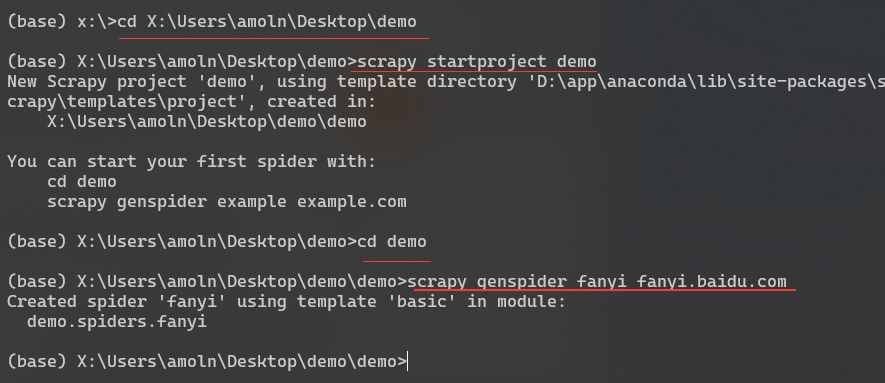
* 選擇一個文件夾用cmd進入,并執行創建項目語句
* cd進`demo`并創建爬蟲類
```
cd X:\Users\amoln\Desktop\demo
scrapy startproject demo
scrapy genspider fanyi fanyi.baidu.com
```
* 生成的文件
```
X:.
│ scrapy.cfg
│
└─demo
│ items.py 用于存放爬蟲爬取數據的模型
│ middlewares.py 用于存放各種中間件的文件
│ pipelines.py 用來將items的模型存儲到本地磁盤中
│ settings.py 本爬蟲的一些配置信息(比如請求頭信息,多久發送一次請求,ip代理池)
│ __init__.py
│
└──spiders 爬蟲書寫文件夾
│ fanyi.py 爬蟲文件
└─ __init__.py
```
* 修改配置文件`settings.py`
```
LOG_LEVEL = 'ERROR' # 隱藏無用shell輸出
DOWNLOAD_DELAY = 0.1 #延遲時間
ROBOTSTXT_OBEY = False #不遵守robots.txt 的規則
import os
FILEPATH = os.path.dirname(os.path.abspath(__file__))
IMGFILEPATH = FILEPATH + "/img/"
# 圖片下載地址
IMAGES_STORE = IMGFILEPATH #定義圖片下載地址為項目下img文件夾
IMAGES_EXPIRES = 90 # 過期天數
IMAGES_MIN_HEIGHT = 100 # 圖片的最小高度
IMAGES_MIN_WIDTH = 100 # 圖片的最小寬度
# 定義響應頭防止被墻
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'
}
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
RETRY_HTTP_CODES = [500, 502, 503, 504, 400, 403, 408]
```
* 修改爬蟲文件` fanyi.py` 輸出爬取狀態
```
import scrapy
class FanyiSpider(scrapy.Spider):
name = 'fanyi'
allowed_domains = ['fanyi.baidu.com'] # 定義只爬取變量內的網站
start_urls = ["https://fanyi.baidu.com/#en/zh/Hello%20friend!%20I'm%20a%20bard"]
# 定義爬取的url,
def parse(self, response): # 爬蟲啟動后進入parse方法
print(response) # 輸出爬取狀態 200為成功獲取內容
```
* cd進項目文件夾并執行`fanyi.py`爬蟲
```
cd demo
scrapy crawl fanyi
```