[toc]
# 一、Java基礎
## 1、Java的基本數據類型
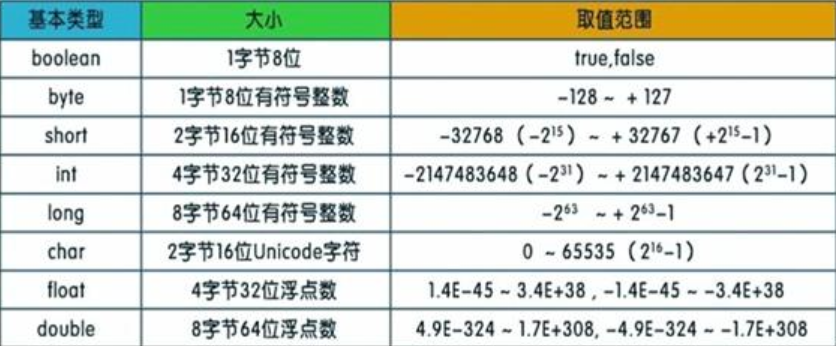
### 1.1 java 的8 型種基本數據類型
### 1.2 java 基本類型與引用類型的區別
基本類型保存原始值,引用類型保存的是引用值(引用值就是指對象在堆中所處的位置/地址)
### 1.3 基本數據類型的裝箱和拆箱
自動裝箱是 Java 編譯器在基本數據類型和對應的對象包裝類型之間做的一個轉化。比
如:把 int 轉化成 Integer,double 轉化成 Double,等等。反之就是自動拆箱。
- 原始類型: boolean,char,byte,short,int,long,float,double
- 封裝類型:Boolean,Character,Byte,Short,Integer,Long,Float,Double
### 1.4 short s1 = 1; s1 = s1 + 1;有什么錯? short s1 = 1; s1+=1;有什么錯?
- 1) 對于 `short s1=1;s1=s1+1` 來說,在 s1+1 運算時會自動提升表達式的類型為 int,
那么將 int 賦予給 short 類型的變量 s1 會出現類型轉換誤。
- 2) 對于 `short s1=1;s1+=1;` 來說 +=是 java 語言規定的運算符,java 編譯器會對它
進行特殊處理,因此可以正確編譯。
### 1.5 int和Integer的區別
> 1、Integer是int的包裝類,int則是java的一種基本數據類型
> 2、Integer變量必須實例化后才能使用,而int變量不需要
> 3、Integer實際是對象的引用,當new一個Integer時,實際上是生成一個指針指向此對象;而int則是直接存儲數據值
> 4、Integer的默認值是null,int的默認值是0
延伸:
關于Integer和int的比較
1、由于Integer變量實際上是對一個Integer對象的引用,所以兩個通過new生成的Integer變量永遠是不相等的(因為new生成的是兩個對象,其內存地址不同)。
```java
Integer i = new Integer(100);
Integer j = new Integer(100);
System.out.print(i == j); //false
```
2、Integer變量和int變量比較時,只要兩個變量的值是向等的,則結果為true(因為包裝類Integer和基本數據類型int比較時,java會自動拆包裝為int,然后進行比較,實際上就變為兩個int變量的比較)
```java
Integer i = new Integer(100);
int j = 100;
System.out.print(i == j); //true
```
3、非new生成的Integer變量和new Integer()生成的變量比較時,結果為false。(因為 ①當變量值在-128~127之間時,非new生成的Integer變量指向的是java常量池中的對象,而new Integer()生成的變量指向堆中新建的對象,兩者在內存中的地址不同;②當變量值在-128~127之間時,非new生成Integer變量時,java API中最終會按照new Integer(i)進行處理(參考下面第4條),最終兩個Interger的地址同樣是不相同的)
```java
Integer i = new Integer(100);
Integer j = 100;
System.out.print(i == j); //false
```
4、對于兩個非new生成的Integer對象,進行比較時,如果兩個變量的值在區間-128到127之間,則比較結果為true,如果兩個變量的值不在此區間,則比較結果為false
```java
Integer i = 100;
Integer j = 100;
System.out.print(i == j); //true
Integer i = 128;
Integer j = 128;
System.out.print(i == j); //false
```
對于第4條的原因:
java在編譯Integer i = 100 ;時,會翻譯成為Integer i = Integer.valueOf(100);,而java API中對Integer類型的valueOf的定義如下:
```java
public static Integer valueOf(int i){
assert IntegerCache.high >= 127;
if (i >= IntegerCache.low && i <= IntegerCache.high){
return IntegerCache.cache[i + (-IntegerCache.low)];
}
return new Integer(i);
}
```
java對于-128到127之間的數,會進行緩存,Integer i = 127時,會將127進行緩存,下次再寫Integer j = 127時,就會直接從緩存中取,就不會new了
### 1.6 float f=3.4;是否正確?
不正確。3.4 是雙精度數,將雙精度型(double)賦值給浮點型(float)屬于下轉型(down-casting,也稱為窄化)會造成精度損失,因此需要強制類型轉換 float f =(float)3.4; 或者寫成 float f=3.4F;。
## 2、String類型
"String對象一旦被創建就是固定不變的了,對String對象的任何改變都不影響到原對象,相關的任何操作都會生成新的對象“。
1. 固定不變 - 從String 對象的源碼中可以看出,String 類聲明為 final,且它的屬性和方法都被 final 所修飾
2. 任何操作都會生成新對象 - String:: subString(),String::concat() 等方法都會生成一個新的String對象,不會在原對象上進行操作
### 2.1 不可變性設計的初衷
- 字符串常量池的需要。String對象的不可變性為字符串常量池的實現提供了基礎,使得常量池便于管理和優化。
- 多線程安全。同一個字符串對象可以被多個線程共享。
- 安全性考慮。字符串應用場景眾多,設計成不可變性可以有效防止字符串被有意篡改。
- 由于String對象的不可變性,可以對其HashCode進行緩存,可以作為HashMap,HashTable等集合的key 值。
### 2.2 字符串常量池
**String 對象存在于堆中,字符串常量池存放了它們的引用**。因為 String 對象是不可變的,所以多個引用 "共享" 同一個String 對象是安全的,這種安全性就是 字符串常量池所帶來的。
### 2.3 字面量的形式創建字符串
```java
public class ImmutableStrings{
public static void main(String[] args){
String one = "someString"; //one
String two = "someString"; //two
System.out.println(one.equals(two)); // true
System.out.println(one == two); //true
}
}
```
執行完上面的第一句代碼之后,會在堆上創建一個String 對象,并把String 對象的引用存放到字符串常量池中,并把引用返回給 one,那當第二句代碼執行時,字符串常量池已經有對應內容的引用了,直接返回對象引用給 two。one.equals(two) / one == two 都為true。 圖形化如下所示:
<img src="https://i.loli.net/2020/12/20/vUbc8YFRuNAfpKs.png" alt="image-20201220210404446" style="zoom:50%;" />
### 2.4 new關鍵字創建字符串
```java
public class ImmutableStrings{
public static void main(String[] args) {
String one = "someString";
String two = new String("someString");
System.out.println(one.equals(two));//true
System.out.println(one == two);//false
}
}
```
在使用 new關鍵字時的情況會有稍微不同,關于這兩個字符串的引用任然會存放字符串常量池中,但是關鍵字 new使得虛擬機在運行時會創建一個新的String對象,而不是使用字符串常量池中已經存在的引用,此時 two 指向 堆中這個新創建的對象,而one 是常量池中的引用。 one.equals(two) 為 true,而 one == two 都為false。
<img src="https://i.loli.net/2020/12/20/YvEhzwg9QHus5m7.png" alt="image-20201220210553909" style="zoom:50%;" />
如果想要one,two都引用同一個對象,則可以使用 String:: intern()方法 - 當調用intern()方法時,如果字符串常量池中已經有了這個字符串,那么直接返回字符串常量池中它的引用,如果沒有,那就將它的引用保存一份到字符串常量池中,然后直接返回這個引用。這個方法是有返回值的,是返回引用。
```java
String one = "someString";
String two = new String("someString"); // 仍指向堆中new 出的新對象
String three = two.intern();
System.out.println(one.equals(two)); // true
System.out.println(one == two); // false
System.out.println(one == three); // true
System.out.println(two == three); // false
```
### 2.5 String 對象的創建和字符串常量池的放入
什么時候會創建String 對象?什么時候引用放入到字符串常量池中呢?先需要提出三個常量池的概念:
**靜態常量池**:常量池表(Constant Pool table,存放在Class文件中),也可稱作為靜態常量池,里面存放編譯器生成的各種字面量和符號引用。其中有兩個重要的常量類型為CONSTANT_String_info和CONSTANT_Utf8_info類型(具體描述可以看看《深入理解Java虛擬機》的p 219 啦~)
**運行時常量池**:運行時常量池屬于方法區的一部分,常量池表中的內容會在類加載時存放在方法區的運行時常量池,運行時常量池相比于Class文件常量池一個重要特征是 動態性,運行期間也可以將新的常量放入到 運行時常量池中
**字符串常量池**:在HotSpot 虛擬機中,使用StringTable來存儲 String 對象的引用,即來實現字符串常量池,StringTable 本質上是HashSet<String>,所以里面的內容是不可以重復的。一般來說,說一個字符串存儲到了字符串常量池也就是說在StringTable中保存了對這個String 對象的引用
執行過程
**在類的解析階段,虛擬機便會在創建String 對象,并把String對象的引用存儲到字符串常量池中**
- 當*.java 文件 編譯為*.class 文件時,字符串會像其他常量一樣存儲到class 文件中的常量池表中,對應于CONSTANT_String_info和CONSTANT_Utf8_info類型;
- 類加載時,會把靜態常量池中的內容存放到方法區中的運行時常量池中,其中CONSTANT_Utf8_info類型在類加載的時候就會全部被創建出來,即說明了加載類的時候,那些字符串字面量會進入到當前類的運行時常量池,但是此時StringTable(字符串常量池)并沒有相應的引用,在堆中也沒有相應的對象產生;
- 遇到ldc字節碼指令(該指令將int、float或String型常量值從常量池中推送至棧頂)之前會觸發解析階段,進入到解析階段,若在解析的過程中發現StringTable已經有與CONSTANT_String_info一樣的引用,則返回該引用,若沒有,則在堆中創建一個對應內容的String對象,并在StringTable中保存創建的對象的引用,然后返回;
其他值得關注的例子:
```java
String s1 = new String("hb");
String s2 = "hb";
System.out.println(s1 == s2); // false
String s3 = s1.intern(); // 從字符串串常量池中得到相應引用
System.out.println(s2 == s3); // true
System.out.println(" ===== 分割線 ===== ");
String s5 = "hb" + "haha"; // 虛擬機會優化進行優化, 當成一個整體 "hbhaha"成立, 而不會用StringBuild::append()處理
String s6 = "hbhaha";
System.out.println(s5 == s6); // true
System.out.println(" ===== 分割線 ===== ");
String temp = "hb";
String s7 = temp+"haha"; //采用StringBuilder::append()處理
System.out.println(s7 == s6); // false
String s8 = s7.intern(); //從字符串串常量池中得到相應引用
System.out.println(s8 == s6); // true
System.out.println(" ===== 分割線 ===== ");
String s9 = new String("hb") + new String("haha"); //采用StringBuilder::append()處理
System.out.println(s9 == s6); // false
String s10 = s9.intern(); //從字符串串常量池中得到相應引用
System.out.println(s10 == s6); // true
```
[Ref]https://www.jianshu.com/p/eba5f54bcf16?open_source=weibo_search
### 2.6 String 和 StringBuilder、StringBuffer 的區別?
* **StringBuilder** 不是線程安全的,效率高
* **StringBuffer** 是線程安全的,內部使用 synchronized 進行同步,效率低
### 2.7 new String("abc")創建幾個對象
```java
String str=new String("abc")
在常量池里有一個"abc"
在堆里有一個"abc"
還有一個引用str
String str1=new String();
只有一個對象
一個引用str1
```
<img src="https://i.loli.net/2020/12/21/mQEDZRtx7fYngdb.jpg" alt="-w500" style="zoom: 67%;" />
String pool若已經存在,只會創建一個對象,如果不存在會創建兩個(String pool 和堆中)
使用這種方式一共會創建兩個字符串對象(前提是 String Pool 中還沒有 "abc" 字符串對象)。
* "abc" 屬于字符串字面量,因此編譯時期會在 String Pool 中創建一個字符串對象,指向這個 "abc" 字符串字面量;
* 而使用 new 的方式會在堆中創建一個字符串對象。
## 3、Java語法相關
### 3.1面向對象的特征有哪些方面?
抽象是將一類對象的共同特征總結出來構造類的過程, 包括數據抽象和行為抽象兩方面。抽象只關注對象有哪些屬性和行為,并不關注這些行為的細節是什么。
**一、繼承:**
- 1.概念:繼承是從已有的類中派生出新的類,新的類能吸收已有類的數據屬性和行為,并能擴展新的能力
- 2.好處:提高代碼的復用,縮短開發周期。
**二、多態:**
- 1.概念:多態(Polymorphism)按字面的意思就是“多種狀態,即同一個實體同時具有多種形式。一般表現形式是程序在運行的過程中,同一種類型在不同的條件下表現不同的結果。多態也稱為動態綁定,一般是在運行時刻才能確定方法的具體執行對象,這個過程也稱為動態委派。
- 2.好處:
- 1)將接口和實現分開,改善代碼的組織結構和可讀性,還能創建可拓展的程序。
- 2)消除類型之間的耦合關系。允許將多個類型視為同一個類型。
- 3)一個多態方法的調用允許有多種表現形式
**三、封裝:**
- 1.概念:就是把對象的屬性和操作(或服務)結合為一個獨立的整體,并盡可能隱藏對象的內部實現細節。
- 2.好處:
- (1)隱藏信息,實現細節。讓客戶端程序員無法觸及他們不應該觸及的部分。
- (2)允許可設計者可以改變類內部的工作方式而不用擔心會影響到客戶端程序員。
**五個基本原則:**
* <font color='darkred'>單一職責原則(Single-Resposibility Principle):</font>一個類,最好只做一件事,只有一個引起它的變化。單一職責原則可以看做是低耦合、高內聚在面向對象原則上的引申,將職責定義為引起變化的原因,以提高內聚性來減少引起變化的原因。
* <font color='darkred'>開放封閉原則(Open-Closed principle)</font>:軟件實體應該是可擴展的,而不可修改的。也就是,對擴展開放,對修改封閉的。
* <font color='darkred'>Liskov替換原則(Liskov-Substituion Principle)</font>:子類必須能夠替換其基類。這一思想體現為對繼承機制的約束規范,只有子類能夠替換基類時,才能保證系統在運行期內識別子類,這是保證繼承復用的基礎。
* <font color='darkred'>依賴倒置原則(Dependecy-Inversion Principle)</font>:依賴于抽象。具體而言就是高層模塊不依賴于底層模塊,二者都同依賴于抽象;抽象不依賴于具體,具體依賴于抽象。
* <font color='darkred'>接口隔離原則(Interface-Segregation Principle)</font>:使用多個小的專門的接口,而不要使用一個大的總接口
簡單概括:
| 原則 | 描述 |
| ------------ | ---------------------------- |
| 單一職責原則 | 只做一件事 |
| 開放封閉原則 | 對擴展開放,對修改關閉 |
| 里氏替換原則 | 子類必須能夠替換基類 |
| 依賴倒置原則 | 抽象不依賴具體,具體依賴抽象 |
| 接口隔離原則 | 多個專門接口,不是一個總的 |
**方法重載(overload)**實現的是編譯時的多態性(也稱為前綁定),而**方法重寫(override)**實現的是運行時的多態性(也稱為后綁定)。運行時的多態是面向對象最精髓的東西,要實現多態需要做兩件事:
- 1). 方法重寫(子類繼承父類并重寫父類中已有或抽象的方法);
- 2). 對象造型(用父類型引用引用子類型對象,這樣同樣引用調用同樣的方法就會根據子類對象的不同而表現出不同的行為)。
### 3.2 訪問修飾符 public,private,protected,以及不寫(默認) 時的區別?
| 修飾符 | 當前類 | 同 包 | 子 類 | 其他包 |
| --------- | ------ | ----- | ----- | ------ |
| public | 能 | 能 | 能 | 能 |
| protected | 能 | 能 | 能 | - |
| default | 能 | 能 | - | - |
| private | 能 | - | - | - |
類的成員不寫訪問修飾時默認為 default。默認對于同一個包中的其他類相當于公 開(public),對于不是同一個包中的其他類相當于私有
(private)。受保護 (protected)對子類相當于公開,對不是同一包中的沒有父子關系的類相當于私 有。Java 中,外部類的修飾符只能
是 public 或默認,類的成員(包括內部類)的 修飾符可以是以上四種。
### 3.3 重載和重寫的區別
> **重寫(Overwrite)**——從字面上看,重寫就是重新寫一遍的意思。其實就是在子類中把父類本身有的方法重新寫一遍。子類繼承了父類原有的方法,但有時子類并不想原封不動的繼承父類中的某個方法,所以在方法名,參數列表,返回類型(除過子類中方法的返回值是父類中方法返回值的子類時)都相同的情況下, 對方法體進行修改或重寫,這就是重寫。但要注意子類函數的訪問修飾權限不能少于父類的。
重寫總結:
- 1.發生在父類與子類之間
- 2.方法名,參數列表,返回類型(除過子類中方法的返回類型是父類中返回類型的子類)必須相同
- 3.訪問修飾符的限制一定要大于被重寫方法的訪問修飾符(public>protected>default>private)
- 4.重寫方法一定不能拋出新的檢查異常或者比被重寫方法申明更加寬泛的檢查型異常
> **重載(Overload)**在一個類中,同名的方法如果有不同的參數列表(**參數類型不同、參數個數不同甚至是參數順序不同**)則視為重載。同時,重載對返回類型沒有要求,可以相同也可以不同,**但不能通過返回類型是否相同來判斷重載**。
重載總結:
- 1.重載Overload是一個類中多態性的一種表現
- 2.重載要求同名方法的參數列表不同(參數類型,參數個數甚至是參數順序)
- 3.重載的時候,返回值類型可以相同也可以不相同。無法以返回型別作為重載函數的區分標準
### 3.4 equals與==的區別
(一)、**==:**== 比較的是變量(棧)內存中存放的對象的(堆)內存地址,用來判斷兩個對象的地址是否相同,即是否是指相同一個對象。比較的是真正意義上的指針操作。
- 1、比較的是操作符兩端的操作數是否是同一個對象。
- 2、兩邊的操作數必須是同一類型的(可以是父子類之間)才能編譯通過。
- 3、比較的是地址,如果是具體的阿拉伯數字的比較,值相等則為true,如:
int a=10 與 long b=10L 與 double c=10.0都是相同的(為true),因為他們都指向地址為10的堆。
(二)、**equals:**equals用來比較的是兩個對象的內容是否相等,由于所有的類都是繼承自java.lang.Object類的,所以適用于所有對象,如果沒有對該方法進行覆蓋的話,調用的仍然是Object類中的方法,而Object中的equals方法返回的卻是==的判斷。
總結:
所有比較是否相等時,都是用equals 并且在對常量相比較時,把常量寫在前面(“常量”.equals(obj)),因為使用object的equals object可能為null 則空指針在阿里的代碼規范中只使用equals ,阿里插件默認會識別,并可以快速修改,推薦安裝阿里插件來排查老代碼使用“==”,替換成equals
hashCode() 方法是相應對象整型的 hash 值。它常用于基于 hash 的集合類,如 Hashtable、HashMap、LinkedHashMap 等等。它與equals() 方法關系特別緊密。根據 Java 規范,兩個使用 equal() 方法來判斷相等的對象,必須具有相同的 hash code。
### 3.5 java中是值傳遞引用傳遞?
> - 值傳遞(pass by value)是指在調用函數時將實際參數復制一份傳遞到函數中,這樣在函數中如果對參數進行修改,將不會影響到實際參數。
> - 引用傳遞(pass by reference)是指在調用函數時將實際參數的地址直接傳遞到函數中,那么在函數中對參數所進行的修改,將影響到實際參數。
java中方法參數傳遞方式是按值傳遞。
如果參數是基本類型,傳遞的是基本類型的字面量值的拷貝。
如果參數是引用類型,傳遞的是該參量所引用的對象在堆中地址值的拷貝。
### 3.6 實例化數組后,能不能改變數組長度呢?
不能,數組一旦實例化,它的長度就是固定的
```java
public static void main(String[] args){
int num=5;
Student[] s2=new Student[num];
System.out.println(s2.length);//輸出結果為:5
num=6;
System.out.println(s2.length);//輸出結果為:5
}
```
### 3.7 形參與實參區別
- **實參(argument):**是在調用時傳遞給函數的參數. 實參可以是常量、變量、表達式、函數等, 無論實參是何種類型的量,<u>**在進行函數調用時,它們都必須具有確定的值, 以便把這些值傳送給形參**</u>。
- **形參(parameter):**不是實際存在變量,所以又稱虛擬變量。是在定義函數名和函數體的時候使用的參數,目的是用來接收調用該函數
時傳入的參數.在調用函數時,實參將賦值給形參。因而,必須注意**<u>實參的個數,類型應與形參一一對應,并且實參必須要有確定的值</u>**。
說明:
- 1.形參變量只有在被調用時才分配內存單元,在調用結束時, 即刻釋放所分配的內存單元。因此,形參只有在函數內部有效。 函數調用結束返回主調函數后則不能再使用該形參變量。
- 2.實參可以是常量、變量、表達式、函數等, 無論實參是何種類型的量,在進行函數調用時,它們都必須具有確定的值, 以便把這些值傳送給形參。
- 3.實參和形參在數量上,類型上,順序上應嚴格一致, 否則會發生“類型不匹配”的錯誤。
- 4.函數調用中發生的數據傳送是單向的。 即只能把實參的值傳送給形參,而不能把形參的值反向地傳送給實參。 因此在函數調用過程中,形參的值發生改變,而實參中的值不會變化。
- 5.當形參和實參不是指針類型時,在該函數運行時,形參和實參是不同的變量,他們在內存中位于不同的位置,形參將實參的內容復制一
份,在該函數運行結束的時候形參被釋放,而實參內容不會改變。
而如果函數的參數是指針類型變量,在調用該函數的過程中,傳給函數的是實參的地址,在函數體內部使用的也是實參的地址,即使用的就是實參本身。所以在函數體內部可以改變實參的值。
### 3.8 Java中內部類和靜態內部類的區別
```java
public class OuterClass {
private int numPrivate = 1;
public int numPublic = 2;
public static int numPublicStatic = 3;
private static int numPrivateStatic = 4;
public void nonStaticPublicMethod(){
System.out.println("using nonStaticPublicMethod");
}
private void nonStaticPrivateMethod(){
System.out.println("using nonStaticPrivateMethod");
}
public static void staticPublicMethod(){
System.out.println("using staticPublicMethod");
}
private static void staticPrivateMethod(){
System.out.println("using staticPrivateMethod");
}
class InnerClass{
//Inner class cannot have static declarations
//static int numInnerClass = 4;
//public static void test(){}
int numNonStaticInnerClass = 5;
public void print(){
System.out.println("using InnerClass");
System.out.println("access private field: "+numPrivate);
System.out.println("access public field: "+numPublic);
System.out.println("access public static field: "+numPublicStatic);
System.out.println("access private static field: "+numPrivateStatic);
System.out.println("access numNonStaticInnerClass: "+numNonStaticInnerClass);
nonStaticPrivateMethod();
nonStaticPublicMethod();
staticPrivateMethod();
staticPublicMethod();
}
}
static class StaticNestedClass{
static int numStaticNestedClass = 6;
int numNonStaticNestedClass = 7;
public void print(){
System.out.println("using StaticNestedClass");
System.out.println("access public static field: "+numPublicStatic);
System.out.println("access private static field: "+numPrivateStatic);
System.out.println("access numStaticNestedClass: "+numStaticNestedClass);
System.out.println("access numNonStaticNestedClass: "+numNonStaticNestedClass);
staticPrivateMethod();
staticPublicMethod();
}
}
public static void main(String[] args) {
//內部類實例對象
OuterClass outerClass = new OuterClass();
OuterClass.InnerClass innerClass = outerClass.new InnerClass();
innerClass.print();
System.out.println("=====================");
//靜態內部類實例化對象
OuterClass.StaticNestedClass nestedClass = new OuterClass.StaticNestedClass();
nestedClass.print();
}
}
```
結果:
```bash
using InnerClass
access private field: 1
access public field: 2
access public static field: 3
access private static field: 4
access numNonStaticInnerClass: 5
using nonStaticPrivateMethod
using nonStaticPublicMethod
using staticPrivateMethod
using staticPublicMethod
=====================
using StaticNestedClass
access public static field: 3
access private static field: 4
access numStaticNestedClass: 6
access numNonStaticNestedClass: 7
using staticPrivateMethod
using staticPublicMethod
```
#### 靜態內部類使用方法
通過外部類訪問靜態內部類
```java
OuterClass.StaticNestedClass
```
創建靜態內部類對象
```java
OuterClass.StaticNestedClass nestedObject = new OuterClass.StaticNestedClass();
```
#### 內部類的使用方法
必須先實例化外部類,才能實例化內部類
```java
OuterClass outerClass = new OuterClass();
OuterClass.InnerClass innerClass = outerClass.new InnerClass();
```
#### 兩者區別
1. 內部類, 即便是私有的也能訪問,無論靜態還是非靜態都能訪問
- 可以訪問封閉類(外部類)中所有的成員變量和方法
- 封閉類(外部類)中的私有private成員變量和方法也可以訪問
- 內部類中不可以有靜態的變量和靜態的方法
2. 靜態內部類
- 無權訪問封閉類(外部類)的中的非靜態變量或者非靜態方法
- 封閉類(外部類)中的私有private的靜態static成員變量和方法也可以訪問
- 靜態內部類中可以有靜態的變量和靜態的方法
3. 內部類可以被聲明為private, public, protected, or package private. 但是封閉類(外部類)只能被聲明為`public` or package private
#### 為什么使用內部類
- **這是一種對僅在一個地方使用的類進行邏輯分組的方法**:如果一個類僅對另一個類有用,那么將其嵌入該類并將兩者保持在一起是合乎邏輯的。
- **它增加了封裝**:考慮兩個頂級類A和B,其中B需要訪問A的成員,如果將A的成員聲明為`private`則B無法訪問。通過將類B隱藏在類A中,可以將A的成員聲明為私有,而B可以訪問它們。另外,B本身可以對外界隱藏。
- **這可能會導致代碼更具可讀性和可維護性**:在外部類中嵌套小類會使代碼更靠近使用位置。
#### 序列化
**強烈建議不要對內部類(包括 本地和 匿名類)進行序列化。**
如果序列化一個內部類,然后使用其他JRE實現對其進行反序列化,則可能會遇到兼容性問題
### 3.9 Static關鍵字有什么作用?
- static可以修飾*屬性,方法,代碼段,內部類(靜態內部類或者嵌套內部類)*
- static修飾的屬性的初始化在編譯期(類加載的時候),只執行一次,如果在主函數中,優先于主函數執行,**優先于對象存在,優先于構造器初始化**
- static修飾的屬性、方法、代碼段與具體對象無關,只跟類有關
- **靜態方法只能訪問靜態成員,不可以訪問非靜態成員**,**靜態內部只能使用靜態的東西**
- 靜態方法中**不能使用this,super**關鍵字(this和super與對象,即實例相關)
- **靜態變量**存在于*方法區*中,**成員變量**存在于*堆內存*中
- 繼承情況下,static修飾的變量及方法子類可以繼承,但是無法展現多態特性(普通屬性也可以繼承,但是無法多態,只有普通方法可以多態)
- **不能與abstract關鍵字共存**(不能使用static abstract void test()),因為靜態方法意味著可以直接調用,但是抽象方法不可以有實現,所以無法直接調用。(理解:static是靜態,具體,不依賴實例。abstract,抽象,依賴繼承類的具體實現)
### 3.10 final在java中的作用,有哪些用法?
- 1. 被final修飾的類不可以被繼承
- 2. 被final修飾的方法不可以被重寫
- 3. 被final修飾的變量不可以被改變.如果修飾引用,那么表示引用不可變,引用指向的內容可變.
<img src="https://i.loli.net/2020/01/31/bRdkYOoQZLz6IFt.jpg" style="zoom: 67%;" />
- 4. 被final修飾的方法,JVM會嘗試將其內聯,以提高運行效率
- 5. 被final修飾的常量,在編譯階段會存入常量池中.
除此之外,編譯器對final域要遵守的兩個重排序規則:
- 在構造函數內對一個final域的寫入,與隨后把這個被構造對象的引用賦值給一個引用變量,這兩個操作之間不能重排序
- 初次讀一個包含final域的對象的引用,與隨后初次讀這個final域,這兩個操作之間不能重排序
**寫final域重排序規則**
<img src="https://i.loli.net/2020/12/20/d39UVpmY4kIJHFe.png" alt="在這里插入圖片描述" style="zoom:50%;" />
由于a,b之間沒有數據依賴性,普通域(普通變量)a可能會被重排序到構造函數之外,線程B就有可能讀到的是普通變量a初始化之前的值(零值),這樣就可能出現錯誤。而final域變量b,根據重排序規則,會禁止final修飾的變量b重排序到構造函數之外,從而b能夠正確賦值,線程B就能夠讀到final變量初始化后的值。
寫final域的重排序規則可以確保:**在對象引用為任意線程可見之前,對象的final域已經被正確初始化過了,而普通域就不具有這個保障**。
**( 二)、讀final域重排序規則**
<img src="https://i.loli.net/2020/12/20/37nvSGgjLTC5RbZ.png" alt="在這里插入圖片描述" style="zoom:50%;" />
讀對象的普通域被重排序到了讀對象引用的前面就會出現線程B還未讀到對象引用就在讀取該對象的普通域變量,這顯然是錯誤的操作。而final域的讀操作就“限定”了在讀final域變量前已經讀到了該對象的引用,從而就可以避免這種情況。
讀final域的重排序規則可以確保:**在讀一個對象的final域之前,一定會先讀這個包含這個final域的對象的引用。**
### 3.11 抽象類和接口的區別?
#### 抽象類: abstract( is a ,模板、可以有內容)
`抽象:不具體,看不明白。抽象類表象體現。`
>在不斷抽取過程中,將**共性內容**中的方法聲明**抽取**,但是方法不一樣,沒有抽取,**這時抽取到的方法,并不具體**,需要被指定關鍵字abstract所標示,聲明為抽象方法。
>抽象方法所在類一定要標示為抽象類,也就是說該類需要被abstract關鍵字所修飾。
**抽象類的特點:**
- 1:抽象方法只能*定義在*抽象類或者接口中,由abstract關鍵字修飾(可以描述類和方法,*不可以描述變量*)。
- 2:抽象方法只定義方法*聲明*,并不定義方法*實現*。
- 3:抽象類*不可以*實例化。
- 4:只有子類繼承抽象類并**覆蓋**了抽象類中的**所有抽象方法**后,該子類才可以實例化。
- 5: 抽象類里的抽象方法必須被子類**全部實現**(除非子類也是抽象類)
- 6: 可以有**構造器**(抽象類:本質也是一個類,提供一種模板的作用)
- 7: 可以**繼承**一個類,**實現**多個接口
- 8: 可以沒有抽象方法
- 9: 抽象方法不能為private,不然不能被子類繼承實現
- 10:可以有靜態代碼塊,靜態方法
- 11: **抽象類實現一個接口時,可以不重寫接口的方法**,同理,可以用一個抽象方法去重寫接口中的方法,但是沒什么意義
**抽象類的細節:**
<font color='darkred'>1:抽象類中是否有構造函數?</font>有,用于給子類對象進行初始化。
<font color='darkred'>2:抽象類中是否可以定義非抽象方法?(模板設計模式運用)</font>
可以。其實,抽象類和一般類沒有太大的區別,都是在描述事物,只不過抽象類在描述事物時,有些功能不具體。所以抽象類和一般類在定義上,都是需要定義屬性和行為的。只不過,比一般類多了一個抽象函數。而且比一般類少了一個創建對象的部分。
<font color='darkred'>3:抽象關鍵字abstract和哪些不可以共存?</font>final , private , static
<font color='darkred'>4:抽象類中可不可以不定義抽象方法?</font>可以。抽象方法目的僅僅為了不讓該類創建對象。
**模板方法設計模式:**
解決的問題:當功能內部一部分實現時確定,一部分實現是不確定的。這時可以把不確定的部分暴露出去,讓子類去實現。
```java
abstract class GetTime{
public final void getTime(){ //此功能如果不需要復寫,可加final限定
long start = System.currentTimeMillis();
code(); //不確定的功能部分,提取出來,通過抽象方法實現
long end = System.currentTimeMillis();
System.out.println("毫秒是:"+(end-start));
}
public abstract void code(); //抽象不確定的功能,讓子類復寫實現
}
class SubDemo extends GetTime{
public void code(){ //子類復寫功能方法
for(int y=0; y<1000; y++){
System.out.println("y");
}
}
}
```
#### 接 口( like a , 定義、契約)
- 1:是用關鍵字interface定義的。
```java
interface Inter{
public static final int x = 3;
public abstract void show();
}
```
- 2:接口中有抽象方法,說明接口**不可以實例化**。接口的子類必須實現了接口中**所有的抽象方法**后,該子類**才可以實例化***(Java8 以后可以不用實現全部,但是要用default去實現一個默認方法)*。否則,該子類還是一個抽象類。
- 3:接口和類不一樣的地方,就是,接口可以被多實現,這就是多繼承改良后的結果。java將多繼承機制通過多現實來體現。
- 4:其實java中是有多繼承的。接口可以多繼承接口。*(類只能單繼承,接口可以多繼承)*
- 5: 沒有構造方法;
- 6:可以有變量和方法,但是變量被隱式地指定為public static final(也只能是此種修飾,**必須被顯式初始化**),方法被指定為public abstract。**所有的方法不能有實現。{}算作空實現。**
- JDK1.8中對接口增加了新的特性:
- 1、默認方法(default method):JDK 1.8允許給接口添加非抽象的方法實現,但必須使用default關鍵字修飾;**定義了default的方法可以不被實現子類所實現,但只能被實現子類的對象調用;如果子類實現了多個接口,并且這些接口包含一樣的默認方法,則子類必須重寫默認方法;**
- 2、靜態方法(static method):JDK 1.8中允許使用static關鍵字修飾一個方法,并提供實現,稱為接口靜態方法。接口靜態方法只能通過接口調用(接口名.靜態方法名)
- 7: 不能有靜態代碼塊以及靜態方法
- 8: **接口可以繼承多個接口,但是不能繼承任何類,不能實現任何接口**
`抽象是重構的結果,接口是設計的結果。`從設計層面上看,抽象類提供了一種 IS-A 關系,那么就必須滿足里式替換原則,即子類對象必須能夠替換掉所有父類對象。而接口更像是一種 LIKE-A 關系,它只是提供一種方法實現契約,并不要求接口和實現接口的類具有 IS-A 關系。
從 Java 8 開始,接口也可以擁有默認的方法實現,這是因為不支持默認方法的接口的維護成本太高了。在 Java 8 之前,如果一個接口想要添加新的方法,那么要修改所有實現了該接口的類。*(關鍵字: default 在接口中方法前面加上修飾符default 編譯器就會認為該方法并非抽象方法,可以在接口中寫實現。)
```java
interface jiekou{
default public int fun(){return 2;};
}
class AAA implements jiekou{//重寫接口默認方法
@Override
public int fun() {return 0;}
}
class BBB implements jiekou{}
public class Main {
public static void main(String[] args) {
AAA aaa = new AAA();
System.out.println(aaa.fun());//0
BBB bbb = new BBB();
System.out.println(bbb.fun());//2
}
}
```
**接口的理解**
接口都用于設計上,設計上的特點:(可以理解主板上提供的接口)
1:接口是對外提供的規則。
2:接口是功能的擴展。
3:接口的出現降低了耦合性。
**抽象類與接口:**
`抽象類`:一般用于描述一個體系單元,將一組**共性內容**進行抽取,特點:可以在類中定義**抽象內容**讓**子類實現**,可以定義**非抽象內容**讓**子類直接使用**。它里面定義的都是一些體系中的基本內容。
`接口`:一般用于**定義**對象的**擴展功能**,是在繼承之外還需這個對象具備的一些功能。
#### 抽象類和接口的共性:
都是不斷向上抽取的結果。
#### 抽象類和接口的區別:
| 抽象類 | 接口 |
| ------------------------------------------------------------ | --------------------------------------------------------- |
| 成員修飾符**可自定義**,比如*抽象類的非抽象方法可以用private*。 | 成員修飾符是**固定的**。全都是**public**的 |
| 只能被繼承,只能*單繼承* | 需要被實現,可以*多實現* |
| 可以定義非抽象方法,子類可以直接繼承使用 | 所有都抽象方法,需要子類去實現。(Java8以后可以有默認實現) |
| 使用的是 *is a*關系 | 使用的 *like a* 關系 |
| 可以有普通變量 | 不可以有,但可以有final static常量 |
| 可以有靜態方法 | 不可以有靜態方法 |
在開發之前,先定義規則,A和B分別開發,A負責實現這個規則,B負責使用這個規則。至于A是如何對規則具體實現的,B是不需要知道的。這樣這個接口的出現就降低了A和B直接耦合性。
### 3.12 Hashcode的作用
java的集合有兩類,一類是List,還有一類是Set。前者有序可重復,后者無序不重復。當我們在set中插入的時候怎么判斷是否已經存在該
元素呢,可以通過equals方法。但是如果元素太多,用這樣的方法就會比較滿。
于是有人發明了哈希算法來提高集合中查找元素的效率。 這種方式將集合分成若干個存儲區域,每個對象可以計算出一個哈希碼,可以將
哈希碼分組,每組分別對應某個存儲區域,根據一個對象的哈希碼就可以確定該對象應該存儲的那個區域。
hashCode方法可以這樣理解:它返回的就是根據對象的內存地址換算出的一個值。這樣一來,當集合要添加新的元素時,先調用這個元素
的hashCode方法,就一下子能定位到它應該放置的物理位置上。如果這個位置上沒有元素,它就可以直接存儲在這個位置上,不用再進行
任何比較了;如果這個位置上已經有元素了,就調用它的equals方法與新元素進行比較,相同的話就不存了,不相同就散列其它的地址。這
樣一來實際調用equals方法的次數就大大降低了,幾乎只需要一兩次。
### 3.13 Java的四種引用,強弱軟虛
#### 強引用
強引用是平常中使用最多的引用,強引用在程序內存不足(OOM)的時候也不會被回收,使用方式:
```java
String str = new String("str");
```
#### 軟引用
軟引用在程序內存不足時,會被回收,使用方式:
```java
// 注意:wrf這個引用也是強引用,它是指向SoftReference這個對象的,
// 這里的軟引用指的是指向new String("str")的引用,也就是SoftReference類中T
SoftReference<String> wrf = new SoftReference<String>(new String("str"));
```
可用場景: 創建緩存的時候,創建的對象放進緩存中,當內存不足時,JVM就會回收早先創建的對象。
#### 弱引用
弱引用就是只要JVM垃圾回收器發現了它,就會將之回收,使用方式:
```java
WeakReference<String>wrf=newWeakReference<String>(str);
```
可用場景:Java源碼中的java.util.WeakHashMap中的key就是使用弱引用,我的理解就是,
一旦我不需要某個引用,JVM會自動幫我處理它,這樣我就不需要做其它操作。
#### 虛引用
虛引用的回收機制跟弱引用差不多,但是它被回收之前,會被放入ReferenceQueue中。注意哦,其它引用是被JVM回收后才被傳入
ReferenceQueue中的。由于這個機制,所以虛引用大多被用于引用銷毀前的處理工作。還有就是,虛引用創建的時候,必須帶有
ReferenceQueue,使用
```java
PhantomReference<String>prf=newPhantomReference<String>(new String("str"),newReferenceQueue<>());
```
可用場景: 對象銷毀前的一些操作,比如說資源釋放等。** Object.finalize() 雖然也可以做這類動作,但是這個方式即不安全又低效
上訴所說的幾類引用,都是指對象本身的引用,而不是指 Reference 的四個子類的引用( SoftReference 等)。
### 3.14 Java創建對象有幾種方式?
java中提供了以下四種創建對象的方式:
1. new創建新對象
2. 通過反射機制
3. 采用clone機制
4. 通過序列化機制
### 3.15 有沒有可能兩個不相等的對象有相同的hashcode
有可能.在產生hash沖突時,兩個不相等的對象就會有相同的 hashcode 值.當hash沖突產生時,一般有以下幾種方式來處理:
1. 拉鏈法:每個哈希表節點都有一個next指針,多個哈希表節點可以用next指針構成一個單向鏈表,被分配到同一個索引上的多個節點可以
用這個單向鏈表進行存儲.
2. 開放定址法:一旦發生了沖突,就去尋找下一個空的散列地址,只要散列表足夠大,空的散列地址總能找到,并將記錄存入
3. 再哈希:又叫雙哈希法,有多個不同的Hash函數.當發生沖突時,使用第二個,第三個….等哈希函數計算地址,直到無沖突.
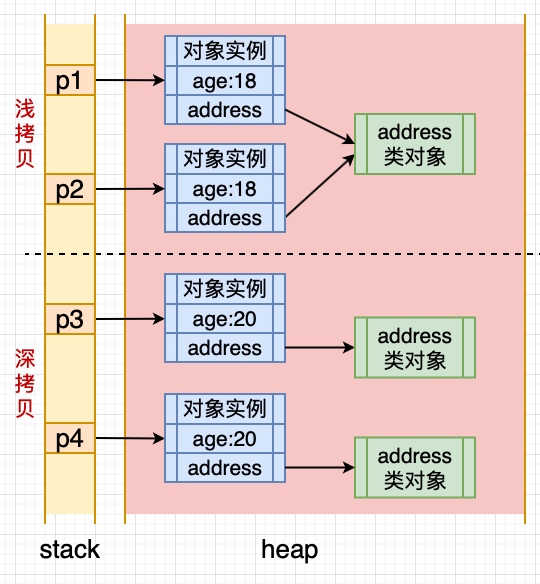
### 3.16 拷貝和淺拷貝的區別是什么?
`淺拷貝`:拷貝對象和原始對象的引用類型引用同一個對象。直接調用clone方法。
`深拷貝`:拷貝對象和原始對象的引用類型引用不同對象。**要克隆**的類和類中所有**非基本數據類型**的屬性**對應的類**。先調用clone方法獲得相關屬性,再依次復制到自己的類中。
`clone的替代方案`:使用 clone() 方法來拷貝一個對象即復雜又有風險,它會拋出異常,并且還需要類型轉換。Effective Java 書上講到,最好不要去使用 clone(),可以使用拷貝構造函數或者`拷貝工廠`來拷貝一個對象。
### 3.17 a=a+b與a+=b有什么區別嗎?
+= 操作符會進行隱式自動類型轉換,此處a+=b隱式的將加操作的結果類型強制轉換為持有結果的類型, 而a=a+b則不會自動進行類型轉換.
如:
```java
byte a = 127;
byte b = 127;
b = a + b; // 報編譯錯誤:cannot convert from int to byte
b += a;
```
以下代碼是否有錯,有的話怎么改?
```java
short s1= 1;
s1 = s1 + 1;
```
有錯誤.short類型在進行運算時會自動提升為int類型,也就是說 s1+1 的運算結果是int類型,而s1是short類型,此時編譯器會報錯.
```java
short s1= 1;
s1 += 1;//+=操作符會對右邊的表達式結果強轉匹配左邊的數據類型,所以沒錯.
```
### 3.18 char 型變量中能不能存貯一個中文漢字,為什么?
char 類型可以存儲一個中文漢字,因為 Java 中使用的編碼是 Unicode(不選擇任何特定的編碼,直接使用字符在字符集中的編號,這是統一的唯一方法),一個 char 類型占 2 個字節(16 比特),所以放一個中文是沒問題的。
### 3.19 如何實現對象克隆?
有兩種方式:
1). 實現 Cloneable 接口并重寫 Object 類中的 clone()方法;
2). 實現 Serializable 接口,通過對象的序列化和反序列化實現克隆,可以實現真正的深度克隆,代碼如下。
```java
public class MyUtil {
@SuppressWarnings("unchecked")
public static <T extends Serializable> T clone(T obj) throws Exception {
ByteArrayOutputStream bout = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bout);
oos.writeObject(obj);
ByteArrayInputStream bin = new
ByteArrayInputStream(bout.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bin);
return (T) ois.readObject();
// 說明:調用 ByteArrayInputStream 或 ByteArrayOutputStream對象的 close 方法沒有任何意義
// 這兩個基于內存的流只要垃圾回收器清理對象就能夠釋放資源,這一點不同于對外部資源(如文件流)的釋放
}
}
```
注意:基于 序列 化和 反序 列化 實現 的克 隆不 僅僅 是深 度克 隆, 更重 要的 是通 過泛型限 定, 可以 檢查 出要 克隆 的對 象是 否支 持
序 列化 ,這 項檢 查是 編譯 器完 成的 ,不是 在運 行時 拋出 異常 ,這種 是方 案明 顯優 于使 用 Object 類的 clone 方法 克隆 對象。 讓問
題在 編譯 的時 候暴 露出 來總 是好 過把 問題 留到 運行 時。
### 3.20 一個”.java”源文件中是否可以包含多個類(不是內部類)?有什么限制?
可以,但一個源文件中最多只能有一個公開類(public class)而且文件名必須和公開類的類名完全保持一致。
### 3.21 異或運算
& | ^
&& 和 ||具有短路功能
快速將某數擴大或縮小,使用<<< 或者>>> 無符號位移
test:不使用第三方變量進行兩個值互換( ^ :相同為0,不同為1)
```java
int a =3,b=5;
a = a+b;
b = a-b;
a = a-b;
a = a^b;
b = a^b;
a = a^b;
```
### 3.22 switch語句相關
```java
switch(變量){
case 值:要執行的語句;break;
...
default:要執行的語句;
}
```
細節:
- 1)break是可以省略的,如果省略了就一直執行遇到break為止;
- 2)switch小括號中的變量為**char, byte, short, int, Character, Byte, Short, Integer, String,enum** *(注意long類型不可以,因為不能隱式轉換為int,JDK7前:只有改數據類型可以自動轉型為int時才可以,JDK7后,String類型也支持);*
- 3)default可以寫在switch中的任意位置,如果將default放在第一行,不管expression與case中的value是否匹配,程序會從default開始執行到第一個break出現。
### 3.23 初始化順序
1. 類中的屬性都會被自動初始化(類加載的準備階段,<font color='darkred'>基本類型為0,引用對象為null</font>),方法中的不會
2. **繼承情況下初始化順序**
```java
class Father {
Father() {System.out.println("父類的構造器");}
int i = fatherCommonMethod();
static String s = fatherStaticMethod();
static void fatherStaticMethod() {
System.out.println("父類的靜態方法");
}
void fatherCommonMethod() {
System.out.println("父類的普通方法");
}
}
class Son extends Father {
Son(){System.out.println("子類的構造器");}
int j = sonCommonMethod();
static String s = sonStaticMethod();
static void sonStaticMethod() {
System.out.println("子類的靜態方法");
}
void sonCommonMethod() {
System.out.println("子類的普通方法");
}
}
```
output
```java
父類的靜態方法
子類的靜態方法
父類的普通方法
父類的構造器
子類的普通方法
子類的構造器
```
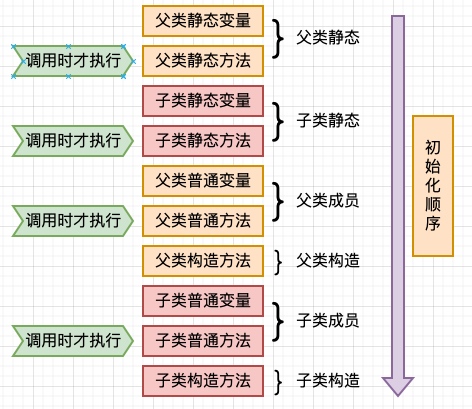
父類靜態變量,父類靜態代碼塊(并列優先級,按照代碼中出現的先后順序執行,且只有第一次加載時執行) -->子類靜態變量,子類靜態代碼塊(同上,按出現順序) -->main方法 -->父變量,父初始塊(按出現順序) --> 父構造器 -->子變量,子初始塊(按出現順序) -->子構造器
### 3.24 泛型
jdk1.5之后出現的一種安全機制。表現格式:< >
只要帶有<>的類或者接口,都屬于帶有類型參數的類或者接口,在使用這些類或者接口時,必須給<>中傳遞一個具體的引用數據類型。
`作用`:在編譯期間確保了正確性
`好處`:
1:將運行時期的問題ClassCastException問題轉換成了編譯失敗,體現在編譯時期,程序員就可以解決問題。
2:避免了強制轉換的麻煩。
```java
/*
第一個問題是有關get方法的,我們每次調用get方法都會返回一個Object對象,
每一次都要強制類型轉換為我們需要的類型,這樣會顯得很麻煩;
第二個問題是有關add方法的,假如我們往聚合了String對象的ArrayList中
加入一個File對象,編譯器不會產生任何錯誤提示,而這不是我們想要的。
*/
public class ArrayList {
public Object get(int i) { ... }
public void add(Object o) { ... }
...
private Object[] elementData;
}
```
所以,從Java 5開始,ArrayList在使用時可以加上一個類型參數(type parameter),這個類型參數用來指明ArrayList中的元素類型。類型參數的引入解決了以上提到的兩個問題
```java
ArrayList<String> s = new ArrayList<String>();
s.add("abc");
String s = s.get(0); //無需進行強制轉換
s.add(123); //編譯錯誤,只能向其中添加String對象
...
```
`原理`:內部使用object對象或者指定的邊界類型,在編譯后變成強制轉換。
`泛型擦除`:在編輯器檢查泛型類型的正確性后,生成的類文件中是沒有泛型的。
```java
//定義泛型
public class Pair<T, U> {
private T first;
private U second;
public Pair(T first, U second) {
this.first = first;
this.second = second;
}
public T getFirst() {return first;}
public U getSecond() {return second;}
public void setFirst(T newValue) {first = newValue;}
public void setSecond(U newValue) {second = newValue;}
}
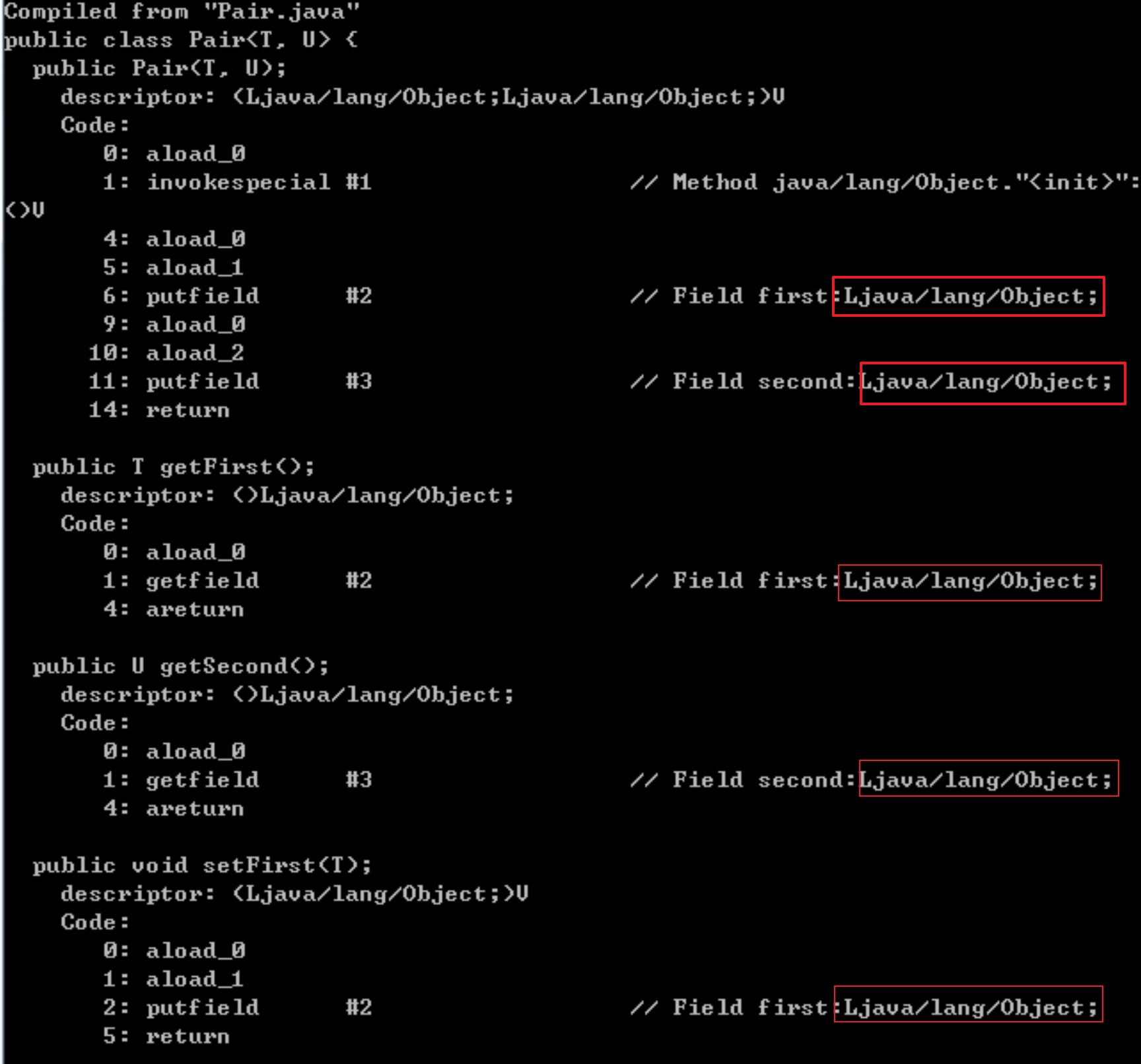
// 實際上,從虛擬機的角度看,不存在“泛型”概念。
//比如上面我們定義的泛型類Pair,在虛擬機看來(即編譯為字節碼后),它長的是這樣的:
public class Pair {
private Object first;
private Object second;
public Pair(Object first, Object second) {
this.first = first;
this.second = second;
}
public Object getFirst() {return first;}
public Object getSecond() {return second;}
public void setFirst(Object newValue) {first = newValue;}
public void setSecond(Object newValue) {second = newValue;}
}
```
簡單地驗證下,編譯Pair.java后,鍵入“javap -c -s Pair”可得到:
`泛型補償`:在編譯時已經確定是同一個類型的元素,在運行時內部進行一次轉換,使用者無需再做轉換動作。
由于在虛擬機中泛型類Pair變為它的raw type,因而getFirst方法返回的是一個Object對象,而從編譯器的角度看,這個方法返回的是我們實例化類時指定的類型參數的對象。實際上, 是編譯器幫我們完成了強制類型轉換的工作。也就是說編譯器會把對Pair泛型類中getFirst方法的調用轉化為兩條虛擬機指令:
```
第一條是對raw type方法getFirst的調用,這個方法返回一個Object對象;
第二條指令把返回的Object對象強制類型轉換為當初我們指定的類型參數類型。
```
```java
public class Pair<T, U> {
//請見上面貼出的代碼
public static void main(String[] args) {
String first = "first", second = "second";
Pair<String, String> p = new Pair<String, String>(first, second);
String result = p.getFirst();
}
}
```
看字節碼
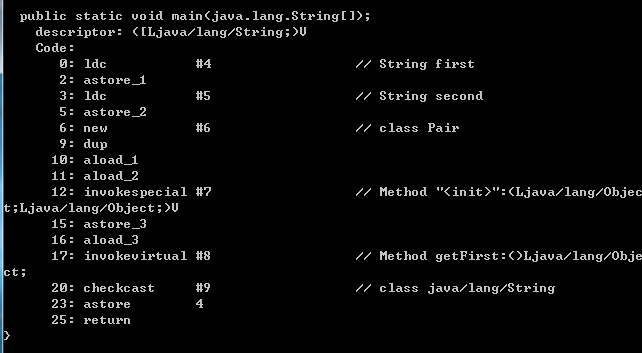
標著”17:"的那行,根據后面的注釋,我們知道這是對getFirst方法的調用,可以看到他的返回類型的確是Object。標著“20:"的那行,是一個checkcast指令,字面上我們就可以知道這條指令的含義是檢查類型轉換是否成功,再看后面的注釋,我們這里確實存在一個到String的強制類型轉換。
#### 什么時候用泛型類呢?
當類中的操作的引用數據類型不確定的時候,以前用的Object來進行擴展的,現在可以用泛型來表示。這樣可以避免強轉的麻煩,而且將運行問題轉移到的編譯時期。
泛型在程序定義上的體現:
```java
//泛型類:將泛型定義在類上。
class Tool<Q> {
private Q obj;
public void setObject(Q obj) {
this.obj = obj;
}
public Q getObject() {
return obj;
}
}
//當方法操作的引用數據類型不確定的時候,可以將泛型定義在方法上。
public <W> void method(W w) {
System.out.println("method:"+w);
}
//靜態方法上的泛型:靜態方法無法訪問類上定義的泛型。
//如果靜態方法操作的引用數據類型不確定的時候,必須要將泛型定義在方法上。
public static <Q> void function(Q t) {
System.out.println("function:"+t);
}
//泛型接口.
interface Inter<T> {
void show(T t);
}
class InterImpl<R> implements Inter<R> {
public void show(R r) {
System.out.println("show:"+r);
}
}
```
`泛型中的通配符:`可以解決當具體類型不確定的時候,這個通配符就是 **?** ;當操作類型時,不需要使用類型的具體功能時,只使用Object類中的功能。那么可以用 ? 通配符來表未知類型。
#### 泛型限定:
? `上限`:`?extends E`:可以接收E類型或者E的子類型對象。稱為**通配符的子類型限定**
? `下限`:`?super E`:可以接收E類型或者E的父類型對象。稱為**通配符的超類型限定**
**上限什么時候用:**往集合中*添加元素*時,既可以添加E類型對象,又可以添加E的子類型對象。為什么?因為取的時候,E類型既可以接收E類對象,又可以接收E的子類型對象。
**下限什么時候用:**當從集合中*獲取元素*進行操作的時候,可以用當前元素的類型接收,也可以用當前元素的父類型接收。
**不能有靜態泛型變量**
a) 靜態方法無法訪問類上定義的泛型,如果靜態方法操作的引用類型不確定時,必須要將泛型定義在靜態方法上。
b) 不能構建泛型數組,只能構建object數組,再進行(E[])強制轉換
c) 泛型類可以new,但是無法使用其方法
d) 不能拋出或者捕獲泛型類對象,但是在異常規范中可以使用泛型變量
e) 泛型在指定類型后,可以存入其子類(ArrayList<father>中可以存入son)
`限定`:extends && super 可以有多個限定,限定類型用&分割,限定中最多只有一個類,且要放到限定的第一個
`?和T的區別`:?代表任意,T代表T這個類型,可以在類中使用此類型。T主要用于聲明一個泛型類或者泛型方法,?主要用于使用泛型類或者泛型方法
? 聲明的泛型中,不能寫入,不能作為返回值
T 不支持 T super E這種,只能寫 ? super E這種形式
介紹類型通配符前,首先介紹兩點:
(1)假設Student是People的子類,Pair<Student, Student>卻不是Pair<People, People>的子類,它們之間不存在"is-a"關系。
(2)Pair<T, T>與它的原始類型Pair之間存在”is-a"關系,Pair<T, T>在任何情況下都可以轉換為Pair類型。
現在考慮這樣一個方法:
```java
public static void printName(Pair<People, People> p) {
People p1 = p.getFirst();
System.out.println(p1.getName()); //假設People類定義了getName實例方法
}
```
在以上的方法中,我們想要同時能夠傳入Pair<Student, Student>和Pair<People, People>類型的參數,然而二者之間并不存在"is-a"關系。在這種情況下,Java提供給我們這樣一種解決方案:使用Pair<? extends People>作為形參的類型。也就是說,Pair<Student, Student>和Pair<People, People>都可以看作是Pair<? extends People>的子類。
現在我們考慮下面這段代碼:
```java
Pair<Student> students = new Pair<Student>(student1, student2);
Pair<? extends People> wildchards = students;
wildchards.setFirst(people1);
```
以上代碼的第三行會報錯,因為wildchards是一個Pair<? extends People>對象,它的setFirst方法和getFirst方法是這樣的:
```java
void setFirst(? extends People)
? extends People getFirst()
```
對于setFirst方法來說,會使得編譯器不知道形參究竟是什么類型(只知道是People的子類),而我們試圖傳入一個People對象,編譯器無法判定People和形參類型是否是”is-a"的關系,所以調用setFirst方法會報錯。而調用wildchards的getFirst方法是合法的,因為我們知道它會返回一個People的子類,而People的子類“always is a People”。(總是可以把子類對象轉換為父類對象)
而對于通配符的超類型限定的情況下,調用getter方法是非法的,而調用setter方法是合法的。
除了子類型限定和超類型限定,還有一種通配符叫做無限定的通配符,它是這樣的:<?>。這個東西我們什么時候會用到呢?考慮一下這個場景,我們調用一個會返回一個getPairs方法,這個方法會返回一組Pair<T, T>對象。其中既有Pair<Student, Student>, 還有Pair<Teacher, Teacher>對象。(Student類和Teacher類不存在繼承關系)顯然,這種情況下,子類型限定和超類型限定都不能用。這時我們可以用這樣一條語句搞定它:
```java
Pair<?>[] pairs = getPairs(...);
```
對于無限定的通配符,調用getter方法和setter方法都是非法的。
PECS(Producer Extends Consumer Super)原則:
* 頻繁往外讀取內容的,適合用上界Extends(知道上界,取出來直接用父類執行取出的對象即可)
* 經常往里插入的,適合用下界Super(知道下界,那么存比下界小的元素都可以,往外取的時候只能存放到object對象中)
參考:
- http://www.ciaoshen.com/java/2016/08/21/superExtends.html
- http://www.ciaoshen.com/java/2016/08/21/wildcards.html
- http://www.cnblogs.com/absfree/p/5270883.html#undefined
### 3.25 枚舉
使用關鍵字enum定義的枚舉類型,在編譯期后,也將轉換成為一個實實在在的類(繼承Enum類),而在該類中,會存在每個在枚舉類型中定義好變量的對應實例對象,如上述的MONDAY枚舉類型對應public static final Day MONDAY;,同時編譯器會為該類創建兩個方法,分別是values()和valueOf()。
- 1. **枚舉不允許繼承類。**Jvm在生成枚舉時已經繼承了Enum類,由于Java語言是單繼承,不支持再繼承額外的類(唯一的繼承名額被Jvm用了)。
- 2. **枚舉允許實現接口。**因為枚舉本身就是一個類,類是可以實現多個接口的。
- 3. **枚舉可以用等號比較。**Jvm會為每個枚舉實例對應生成一個類對象,這個類對象是用public static final修飾的,在static代碼塊中初始化,是一個單例。
- 4. **不可以繼承枚舉。**因為Jvm在生成枚舉類時,將它聲明為final。
- 5. 枚舉本身就是一種對**單例設計模式**友好的形式,它是實現單例模式的一種很好的方式。
- 6. 枚舉類型的**compareTo()**方法比較的是枚舉類對象的ordinal的值。
- 7. 枚舉類型的**equals()**方法比較的是枚舉類對象的內存地址,作用與等號等價。
```java
public enum EnumTest {
SUCESS("1","成功");
private String code;
private String desc;
EnumTest(String code, String desc) {
this.code = code;
this.desc = desc;
}
public String getCode(){
return code;
}
public String getDesc(){
return desc;
}
}
```
* 一定要把枚舉變量的定義放在第一行,并且以分號結尾。
* 構造函數必須私有化。事實上,private是多余的,你完全沒有必要寫,因為它默認并強制是private,如果你要寫,也只能寫private,寫public是不能通過編譯的。
* 自定義變量與默認的ordinal屬性并不沖突,ordinal還是按照它的規則給每個枚舉變量按順序賦值。
### 3.26 反射
>反射機制是在**運行狀態**中,對于*任意一個類*,都能夠知道這個類的所有*屬性*和*方法*;對于*任意一個對象*,都能夠調用它的任意一個*方法*和*屬性*;這種**動態獲取**的信息以及**動態調用**對象的方法的功能稱為java語言的反射機制。
每一個類都有一個Class對象。Class對象是在類加載的時候由Java虛擬機以及通過調用類加載器中的 defineClass 方法自動構造的。hotspot虛擬機中class對象存在方法區中。
java源文件被編譯成java字節碼(class文件)時,會在這個字節碼文件中加上一個Class對象。
類的class屬性是Class類的實例,這個class對象的內容是類的信息
#### 3.26.1 反射機制中的類
* `java.lang.Class;` Class對象類
* `java.lang.reflect.Constructor;` 構造函數類
* `java.lang.reflect.Field;` 類屬性類
* `java.lang.reflect.Method;` 方法類
* `java.lang.reflect.Modifier;` 修飾符類
#### 3.26.2 獲取Class對象
* 調用某個對象的`getClass()`方法。
```java
Person p= new Person(); Class clazz=p.getClass();
```
* 調用某個類的`class屬性`來獲取該類對應的Class對象。
```java
Class clazz = Person.class;
```
* 使用Class類中的`forName()`靜態方法。
```java
Class clazz = Class.forName(“類的全路徑”)。
```
#### 3.26.3 獲取屬性&方法&構造函數
```java
Method[] method=clazz.getDeclaredMethods();
Field[] field=clazz.getDeclaredFields();
Constructor[] constructor=clazz.getDeclaredConstructors();
```
#### 3.26.4 創建對象
* 1. 使用 Class 對象的 `newInstance()`方法來創建該 Class 對象對應類的實例,但是這種方法要求該 Class 對象對應的類有**默認的空構造器**。
* 2. 先使用 Class 對象獲取指定的 `Constructor對象`,再調用 Constructor 對象的 newInstance()方法來創建 Class 對象對應類的實例,通過這種方法可以選定構造方法創建實例。
```java
Constructor c=
clazz.getDeclaredConstructor(String.class,String.class,int.class);
Person p1=(Person) c.newInstance("李四","男",20);
```
#### 3.26.5 設置屬性&調用方法
調用類方法:**invoke(Object obj, Object... args)**,obj是類對象,args是方法中的可變參數列表
```java
Class<?> clazz = Class.forName("net.xsoftlab.baike.TestReflect");
// 調用TestReflect類中的reflect1方法
Method method = clazz.getMethod("reflect1");
method.invoke(clazz.newInstance());
```
field.set(Object obj, Object value):**obj是對象實例,value是要設置的屬性值**
```java
Class<?> clazz = Class.forName("net.xsoftlab.baike.TestReflect");
Object obj = clazz.newInstance();
// 可以直接對 private 的屬性賦值
Field field = clazz.getDeclaredField("proprety");
field.setAccessible(true);
field.set(obj, "Java反射機制");
```
* `ClassforName(...)` 方法,除了將類的 `.class` 文件加載到JVM 中之外,還會對類進行解釋,執行類中的 `static` 塊。
* ClassLoader 只干一件事情,就是將 `.class` 文件加載到 JVM 中,不會執行 `static` 中的內容,只有在 newInstance 才會去執行 `static` 塊。
#### 3.26.6 反射機制的優缺點:
**優點:**
1)能夠運行時動態獲取類的實例,提高靈活性;
2)與動態編譯結合
Class.forName('com.mysql.jdbc.Driver.class');//加載MySQL的驅動類
**缺點:**
1)使用反射性能較低,需要解析字節碼,將內存中的對象進行解析。
**解決方案:**
1、通過setAccessible(true)關閉JDK的安全檢查來提升反射速度;
2、多次創建一個類的實例時,有緩存會快很多
3、ReflflectASM工具類,通過字節碼生成的方式加快反射速度
2)相對不安全,破壞了封裝性(因為通過反射可以獲得私有方法和屬性)
#### 3.26.7 反射使用步驟(獲取 Class 對象、調用對象方法)
1. 獲取想要操作的類的 Class 對象,他是反射的核心,通過 Class 對象我們可以任意調用類的方法。
2. 調用 Class 類中的方法,既就是反射的使用階段。
3. 使用反射 API 來操作這些信息。
### 3.27 序列化
序列化就是將一個對象轉換成字節序列,方便存儲和傳輸。
* 序列化:`ObjectOutputStream.writeObject()`
* 反序列化:`ObjectInputStream.readObject()`
**不會對靜態變量進行序列化**,*因為序列化只是保存對象的狀態,靜態變量屬于類的狀態。*
序列化的類需要實現 `Serializable 接口`,它只是一個標準,沒有任何方法需要實現,但是如果不去實現它的話而進行序列化,會拋出異常。
`transient` 關鍵字可以使一些屬性不會被序列化。
ArrayList 中存儲數據的數組 elementData 是用 transient 修飾的,因為這個數組是動態擴展的,并不是所有的空間都被使用,因此就**不需要所有的內容都被序列化**。通過重寫序列化和反序列化方法,使得可以只序列化數組中有內容的那部分數據。
```java
transient Object[] elementData;
//重寫序列化方法
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
int expectedModCount = modCount;
s.defaultWriteObject();
s.writeInt(size);
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
//反序列化方法
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
s.defaultReadObject();
s.readInt();
if (size > 0) {
SharedSecrets.getJavaObjectInputStreamAccess()
.checkArray(s, Object[].class, size);
Object[] elements = new Object[size];
for (int i = 0; i < size; i++) {
elements[i] = s.readObject();
}
elementData = elements;
} else if (size == 0) {
elementData = EMPTY_ELEMENTDATA;
} else {
throw new java.io.InvalidObjectException("Invalid size: " + size);
}
}
```
### 3.28 Object的方法
#### 概覽
```java
public native int hashCode()
public boolean equals(Object obj)
protected native Object clone() throws CloneNotSupportedException
public String toString()
public final native Class<?> getClass()
protected void finalize() throws Throwable {}
public final native void notify()
public final native void notifyAll()
public final native void wait(long timeout) throws InterruptedException
public final void wait(long timeout, int nanos) throws InterruptedException
public final void wait() throws InterruptedException
```
#### equals
**1. 等價關系**
* `自反性`:x.equals(x); // true
* `對稱性`:x.equals(y) == y.equals(x); // true
* `傳遞性`:if (x.equals(y) && y.equals(z)){ x.equals(z);} // true;
* `一致性`:多次調用結果不變。x.equals(y) == x.equals(y); // true
* `與null比較`:對任何不是 null 的對象 x 調用 x.equals(null) 結果都為 false
**2. 等價與相等**
默認的equals實現是 return == 比較兩個對象是否為同一個對象
* 對于`基本類型`,== 判斷兩個值是否相等,基本類型沒有 equals() 方法。
* 對于`引用類型`,== 判斷兩個變量是否引用同一個對象,而 equals() 判斷引用的對象是否等價(需要自己重寫)。
#### hashCode
- hashCode() 返回散列值,而 equals() 是用來判斷兩個對象是否等價。等價的兩個對象散列值一定相同,但是散列值相同的兩個對象不一定等價。
- 在覆蓋 equals() 方法時應當總是覆蓋 hashCode() 方法,保證等價的兩個對象散列值也相等。
#### toString
默認返回 ToStringExample@4554617c 這種形式,其中 @ 后面的數值為散列碼的無符號十六進制表示。
#### clone
clone() 是 Object 的 protected 方法,它不是 public,一個類不顯式去重寫 clone(),其它類就不能直接去調用該類實例的 clone() 方法。應該注意的是,clone() 方法并不是 Cloneable 接口的方法,而是 Object 的一個 protected 方法。Cloneable 接口只是規定,如果一個類沒有實現 Cloneable 接口又調用了 clone() 方法,就會拋出 CloneNotSupportedException。
#### finalize
`final`用于聲明屬性,方法和類,分別表示**屬性不可變,方法不可覆蓋,類不可繼承**。
`finally`是異常處理語句結構的一部分,表示總是執行。
`finalize`是Object類的一個方法,在垃圾收集器執行的時候會調用被回收對象的此方法,可以覆蓋此方法提供垃圾收集時的其他資源的回收,例如關閉文件等。垃圾收集器會先執行對象的finalize方法,但不保證會執行完畢(死循環或執行很緩慢的情況會被強行終止),此為第一次標記。第二次檢查時,如果對象仍然不可達,才會執行回收
### 3.29 異常
java異常類層次結構
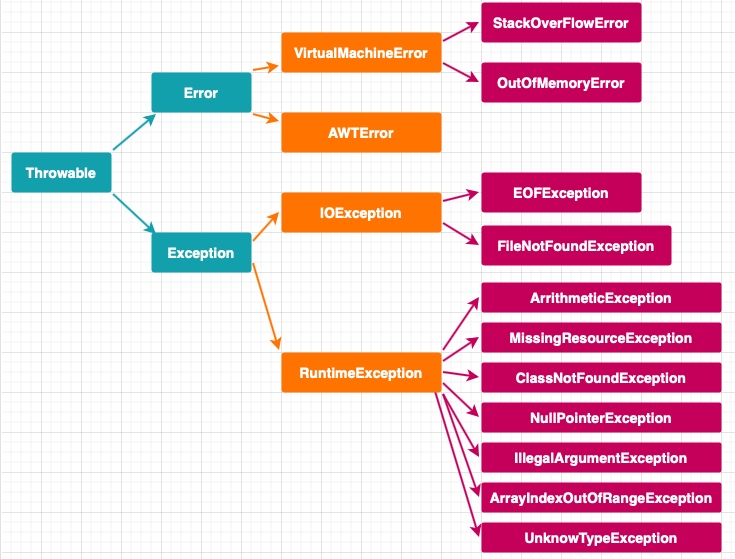
祖先java.lang包中的 **Throwable類**。Throwable: 有兩個重要的子類:**Exception(異常)** 和 **Error(錯誤)** ,二者都是 Java 異常處理的重要子類,各自都包含大量子類。
**Error(錯誤):是程序無法處理的錯誤**,表示運行應用程序中較嚴重問題。大多數錯誤與代碼編寫者執行的操作無關,而表示代碼運行時 JVM(Java 虛擬機)出現的問題。例如,Java虛擬機運行錯誤(Virtual MachineError),當 JVM 不再有繼續執行操作所需的內存資源時,將出現 OutOfMemoryError。這些異常發生時,Java虛擬機(JVM)一般會選擇線程終止。
這些錯誤表示故障發生于虛擬機自身、或者發生在虛擬機試圖執行應用時,如Java虛擬機運行錯誤(Virtual MachineError)、類定義錯誤(NoClassDefFoundError)等。這些錯誤是不可查的,因為它們在應用程序的控制和處理能力之 外,而且絕大多數是程序運行時不允許出現的狀況。對于設計合理的應用程序來說,即使確實發生了錯誤,本質上也不應該試圖去處理它所引起的異常狀況。在 Java中,錯誤通過Error的子類描述。
**Exception(異常):是程序本身可以處理的異常**。Exception 類有一個重要的子類 **RuntimeException**。RuntimeException 異常由Java虛擬機拋出。**NullPointerException**(要訪問的變量沒有引用任何對象時,拋出該異常)、**ArithmeticException**(算術運算異常,一個整數除以0時,拋出該異常)和 **ArrayIndexOutOfBoundsException** (下標越界異常)。
**注意:異常和錯誤的區別:異常能被程序本身可以處理,錯誤是無法處理。**
throw是拋出具體的異常,throws是用于在方法上指定沒有處理的異常。
#### try catch fifinally,try里有return,finally還執行么?
執行,并且finally的執行早于try里面的return
結論:
1、不管有木有出現異常,finally塊中代碼都會執行;
2、當try和catch中有return時,finally仍然會執行;
3、finally是在return后面的表達式運算后執行的(此時并沒有返回運算后的值,而是先把要返回的值保存起來,管finally中的代碼怎么樣,
返回的值都不會改變,任然是之前保存的值),所以函數返回值是在finally執行前確定的;
4、finally中最好不要包含return,否則程序會提前退出,返回值不是try或catch中保存的返回值。
#### Thow與thorws區別
**位置不同**
1. throws 用在函數上,后面跟的是異常類,可以跟多個;而 throw 用在函數內,后面跟的
是異常對象。
**功能不同:**
1. throws 用來聲明異常,讓調用者只知道該功能可能出現的問題,可以給出預先的處理方
式;throw 拋出具體的問題對象,執行到 throw,功能就已經結束了,跳轉到調用者,并
將具體的問題對象拋給調用者。也就是說 throw 語句獨立存在時,下面不要定義其他語
句,因為執行不到。
2. throws 表示出現異常的一種可能性,并不一定會發生這些異常;throw 則是拋出了異常,
執行 throw 則一定拋出了某種異常對象。
3. 兩者都是消極處理異常的方式,只是拋出或者可能拋出異常,但是不會由函數去處理異
常,真正的處理異常由函數的上層調用處理。