

*****
## 索引
### 思考
> 在圖書館中是如何找到一本書的?
一般的應用系統對比數據庫的讀寫比例在10:1左右(即有10次查詢操作時有1次寫的操作),
而且插入操作和更新操作很少出現性能問題,
遇到最多、最容易出問題還是一些復雜的查詢操作,所以查詢語句的優化顯然是重中之重
### 解決辦法
當數據庫中數據量很大時,查找數據會變得很慢
優化方案:索引
### 索引是什么
索引是一種特殊的文件(InnoDB數據表上的索引是表空間的一個組成部分),它們包含著對數據表里所有記錄的引用指針。
<br>更通俗的說,數據庫索引好比是一本書前面的目錄,能加快數據庫的查詢速度
### 索引的目的
索引的目的在于提高查詢效率,可以類比字典,如果要查“mysql”這個單詞,我們肯定需要定位到m字母,然后從下往下找到y字母,再找到剩下的sql。
### 索引原理
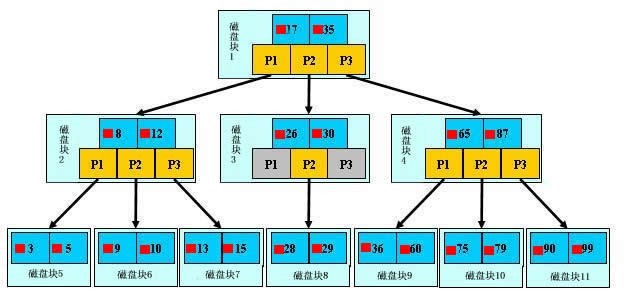
除了詞典,生活中隨處可見索引的例子,如火車站的車次表、圖書的目錄等。它們的原理都是一樣的,通過不斷的縮小想要獲得數據的范圍來篩選出最終想要的結果,同時把隨機的事件變成順序的事件,也就是我們總是通過同一種查找方式來鎖定數據。
<br>數據庫也是一樣,但顯然要復雜許多,因為不僅面臨著等值查詢,還有范圍查詢(>、<、between、in)、模糊查詢(like)、并集查詢(or)等等。數據庫應該選擇怎么樣的方式來應對所有的問題呢?
### 索引的使用
* 查看索引
~~~
show index from 表名;
~~~
* 創建索引
* 如果指定字段是字符串,需要指定長度,建議長度與定義字段時的長度一致
* 字段類型如果不是字符串,可以不填寫長度部分
~~~
create index 索引名稱 on 表名(字段名稱(長度))
~~~
* 刪除索引:
~~~
drop index 索引名稱 on 表名;
~~~
## 索引案例
創建測試表test
```
create table test(title varchar(10));
```
- 使用python程序向表中加入十萬條數據
#### 查詢
* 開啟運行時間監測:
~~~
set profiling=1;
~~~
* 查找第1萬條數據ha-99999
~~~
select * from test where title='ha-99999';
~~~
* 查看執行的時間:
~~~
show profiles;
~~~
* 為表title\_index的title列創建索引:
~~~
create index title_index on test(title(10));
~~~
* 執行查詢語句:
~~~
select * from test where title='ha-99999';
~~~
* 再次查看執行的時間
~~~
show profiles;
~~~
### 適合建立索引的情況
1.主鍵自動建立索引
2.頻繁作為查詢條件的字段應該建立索引
3.查詢中與其他表關聯的字段,外鍵關系建立索引
4.在高并發的情況下創建復合索引
5.查詢中排序的字段,排序字段若通過索引去訪問將大大提高排序速度 (建立索引的順序跟排序的順序保持一致)
### 不適合建立索引的情況
頻繁更新的字段不適合建立索引
where條件里面用不到的字段不創建索引
表記錄太少,當表中數據量超過三百萬條數據,可以考慮建立索引
數據重復且平均的表字段,比如性別,國籍
- 1-數據庫-基本使用
- 1-1-數據存儲
- 1-2-數據庫
- 1-3-MySQL安裝和配置
- 1-4-SQL
- 1-5-數據完整性
- 1-6-命令行操作數據庫
- 2-MySQL查詢
- 2-1-MySQL查詢
- 2-2-條件
- 2-3-聚合函數
- 2-4-分組
- 2-5-排序
- 2-6-分頁
- 2-7-連接查詢
- 2-8-子查詢
- 2-9-自關聯
- 3-MySQL外鍵
- 4-MySQL與Python交互
- 4-1-數據準備
- 4-2-數據表的拆分
- 4-3-Python操作MySQL
- 5-MySQL高級
- 5-1-視圖
- 5-2-事務
- 5-3-索引
- 5-4-賬戶管理(了解)
- 6-數據庫存儲引擎
- 6-1-MyISAM存儲引擎
- 6-2-Innodb存儲引擎
- 6-3-CSV存儲引擎
- 6-4-Memory存儲引
- 7-MySQL基準測試
- 8-explain分析SQL語句
- 8-1-影響服務器性能的幾個方面
- 8-2-explain分析SQL
- 9-索引優化案例
- 10-索引優化
- 11-排序優化
- 12-慢查詢日志
- 13-Show Profile進行SQL分析
- 14-數據庫鎖
- 15-主從復制
- 16-MySQL分區表
- 17-MySQL操作規范