
本文對應視頻:https://www.bilibili.com/video/BV1Da411Y76u/
前面兩小節白話完之后,舉一個專業點的例子。說明一下消息隊列在實際開發中的一個典型的應用場景。
### 用戶訂單處理
先看下面的這個模型,用戶通過瀏覽器瀏覽商品并進行下單的動作。用戶下單之后,應用程序通常會做如下的一些操作:
1. 訂單管理:為用戶生成訂單
2. 庫存管理:商品庫存減1
3. 積分管理:為用戶增加積分
**請求同步處理模型:**

如果按照上圖的操作,用戶下單之后,依次同步進行訂單、庫存、積分管理操作。這樣做的缺點是用戶等待的時間會較長,特別是在系統用戶量大、并發度高的情況下,可能會出現用戶下單之后頁面超長等待的現象。"哎呀,怎么這么慢,是不是沒成功啊,再點幾下,欸欸,電腦怎么卡死了。"
**請求異步處理模型:**
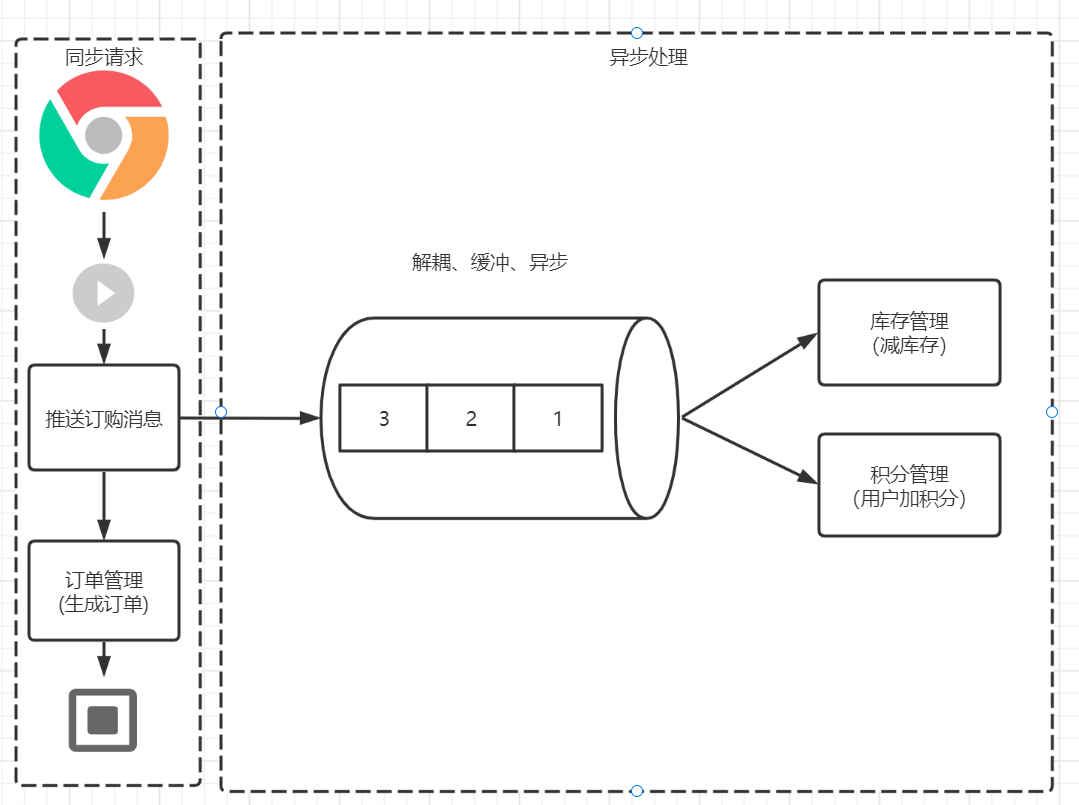
為了有效地提升用戶的體驗,可以在用戶下單之后,**將訂購消息發送至消息隊列(kafka的延時可以做到毫秒級)**,之后生成訂單,返回給用戶一個訂購成功的消息。用戶直接跳轉到訂單支付頁面。大家看到這里的就涉及到同步和異步。
* 同步:推送消息和訂單管理是同步進行的,為什么?因為訂單的生成是不允許延時操作的,必須先有訂單用戶才能進行支付操作。
* 異步:庫存管理和積分管理是異步操作?因為用戶下單之后并不會關心商品庫存是不是減少了;對于自己購買商品的積分,用戶通常也不會特別關注時效性。所以采用異步處理方式。
因此通過異步操作,我們**減少了同步操作的步驟,縮短用戶瀏覽等待時間,提升了用戶體驗**。除此之外,消息隊列可以有效地進行系統功能解耦,采用異步處理模型,能夠有效的進行服務解耦。
**單體應用與服務解耦**
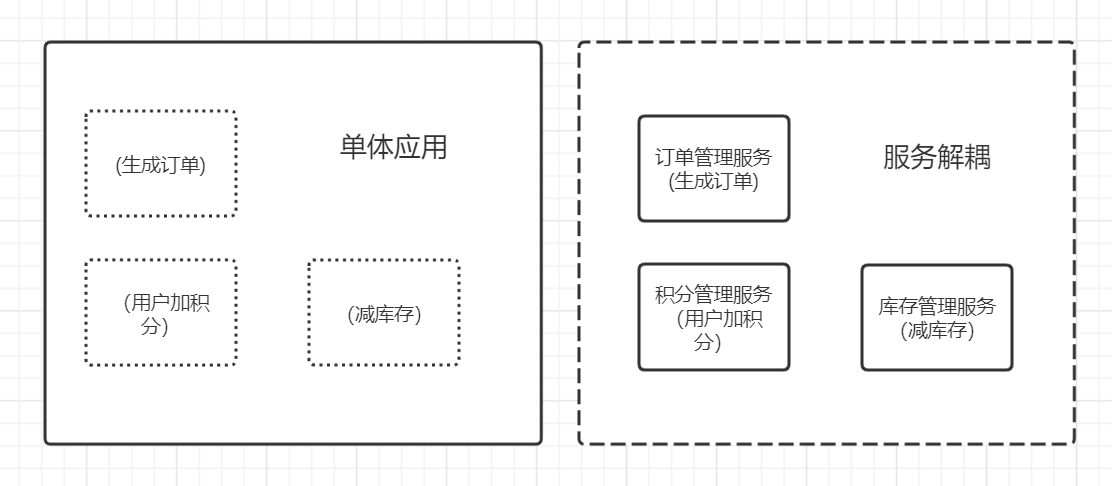
* 在同步處理模型下,將生成訂單、用戶加積分、減庫存操作寫在一個單體應用中。修改訂單可能影響用戶積分,修改用戶積分代碼可能影響減庫存。修改應用程序中的任何一部分代碼,都需要將應用整體打包重新部署。這比較適合小團隊、用戶量小項目的開發模型。
* 在異步的處理模型下,可以將訂單管理、積分管理、庫存管理都單獨拆分為一個服務獨立運行、獨立代碼、獨立部署,彼此之間通過消息隊列或RPC進行交互。便于小團隊知識聚合、專業度增強,代碼質量的提升,單個服務測試難度的下降。當服務耦合度下降的時候,也意味著擴展能力的增強,面對更復雜的業務需求也更有的放矢。
一般來說小團隊、用戶量較小的項目很少會將“程序解耦”作為優先的選項。如果阿里巴巴從工作第一天就想把架構做成今天的樣子,它也一定不會成為今天的阿里巴巴。應用服務的解耦一定是配合著業務量的增長,團隊規模及知識儲備的提升。應用服務的解耦有很多方式,使用消息隊列就是核心選項之一。
**數據緩沖**
當我們使用到消息隊列,一定意味著“單體應用”的方式已經無法滿足我們的用戶并發度需求,無法滿足高速增長的業務量。對于高并發的處理,通常有兩種方式來緩解
1. 集群部署,增加應用實例部署規模,比如一個應用實例處理不過來的請求,通過部署多個實例來完成,配合有效的負載均衡處理高并發需求。也就是:“一個好漢三個幫”,自己干不過來就找人來一起干。
2. 增加集群應用實例規模的方式固然有效,但是要考慮的一件事是:服務器資源是有限的,那么怎么在有限的生產力條件下,既能滿足用戶需求,又能合理的安排生產,這是“架構師”需要思考的事情。所以架構師將消息處理按照時效性分成兩類:
* 對于高時效性的消息數據進行實時同步處理,如:生成訂單。
* 對于低時效性、并發度又很高的數據,先緩沖起來。消息隊列就是緩沖隊列,緩沖的目的是降低后端服務處理瓶頸,根據消息隊列后端消費服務的處理能力來拉取數據進行處理,而不是一下子把所有的數據全交給后端消費服務,把后端消費服務壓死。如:增加積分、減少庫存。
**提升數據處理性能**
既然消息隊列已經緩沖了數據,就為我們進行消息的批處理創造了條件。數據批量接收、批量處理、批量入庫的操作,一定是比我們一條一條數據的處理操作性能更高的。
- 文檔概要
- 如何提問
- 一、kafka基礎入門
- 1.1.白話消息隊列
- 1.2.消息傳遞模型
- 1.3.典型應用場景一
- 1.4.典型應用場景二
- 1.5.kafka簡單介紹
- 1.6.kafka核心概念解析
- 1.7.搭建kafka單機版
- 1.8.kafka3中zk替代方案
- 二、生產級集群安裝
- 2.1.linux安裝JDK
- 2.2.linux主機與ip解析
- 2.3.linux新建用戶
- 2.4.linux開放防火墻端口
- 2.5.最大打開文件句柄數
- 2.6.集群主機之間免密登錄
- 2.7.zookeeper集群安裝(腳本)
- 2.8.kafka集群安裝部署(腳本)
- 2.9.kafka3無需zk的集群安裝
- 2.10.集群可用性驗證及配置
- 2.11.kafka集群可靠性配置
- 2.12內外網絡映射問題
- 三、生產者客戶端
- 3.1.本章閱讀說明
- 3.2.圖解kafka生產者
- 3.3.數據生產可靠性
- 3.4.保證消息順序性
- 3.5.生產者Java實現
- 3.6.自定義攔截器
- 3.7.自定義序列化器
- 3.8.自定義分區器
- 3.9.冪等與事務處理
- 四、消費者客戶端
- 4.1.消費者組與數據積壓
- 4.2.消費者Java實現
- 4.3.消費偏移與可靠性
- 4.4.分區再均衡
- 4.5.線程池與消費者組
- 4.6.消費者攔截器
- 4.7.自定義反序列化器
- 五、SpringBoot集成kafka
- 5.1.整合集成kafka客戶端
- 5.2.生產者同步異步分區攔截
- 5.3.生產者事務處理
- 5.4.KafkaListener詳解
- 5.5.Header及sendTo
- 5.5.監聽器模式及偏移量提交
- 5.3.消費監聽器的異常處理
- 5.6.JSON序列化日期問題處理
- 六、kafka安全認證
- 6.1.用戶名密碼PLAIN認證
- 6.2.SCRAM認證
- 6.3.Kerberos認證(撰寫中)
- 七、kafka運維配置管理
- 7.1.topic管理命令
- 7.2.KafkaTool帶界面管理工具
- 7.3.LogiKM企業級監控管理(撰寫中)
- 附錄
- linux虛擬機集群的搭建
- 筆者其他作品推薦
- vue深入淺出系列
- 手摸手教你Spring Boot2.0
- Spring Security-JWT-OAuth2一本通
- 實戰前后端分離RBAC權限管理系統
- 實戰SpringCloud微服務從青銅到王者
- 送書活動