
# 進程,第 1 部分:簡介
> 原文:[Processes, Part 1: Introduction](https://github.com/angrave/SystemProgramming/wiki/Processes%2C-Part-1%3A-Introduction)
> 校驗:[飛龍](https://github.com/wizardforcel)
> 自豪地采用[谷歌翻譯](https://translate.google.cn/)
## 概覽
進程是運行中的程序(大致)。進程也只是這個運行中的計算機程序的一個實例。進程有很多東西可供使用。在每個程序啟動時,您將獲得一個進程,但每個程序可以創建更多進程。實際上,您的操作系統只啟動了一個進程,所有其他進程都是由它分叉的 - 所有這些都是在啟動時在背后完成的。
## 好吧,但是什么是程序?
程序通常包含以下內容
+ 二進制格式:告訴操作系統二進制中的哪些位集是什么 -- 哪個部分是可執行的,哪些部分是常量,要包括哪些庫等。
+ 一套機器指令
+ 表示從哪條指令開始的數字
+ 常量
+ 要鏈接的庫以及在何處填寫這些庫的地址
## 最開始
當您的操作系統在 Linux 機器上啟動時,會創建一個名為`init.d`的進程。該進程是個處理信號和中斷的特殊進程,和某些內核元素的持久性模塊。無論何時想要創建一個新進程,都可以調用`fork`(將在后面的部分中討論)并使用另一個函數來加載另一個程序。
## 進程隔離
進程非常強大,但它們是隔離的!這意味著默認情況下,任何進程都無法與另一個進程通信。這非常重要,因為如果你有一個大型系統(比方說 EWS),那么你希望某些進程擁有比普通用戶更高的權限(監控,管理員),并且當然不希望普通用戶通過有意或無意修改進程,能夠搞崩整個系統。
如果我在兩個不同的終端上運行以下代碼,
```
int secrets; //maybe defined in the kernel or else where
secrets++;
printf("%d\n", secrets);
```
正如你猜測的那樣,它們都打印出 1 而不是 2。即使我們改變了代碼來做一些真正的黑魔法(除了直接讀取內存),也沒有辦法改變另一個進程的狀態(好吧,也許 [DirtyCow](https://en.wikipedia.org/wiki/Dirty_COW) 可以,但這有點太深入了)。
## 進程內容
## 內存布局
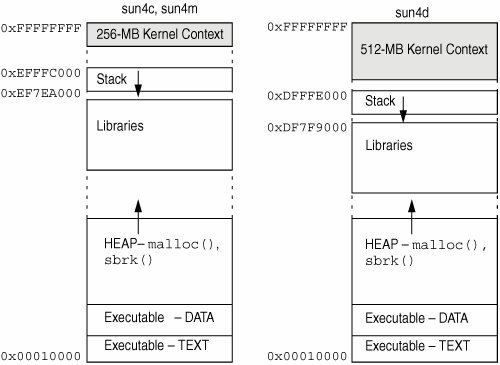
當進程啟動時,它會獲得自己的地址空間。意味著每個進程得到:
* **一個棧**。棧是存儲自動變量和函數調用返回地址的位置。每次聲明一個新變量時,程序都會向下移動棧指針來保留變量的空間。棧的這一部分是可寫的但不可執行。如果棧增長得太遠(意味著它增長超出預設邊界或與堆相交),您將獲得棧溢出,最有可能導致 SEGFAULT 或類似的東西。**棧默認靜態分配,意味著只有一定數量的可寫空間**。
* **堆**。堆是一個擴展的內存區域。如果你想分配一個大對象,它就在這里。堆從文本段的頂部開始向上增長(有時當你調用`malloc`它要求操作系統向上推動堆邊界)。此區域也是可寫但不可執行。如果系統受限制或者地址耗盡(在 32 位系統上更常見),則可能會耗盡堆內存。
* **數據段**包含所有全局變量。此部分從 Text 段的末尾開始,并且大小是靜態的,因為在編譯時已知全局變量。這部分是可寫的但不是可執行的,這里沒有太過花哨的其他任何東西。
* **文本段**。可以說,這是地址中最重要的部分。這是存儲所有代碼的地方。由于匯編代碼編譯為 1 和 0,因此這是存儲 1 和 0 的地方。程序計數器在該段中移動來執行指令,并向下一條指令移動。請務必注意,這是代碼中唯一的可執行部分。如果您嘗試在運行時更改代碼,很可能會出現段錯誤(有很多方法可以解決它,但只是假設它是段錯誤)。
* 為什么不從零開始?它在這個課程的[范圍](https://en.wikipedia.org/wiki/Address_space_layout_randomization)之外,但它是為了安全。
## 進程 ID(PID)
為了跟蹤所有這些進程,您的操作系統為每個進程提供一個編號,該進程稱為 PID,即進程 ID。 進程也有一個 ppid,它是父進程 ID 的縮寫。 每個進程都有一個父進程,該父進程可以是`init.d`。
進程也可以包含:
+ 運行狀態 -- 進程是否正在準備,運行,停止,終止等。
+ 文件描述符 -- 整數到實際設備(文件,USB 記憶棒,套接字)的映射列表
+ 權限 -- 正在運行文件的用戶以及進程所屬的組。 然后,該進程只對這個用戶或組是可接受的,就像打開用戶已經設為排他的文件一樣。 有一些技巧可以使程序不成為啟動該程序的用戶,即`sudo`接受一個由用戶啟動的程序并以`root`身份執行該程序。
+ 參數 -- 字符串列表,告訴您的程序要在哪些參數下運行。
+ 環境列表 -- 可以修改的格式為`NAME=VALUE`的字符串列表。
- UIUC CS241 系統編程中文講義
- 0. 簡介
- #Informal 詞匯表
- #Piazza:何時以及如何尋求幫助
- 編程技巧,第 1 部分
- 系統編程短篇小說和歌曲
- 1.學習 C
- C 編程,第 1 部分:簡介
- C 編程,第 2 部分:文本輸入和輸出
- C 編程,第 3 部分:常見問題
- C 編程,第 4 部分:字符串和結構
- C 編程,第 5 部分:調試
- C 編程,復習題
- 2.進程
- 進程,第 1 部分:簡介
- 分叉,第 1 部分:簡介
- 分叉,第 2 部分:Fork,Exec,等等
- 進程控制,第 1 部分:使用信號等待宏
- 進程復習題
- 3.內存和分配器
- 內存,第 1 部分:堆內存簡介
- 內存,第 2 部分:實現內存分配器
- 內存,第 3 部分:粉碎堆棧示例
- 內存復習題
- 4.介紹 Pthreads
- Pthreads,第 1 部分:簡介
- Pthreads,第 2 部分:實踐中的用法
- Pthreads,第 3 部分:并行問題(獎金)
- Pthread 復習題
- 5.同步
- 同步,第 1 部分:互斥鎖
- 同步,第 2 部分:計算信號量
- 同步,第 3 部分:使用互斥鎖和信號量
- 同步,第 4 部分:臨界區問題
- 同步,第 5 部分:條件變量
- 同步,第 6 部分:實現障礙
- 同步,第 7 部分:讀者編寫器問題
- 同步,第 8 部分:環形緩沖區示例
- 同步復習題
- 6.死鎖
- 死鎖,第 1 部分:資源分配圖
- 死鎖,第 2 部分:死鎖條件
- 死鎖,第 3 部分:餐飲哲學家
- 死鎖復習題
- 7.進程間通信&調度
- 虛擬內存,第 1 部分:虛擬內存簡介
- 管道,第 1 部分:管道介紹
- 管道,第 2 部分:管道編程秘密
- 文件,第 1 部分:使用文件
- 調度,第 1 部分:調度過程
- 調度,第 2 部分:調度過程:算法
- IPC 復習題
- 8.網絡
- POSIX,第 1 部分:錯誤處理
- 網絡,第 1 部分:簡介
- 網絡,第 2 部分:使用 getaddrinfo
- 網絡,第 3 部分:構建一個簡單的 TCP 客戶端
- 網絡,第 4 部分:構建一個簡單的 TCP 服務器
- 網絡,第 5 部分:關閉端口,重用端口和其他技巧
- 網絡,第 6 部分:創建 UDP 服務器
- 網絡,第 7 部分:非阻塞 I O,select()和 epoll
- RPC,第 1 部分:遠程過程調用簡介
- 網絡復習題
- 9.文件系統
- 文件系統,第 1 部分:簡介
- 文件系統,第 2 部分:文件是 inode(其他一切只是數據...)
- 文件系統,第 3 部分:權限
- 文件系統,第 4 部分:使用目錄
- 文件系統,第 5 部分:虛擬文件系統
- 文件系統,第 6 部分:內存映射文件和共享內存
- 文件系統,第 7 部分:可擴展且可靠的文件系統
- 文件系統,第 8 部分:從 Android 設備中刪除預裝的惡意軟件
- 文件系統,第 9 部分:磁盤塊示例
- 文件系統復習題
- 10.信號
- 過程控制,第 1 部分:使用信號等待宏
- 信號,第 2 部分:待處理的信號和信號掩碼
- 信號,第 3 部分:提高信號
- 信號,第 4 部分:信號
- 信號復習題
- 考試練習題
- 考試主題
- C 編程:復習題
- 多線程編程:復習題
- 同步概念:復習題
- 記憶:復習題
- 管道:復習題
- 文件系統:復習題
- 網絡:復習題
- 信號:復習題
- 系統編程笑話