# 基礎的數據結構
這篇文章不是講解數據結構的文章,而是結合現實的場景幫助大家`理解和復習`數據結構與算法,如果你的數據結構基礎很差,建議先去看一些基礎教程,再轉過來看。
本篇文章的定位是側重于前端的,通過學習前端中實際場景的數據結構,從而加深大家對數據結構的理解和認識。
## 線性結構
數據結構我們可以從邏輯上分為線性結構和非線性結構。線性結構有數組,棧,鏈表等, 非線性結構有樹,圖等。
> 其實我們可以稱樹為一種半線性結構。
需要注意的是,線性和非線性不代表存儲結構是線性的還是非線性的,這兩者沒有任何關系,它只是一種邏輯上的劃分。
比如我們可以用數組去存儲二叉樹。
一般而言,有前驅和后繼的就是線性數據結構。比如數組和鏈表。
> 其實一叉樹就是鏈表。
### 數組
數組是最簡單的數據結構了,很多地方都用到它。 比如有一個數據列表等,用它是再合適不過了。
其實后面的數據結構很多都有數組的影子。
我們之后要講的棧和隊列其實都可以看成是一種`受限`的數組,怎么個受限法呢?我們后面討論。
我們來講幾個有趣的例子來加深大家對數組這種數據結構的理解。
#### React Hooks
Hooks 的本質就是一個數組, 偽代碼:

那么為什么 hooks 要用數組? 我們可以換個角度來解釋,如果不用數組會怎么樣?
```js
function Form() {
// 1. Use the name state variable
const [name, setName] = useState("Mary");
// 2. Use an effect for persisting the form
useEffect(function persistForm() {
localStorage.setItem("formData", name);
});
// 3. Use the surname state variable
const [surname, setSurname] = useState("Poppins");
// 4. Use an effect for updating the title
useEffect(function updateTitle() {
document.title = name + " " + surname;
});
// ...
}
```
基于數組的方式,Form 的 hooks 就是 [hook1, hook2, hook3, hook4]。
進而我們可以得出這樣的關系, hook1 就是 [name, setName] 這一對,hook2 就是 persistForm 這個。
如果不用數組實現,比如對象,Form 的 hooks 就是
```js
{
'key1': hook1,
'key2': hook2,
'key3': hook3,
'key4': hook4,
}
```
那么問題是 key1,key2,key3,key4 怎么取呢?這就是個問題了。更多關于 React hooks 的本質研究,請查看 [React hooks: not magic, just arrays](https://medium.com/@ryardley/react-hooks-not-magic-just-arrays-cd4f1857236e)
不過使用數組也有一個問題, 那就是 React 將`如何確保組件內部 hooks 保存的狀態之間的對應關系`這個工作交給了開發人員去保證,即你必須保證 HOOKS 的順序嚴格一致,具體可以看 React 官網關于 Hooks Rule 部分。
### 隊列
隊列是一種受限的序列,它只能夠操作隊尾和隊首,并且只能只能在隊尾添加元素,在隊首刪除元素。
隊列作為一種最常見的數據結構同樣有著非常廣泛的應用, 比如消息隊列
> "隊列"這個名稱,可類比為現實生活中排隊(不插隊的那種)
在計算機科學中,一個 隊列 (queue) 是一種特殊類型的抽象數據類型或集合,集合中的實體按順序保存。
隊列基本操作有兩種:
- 向隊列的后端位置添加實體,稱為入隊
- 從隊列的前端位置移除實體,稱為出隊。
隊列中元素先進先出 FIFO (first in, first out) 的示意:
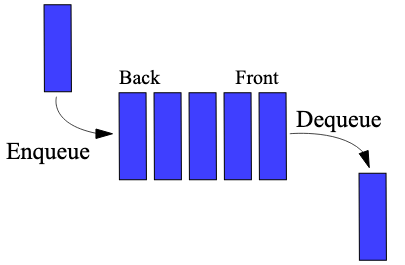
(圖片來自 https://github.com/trekhleb/javascript-algorithms/blob/master/src/data-structures/queue/README.zh-CN.md)
我們前端在做性能優化的時候,很多時候會提到的一點就是“HTTP 1.1 的隊頭阻塞問題”,具體來說
就是 HTTP2 解決了 HTTP1.1 中的隊頭阻塞問題,但是為什么 HTTP1.1 有隊頭阻塞問題,HTTP2 究竟怎么解決的這個問題,很多人都不清楚。
其實`隊頭阻塞`是一個專有名詞,不僅僅在 HTTP 有,交換器等其他地方也都涉及到了這個問題。實際上引起這個問題的根本原因是使用了`隊列`這種數據結構。
協議規定, 對于同一個 tcp 連接,所有的 http1.0 請求放入隊列中,只有前一個`請求的響應`收到了,才能發送下一個請求,這個時候就發生了阻塞,并且這個阻塞主要發生在客戶端。
這就好像我們在等紅綠燈,即使旁邊綠燈亮了,你的這個車道是紅燈,你還是不能走,還是要等著。

`HTTP/1.0` 和 `HTTP/1.1`:
在`HTTP/1.0` 中每一次請求都需要建立一個 TCP 連接,請求結束后立即斷開連接。
在`HTTP/1.1` 中,每一個連接都默認是長連接 (persistent connection)。對于同一個 tcp 連接,允許一次發送多個 http1.1 請求,也就是說,不必等前一個響應收到,就可以發送下一個請求。這樣就解決了 http1.0 的客戶端的隊頭阻塞,而這也就是`HTTP/1.1`中`管道 (Pipeline)`的概念了。
但是,`http1.1 規定,服務器端的響應的發送要根據請求被接收的順序排隊`,也就是說,先接收到的請求的響應也要先發送。這樣造成的問題是,如果最先收到的請求的處理時間長的話,響應生成也慢,就會阻塞已經生成了的響應的發送,這也會造成隊頭阻塞。可見,http1.1 的隊首阻塞是發生在服務器端。
如果用圖來表示的話,過程大概是:

`HTTP/2` 和 `HTTP/1.1`:
為了解決`HTTP/1.1`中的服務端隊首阻塞,`HTTP/2`采用了`二進制分幀` 和 `多路復用` 等方法。
幀是`HTTP/2`數據通信的最小單位。在 `HTTP/1.1` 中數據包是文本格式,而 `HTTP/2` 的數據包是二進制格式的,也就是二進制幀。
采用幀的傳輸方式可以將請求和響應的數據分割得更小,且二進制協議可以更地被高效解析。`HTTP/2`中,同域名下所有通信都在單個連接上完成,該連接可以承載任意數量的雙向數據流。每個數據流都以消息的形式發送,而消息又由一個或多個幀組成。多個幀之間可以亂序發送,根據幀首部的流標識可以重新組裝。
`多路復用`用以替代原來的序列和擁塞機制。在`HTTP/1.1`中,并發多個請求需要多個 TCP 鏈接,且單個域名有 6-8 個 TCP 鏈接請求限制(這個限制是瀏覽器限制的,不同的瀏覽器也不一定一樣)。在`HTTP/2`中,同一域名下的所有通信在單個鏈接完成,僅占用一個 TCP 鏈接,且在這一個鏈接上可以并行請求和響應,互不干擾。
> [此網站](https://http2.akamai.com/demo) 可以直觀感受 `HTTP/1.1` 和 `HTTP/2` 的性能對比。
### 棧
棧也是一種受限的序列,它只能夠操作棧頂,不管入棧還是出棧,都是在棧頂操作。
在計算機科學中,一個棧 (stack) 是一種抽象數據類型,用作表示元素的集合,具有兩種主要操作:
- push, 添加元素到棧的頂端(末尾)
- pop, 移除棧最頂端(末尾)的元素
以上兩種操作可以簡單概括為**后進先出 (LIFO = last in, first out)**。
此外,應有一個 peek 操作用于訪問棧當前頂端(末尾)的元素。(只返回不彈出)
> "棧"這個名稱,可類比于一組物體的堆疊(一摞書,一摞盤子之類的)。
棧的 push 和 pop 操作的示意:

(圖片來自 https://github.com/trekhleb/javascript-algorithms/blob/master/src/data-structures/stack/README.zh-CN.md)
棧在很多地方都有著應用,比如大家熟悉的瀏覽器就有很多棧,其實瀏覽器的執行棧就是一個基本的棧結構,從數據結構上說,它就是一個棧。
這也就解釋了,我們用遞歸的解法和用循環+棧的解法本質上是差不多的。
比如如下 JS 代碼:
```js
function bar() {
const a = 1;
const b = 2;
console.log(a, b);
}
function foo() {
const a = 1;
bar();
}
foo();
```
真正執行的時候,內部大概是這樣的:

> 我畫的圖沒有畫出執行上下文中其他部分(this 和 scope 等), 這部分是閉包的關鍵,而我這里不是講閉包的,是為了講解棧的。
> 社區中有很多“執行上下文中的 scope 指的是執行棧中父級聲明的變量”說法,這是完全錯誤的, JS 是詞法作用域,scope 指的是函數定義時候的父級,和執行沒關系
棧常見的應用有進制轉換,括號匹配,棧混洗,中綴表達式(用的很少),后綴表達式(逆波蘭表達式)等。
合法的棧混洗操作也是一個經典的題目,這其實和合法的括號匹配表達式之間存在著一一對應的關系,也就是說 n 個元素的棧混洗有多少種,n 對括號的合法表達式就有多少種。感興趣的可以查找相關資料。
### 鏈表
鏈表是一種最基本數據結構,熟練掌握鏈表的結構和常見操作是基礎中的基礎。

(圖片來自: https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/linked-list/traversal)
#### React Fiber
很多人都說 fiber 是基于鏈表實現的,但是為什么要基于鏈表呢,可能很多人并沒有答案,那么我覺得可以把這兩個點(fiber 和鏈表)放到一起來講下。
fiber 出現的目的其實是為了解決 react 在執行的時候是無法停下來的,需要一口氣執行完的問題的。

> 圖片來自 Lin Clark 在 ReactConf 2017 分享
上面已經指出了引入 fiber 之前的問題,就是 react 會阻止優先級高的代碼(比如用戶輸入)執行。因此他們打算自己自建一個`虛擬執行棧`來解決這個問題,這個虛擬執行棧的底層實現就是鏈表。
Fiber 的基本原理是將協調過程分成小塊,一次執行一塊,然后將運算結果保存起來,并判斷是否有時間繼續執行下一塊(react 自己實現了一個類似 requestIdleCallback 的功能)。如果有時間,則繼續。 否則跳出,讓瀏覽器主線程歇一會,執行別的優先級高的代碼。
當協調過程完成(所有的小塊都運算完畢), 那么就會進入提交階段, 執行真正的進行副作用(side effect)操作,比如更新 DOM,這個過程是沒有辦法取消的,原因就是這部分有副作用。
問題的關鍵就是將協調的過程劃分為一塊塊的,最后還可以合并到一起,有點像 Map/Reduce。
React 必須重新實現遍歷樹的算法,從依賴于`內置堆棧的同步遞歸模型`,變為`具有鏈表和指針的異步模型`。
> Andrew 是這么說的: 如果你只依賴于 [內置] 調用堆棧,它將繼續工作直到堆棧為空。
如果我們可以隨意中斷調用堆棧并手動操作堆棧幀,那不是很好嗎?
這就是 React Fiber 的目的。 `Fiber 是堆棧的重新實現,專門用于 React 組件`。 你可以將單個 Fiber 視為一個`虛擬堆棧幀`。
react fiber 大概是這樣的:
```js
let fiber = {
tag: HOST_COMPONENT,
type: "div",
return: parentFiber,
children: childFiber,
sibling: childFiber,
alternate: currentFiber,
stateNode: document.createElement("div"),
props: { children: [], className: "foo" },
partialState: null,
effectTag: PLACEMENT,
effects: [],
};
```
從這里可以看出 fiber 本質上是個對象,使用 parent,child,sibling 屬性去構建 fiber 樹來表示組件的結構樹,
return, children, sibling 也都是一個 fiber,因此 fiber 看起來就是一個鏈表。
> 細心的朋友可能已經發現了, alternate 也是一個 fiber, 那么它是用來做什么的呢?
> 它其實原理有點像 git, 可以用來執行 git revert ,git commit 等操作,這部分挺有意思,我會在我的《從零開發 git》中講解
想要了解更多的朋友可以看 [這個文章](https://github.com/dawn-plex/translate/blob/master/articles/the-how-and-why-on-reacts-usage-of-linked-list-in-fiber-to-walk-the-components-tree.md)
如果可以翻墻, 可以看 [英文原文](https://medium.com/react-in-depth/the-how-and-why-on-reacts-usage-of-linked-list-in-fiber-67f1014d0eb7)
[這篇文章](https://engineering.hexacta.com/didact-fiber-incremental-reconciliation-b2fe028dcaec) 也是早期講述 fiber 架構的優秀文章
我目前也在寫關于《從零開發 react 系列教程》中關于 fiber 架構的部分,如果你對具體實現感興趣,歡迎關注。
## 非線性結構
那么有了線性結構,我們為什么還需要非線性結構呢? 答案是為了高效地兼顧靜態操作和動態操作。大家可以對照各種數據結構的各種操作的復雜度來直觀感受一下。
### 樹
樹的應用同樣非常廣泛,小到文件系統,大到因特網,組織架構等都可以表示為樹結構,而在我們前端眼中比較熟悉的 DOM 樹也是一種樹結構,而 HTML 作為一種 DSL 去描述這種樹結構的具體表現形式。如果你接觸過 AST,那么 AST 也是一種樹,XML 也是樹結構。樹的應用遠比大多數人想象的要多得多。
樹其實是一種特殊的`圖`,是一種無環連通圖,是一種極大無環圖,也是一種極小連通圖。
從另一個角度看,樹是一種遞歸的數據結構。而且樹的不同表示方法,比如不常用的`長子 + 兄弟`法,對于
你理解樹這種數據結構有著很大用處, 說是一種對樹的本質的更深刻的理解也不為過。
樹的基本算法有前中后序遍歷和層次遍歷,有的同學對前中后這三個分別具體表現的訪問順序比較模糊,其實當初我也是一樣的,后面我學到了一點,你只需要記住:`所謂的前中后指的是根節點的位置,其他位置按照先左后右排列即可`。比如前序遍歷就是`根左右`, 中序就是`左根右`,后序就是`左右根`, 很簡單吧?
我剛才提到了樹是一種遞歸的數據結構,因此樹的遍歷算法使用遞歸去完成非常簡單,幸運的是樹的算法基本上都要依賴于樹的遍歷。
但是遞歸在計算機中的性能一直都有問題,因此掌握不那么容易理解的"命令式地迭代"遍歷算法在某些情況下是有用的。如果你使用迭代式方式去遍歷的話,可以借助上面提到的`棧`來進行,可以極大減少代碼量。
> 如果使用棧來簡化運算,由于棧是 FILO 的,因此一定要注意左右子樹的推入順序。
樹的重要性質:
- 如果樹有 n 個頂點,那么其就有 n - 1 條邊,這說明了樹的頂點數和邊數是同階的。
- 任何一個節點到根節點存在`唯一`路徑,路徑的長度為節點所處的深度
實際使用的樹有可能會更復雜,比如使用在游戲中的碰撞檢測可能會用到四叉樹或者八叉樹。以及 k 維的樹結構 `k-d 樹`等。

(圖片來自 https://zh.wikipedia.org/wiki/K-d%E6%A0%91)
### 二叉樹
二叉樹是節點度數不超過二的樹,是樹的一種特殊子集,有趣的是二叉樹這種被限制的樹結構卻能夠表示和實現所有的樹,
它背后的原理正是`長子 + 兄弟`法,用鄧老師的話說就是`二叉樹是多叉樹的特例,但在有根且有序時,其描述能力卻足以覆蓋后者`。
> 實際上, 在你使用`長子 + 兄弟`法表示樹的同時,進行 45 度角旋轉即可。
一個典型的二叉樹:
標記為 7 的節點具有兩個子節點,標記為 2 和 6; 一個父節點,標記為 2, 作為根節點,在頂部,沒有父節點。

(圖片來自 https://github.com/trekhleb/javascript-algorithms/blob/master/src/data-structures/tree/README.zh-CN.md)
對于一般的樹,我們通常會去遍歷,這里又會有很多變種。
下面我列舉一些二叉樹遍歷的相關算法:
- [94.binary-tree-inorder-traversal](../problems/94.binary-tree-inorder-traversal.md)
- [102.binary-tree-level-order-traversal](../problems/102.binary-tree-level-order-traversal.md)
- [103.binary-tree-zigzag-level-order-traversal](../problems/103.binary-tree-zigzag-level-order-traversal.md)
- [144.binary-tree-preorder-traversal](../problems/144.binary-tree-preorder-traversal.md)
- [145.binary-tree-postorder-traversal](../problems/145.binary-tree-postorder-traversal.md)
- [199.binary-tree-right-side-view](../problems/199.binary-tree-right-side-view.md)
相關概念:
- 真二叉樹 (所有節點的度數只能是偶數,即只能為 0 或者 2)
另外我也專門開設了 [二叉樹的遍歷](./binary-tree-traversal.md) 章節,具體細節和算法可以去那里查看。
#### 堆
堆其實是一種優先級隊列,在很多語言都有對應的內置數據結構,很遺憾 javascript 沒有這種原生的數據結構。
不過這對我們理解和運用不會有影響。
堆的特點:
- 在一個 最小堆 (min heap) 中,如果 P 是 C 的一個父級節點,那么 P 的 key(或 value) 應小于或等于 C 的對應值。
正因為此,堆頂元素一定是最小的,我們會利用這個特點求最小值或者第 k 小的值。

- 在一個 最大堆 (max heap) 中,P 的 key(或 value) 大于 C 的對應值。

需要注意的是優先隊列不僅有堆一種,還有更復雜的,但是通常來說,我們會把兩者做等價。
相關算法:
- [295.find-median-from-data-stream](../problems/295.find-median-from-data-stream.md)
#### 二叉查找樹
二叉排序樹(Binary Sort Tree),又稱二叉查找樹(Binary Search Tree),亦稱二叉搜索樹。
二叉查找樹具有下列性質的二叉樹:
- 若左子樹不空,則左子樹上所有節點的值均小于它的根節點的值;
- 若右子樹不空,則右子樹上所有節點的值均大于它的根節點的值;
- 左、右子樹也分別為二叉排序樹;
- 沒有鍵值相等的節點。
對于一個二叉查找樹,常規操作有插入,查找,刪除,找父節點,求最大值,求最小值。
二叉查找樹,之所以叫查找樹就是因為其非常適合查找,舉個例子,
如下一顆二叉查找樹,我們想找節點值小于且最接近 58 的節點,搜索的流程如圖所示:

(圖片來自 https://www.geeksforgeeks.org/floor-in-binary-search-tree-bst/)
另外我們二叉查找樹有一個性質是: `其中序遍歷的結果是一個有序數組`。
有時候我們可以利用到這個性質。
相關題目:
- [98.validate-binary-search-tree](../problems/98.validate-binary-search-tree.md)
### 二叉平衡樹
平衡樹是計算機科學中的一類數據結構,是一種改進的二叉查找樹。一般的二叉查找樹的查詢復雜度取決于目標結點到樹根的距離(即深度),因此當結點的深度普遍較大時,查詢的均攤復雜度會上升。為了實現更高效的查詢,產生了平衡樹。
在這里,平衡指所有葉子的深度趨于平衡,更廣義的是指在樹上所有可能查找的均攤復雜度偏低。
一些數據庫引擎內部就是用的這種數據結構,其目標也是將查詢的操作降低到 logn(樹的深度),可以簡單理解為`樹在數據結構層面構造了二分查找算法`。
基本操作:
- 旋轉
- 插入
- 刪除
- 查詢前驅
- 查詢后繼
#### AVL
是最早被發明的自平衡二叉查找樹。在 AVL 樹中,任一節點對應的兩棵子樹的最大高度差為 1,因此它也被稱為高度平衡樹。查找、插入和刪除在平均和最壞情況下的時間復雜度都是 O(logn)。增加和刪除元素的操作則可能需要借由一次或多次樹旋轉,以實現樹的重新平衡。AVL 樹得名于它的發明者 G. M. Adelson-Velsky 和 Evgenii Landis,他們在 1962 年的論文 An algorithm for the organization of information 中公開了這一數據結構。 節點的平衡因子是它的左子樹的高度減去它的右子樹的高度(有時相反)。帶有平衡因子 1、0 或 -1 的節點被認為是平衡的。帶有平衡因子 -2 或 2 的節點被認為是不平衡的,并需要重新平衡這個樹。平衡因子可以直接存儲在每個節點中,或從可能存儲在節點中的子樹高度計算出來。
#### 紅黑樹
在 1972 年由魯道夫·貝爾發明,被稱為"對稱二叉 B 樹",它現代的名字源于 Leo J. Guibas 和 Robert Sedgewick 于 1978 年寫的一篇論文。紅黑樹的結構復雜,但它的操作有著良好的最壞情況運行時間,并且在實踐中高效:它可以在 O(logn) 時間內完成查找,插入和刪除,這里的 n 是樹中元素的數目
### 字典樹(前綴樹)
又稱 Trie 樹,是一種樹形結構。典型應用是用于統計,排序和保存大量的字符串(但不僅限于字符串),所以經常被搜索引擎系統用于文本詞頻統計。它的優點是:利用字符串的公共前綴來減少查詢時間,最大限度地減少無謂的字符串比較,查詢效率比哈希樹高。

(圖來自 https://baike.baidu.com/item/%E5%AD%97%E5%85%B8%E6%A0%91/9825209?fr=aladdin)
它有 3 個基本性質:
- 根節點不包含字符,除根節點外每一個節點都只包含一個字符;
- 從根節點到某一節點,路徑上經過的字符連接起來,為該節點對應的字符串;
- 每個節點的所有子節點包含的字符都不相同。
#### immutable 與 字典樹
`immutableJS`的底層就是`share + tree`. 這樣看的話,其實和字典樹是一致的。
相關算法:
- [208.implement-trie-prefix-tree](../problems/208.implement-trie-prefix-tree.md)
- [211.add-and-search-word-data-structure-design](../problems/211.add-and-search-word-data-structure-design.md)
- [212.word-search-ii](../problems/212.word-search-ii.md)
## 圖
前面講的數據結構都可以看成是圖的特例。 前面提到了二叉樹完全可以實現其他樹結構,
其實有向圖也完全可以實現無向圖和混合圖,因此有向圖的研究一直是重點考察對象。
圖論〔Graph Theory〕是數學的一個分支。它以圖為研究對象。圖論中的圖是由若干給定的點及連接兩點的線所構成的圖形,這種圖形通常用來描述某些事物之間的某種特定關系,用點代表事物,用連接兩點的線表示相應兩個事物間具有這種關系。
## 圖的表示方法
- 鄰接矩陣(常見)
空間復雜度 O(n^2),n 為頂點個數。
優點:
1. 直觀,簡單。
2. 適用于稠密圖
3. 判斷兩個頂點是否連接,獲取入度和出度以及更新度數,時間復雜度都是 O(1)
- 關聯矩陣
- 鄰接表
對于每個點,存儲著一個鏈表,用來指向所有與該點直接相連的點
對于有權圖來說,鏈表中元素值對應著權重
例如在無向無權圖中:

(圖片來自 https://zhuanlan.zhihu.com/p/25498681)
可以看出在無向圖中,鄰接矩陣關于對角線對稱,而鄰接鏈表總有兩條對稱的邊
而在有向無權圖中:

(圖片來自 https://zhuanlan.zhihu.com/p/25498681)
## 圖的遍歷
圖的遍歷就是要找出圖中所有的點,一般有以下兩種方法:
1. 深度優先遍歷:(Depth First Search, DFS)
深度優先遍歷圖的方法是,從圖中某頂點 v 出發, 不斷訪問鄰居, 鄰居的鄰居直到訪問完畢。
2. 廣度優先搜索:(Breadth First Search, BFS)
廣度優先搜索,可以被形象地描述為 "淺嘗輒止",它也需要一個隊列以保持遍歷過的頂點順序,以便按出隊的順序再去訪問這些頂點的鄰接頂點。
- 前言
- 第一章 - 算法專題
- 數據結構
- 二叉樹的遍歷
- 動態規劃
- 哈夫曼編碼和游程編碼
- 布隆過濾器
- 字符串問題
- 前綴樹專題
- 《貪婪策略》專題
- 《深度優先遍歷》專題
- 滑動窗口(思路 + 模板)
- 位運算
- 設計題
- 小島問題
- 最大公約數
- 并查集
- 平衡二叉樹專題
- 第二章 - 91 天學算法
- 第一期講義-二分法
- 第一期講義-雙指針
- 第二期
- 第三章 - 精選題解
- 《日程安排》專題
- 《構造二叉樹》專題
- 字典序列刪除
- 百度的算法面試題 * 祖瑪游戲
- 西法的刷題秘籍】一次搞定前綴和
- 字節跳動的算法面試題是什么難度?
- 字節跳動的算法面試題是什么難度?(第二彈)
- 《我是你的媽媽呀》 * 第一期
- 一文帶你看懂二叉樹的序列化
- 穿上衣服我就不認識你了?來聊聊最長上升子序列
- 你的衣服我扒了 * 《最長公共子序列》
- 一文看懂《最大子序列和問題》
- 第四章 - 高頻考題(簡單)
- 面試題 17.12. BiNode
- 0001. 兩數之和
- 0020. 有效的括號
- 0021. 合并兩個有序鏈表
- 0026. 刪除排序數組中的重復項
- 0053. 最大子序和
- 0088. 合并兩個有序數組
- 0101. 對稱二叉樹
- 0104. 二叉樹的最大深度
- 0108. 將有序數組轉換為二叉搜索樹
- 0121. 買賣股票的最佳時機
- 0122. 買賣股票的最佳時機 II
- 0125. 驗證回文串
- 0136. 只出現一次的數字
- 0155. 最小棧
- 0167. 兩數之和 II 輸入有序數組
- 0169. 多數元素
- 0172. 階乘后的零
- 0190. 顛倒二進制位
- 0191. 位1的個數
- 0198. 打家劫舍
- 0203. 移除鏈表元素
- 0206. 反轉鏈表
- 0219. 存在重復元素 II
- 0226. 翻轉二叉樹
- 0232. 用棧實現隊列
- 0263. 丑數
- 0283. 移動零
- 0342. 4的冪
- 0349. 兩個數組的交集
- 0371. 兩整數之和
- 0437. 路徑總和 III
- 0455. 分發餅干
- 0575. 分糖果
- 0874. 模擬行走機器人
- 1260. 二維網格遷移
- 1332. 刪除回文子序列
- 第五章 - 高頻考題(中等)
- 0002. 兩數相加
- 0003. 無重復字符的最長子串
- 0005. 最長回文子串
- 0011. 盛最多水的容器
- 0015. 三數之和
- 0017. 電話號碼的字母組合
- 0019. 刪除鏈表的倒數第N個節點
- 0022. 括號生成
- 0024. 兩兩交換鏈表中的節點
- 0029. 兩數相除
- 0031. 下一個排列
- 0033. 搜索旋轉排序數組
- 0039. 組合總和
- 0040. 組合總和 II
- 0046. 全排列
- 0047. 全排列 II
- 0048. 旋轉圖像
- 0049. 字母異位詞分組
- 0050. Pow(x, n)
- 0055. 跳躍游戲
- 0056. 合并區間
- 0060. 第k個排列
- 0062. 不同路徑
- 0073. 矩陣置零
- 0075. 顏色分類
- 0078. 子集
- 0079. 單詞搜索
- 0080. 刪除排序數組中的重復項 II
- 0086. 分隔鏈表
- 0090. 子集 II
- 0091. 解碼方法
- 0092. 反轉鏈表 II
- 0094. 二叉樹的中序遍歷
- 0095. 不同的二叉搜索樹 II
- 0096. 不同的二叉搜索樹
- 0098. 驗證二叉搜索樹
- 0102. 二叉樹的層序遍歷
- 0103. 二叉樹的鋸齒形層次遍歷
- 0113. 路徑總和 II
- 0129. 求根到葉子節點數字之和
- 0130. 被圍繞的區域
- 0131. 分割回文串
- 0139. 單詞拆分
- 0144. 二叉樹的前序遍歷
- 0150. 逆波蘭表達式求值
- 0152. 乘積最大子數組
- 0199. 二叉樹的右視圖
- 0200. 島嶼數量
- 0201. 數字范圍按位與
- 0208. 實現 Trie (前綴樹)
- 0209. 長度最小的子數組
- 0211. 添加與搜索單詞 * 數據結構設計
- 0215. 數組中的第K個最大元素
- 0221. 最大正方形
- 0229. 求眾數 II
- 0230. 二叉搜索樹中第K小的元素
- 0236. 二叉樹的最近公共祖先
- 0238. 除自身以外數組的乘積
- 0240. 搜索二維矩陣 II
- 0279. 完全平方數
- 0309. 最佳買賣股票時機含冷凍期
- 0322. 零錢兌換
- 0328. 奇偶鏈表
- 0334. 遞增的三元子序列
- 0337. 打家劫舍 III
- 0343. 整數拆分
- 0365. 水壺問題
- 0378. 有序矩陣中第K小的元素
- 0380. 常數時間插入、刪除和獲取隨機元素
- 0416. 分割等和子集
- 0445. 兩數相加 II
- 0454. 四數相加 II
- 0494. 目標和
- 0516. 最長回文子序列
- 0518. 零錢兌換 II
- 0547. 朋友圈
- 0560. 和為K的子數組
- 0609. 在系統中查找重復文件
- 0611. 有效三角形的個數
- 0718. 最長重復子數組
- 0754. 到達終點數字
- 0785. 判斷二分圖
- 0820. 單詞的壓縮編碼
- 0875. 愛吃香蕉的珂珂
- 0877. 石子游戲
- 0886. 可能的二分法
- 0900. RLE 迭代器
- 0912. 排序數組
- 0935. 騎士撥號器
- 1011. 在 D 天內送達包裹的能力
- 1014. 最佳觀光組合
- 1015. 可被 K 整除的最小整數
- 1019. 鏈表中的下一個更大節點
- 1020. 飛地的數量
- 1023. 駝峰式匹配
- 1031. 兩個非重疊子數組的最大和
- 1104. 二叉樹尋路
- 1131.絕對值表達式的最大值
- 1186. 刪除一次得到子數組最大和
- 1218. 最長定差子序列
- 1227. 飛機座位分配概率
- 1261. 在受污染的二叉樹中查找元素
- 1262. 可被三整除的最大和
- 1297. 子串的最大出現次數
- 1310. 子數組異或查詢
- 1334. 閾值距離內鄰居最少的城市
- 1371.每個元音包含偶數次的最長子字符串
- 第六章 - 高頻考題(困難)
- 0004. 尋找兩個正序數組的中位數
- 0023. 合并K個升序鏈表
- 0025. K 個一組翻轉鏈表
- 0030. 串聯所有單詞的子串
- 0032. 最長有效括號
- 0042. 接雨水
- 0052. N皇后 II
- 0084. 柱狀圖中最大的矩形
- 0085. 最大矩形
- 0124. 二叉樹中的最大路徑和
- 0128. 最長連續序列
- 0145. 二叉樹的后序遍歷
- 0212. 單詞搜索 II
- 0239. 滑動窗口最大值
- 0295. 數據流的中位數
- 0301. 刪除無效的括號
- 0312. 戳氣球
- 0335. 路徑交叉
- 0460. LFU緩存
- 0472. 連接詞
- 0488. 祖瑪游戲
- 0493. 翻轉對
- 0887. 雞蛋掉落
- 0895. 最大頻率棧
- 1032. 字符流
- 1168. 水資源分配優化
- 1449. 數位成本和為目標值的最大數字
- 后序