

## QuerySet API
我們通常做查詢操作的時候,都是通過模型名字.objects的方式進行操作。其實模型名字.objects是一個django.db.models.manager.Manager對象,而Manager這個類是一個“空殼”的類,他本身是沒有任何的屬性和方法的。他的方法全部都是通過Python動態添加的方式,從QuerySet類中拷貝過來的
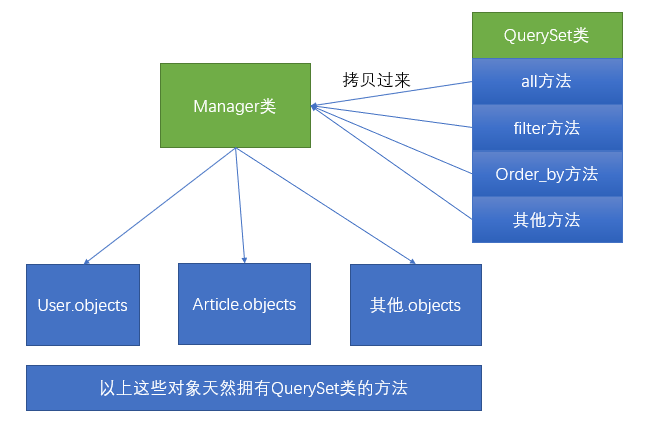
所以我們如果想要學習ORM模型的查找操作,首先要學會QuerySet上的一些API的使用。
## QuerySet的方法
在使用QuerySet進行查找操作的時候,可以提供多種操作。比如過濾完后還要根據某個字段進行排序,那么這一系列的操作我們可以通過一個非常流暢的鏈式調用的方式進行。比如要從文章表中獲取標題為123,并且提取后要將結果根據發布的時間進行排序,那么可以使用以下方式來完成
```
articles = Article.objects.filter(title='123').order_by('create_time')
```
可以看到order\_by方法是直接在filter執行后調用的。這說明filter返回的對象是一個擁有order\_by方法的對象。而這個對象正是一個新的QuerySet對象。因此可以使用order\_by方法。
那么以下將介紹在那些會返回新的QuerySet對象的方法。
1.`filter`:將滿足條件的數據提取出來,返回一個新的`QuerySet`
2.`exclude`:排除滿足條件的數據,返回一個新的`QuerySet`
```
提取那些標題不包含`hello`的圖書
Article.objects.exclude(title__contains='hello')
```
3.`annotate`:給`QuerySet`中的每個對象都添加一個使用查詢表達式(聚合函數、F表達式、Q表達式、Func表達式等)的新字段
```
將在每個對象中都添加一個`author__name`的字段,用來顯示這個文章的作者的年齡
articles = Article.objects.annotate(author_name=F("author__name"))
```
4.`order_by`:指定將查詢的結果根據某個字段進行排序。如果要倒敘排序,那么可以在這個字段的前面加一個負號
```
# 根據創建的時間正序排序(從小到大,默認排序規則)
articles = Article.objects.order_by("create_time")
# 根據創建的時間倒序排序
articles = Article.objects.order_by("-create_time")
# 根據作者的名字進行排序
articles = Article.objects.order_by("author__name")
# 首先根據創建的時間進行排序,如果時間相同,則根據作者的名字進行排序
articles = Article.objects.order_by("create_time",'author__name')
# 根據圖書訂單的評分來排序
articles = BookOrder.objects.order_by("book__rating")
```
5.`values`:用來指定在提取數據出來,需要提取哪些字段。默認情況下會把表中所有的字段全部都提取出來,可以使用`values`來進行指定,并且使用了`values`方法后,提取出的`QuerySet`中的數據類型不是模型,而是在`values`方法中指定的字段和值形成的字典
```
articles = Article.objects.values("title",'content')
for article in articles:
print(article)
```
以上打印出來的`article`是類似于`{"title":"abc","content":"xxx"}`的形式
6.`values_list`:類似于`values`。只不過返回的`QuerySet`中,存儲的不是字典,而是元組
```
articles = Article.objects.values_list("id","title")
print(articles)
```
那么在打印`articles`后,結果為`<QuerySet [(1,'abc'),(2,'xxx'),...]>`等
7.`all`:獲取這個`ORM`模型的`QuerySet`對象。
8.`select_related`:在提取某個模型的數據的同時,也提前將相關聯的數據提取出來。比如提取文章數據,可以使用`select_related`將`author`信息提取出來,以后再次使用`article.author`的時候就不需要再次去訪問數據庫了。可以減少數據庫查詢的次數
```
article = Article.objects.get(pk=1)
>> article.author # 重新執行一次查詢語句
article = Article.objects.select_related("author").get(pk=2)
>> article.author # 不需要重新執行查詢語句了
```
`selected_related`只能用在`一對多`或者`一對一`中,不能用在`多對多`或者`多對一`中。比如可以提前獲取文章的作者,但是不能通過作者獲取這個作者的文章,或者是通過某篇文章獲取這個文章所有的標簽
9.`prefetch_related`:這個方法和`select_related`非常的類似,就是在訪問多個表中的數據的時候,減少查詢的次數。這個方法是為了解決`多對一`和`多對多`的關系的查詢問題。比如要獲取標題中帶有`hello`字符串的文章以及他的所有標簽
```
from django.db import connection
articles = Article.objects.prefetch_related("tag_set").filter(title__contains='hello')
print(articles.query) # 通過這條命令查看在底層的SQL語句
for article in articles:
print("title:",article.title)
print(article.tag_set.all())
```
10.`create`:創建一條數據,并且保存到數據庫中。這個方法相當于先用指定的模型創建一個對象,然后再調用這個對象的`save`方法
```
article = Article(title='abc')
article.save()
# 下面這行代碼相當于以上兩行代碼
article = Article.objects.create(title='abc')
```
11.`get_or_create`:根據某個條件進行查找,如果找到了那么就返回這條數據,如果沒有查找到,那么就創建一個
```
obj,created= Category.objects.get_or_create(title='默認分類')
```
如果有標題等于`默認分類`的分類,那么就會查找出來,如果沒有,則會創建并且存儲到數據庫中。
這個方法的返回值是一個元組,元組的第一個參數`obj`是這個對象,第二個參數`created`代表是否創建的。
12.`exists`:判斷某個條件的數據是否存在。如果要判斷某個條件的元素是否存在,那么建議使用`exists`,這比使用`count`或者直接判斷`QuerySet`更有效得多。
```
if Article.objects.filter(title__contains='hello').exists():
print(True)
比使用count更高效:
if Article.objects.filter(title__contains='hello').count() > 0:
print(True)
也比直接判斷QuerySet更高效:
if Article.objects.filter(title__contains='hello'):
print(True)
```
13.`update`:執行更新操作,在`SQL`底層走的也是`update`命令。比如要將所有`category`為空的`article`的`article`字段都更新為默認的分類
```
Article.objects.filter(category__isnull=True).update(category_id=3)
```
注意這個方法走的是更新的邏輯。所以更新完成后保存到數據庫中不會執行`save`方法,因此不會更新`auto_now`設置的字段
14.切片操作:有時候我們查找數據,有可能只需要其中的一部分
```
books = Book.objects.all()[1:3]
for book in books:
print(book)
```
切片操作并不是把所有數據從數據庫中提取出來再做切片操作。而是在數據庫層面使用`LIMIE`和`OFFSET`來幫我們完成。所以如果只需要取其中一部分的數據的時候,建議大家使用切片操作。
## 將QuerySet轉換為SQL去執行
生成一個QuerySet對象并不會馬上轉換為SQL語句去執行
```
from django.db import connection
books = Book.objects.all()
print(connection.queries)
```
我們可以看到在打印connection.quries的時候打印的是一個空的列表。說明上面的QuerySet并沒有真正的執行。
在以下情況下QuerySet會被轉換為SQL語句執行
1. 迭代:在遍歷QuerySet對象的時候,會首先先執行這個SQL語句,然后再把這個結果返回進行迭代。比如以下代碼就會轉換為SQL語句:
```
for book in Book.objects.all():
print(book)
```
2. 使用步長做切片操作:QuerySet可以類似于列表一樣做切片操作。做切片操作本身不會執行SQL語句,但是如果如果在做切片操作的時候提供了步長,那么就會立馬執行SQL語句。需要注意的是,做切片后不能再執行filter方法,否則會報錯。
3. 調用len函數:調用len函數用來獲取QuerySet中總共有多少條數據也會執行SQL語句。
4. 調用list函數:調用list函數用來將一個QuerySet對象轉換為list對象也會立馬執行SQL語句。
5. 判斷:如果對某個QuerySet進行判斷,也會立馬執行SQL語句。
- 空白目錄
- 1-Django前導知識
- 1-1-虛擬環境
- 1-2-Django框架介紹與環境搭建
- 2-URL與視圖
- 2-1-URL與視圖
- 3-模板
- 3-1-模板介紹
- 3-2-模板變量
- 3-3-常用標簽
- 3-4-模板常用過濾器
- 3-5-模板結構優化
- 3-6-加載靜態文件
- 4-數據庫
- 4-1-操作數據庫
- 4-2-圖書管理系統
- 4-3-ORM模型介紹
- 4-4-ORM模型的增刪改查
- 4-5-模型常用屬性
- 4-6-外鍵和表
- 4-7-查詢操作
- 4-8-QuerySet的方法
- 4-9-ORM模型練習
- 4-10-ORM模型遷移
- 5-視圖高級
- 1-Django限制請求method
- 2-頁面重定向
- 3-HttpRequest對象
- 4-HttpResponse對象
- 5-類視圖
- 6-錯誤處理
- 6-表單
- 1-用表單驗證數據
- 2-ModelForm
- 3-文件上傳
- 7-session和cookie
- 1-session和cookie
- 8-memcached
- 1-memcached
- 9-阿里云部署
- 阿里云部署