
# 備份和恢復
## 79\. 概述
備份和還原是許多數據庫提供的標準操作。有效的備份和還原策略有助于確保用戶可以在發生意外故障時恢復數據。 HBase備份和還原功能有助于確保使用HBase作為規范數據存儲庫的企業可以從災難性故障中恢復。另一個重要功能是能夠將數據庫還原到特定時間點,通常稱為快照。
HBase備份和還原功能可以在HBase集群中的表上創建完整備份和增量備份。完整備份是應用增量備份以構建不同版本快照的基礎。可以按計劃運行增量備份以捕獲隨時間的變化,例如通過使用Cron任務。增量備份比完全備份更具成本效益,因為它們僅捕獲自上次備份以來的更改,并且還使管理員能夠將數據庫還原到任何先前的增量備份。此外,如果你不想進行整個數據集備份和恢復,該機制也支持啟用表級數據備份和恢復。
備份和還原功能是對HBase復制功能的補充。雖然HBase復制非常適合創建數據的“熱”副本(復制數據可立即用于查詢),但備份和恢復功能非常適合創建“冷”數據副本(必須手動來恢復系統)。用戶以前只能通過ExportSnapshot功能創建完整備份。增量備份實現是對ExportSnapshot提供的備份功能的改進。
備份和還原功能使用DistCp在群集之間傳輸文件。 [HADOOP-15850](https://issues.apache.org/jira/browse/HADOOP-15850)修復了一個CopyCommitter#concatFileChunks無條件地嘗試將正在DistCp傳輸的文件都拼接起來,拷貝到目標集群(盡管文件是獨立的)的bug。如果沒有[HADOOP-15850](https://issues.apache.org/jira/browse/HADOOP-15850)的修復,拷貝會失敗。以下是能正確支持備份和恢復功能的hadoop版本。
* 2.7.x
* 2.8.x
* 2.9.2+
* 2.10.0+
* 3.0.4+
* 3.1.2+
* 3.2.0+
* 3.3.0+
## 80\. 術語
備份和還原功能引入了新術語,可用于了解系統控制流。
* _A backup_: 數據和元數據的邏輯單元,可以將表恢復到特定時間點的狀態。
* _Full backup_: 一種備份類型,完整包含某個時間點表的所有內容。
* _Incremental backup_: 一種備份類型,包含自上一次完整備份以來表中的所有更改內容。
* _Backup set_: 一個用戶定義的名稱,用來表示一個或多個可以執行備份操作的表。
* _Backup ID_: 一個唯一的名稱,用于標識一份備份,例如: `backupId_1467823988425`。
## 81\. 規劃
有一些常用策略可用于在你的環境中實現備份和還原。以下部分將展示這些策略的實現方式和內在權衡。
>此備份和還原工具尚未在啟用透明數據加密(TDE)的HDFS群集上進行測試。這與未決問題[HBASE-16178](https://issues.apache.org/jira/browse/HBASE-16178)有關。
### 81.1\. 集群內備份
此策略將備份數據存儲在備份源的集群上。這種方法僅適用于測試,因為它不會為集群提供任何額外的安全性。
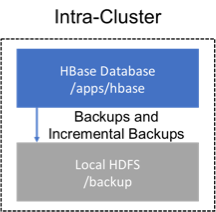Figure 4\. 集群內備份
### 81.2\. 使用專用集群備份
此策略提供更高的容錯能力,并提供了一條災難恢復途徑。在此設置中,您將備份存儲在單獨的HDFS群集上,方法是將備份目標群集的HDFS URL提供給備份實用程序。您應該考慮備份到不同的物理位置,例如不同的數據中心。
通常備份專用HDFS集群會使用更經濟的硬件配置來節省資金。
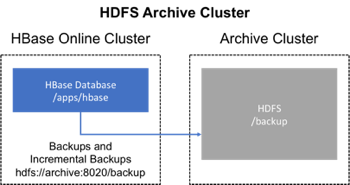Figure 5\. 專用HDFS備份集群
### 81.3\. 備份到云或存儲設備供應商
保護HBase增量備份的另一種方法是將數據存儲在屬于第三方供應商且異地的安全服務器上。供應商可以是公共云提供商或使用Hadoop文件系統兼容的存儲供應商,例如S3和其他與HDFS兼容的系統。
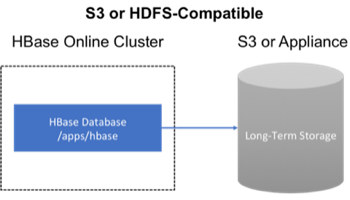Figure 6\. 備份到云或存儲設備供應商
> HBase備份應用程序不支持備份到多個目標。解決方法是從HDFS或S3手動創建備份文件的副本。
## 82\. 首次配置步驟
本節包含使用備份和還原功能的必要配置。由于此功能大量使用YARN的MapReduce框架來并行化這些I / O繁重的操作,因此配置更改擴展到了`hbase-site.xml`之外。
### 82.1\. 在YARN中授權“hbase”系統用戶
YARN **container-executor.cfg** 配置文件必須具有以下屬性設置:_allowed.system.users =hbase_。此配置文件的條目中不允許有空格。
> 跳過此步驟將導致執行備份任務時發生運行時錯誤。
**與備份和恢復功能有關的的有效container-executor.cfg文件的示例如下:**
```
yarn.nodemanager.log-dirs=/var/log/hadoop/mapred
yarn.nodemanager.linux-container-executor.group=yarn
banned.users=hdfs,yarn,mapred,bin
allowed.system.users=hbase
min.user.id=500
```
### 82.2\. HBase相關更改
將以下屬性添加到hbase-site.xml里并重新啟動HBase(如果它已在運行)。
> “,...”是一個省略號,意味著這是一個以逗號分隔的值列表,而不是應該添加到hbase-site.xml的文本文本。
```
<property>
<name>hbase.backup.enable</name>
<value>true</value>
</property>
<property>
<name>hbase.master.logcleaner.plugins</name>
<value>org.apache.hadoop.hbase.backup.master.BackupLogCleaner,...</value>
</property>
<property>
<name>hbase.procedure.master.classes</name>
<value>org.apache.hadoop.hbase.backup.master.LogRollMasterProcedureManager,...</value>
</property>
<property>
<name>hbase.procedure.regionserver.classes</name>
<value>org.apache.hadoop.hbase.backup.regionserver.LogRollRegionServerProcedureManager,...</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.backup.BackupObserver,...</value>
</property>
<property>
<name>hbase.master.hfilecleaner.plugins</name>
<value>org.apache.hadoop.hbase.backup.BackupHFileCleaner,...</value>
</property>
```
## 83\. 備份和恢復指令
這包括管理員用于創建,恢復和合并備份的命令行機制。有關檢查特定備份會話詳細信息的工具將在下一節[備份映像管理](#br.administration)中介紹。
運行命令`hbase backup help <command>`可以查看有關命令及其選項的基本信息。下面涉及到的信息都可以在對應命令幫助消息中找到。
### 83.1\. 創建一個備份鏡像
| |
對于也使用Apache Phoenix的HBase集群:在備份中包含SQL系統目錄表。如果需要恢復HBase備份,則可以通過訪問系統目錄表來恢復Phoenix與已還原數據的互操作性。
|
運行備份和還原程序的第一步是執行完全備份,并將數據存儲在與源不同的映像中。至少,您必須執行此操作才能獲得基準,然后才能依賴增量備份。
以HBase超級用戶身份運行以下命令:
```
hbase backup create <type> <backup_path>
```
命令完成運行后,控制臺將顯示SUCCESS或FAILURE狀態消息。 SUCCESS消息包括 _backup\_ID_ 。備份ID是HBase master從客戶端收到備份請求的Unix時間(也稱為Epoch時間)。
| |
記錄成功備份結束時顯示的備份ID。一旦源群集出現故障并且您需要使用恢復操作恢復數據集,此時如果有備份ID則可以節省時間。
|
#### 83.1.1\. 位置命令行參數
_type_
要執行的備份類型:_full_或 _incremental_。提醒一下,_incremental_ 備份需要 _full_ 備份才能存在。
_backup\_path_
_backup\_path_ 參數指定存儲備份映像的位置的完整文件系統URI。有效前綴為 _hdfs:_, _webhdfs:_, _s3a:_或其他兼容的Hadoop文件系統實現。
#### 83.1.2\. 命名命令行參數
_-t <table_name[,table_name]>_
要備份的以逗號分隔的表列表。如果未指定表,則備份所有表。不支持正則表達式或通配符;必須明確列出所有表名。有關對表集合執行操作的更多信息,請參見[備份集](#br.using.backup.sets)。與 _-s_ 選項互斥;二者之間必須選一個。
_-s <backup_set_name>_
根據備份集確定要備份的表。有關備份集的用途和用法,請參閱[使用備份集](#br.using.backup.sets)。與 _-t_ 選項互斥。
_-w <number_workers>_
(可選)指定將數據復制到備份目標的并行工作線程數。備份當前是由MapReduce作業執行的,因此該值也對應于作業將生成的Mapper數。
_-b <bandwidth_per_worker>_
(可選)指定每個工作線程的帶寬,以MB/秒為單位。
_-d_
可選)啟用“DEBUG”模式,該模式打印有關備份創建的其他日志記錄。
_-q <name>_
(可選)指定執行創建備份的MapReduce作業的YARN隊列的名稱。此選項有助于防止備份任務與其他高優先級MapReduce作業中競爭資源。
#### 83.1.3\. 用法示例
```
$ hbase backup create full hdfs://host5:8020/data/backup -t SALES2,SALES3 -w 3
```
此命令在路徑 _/data/backup_ 中的NameNode為host5:8020的HDFS實例中創建兩個表SALES2和SALES3的完整備份映像。 _-w_ 選項指定不超過三個并行工作完成操作。
### 83.2\. 從一個備份鏡像中恢復
以HBase超級用戶身份運行以下命令。您只能在正在運行的HBase集群上恢復備份,因為必須將數據重新分發到RegionServers才能成功完成操作。
```
hbase restore <backup_path> <backup_id>
```
#### 83.2.1\. 位置命令參數
_backup_path_
_backup\_path_ 參數指定存儲備份映像的位置的完整文件系統URI。有效前綴為 _hdfs:_, _webhdfs:_, _s3a:_或其他兼容的Hadoop文件系統實現。
_backup_id_
唯一標識要還原的備份映像的備份ID。
#### 83.2.2\. 命名命令參數
_-t <table_name[,table_name]>_
要恢復的以逗號分隔的表列表。有關對表集合執行操作的更多信息,請參見[備份集](#br.using.backup.sets)。與 _-s_ 選項互斥;二者之間必須選一個。
_-s <backup_set_name>_
根據備份集確定要備份的表。有關備份集的用途和用法,請參閱[使用備份集](#br.using.backup.sets)。與 _-t_ 選項互斥。
_-q <name>_
(可選)指定執行創建備份的MapReduce作業的YARN隊列的名稱。此選項有助于防止備份任務與其他高優先級MapReduce作業中競爭資源。
_-c_
(可選)執行還原的模擬運行。只執行檢查操作,但不執行。
_-m <target_tables>_
(可選)要還原的以逗號分隔的表列表。如果未提供此選項,則使用原始表名。提供此選項時,必須提供與`-t`選項中相同數量的條目。
_-o_
(可選)指定對于要還原的目標表,如果存在,則執行覆蓋操作。
#### 83.2.3\. 用法示例
```
hbase restore /tmp/backup_incremental backupId_1467823988425 -t mytable1,mytable2
```
此命令恢復增量備份映像的兩個表。在此示例中:? `/tmp/backup_incremental`是包含備份映像的目錄的路徑。 ? `backupId_1467823988425`是備份ID。 ? `mytable1`和`mytable2`是要恢復的備份映像中的表的名稱。
### 83.3\. 合并增量備份映像
此命令可用于將兩個或多個增量備份映像合并為單個增量備份映像。這可用于將多個小型增量備份映像合并為一個較大的增量備份映像。此命令可用于將每小時增量備份合并到每日增量備份映像中,或每日增量備份合并到每周增量備份中。
```
$ hbase backup merge <backup_ids>
```
#### 83.3.1\. 位置命令參數
_backup_ids_
以逗號分隔的增量備份鏡像ID列表,這些ID將合并到單個鏡像中。
#### 83.3.2\. 命名命令參數
無。
#### 83.3.3\. 用法示例
```
$ hbase backup merge backupId_1467823988425,backupId_1467827588425
```
### 83.4\. 使用備份集
備份集可以通過減少表名重復輸入的數量來簡化HBase數據備份和還原的管理。您可以使用`hbase backup set add`命令將表分組到命名備份集中。然后,您可以使用`-set`選項在`hbase backup create`或`hbase restore`中調用備份集的名稱,而不是單獨列出組中的每個表。您可以擁有多個備份集。
>注意`hbase backup set add`命令和 _-set_ 選項之間的區別。必須先運行`hbase backup set add`命令,然后才能在其他命令中使用`-set`選項,因為在將備份集用作快捷方式之前,必須先命名和定義備份集。
如果運行`hbase backup set add`命令并指定系統上尚不存在的備份集名稱,則會創建一個新集。如果運行具有現有備份集名稱的命令的命令,則指定的表將添加到該集合中。
在此命令中,備份集名稱區分大小寫。
>備份集的元數據存儲在HBase中。如果您無法訪問具有備份集元數據的原始HBase集群,則必須指定單個表名以還原數據。
要創建備份集,請以HBase超級用戶身份運行以下命令:
```
$ hbase backup set <subcommand> <backup_set_name> <tables>
```
#### 83.4.1\. 備份集子命令
以下列表詳細介紹了hbase backup set命令的子命令。
>在hbase備份集設置完成操作后,您必須輸入以下子命令中的一個(且不超過一個)。此外,備份集名稱在命令行程序中是區分大小寫的。
_add_
將表[s]添加到備份集。在此參數后面指定 _backup_set_name_值以創建備份集。
_remove_
從集中刪除表。在tables參數中指定要刪除的表。
_list_
列出所有備份集。
_describe_
顯示備份集的描述信息。包括該集合是具有完整備份還是增量備份,備份的開始和結束時間以及集合中的表列表。此子命令必須為 _backup\_set\_name_ 指定一個有效值。
_delete_
刪除備份集。在`hbase backup set delete`命令后直接輸入 _backup\_set\_name_ 選項的值。
#### 83.4.2\. 位置命令參數
_backup_set_name_
用于分配或執行操作的備份集名稱。備份集名稱必須僅包含可打印字符,并且不能包含任何空格。
_tables_
要包含在備份集中的表(或單個表)的列表。輸入表名是以逗號作為分隔符的列表。如果未指定表,則所有表都包含在集中。
>保存好備份集名稱以及其在遠程集群上相應的表列表和備份策略。如果主群集出現故障,這些信息可以幫助您。
#### 83.4.3\. 用法示例
```
$ hbase backup set add Q1Data TEAM3,TEAM_4
```
根據環境的不同,此命令將導致以下一項操作:
* 如果`Q1Data`備份集不存在,則創建包含表`TEAM_3`和`TEAM_4`的備份集。
* 如果`Q1Data`備份集已經存在,表`TEAM_3`和`TEAM_4`將被添加到`Q1Data`備份集。
## 84\. 備份鏡像管理
`hbase backup`命令有幾個子命令,可以幫助管理備份映像。大多數生產環境都需要重復備份,因此必須使用工具程序來幫助管理備份存儲庫的數據。通過某些子命令,您可以查找有助于識別與搜索特定數據相關的備份的信息。您還可以刪除備份映像。
以下列表詳細介紹了可以幫助管理備份的每個`hbase backup子命令`。以HBase超級用戶身份運行完整的命令-子命令行。
### 84.1\. 管理備份進度
您可以通過運行 _hbase backup progress_命令并將備份ID指定為參數來監視另一個終端會話中正在運行的備份。
例如,以hbase超級用戶身份運行以下命令以查看備份進度
```
$ hbase backup progress <backup_id>
```
#### 84.1.1\. 位置命令行參數
_backup_id_
通過查看進度信息指定要監視的備份。 backupId區分大小寫。
#### 84.1.2\. 命名命令行參數
None.
#### 84.1.3\. 用法示例
```
hbase backup progress backupId_1467823988425
```
### 84.2\. 管理備份歷史記錄
此命令顯示備份會話的日志。每個會話的信息包括備份ID,類型(完整或增量),備份中的表,狀態以及開始和結束時間。使用可選的-n參數指定要顯示的備份會話數。
```
$ hbase backup history <backup_id>
```
#### 84.2.1\. 位置命令行參數
_backup_id_
通過查看進度信息指定要監視的備份。 backupId區分大小寫。
#### 84.2.2\. 命令命令行參數
_-n <num_records>_
(可選)最大備份記錄數(默認值:10)。
_-p <backup_root_path>_
存儲備份映像的完整文件系統URI。
_-s <backup_set_name>_
要獲取其歷史記錄的備份集的名稱。與 _-t_ 選項互斥。
_-t_ <table_name>
獲取歷史記錄的表的名稱。與 _-s_ 選項互斥。
#### 84.2.3\. 用法示例
```
$ hbase backup history
$ hbase backup history -n 20
$ hbase backup history -t WebIndexRecords
```
### 84.3\. 描述備份映像
此命令可用于獲取有關特定備份映像的信息。
```
$ hbase backup describe <backup_id>
```
#### 84.3.1\. 位置命令行參數
_backup_id_
要描述的備份映像的ID。
#### 84.3.2\. 命名命令行參數
None.
#### 84.3.3\. 用法示例
```
$ hbase backup describe backupId_1467823988425
```
### 84.4\. 刪除備份映像
此命令可用于刪除不再需要的備份映像。
```
$ hbase backup delete <backup_id>
```
#### 84.4.1\. 位置命令行參數
_backup_id_
應刪除備份映像的ID。
#### 84.4.2\. 命名命令行參數
None.
#### 84.4.3\. 用法示例
```
$ hbase backup delete backupId_1467823988425
```
### 84.5\. 備份修復命令
此命令嘗試更正由于軟件錯誤或未處理的故障情況而存在的持久備份元數據中的任何不一致。雖然備份實現嘗試自行更正所有錯誤,但在系統無法自動恢復的情況下,此工具可能是必需的。
```
$ hbase backup repair
```
#### 84.5.1\. 位置命令行參數
None.
### 84.6\. 命名命令行參數
None.
#### 84.6.1\. 用法示例
```
$ hbase backup repair
```
## 85\. 配置鍵
備份和還原功能包括必需和可選配置鍵。
### 85.1\. 必需的屬性
_hbase.backup.enable_ :控制是否啟用該功能(默認值:`false`)。將此值設置為`true`。
_hbase.master.logcleaner.plugins_ :清除HBase Master中的日志時調用的逗號分隔的類列表。將此值設置為`org.apache.hadoop.hbase.backup.master.BackupLogCleaner`或將其附加到當前值。
_hbase.procedure.master.classes_ :用Master中的Procedure框架調用的逗號分隔的類列表。將此值設置為`org.apache.hadoop.hbase.backup.master.LogRollMasterProcedureManager`或將其附加到當前值。
_hbase.procedure.regionserver.classes_ :使用RegionServer中的Procedure框架調用的逗號分隔的類列表。將此值設置為`org.apache.hadoop.hbase.backup.regionserver.LogRollRegionServerProcedureManager`或將其附加到當前值。
_hbase.coprocessor.region.classes_ :在表上部署的以逗號分隔的RegionObservers列表。將此值設置為`org.apache.hadoop.hbase.backup.BackupObserver`或將其附加到當前值。
_hbase.master.hfilecleaner.plugins_ :部署在Master上的以逗號分隔的HFileCleaners列表。將此值設置為`org.apache.hadoop.hbase.backup.BackupHFileCleaner`或將其附加到當前值。
### 85.2\. 可選屬性
_hbase.backup.system.ttl_ :`hbase:backup`表中數據的生存時間(以秒為單位)(默認值:永久)。此屬性僅在創建`hbase:backup`表之前有效。當此表已存在時,使用HBase shell中的`alter`命令修改TTL。有關此配置屬性的影響的更多詳細信息,請參見下面的[部分](#br.filesystem.growth.warning)。
_hbase.backup.attempts.max_ :做hbase表快照時嘗試執行的次數(默認值:10)。
_hbase.backup.attempts.pause.ms_ :重試快照時需要等待的時間(以毫秒為單位)(默認值:10000)。
_hbase.backup.logroll.timeout.millis_ :等待RegionServers在Master的過程框架中執行WAL滾動的時間(以毫秒為單位)(默認值:30000)。
## 86\. 最佳做法
### 86.1\. 制定恢復策略并對其進行測試
在依賴生產環境的備份和還原策略之前,必須演練如何執行備份,更重要的是,必須演練如何還原。測試該策略以確保其可行。至少,能把生產集群的數據存儲備份到不同集群或服務器上的。要進一步保護數據,請使用位于不同物理位置的備份位置。
如果由于計算機系統問題導致主生產集群上的數據丟失不可恢復,則可以從同一站點的其他集群或服務器還原數據。然而,破壞整個站點的災難使本地存儲的備份變得毫無用處。考慮存儲備份數據和必要資源(計算能力和操作員專業知識),以便在遠離生產站點的站點恢復數據。如果在整個主要站點(火災,地震等)發生災難,遠程備份站點可能非常有價值。
### 86.2\. 首先保護完整備份映像
作為基準,您必須至少完成一次HBase數據的完整備份,然后才能依賴增量備份。完整備份應存儲在源集群之外。要確保完整的數據集恢復,必須使用還原基準完全備份選項運行還原實用程序。完整備份是數據集的基礎。在還原操作期間,將在完全備份的基礎上應用增量備份數據,以使您返回上次執行備份的時間點。
### 86.3\. 為作為整個數據集的邏輯子集的表組定義和使用備份集
您可以將表分組到稱為備份集的對象中。當您有一組特定的表,您希望重復備份或還原時,備份集可以節省時間。
創建備份集時,鍵入要包括在組中的表名。備份集不僅包括相關表組,還包含HBase備份元數據。然后,您可以使用備份集名稱以指示對哪些表執行命令,而不用輸入所有表名。
### 86.4\. 記錄備份和還原策略,理想情況下記錄有關每個備份的信息
記錄整個過程,以便知識庫可以在員工離職后轉移給新的管理員。作為額外的安全預防措施,還要記錄日期,時間以及有關每個備份數據的其他相關詳細信息。在源群集發生故障或主站點災難的情況下,此元數據可能有助于查找特定數據集。給所有文檔維護重復副本:生產集群站點的一個副本和備份位置的或管理員從生產集群遠程訪問的任何位置一個副本。
## 87\. 場景:在Amazon S3上保護應用程序數據集
此業務情景描述了假設的零售業務如何使用備份來保護應用程序數據,然后在故障后恢復數據集。
HBase管理團隊使用備份集來存儲來自一組表的數據,這些表具有名為green的應用程序的相關信息。在此示例中,一個表包含事務記錄,另一個表包含客戶詳細信息。需要備份這兩個表并將其作為一個組進行恢復。
管理團隊還希望確保自動進行每日備份。
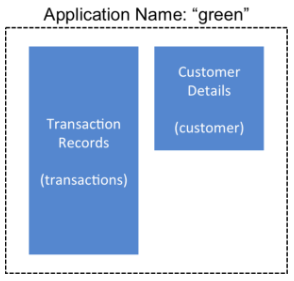圖 7\. 備份集中的表
以下是用于備份 _green_ 應用程序的數據并稍后恢復數據的命令步驟和示例的大綱。所有命令需要以HBase超級用戶身份運行。
* 創建名為 _green_set_ 的備份集作為事務表和客戶表的別名。備份集可用于所有操作,以避免鍵入每個表名。備份集名稱區分大小寫,應僅使用可打印字符且不帶空格。
```
$ hbase backup set add green_set transactions
$ hbase backup set add green_set customer
```
* green_set數據的第一個備份必須是完整備份。以下命令示例顯示如何將憑據傳遞到Amazon S3并指定文件系統使用s3a:前綴。
```
$ ACCESS_KEY=ABCDEFGHIJKLMNOPQRST
$ SECRET_KEY=123456789abcdefghijklmnopqrstuvwxyzABCD
$ sudo -u hbase hbase backup create full\
s3a://$ACCESS_KEY:SECRET_KEY@prodhbasebackups/backups -s green_set
```
* 應根據計劃運行增量備份,以確保在發生災難時進行必要的數據恢復。在這家零售公司,HBase管理團隊決定自動每日備份可以充分保護數據。團隊決定通過修改`/etc/crontab`中定義的現有Cron作業來實現此目的。因此,IT通過添加以下行來修改Cron作業:
```
@daily hbase hbase backup create incremental s3a://$ACCESS_KEY:$SECRET_KEY@prodhbasebackups/backups -s green_set
```
* 災難性IT事件導致green應用程序的生產集群不可用。備份群集的HBase系統管理員必須將 _green _set_數據集還原到最接近恢復目標的時間點。
> 如果備份HBase群集的管理員具有可訪問記錄中具有相關詳細信息的備份ID,則可以繞過以下使用`hdfs dfs -ls`命令進行的搜索并手動掃描備份ID列表。請考慮在環境中的生產集群外部持續維護和保護備份ID的詳細日志。
HBase管理員在存儲備份的目錄上運行以下命令,以在控制臺上打印成功備份ID的列表:
```
`hdfs dfs -ls -t /prodhbasebackups/backups`
```
* 管理員掃描列表以查看在最接近恢復目標的日期和時間創建了哪個備份。為此,管理員將恢復時間點的日歷時間戳轉換為Unix時間,因為備份ID是用Unix時間唯一標識的。備份ID按反向時間順序列出,這意味著最先出現的最新成功備份。
管理員注意到命令輸出中的以下行與需要恢復的 _green_set_ 備份相對應:
```
/prodhbasebackups/backups/backup_1467823988425`
```
* 管理員恢復green_set調用備份ID和-overwrite選項。 -overwrite選項會刪除目標集群中的所有現有數據,并使用備份數據集中的數據填充表。如果沒有此標志,備份數據將附加到目標中的現有數據。在當前情況下,管理員決定覆蓋數據,因為它已損壞。
```
$ sudo -u hbase hbase restore -s green_set \
s3a://$ACCESS_KEY:$SECRET_KEY@prodhbasebackups/backups backup_1467823988425 \ -overwrite
```
## 88\. 備份數據的安全性
利用此功能可以將數據復制到遠程位置,需要花些時間思考數據安全性問題。與HBase復制功能一樣,備份和還原提供了將數據從公司內自動復制到公司外的某個系統的能力。在做敏感數據備份和恢復功能時,除了從HBase中提取數據,還有發送數據的位置都經過安全審核以確保只允許經過身份驗證的用戶訪問該數據時,這一點非常重要。
例如,上述示例將數據備份到S3,最重要的是將適當的權限分配給S3存儲桶以確保僅允許最小的一組授權用戶訪問該數據。由于不再通過HBase訪問數據及其身份驗證和授權控制,因此我們必須確保存儲該數據的文件系統提供相當級別的安全性。這是用戶 **必須** 自行實施的手動步驟。
## 89\. 增量備份和還原的技術細節
與之前嘗試使用串行備份和還原解決方案(例如僅使用HBase導出和導入API的方法)相比,HBase增量備份可以更有效地捕獲HBase表映像。增量備份使用“預寫日志”(WAL)來捕獲自上次備份創建以來的數據更改。在所有RegionServers上執行WAL roll(創建新的WAL)以跟蹤需要在備份中的WAL。
創建增量備份映像后,源備份文件通常與數據源位于同一節點上。類似于DistCp(分布式拷貝)工具的進程會將源備份文件移動到目標文件系統。當表恢復操作開始時,會執行一個兩步過程。首先,從完整備份映像恢復完整備份。其次,來自上次完全備份和正在恢復的增量備份之間的增量備份的所有WAL文件都將轉換為HFiles,HBase批量裝載程序會自動將其導入為表中的已還原數據。
您只能在活動的HBase集群上進行還原,因為必須重新分發數據才能成功完成還原操作。
## 90\. 關于文件系統容量增長的警告
提醒一下,通過保留HBase主要用于數據持久性的預寫日志來實現增量備份。因此,為確保在系統中仍然可用的所有數據包含在備份中,HBase備份和還原功能將保留自上次備份以來直到執行下一個增量備份的所有預寫日志。
與HBase快照一樣,對于數據量大的表,這可能對HBase依賴的HDFS使用產生巨大影響。注意啟用和使用備份和還原功能,尤其要注意在未主動使用備份會話時記得刪除備份會話。
目前,用于設定備份和還原的保留預寫日志大小上限是基于`hbase:backup`系統表的TTL,截至本文檔編寫時,該TTL是無限的(備份表條目永遠不會自動刪除)。這要求管理員按照周期性執行備份,該計劃的頻率需要與HDFS上的可用空間量相匹配(例如,較少的可用HDFS空間需要更積極的備份合并和刪除)。提醒一下,可以使用HBase shell中的`alter`命令在`hbase:backup`表上更改TTL。在系統表存在后修改hbase-site.xml中的配置屬性`hbase.backup.system.ttl`無效。
## 91\. 容量規劃
在規劃分布式系統部署時,必須執行一些基本的數學估算,以確保在給定系統的數據和軟件要求的情況下有足夠的計算能力。而對于備份和還原功能,在估算備份和還原策略的性能時,網絡容量是最大的瓶頸。第二個瓶頸是可以讀/寫數據的速度。
### 91.1\. 完整備份
要估計完整備份的持久化時間,我們必須了解調用的一般操作:
* 每個RegionServer上的預寫日志滾動:根據每個RegionServer的不同負載,每個RegionServer一到數十秒。
* 獲取表格的HBase快照:通常幾十秒。根據構成表的region和文件的數量不同有所變化。
* 將快照導出到目的地:請參閱下文。與數據的大小和到目的地的網絡帶寬有關。
為了估計最后一步將花費多長時間,我們必須對硬件做出一些假設。請注意,這些對您的系統來說是 **并非**準確的 - 這些是您或您的管理員對您的系統所熟知的數字。假設在單個節點上從HDFS讀取數據的速度上限為80MB / s(在該主機上運行的所有Mapper上),現代網絡接口控制器(NIC)支持10Gb / s,架頂式交換機可以處理40Gb / s,集群之間的WAN為10Gb / s。這意味著您只能以1.25GB / s的速度向遠程數據庫發送數據 - 這意味著參與ExportSnapshot的16個節點(`1.25 * 1024 / 80 = 16`)應該能夠完全打滿集群之間的鏈接。由于群集中有很多節點,我們可以讓每個節點export一部分,仍然可以打滿網絡。這樣對任何一個節點的影響較小,有助于確保本地SLA。如果快照的大小是10TB,這將完全備份將占用2.5小時的網絡帶寬(`10 * 1024 / 1.25 / (60 * 60) = 2.23hrs`)
通常,本地集群與遠程存儲之間的WAN帶寬很可能是完整備份速度的最大瓶頸。
當關注限制備份對“生產系統”的計算性能影響時,上述公式可以與`hbase backup create`:`-b`,`-w`,`-q`的可選命令行參數一起使用。 `-b`選項限制每個工作程序(Mapper)寫入數據的帶寬。 `-w`參數限制將在DistCp作業中生成的工作程序數量。 `-q`允許用戶指定YARN隊列,該隊列可以限制執行復制備份工作到特定節點 - 這可以將執行復制的備份工作任務隔離到一組非關鍵節點。將`-b`和`-w`選項與我們之前的公式相關聯:`-b`將用于限制每個節點以完全80MB/s的速度讀取數據,`-w`用于限制該任務只產生16個工作程序。
### 91.2\. 增量備份
就像我們為完整備份所做的那樣,我們也必須了解增量備份過程的運行時和成本。
* 識別自上次完全備份或增量備份以來的新預寫日志:可忽略不計,根據來自備份系統表的先驗知識就能獲取。
* 讀取,過濾和寫入等同于WALls的“最小化”文件:以寫入數據的速度為主,這個取決于HDFS的寫入速度。
* 將HFiles拷貝到目的地:[見上文](#br.export.snapshot.cost)。
對于第二步,此操作的主要成本是重寫數據(假設WAL中的大多數數據被保留)。在這種情況下,我們可以假設每個節點的聚合寫入速度為30MB / s。繼續我們的16節點集群示例,這需要大約15分鐘來執行50GB數據(50 * 1024/60/60 = 14.2)寫入。啟動DistCp MapReduce作業的時間可能會主導復制數據所需的實際時間,網絡傳輸時間(50 / 1.25 = 40秒)可以忽略。
## 92\. 備份和還原機制的限制
**串行備份操作**
備份操作不能同時運行。操作包括創建,刪除,還原和合并等操作。僅支持一個活動備份會話。 [HBASE-16391](https://issues.apache.org/jira/browse/HBASE-16391) 將引入多備份會話支持。
**無法取消備份操作**
備份和還原操作都無法取消。 ( [HBASE-15997](https://issues.apache.org/jira/browse/HBASE-15997) , [HBASE-15998](https://issues.apache.org/jira/browse/HBASE-15998) )。取消備份的解決方法是終止客戶端備份命令(`control-C`),確保已退出所有相關的MapReduce作業,然后運行`hbase backup repair`命令以確保系統備份元數據一致。
**備份只能保存到一個位置**
將備份信息復制到多個位置需要用戶自己實現。 [HBASE-15476](https://issues.apache.org/jira/browse/HBASE-15476) 將引入本質上指定多備份目的地的能力。
**需要HBase超級用戶訪問**
只允許HBase超級用戶(例如hbase)執行備份/恢復,這可能會對共享HBase用戶造成問題。當前的緩解措施需要與系統管理員協調,以構建和部署備份和恢復策略( [HBASE-14138](https://issues.apache.org/jira/browse/HBASE-14138) )。
**備份恢復是在線操作**
要從備份數據執行還原操作,當前實現需要HBase集群在線( [HBASE-16573](https://issues.apache.org/jira/browse/HBASE-16573) )。
**某些操作可能會失敗并需要重新運行**
HBase備份功能主要由客戶端驅動。雖然HBase連接中內置了標準的HBase重試邏輯,但執行操作中的持久性錯誤可能會傳播回客戶端(例如,由于區域分裂導致的快照失敗)。應將備份實現從客戶端移動到將來的ProcedureV2框架中,這將為瞬態/可重試故障提供額外的穩健性。 `hbase backup repair`命令用于糾正系統無法自動檢測和恢復的狀態。
**避免聲明公開API**
雖然存在與此功能交互的Java API并且其實現與接口分離,但是仍然不足以說明它是否是我們打算給普通用戶使用的。因此,它被標記為`Private`受眾,一旦用戶開始嘗試該功能,這將會破壞兼容性( [HBASE-17517](https://issues.apache.org/jira/browse/HBASE-17517) )。
**缺乏備份和恢復的全局指標**
單獨的備份和恢復操作包含有關操作所包含的工作量的指標,但沒有集中位置(例如Master UI)提供執行相關信息( [HBASE-16565](https://issues.apache.org/jira/browse/HBASE-16565) )。
- HBase? 中文參考指南 3.0
- Preface
- Getting Started
- Apache HBase Configuration
- Upgrading
- The Apache HBase Shell
- Data Model
- HBase and Schema Design
- RegionServer Sizing Rules of Thumb
- HBase and MapReduce
- Securing Apache HBase
- Architecture
- In-memory Compaction
- Backup and Restore
- Synchronous Replication
- Apache HBase APIs
- Apache HBase External APIs
- Thrift API and Filter Language
- HBase and Spark
- Apache HBase Coprocessors
- Apache HBase Performance Tuning
- Troubleshooting and Debugging Apache HBase
- Apache HBase Case Studies
- Apache HBase Operational Management
- Building and Developing Apache HBase
- Unit Testing HBase Applications
- Protobuf in HBase
- Procedure Framework (Pv2): HBASE-12439
- AMv2 Description for Devs
- ZooKeeper
- Community
- Appendix