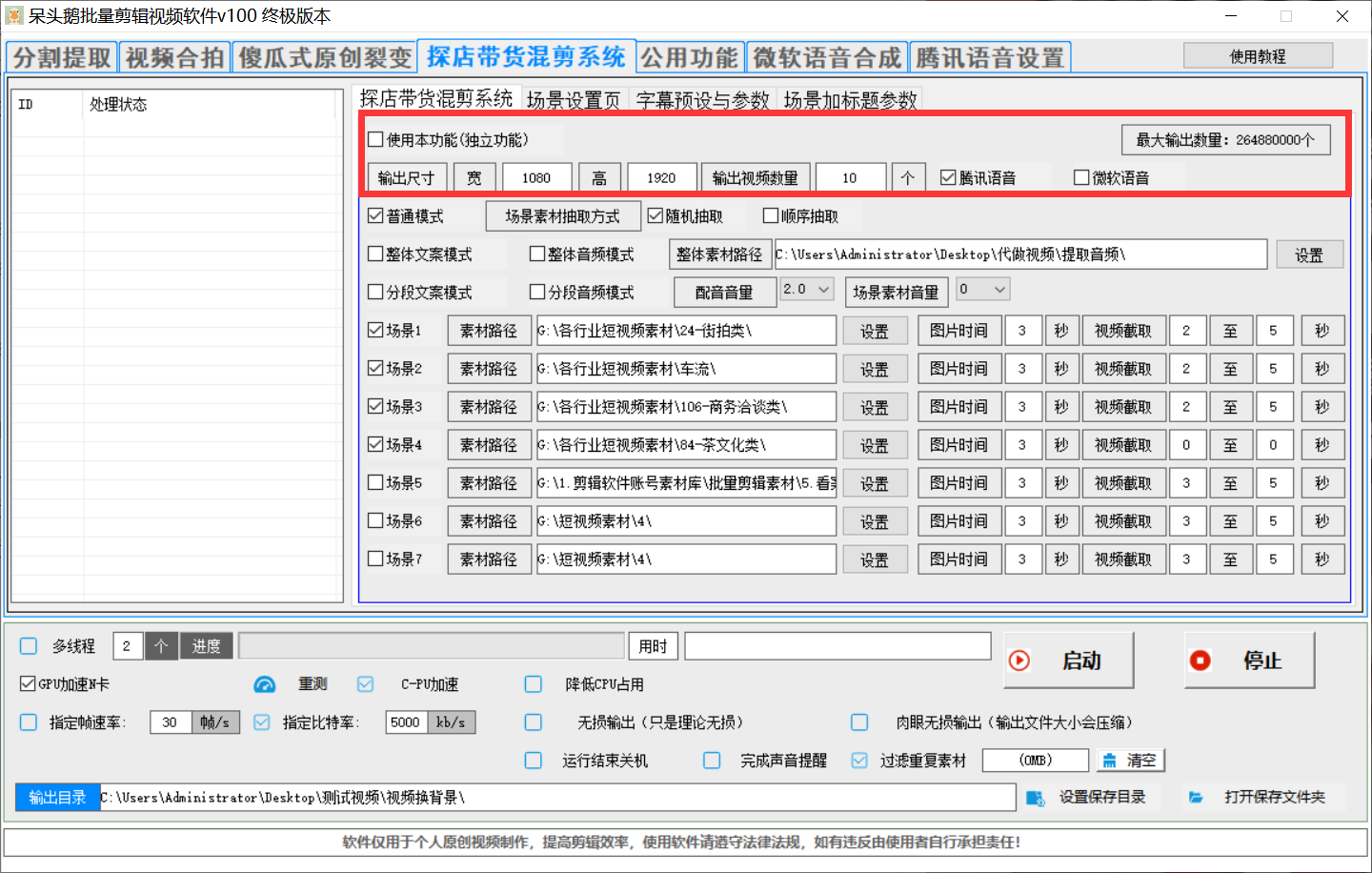
啟用本功能:必須選擇
最大場景數量支持:19個場景
最大輸出數量:為最大輸出視頻數量,計算方式:每個場景文件夾的視頻數量相乘為最大輸出數量。
輸出尺寸:輸出豎屏,輸出橫板,自定義尺寸
輸出視頻數量:想做多少個,就輸入多少個,建議先做一個,然后在進行大量輸出。
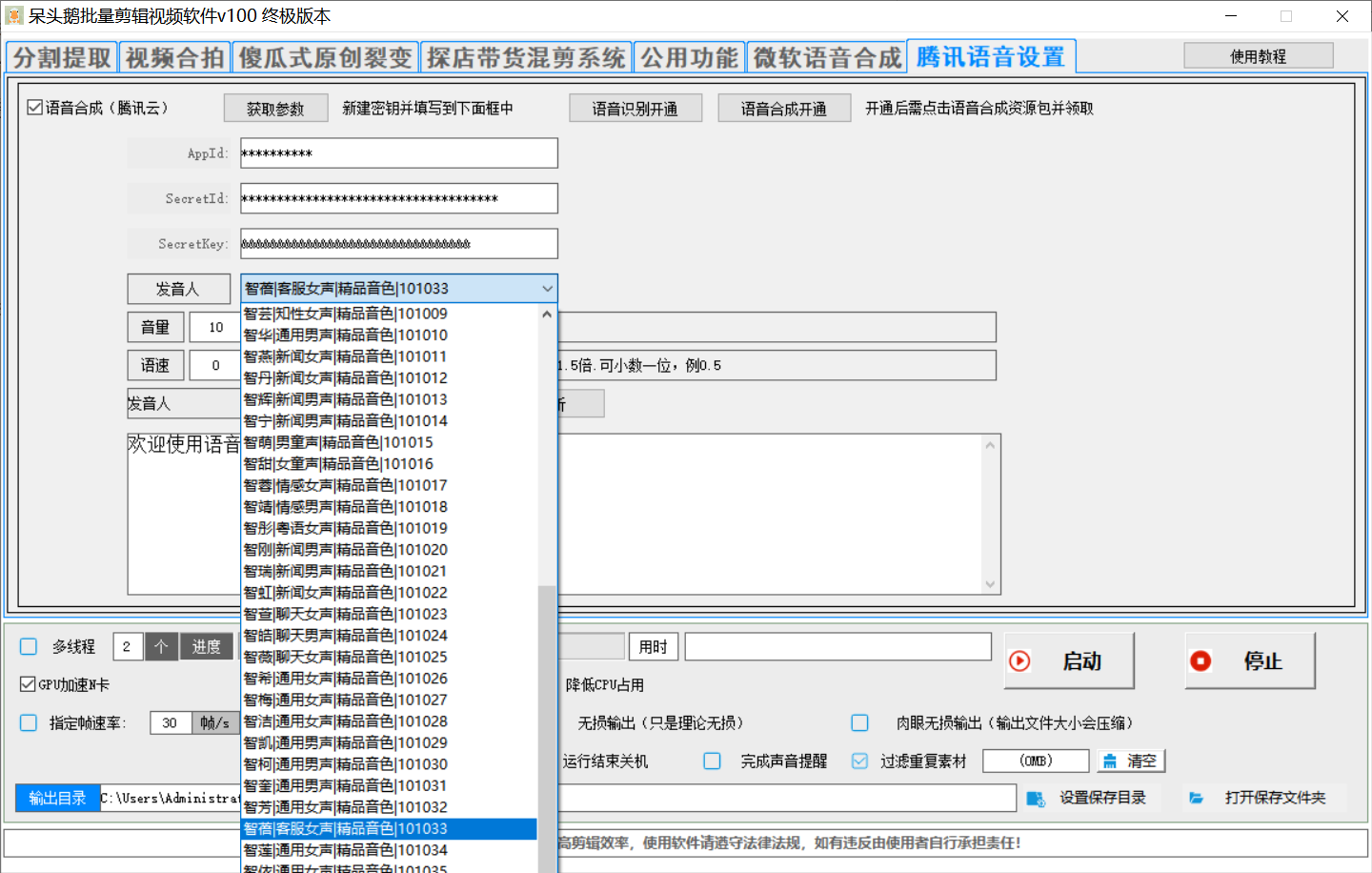
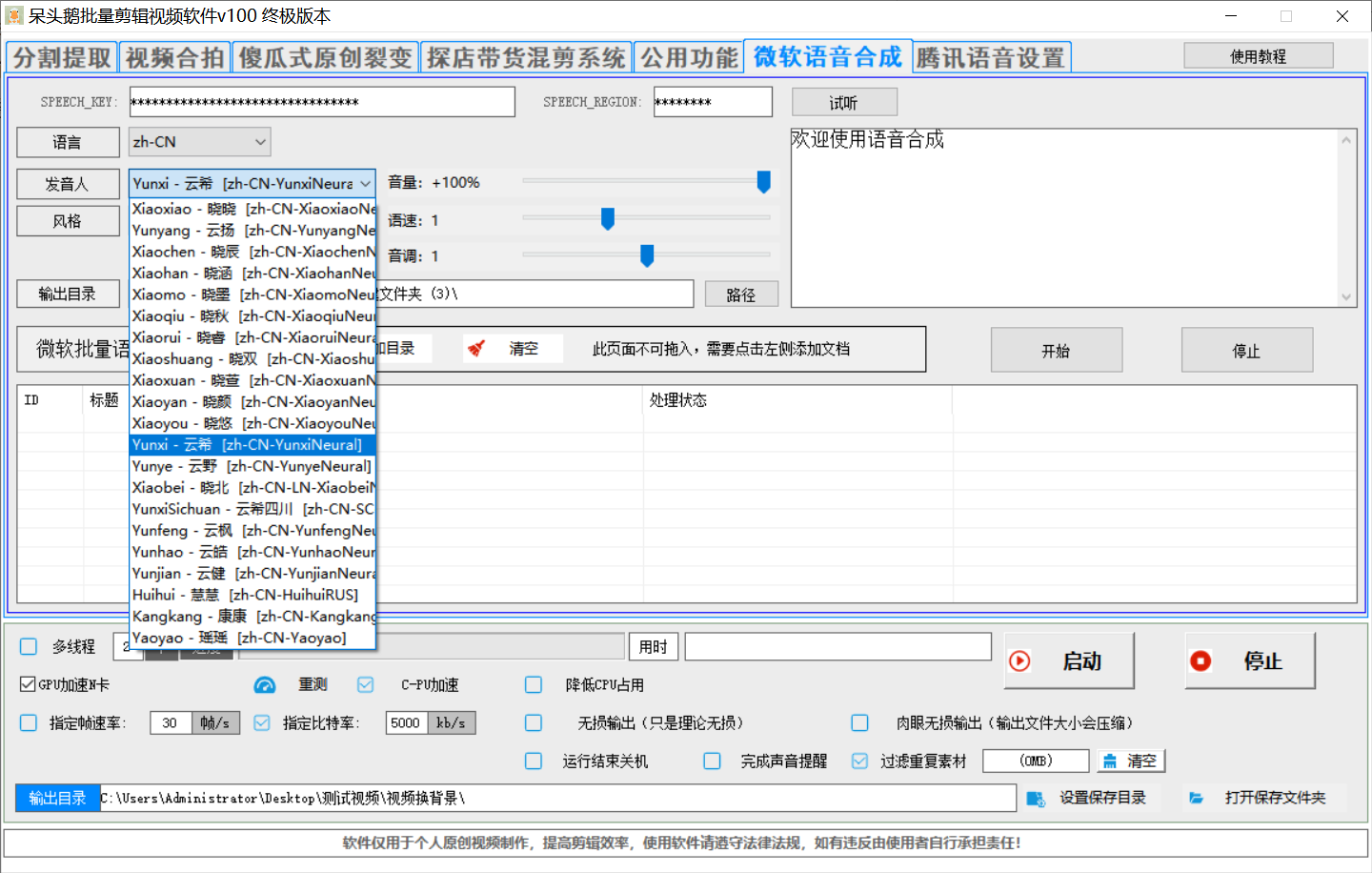
騰訊語音和微軟語音二選一
騰訊語音:必須在右側微軟語音或騰訊云語音開通,填寫對應的參數,并開通語音合成,語音識別,并領取對應的資源包才可以用,否則無法使用。
騰訊云語音參數獲取
https://cloud.tencent.com/login?s_url=https%3A%2F%2Fconsole.cloud.tencent.com%2Fcam%2Fcapi
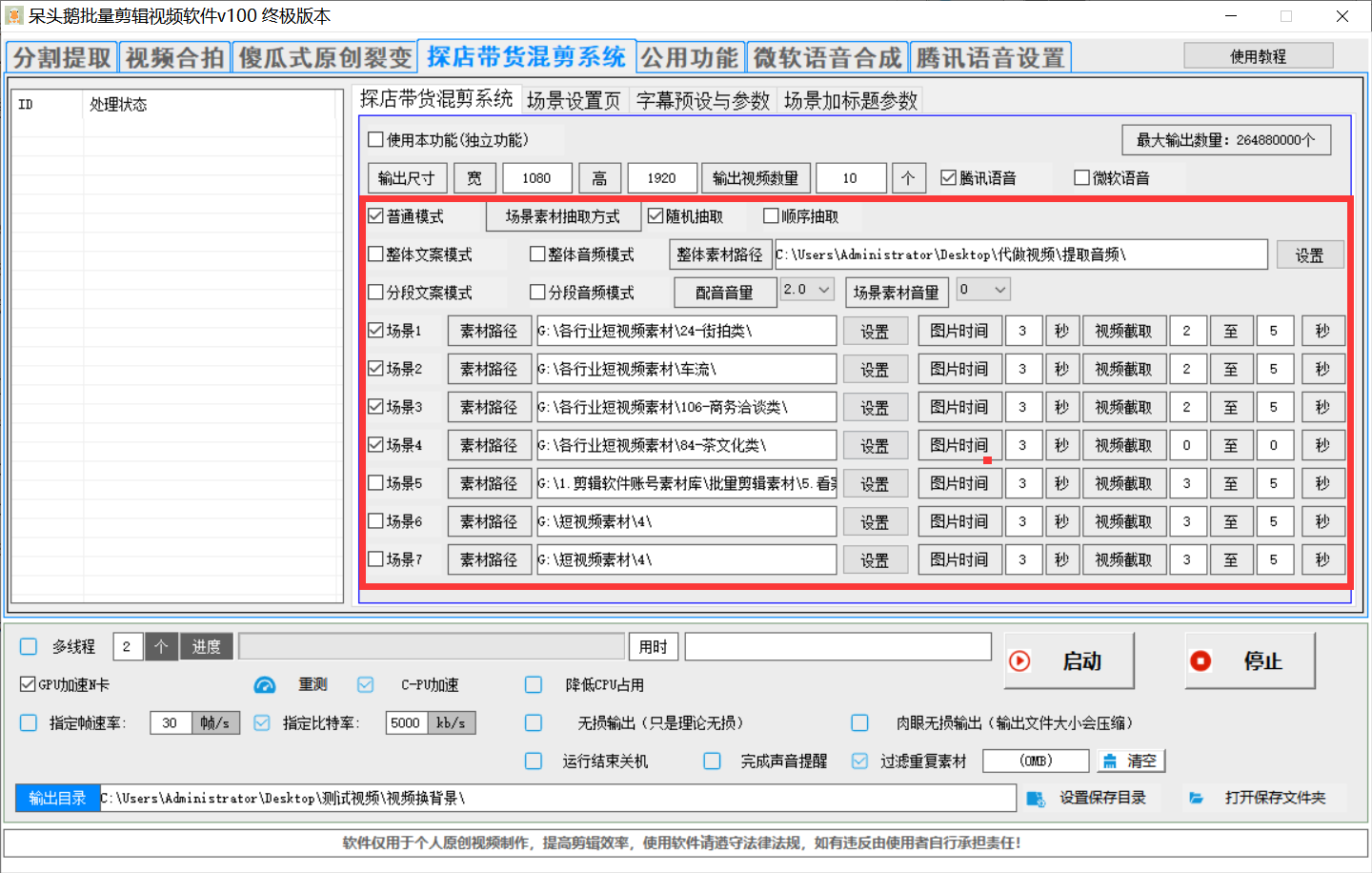
配音音量:通過騰云語音或者微軟的配音的音量。
場景素材音量:場景中素材的音量。
普通模式:把每個場景中隨機抽取一個視頻或圖片,進行截取對應的長度,進行合并
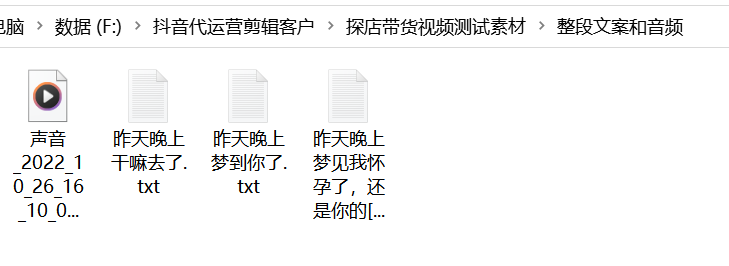
整體文案模式:整體素材路徑中拖入文案文件夾,把里面的文案轉換成音頻,自動計算音頻的長度,并平均分配到每個場景中,每次隨機抽取場景中一個視頻或圖片,截取對應的長度并合并。
整體音頻模式:整體素材路徑中拖入音頻文件夾,自動計算音頻的長度,并平均分配到每個場景中,每次隨機抽取場景中一個視頻或圖片,截取對應的長度并合并。
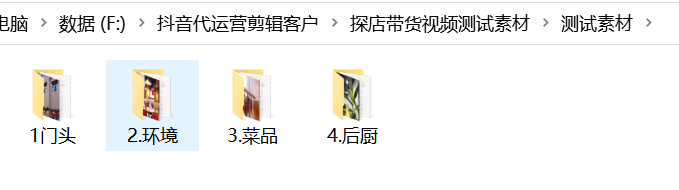
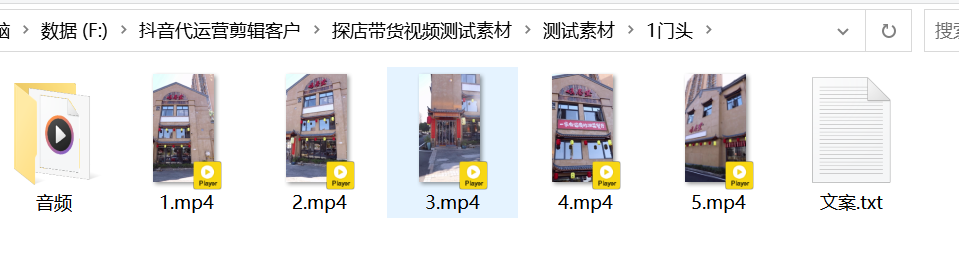
分段文案模式:每個場景文件夾中建立一個名字為 文案.txt,進行把文案.txt順序抽取一行,把文案轉換成音頻,自動計算音頻的長度,抽取對應的場景文件夾中的視頻進行合并。最后進行每個場景文件夾做出來的視頻,進行合并到一塊。
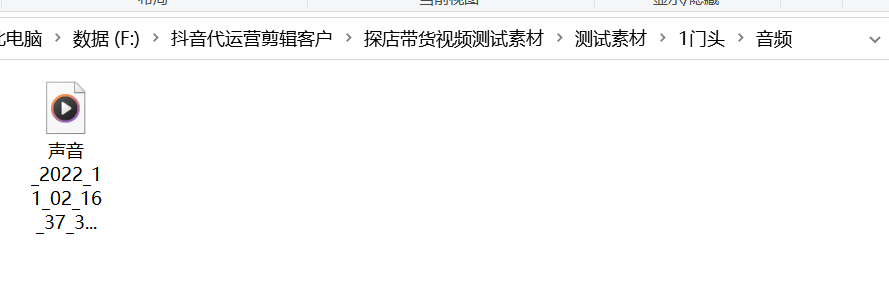
分段音頻模式:每個場景文件夾中建立一個名字為 音頻 的文件夾,自動計算音頻的長度,抽取對應的場景文件夾中的視頻進行合并。最后進行每個場景文件夾做出來的視頻,進行合并到一塊。
