.1.3 sds主要操作的API
- 2.2 雙向鏈表
- 2.2.1 adlist的結構
- 2.2.2 adlist和listNode的API
- 2.3 字典
- 2.3.1 字典的結構
- 2.3.2 哈希算法
- 2.3.3 解決鍵沖突
- 2.3.4 rehash
- 2.3.5 字典的API
- 2.4 跳躍表
- 2.4.1 跳躍表的結構
- 2.4.2 跳躍表的API
- 2.5 整數集合
- 2.5.1 整數集合的結構
- 2.5.2 整數集合的API
- 2.6 壓縮列表
- 2.6.1 壓縮列表的結構
- 2.6.2 壓縮列表結點的結構
- 2.6.3 連鎖更新
- 2.6.4 壓縮列表API
- 2.7 對象
- 2.7.1 類型
- 2.7.2 編碼和底層實現
- 2.7.3 字符串對象
- 2.7.4 列表對象
- 2.7.5 哈希對象
- 2.7.6 集合對象
- 2.7.7 有序集合對象
- 2.7.8 類型檢查與命令多態
- 2.7.9 內存回收
- 2.7.10 對象共享
- 2.7.11 對象空轉時長
- 3 單機數據庫的實現
- 3.1 數據庫
- 3.1.1 服務端中的數據庫
- 3.1.2 切換數據庫
- 3.1.3 數據庫鍵空間
- 3.1.4 過期鍵的處理
- 3.1.5 數據庫通知
- 3.2 RDB持久化
- 操作系統
- 2021-01-08 Linux I/O 操作
- 2021-03-01 Linux 進程控制
- 2021-03-01 Linux 進程通信
- 2021-06-11 Linux 性能優化
- 2021-06-18 性能指標
- 2022-05-05 Android 系統源碼閱讀筆記
- Java基礎
- 2020-07-18 Java 前端編譯與優化
- 2020-07-28 Java 虛擬機類加載機制
- 2020-09-11 Java 語法規則
- 2020-09-28 Java 虛擬機字節碼執行引擎
- 2020-11-09 class 文件結構
- 2020-12-08 Java 內存模型
- 2021-09-06 Java 并發包
- 代碼性能
- 2020-12-03 Java 字符串代碼性能
- 2021-01-02 ASM 運行時增強技術
- 理解Unsafe
- Java 8
- 1 行為參數化
- 1.1 行為參數化的實現原理
- 1.2 Java 8中的行為參數化
- 1.3 行為參數化 - 排序
- 1.4 行為參數化 - 線程
- 1.5 泛型實現的行為參數化
- 1.6 小結
- 2 Lambda表達式
- 2.1 Lambda表達式的組成
- 2.2 函數式接口
- 2.2.1 Predicate
- 2.2.2 Consumer
- 2.2.3 Function
- 2.2.4 函數式接口列表
- 2.3 方法引用
- 2.3.1 方法引用的類別
- 2.3.2 構造函數引用
- 2.4 復合方法
- 2.4.1 Comparator復合
- 2.4.2 Predicate復合
- 2.4.3 Function復合
- 3 流處理
- 3.1 流簡介
- 3.1.1 流的定義
- 3.1.2 流的特點
- 3.2 流操作
- 3.2.1 中間操作
- 3.2.2 終端操作
- 3.3.3 構建流
- 3.3 流API
- 3.3.1 flatMap的用法
- 3.3.2 reduce的用法
- 3.4 collect操作
- 3.4.1 collect示例
- 3.4.2 Collector接口