
## **索引有哪些數據結構,優缺點**
> 在創建索引時,通常采用的數據結構有:Hash、二叉搜索樹、紅黑樹、B樹以及B+樹。這里主要介紹這些數據結構的設計思想,不做底層實現研究。
1. Hash結構:通過一定的算法計算數據的Hash值,然后得到數據的存放位置,例如JAVA中的HashMap采用就是這種數據索引結構。
* 優點:檢索時間快,平均檢索時間為O(1)。
* 缺點:
* 因為Hash值是通過算法計算出來的,存在Hash碰撞的幾率,比如HashMap對于Hash值相同的數據,會在Hash值所在桶創建一個鏈表,用于存放相同Hash值的數據。
* 在數據量很大的情況下,內存無法加載全部的數據索引。
2. 二叉搜索樹:定義規則為“左邊節點值比根節點小,右邊節點值比根節點大,并且左右子節點都是排序樹”。
* 優點:可以解決大量數據索引無法一次加載進內存中的問題,二叉搜索樹可以批量加載數據進內存。
* 缺點:
* 檢索時間與樹的高度有關,樹的高度越高,檢索次數及時間相對就會越久。
* 極端情況下,如果數據本身就是有序的,二叉搜索樹會退化成鏈表,性能會急劇降低。
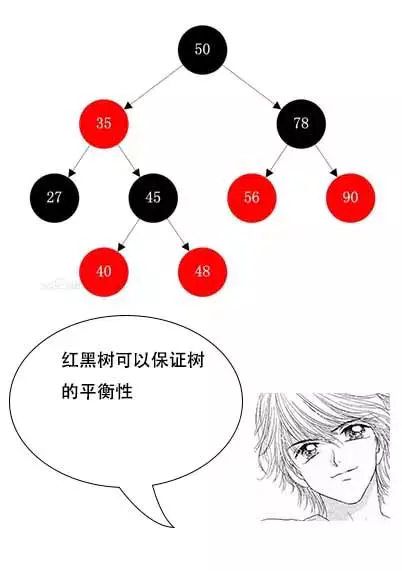
3. 紅黑樹:紅黑樹是一種自平衡二叉樹,主要解決二叉搜索樹在極端情況下退化成鏈表的情況,在數據插入的時候同時調整整個樹,使其節點盡量均勻分布,保證平衡性,目的在于降低樹的高度,提高查詢效率。
* 優點:解決二叉搜索樹的極端情況的退化問題。
* 缺點:檢索時間依舊與樹的高度有關,當數據量很大時,樹的高度就會很高,檢索的次數就會比較多,檢索的時間會比較久,效率低。
:-: 
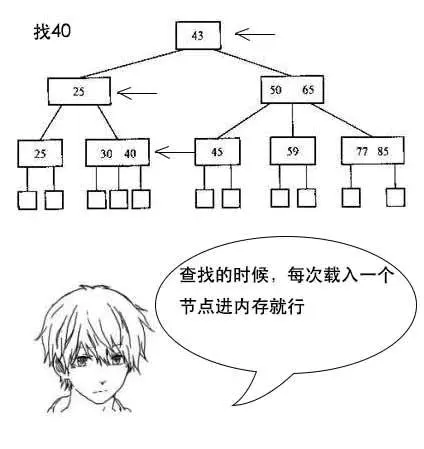
4. B樹:B樹是一種多路搜索樹,每個子節點可以擁有多于2個子節點,M路的B樹最多可擁有M個子節點。設計成多路,其目的是為了降低樹的高度,降低查詢次數,提高查詢效率。
* 雖然多路可以降低樹的高度,但是如果設計成無限多路,就會退化成有序數組,一般B樹的使用場景是用于文件的索引,這些索引會存放于硬盤中,有時內存是無法一次性加載完,此時就無法進行查找。
* 如果全部在內存中,紅黑樹的查找效率要高于B樹,但是涉及到磁盤操作,B樹要優于紅黑樹,所以在JDK1.8版本的HashMap中,如果單個桶的鏈表長度多于8或全部桶的鏈表總長度多余64,會將鏈表轉換成紅黑樹。
:-: 
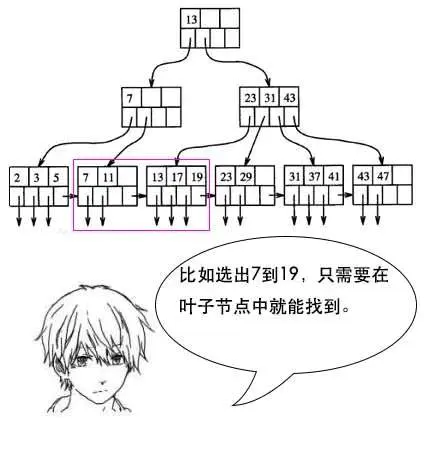
5. B+樹:B+樹是對于B樹進行優化的多路搜索樹,主要設計是將數據全部存放于葉子節點,并將葉子節點用指針進行鏈表鏈接。
* 主要使用場景:常用于數據庫的索引。
* 數據庫的索引一般數據量不小,同時又存放于磁盤中,采用多路搜索樹,可以降低樹的高度,同時在大數據量下可以分批載入內存,提高查詢效率。
* 不同于B樹的使用場景,數據庫的查詢中,我們一般查詢的數量不會是單條數據,例如列表常用查詢中的分頁查詢--查詢第1頁的10條數據,此時如果采用B樹,需要進行樹的中序遍歷,可能需要跨層訪問。
* 而B+樹的所有數據全部存放于葉子節點上,且葉子節點之間采用指針進行鏈表鏈接,一次查詢多條時,確定首尾位置,便可以方便的確定多條數據位置。
:-: 
- PHP篇
- 函數傳值和傳引用的區別
- 簡述PHP的垃圾回收機制
- 簡述CGI、FAST-CGI、PHP-FPM的關系
- 常見正則表達式
- 多進程寫文件,如何保證都寫成功
- php支持回調函數的數組函數
- MySQL篇
- MySQL的兩種存儲引擎區別
- 事務的四大特性
- 數據庫事務隔離級別
- 什么是索引
- 索引有哪些數據結構,優缺點
- 索引的一些潛規則
- SQL的優化方案
- 簡述MySQL的鎖機制
- 死鎖是怎么產生的?怎么解決?
- 簡述MySQL的主從復制過程,延遲問題怎么解決
- 分布式事務的解決方案
- 數據庫中間件MyCat
- Linux篇
- Linux常用命令
- 對日志文件的IP出現的次數進行統計,并顯示次數最多的前5名
- WEB篇
- 跨域是怎么產生的,如何解決跨域
- Redis篇
- redis介紹
- redis和memcached區別
- redis的持久化方案
- 緩存穿透、擊穿、雪崩、預熱、更新、降級
- 網絡篇
- 計算機網絡體系結構
- 簡述TCP的三次握手、四次揮手過程
- UDP、TCP 區別,適用場景
- HTTP常見狀態碼含義
- 設計模式篇
- 單例模式
- 簡單工廠模式
- 抽象工廠模式
- 觀察者模式
- 策略模式
- 注冊模式
- 適配器模式
- 安全篇
- 跨站腳本攻擊(XSS)
- 跨站點請求偽造(CSRF)
- SQL 注入
- 應用層拒絕服務攻擊
- PHP安全
- 運維篇
- docker面試題
- 消息隊列篇
- 架構篇
- 數據結構與算法篇