
# C 編程,第 4 部分:字符串和結構體
> 原文:[Processes, Part 1: Introduction](https://github.com/angrave/SystemProgramming/wiki/Processes%2C-Part-1%3A-Introduction)
> 校驗:[_stund](https://github.com/hqiwen)
> 自豪地采用[谷歌翻譯](https://translate.google.cn/)
## 字符串,結構和陷阱
## 那什么是字符串?

在 C 中,由于歷史原因,我們有 [Null Terminated](https://en.wikipedia.org/wiki/Null-terminated_string) 字符串而不是 [Length Prefixed](https://en.wikipedia.org/wiki/String_(computer_science)#Length-prefixed) 。對于平均日常編程而言,這意味著您需要記住空字符! C 中的字符串被定義為一串字節,直到您達到'\ 0'或空字節。
### 兩個不同地方的字符串
每當你定義一個常量字符串(即`char* str = "constant"`形式的那個)時,該字符串存儲在數據或代碼 段中,**只讀**意味著任何修改字符串的嘗試都會導致段錯誤。
如果一個字符串在`malloc`的空間,可以將該字符串更改為他們想要的任何內容。
### 內穿管理不善
一個常見的問題是當你寫下面的內容時
```c
char* hello_string = malloc(14);
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___
// hello_string ----> | g | a | r | b | a | g | e | g | a | r | b | a | g | e |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄
hello_string = "Hello Bhuvan!";
// (constant string in the text segment)
// hello_string ----> [ "H" , "e" , "l" , "l" , "o" , " " , "B" , "h" , "u" , "v" , "a" , "n" , "!" , "\0" ]
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___
// memory_leak -----> | g | a | r | b | a | g | e | g | a | r | b | a | g | e |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄
hello_string[9] = 't'; //segfault!!分段錯誤
```
我們做了什么?我們為 14 個字節分配了空間,重新分配指針并成功實現了分段錯誤!記得要記錄你的指針在做什么。您可能想要做的是使用`string.h`功能`strcpy`。
```c
strcpy(hello_string, "Hello Bhuvan!");
```
### 記住 NULL 字節!
忘記 NULL 終止字符串對字符串有很大的影響!界限檢查很重要,它是之前在 wikibook 中提到的重要bug的一部分。
### 我在哪里可以找到所有這些功能的深入和分配 - 綜合解釋?
[就在這里!](https://linux.die.net/man/3/string)
### 字符串信息/比較:`strlen` `strcmp`
`int strlen(const char *s)`返回不包括空字節的字符串的長度
`int strcmp(const char *s1, const char *s2)`返回一個確定字符串的字典順序的整數。如果 s1 在字典中的 s2 之前到達,則返回-1。如果兩個字符串相等,則為 0.否則為 1。
對于大多數這些函數,他們希望字符串是可讀的而不是 NULL,但是當你將它們傳遞給 NULL 時會有未定義的行為。
### 字符串更改:`strcpy` `strcat` `strdup`
`char *strcpy(char *dest, const char *src)`將`src`處的字符串復制到`dest`。 **假設 dest 有足夠的空間用于 src**
`char *strcat(char *dest, const char *src)`將`src`的字符串連接到目的地的末尾。 **此函數假定目的地末尾有足夠的`src`空間,包括 NULL 字節**
`char *strdup(const char *dest)`返回字符串的`malloc`編輯副本。
### 字符串搜索:`strchr` `strstr`
`char *strchr(const char *haystack, int needle)`返回指向`haystack`中第一次出現`needle`的指針。如果沒有找到,則返回`NULL`。
`char *strstr(const char *haystack, const char *needle)`與上面相同,但這次是一個字符串!
### 字符串切分:`strtok`
一個危險但有用的函數 strtok 需要一個字符串并將其切分。這意味著它會將字符串轉換為單獨的字符串。這個函數有很多規格,所以請閱讀手冊,下面是一個人為的例子。
```c
#include <stdio.h>
#include <string.h>
int main(){
char* upped = strdup("strtok,is,tricky,!!");
char* start = strtok(upped, ",");
do{
printf("%s\n", start);
}while((start = strtok(NULL, ",")));
return 0;
}
```
**輸出**
```c
strtok
is
tricky
!!
```
當我像這樣更改`upped`時會發生什么?
```c
char* upped = strdup("strtok,is,tricky,,,!!");
```
### 內存移動:`memcpy`和`memmove`
為什么`memcpy`和`memmove`都在`<string.h>`中?因為字符串本質上是原始內存,在它們的末尾有一個空字節!
`void *memcpy(void *dest, const void *src, size_t n)`將從`str`開始的`n`字節移動到`dest`。 **注意**當內存區域重疊時,存在未定義的行為。這是我的機器示例中的經典作品之一,因為很多時候 valgrind 將無法拾取它,因為它看起來像是在你的機器上運行。當自動編程器命中時,失敗。考慮更安全的版本。
`void *memmove(void *dest, const void *src, size_t n)`執行與上面相同的操作,但如果內存區域重疊,則可以保證所有字節都將被正確復制。
## 那么什么是`struct`結構體?
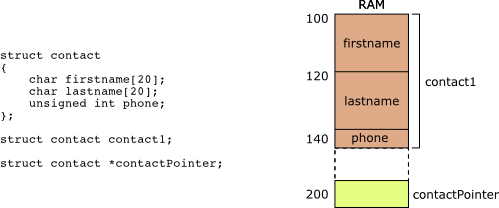
在低層次上,結構體只是一塊連續的內存,僅此而已。就像數組一樣,struct 有足夠的空間來保留其所有成員。但與數組不同,它可以存儲不同的類型。考慮上面聲明的 contact 結構
```c
struct contact {
char firstname[20];
char lastname[20];
unsigned int phone;
};
struct contact bhuvan;
```
**簡短的寫法**
```c
/* a lot of times we will do the following typdef
so we can just write contact contact1 */
typedef struct contact contact;
contact bhuvan;
/* You can also declare the struct like this to get
it done in one statement */
typedef struct optional_name {
...
} contact;
```
如果在沒有任何優化和重新排序的情況下編譯代碼,您可以期望每個變量的地址看起來像這樣。
```c
&bhuvan // 0x100
&bhuvan.firstname // 0x100 = 0x100+0x00
&bhuvan.lastname // 0x114 = 0x100+0x14
&bhuvan.phone // 0x128 = 0x100+0x28
```
因為你所有的編譯器都說'嘿保留這么多空間,我將去計算你想寫的任何變量的偏移'。
### 這些偏移是什么意思?
偏移量是變量開始的位置。聯系變量從`0x128`個字節開始,并繼續為 sizeof(int)字節,但并非總是如此。 **偏移不會確定**變量的結束位置。考慮一下你在很多內核代碼中看到的以下 hack。
```c
typedef struct {
int length;
char c_str[0];
} string;
const char* to_convert = "bhuvan";
int length = strlen(to_convert);
// Let's convert to a c string
string* bhuvan_name;
bhuvan_name = malloc(sizeof(string) + length+1);
/*
Currently, our memory looks like this with junk in those black spaces
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___
bhuvan_name = | | | | | | | | | | | |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄
*/
bhuvan_name->length = length;
/*
This writes the following values to the first four bytes
The rest is still garbage
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___
bhuvan_name = | 0 | 0 | 0 | 6 | | | | | | | |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄
*/
strcpy(bhuvan_name->c_str, to_convert);
/*
Now our string is filled in correctly at the end of the struct
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ____
bhuvan_name = | 0 | 0 | 0 | 6 | b | h | u | v | a | n | \0 |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄ ̄
*/
strcmp(bhuvan_name->c_str, "bhuvan") == 0 //The strings are equal!
```
### 但并非所有結構都是完美的
結構體可能需要一些稱為[填充](http://www.catb.org/esr/structure-packing/)(教程)的東西。 **我們不希望你在這個課程中打包結構,只知道它在那里這是因為在早期(甚至現在)當你需要從內存中的地址時你必須在 32 位或 64 位塊中進行。這也意味著您只能請求多次來獲得相應的地址。意思是
```c
struct picture{
int height;
pixel** data;
int width;
char* enconding;
}
// You think picture looks like this
height data width encoding
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___
picture = | | | | |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄
```
在概念上可能看起來像這樣
```c
struct picture{
int height;
char slop1[4];
pixel** data;
int width;
char slop2[4];
char* enconding;
}
height slop1 data width slop2 encoding
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___
picture = | | | | | | |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄
```
(這是在 64 位系統上)并非總是如此,因為有時您的處理器支持未對齊的訪問。這是什么意思?那么您可以設置兩個屬性選項
```c
struct __attribute__((packed, aligned(4))) picture{
int height;
pixel** data;
int width;
char* enconding;
}
// Will look like this
height data width encoding
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___
picture = | | | | |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄
```
但現在每次我想訪問`data`或`encoding`時,我都要進行兩次內存訪問。您可以做的另一件事是重新排序結構,盡管這并不總是可行的
```c
struct picture{
int height;
int width;
pixel** data;
char* enconding;
}
// You think picture looks like this
height width data encoding
___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___ ___
picture = | | | | |
 ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄  ̄ ̄ ̄
```
- UIUC CS241 系統編程中文講義
- 0. 簡介
- #Informal 詞匯表
- #Piazza:何時以及如何尋求幫助
- 編程技巧,第 1 部分
- 系統編程短篇小說和歌曲
- 1.學習 C
- C 編程,第 1 部分:簡介
- C 編程,第 2 部分:文本輸入和輸出
- C 編程,第 3 部分:常見問題
- C 編程,第 4 部分:字符串和結構
- C 編程,第 5 部分:調試
- C 編程,復習題
- 2.進程
- 進程,第 1 部分:簡介
- 分叉,第 1 部分:簡介
- 分叉,第 2 部分:Fork,Exec,等等
- 進程控制,第 1 部分:使用信號等待宏
- 進程復習題
- 3.內存和分配器
- 內存,第 1 部分:堆內存簡介
- 內存,第 2 部分:實現內存分配器
- 內存,第 3 部分:粉碎堆棧示例
- 內存復習題
- 4.介紹 Pthreads
- Pthreads,第 1 部分:簡介
- Pthreads,第 2 部分:實踐中的用法
- Pthreads,第 3 部分:并行問題(獎金)
- Pthread 復習題
- 5.同步
- 同步,第 1 部分:互斥鎖
- 同步,第 2 部分:計算信號量
- 同步,第 3 部分:使用互斥鎖和信號量
- 同步,第 4 部分:臨界區問題
- 同步,第 5 部分:條件變量
- 同步,第 6 部分:實現障礙
- 同步,第 7 部分:讀者編寫器問題
- 同步,第 8 部分:環形緩沖區示例
- 同步復習題
- 6.死鎖
- 死鎖,第 1 部分:資源分配圖
- 死鎖,第 2 部分:死鎖條件
- 死鎖,第 3 部分:餐飲哲學家
- 死鎖復習題
- 7.進程間通信&amp;調度
- 虛擬內存,第 1 部分:虛擬內存簡介
- 管道,第 1 部分:管道介紹
- 管道,第 2 部分:管道編程秘密
- 文件,第 1 部分:使用文件
- 調度,第 1 部分:調度過程
- 調度,第 2 部分:調度過程:算法
- IPC 復習題
- 8.網絡
- POSIX,第 1 部分:錯誤處理
- 網絡,第 1 部分:簡介
- 網絡,第 2 部分:使用 getaddrinfo
- 網絡,第 3 部分:構建一個簡單的 TCP 客戶端
- 網絡,第 4 部分:構建一個簡單的 TCP 服務器
- 網絡,第 5 部分:關閉端口,重用端口和其他技巧
- 網絡,第 6 部分:創建 UDP 服務器
- 網絡,第 7 部分:非阻塞 I O,select()和 epoll
- RPC,第 1 部分:遠程過程調用簡介
- 網絡復習題
- 9.文件系統
- 文件系統,第 1 部分:簡介
- 文件系統,第 2 部分:文件是 inode(其他一切只是數據...)
- 文件系統,第 3 部分:權限
- 文件系統,第 4 部分:使用目錄
- 文件系統,第 5 部分:虛擬文件系統
- 文件系統,第 6 部分:內存映射文件和共享內存
- 文件系統,第 7 部分:可擴展且可靠的文件系統
- 文件系統,第 8 部分:從 Android 設備中刪除預裝的惡意軟件
- 文件系統,第 9 部分:磁盤塊示例
- 文件系統復習題
- 10.信號
- 過程控制,第 1 部分:使用信號等待宏
- 信號,第 2 部分:待處理的信號和信號掩碼
- 信號,第 3 部分:提高信號
- 信號,第 4 部分:信號
- 信號復習題
- 考試練習題
- 考試主題
- C 編程:復習題
- 多線程編程:復習題
- 同步概念:復習題
- 記憶:復習題
- 管道:復習題
- 文件系統:復習題
- 網絡:復習題
- 信號:復習題
- 系統編程笑話