

*****
## explain
### explain是什么?
使用explain關鍵字可以模擬優化器執行SQL查詢語句,從而知道MySQL是如何處理你的SQL語句的。
### explain能干嘛?
* 表的讀取順序
* 數據讀取操作的操作類型
* 那些索引可以使用
* 那些索引被實際使用
* 表之間的引用
* 每張表有多少行被優化器查詢
### explain怎么玩?
~~~
explain + SQL語句
~~~
## explain字段解釋
### id表的讀取順序
<br>
select查詢的順序號,包含一組數字,表示查詢中執行select子句或操作表的順序
<br>
兩種情況:
1.id相同,執行順序由上至下
2.id不同,如果是子查詢,id的序號會遞增,id值越大優先級越高,越先被執行
### select\_type---數據讀取操作的操作類型
1.simple 簡單的select查詢,查詢中不包含子查詢或者union
2.primary 查詢中若包含任何復雜的子部分,最外層查詢則被標記。就是最后加載的那個
3.subquery 在select或where列表中包含了子查詢
4.union 若第二個select出現在union之后,則被標記為union
5.union result 從union表獲取結果的select
### table---顯示這一行的數據時關于那張表的
### partitions-查詢訪問的分區
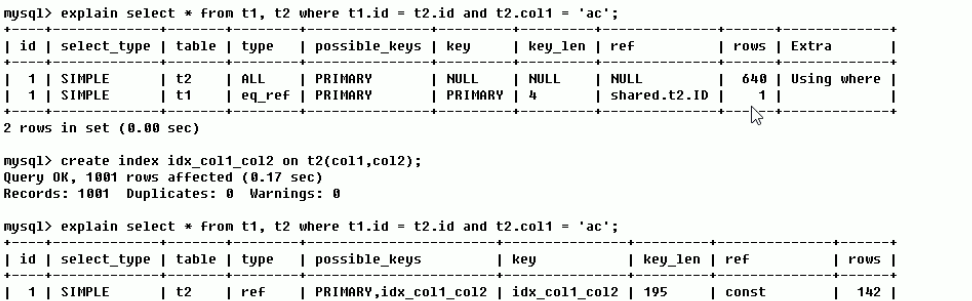
### type

從最好到最差依次是
```
system > const > eq_ref > ref > range > index > ALL
```
- system,表只有一行記錄(等于系統表),這是const類型的特例
- const表示通過索引一次就找到了,const用于比較primary key
- eq\_ref,唯一索引掃描,對于每個索引鍵,表中只有一條記錄與之匹配
- ref,非唯一性索引掃描,返回匹配某個單獨值得所有行,本質上也是一種索引訪問,它返回所有匹配某個單獨值的行
* range,只檢索給定范圍的行,使用一個索引來選擇行。
* index,Full Index Scan,index與ALL區別為index類型只遍歷索引樹。
* ALL,將遍歷全表找到匹配的行
### possible\_keys
顯示可能應用在這張表中的索引,一個或多個。
### key
實際使用的索引。如果為null,則沒有使用索引
<br>查詢中若使用了覆蓋索引,則該索引僅出現在key列表中
### key\_len
表示索引中使用的字節數,可通過該列計算查詢中使用的索引長度。在不損失精確性的情況下,長度越短越好
key\_len顯示的值為索引字段的最大可能長度,并非實際使用長度,即key\_len是根據表定義計算而得,不是通過表內檢索出的
#### 索引長度計算
~~~
varchr(24)變長字段且允許NULL
24*(Character Set:utf8=3,gbk=2,latin1=1)+1(NULL)+2(變長字段)
varchr(10)變長字段且不允許NULL
10*(Character Set:utf8=3,gbk=2,latin1=1)+2(變長字段)
char(10)固定字段且允許NULL
10*(Character Set:utf8=3,gbk=2,latin1=1)+1(NULL)
char(10)固定字段且不允許NULL
10*(Character Set:utf8=3,gbk=2,latin1=1)
~~~
### ref
顯示索引那一列被使用到了
### rows
根據表統計信息及索引選用情況,大致估算出找到所需的記錄所需要讀取的行數
### Extra
包含不適合在其他列中顯示但十分重要的額外信息
- Using filesort,說明mysql會對數據使用一個外部的索引排序,而不是按照表內的索引順序進行讀取,MySQL中無法利用索引完成的排序操作稱為"文件排序"
- Using temporary,使用臨時表保存中間結果,MySQL在對查詢結果排序時使用臨時表。
- Using index,使用了索引,避免了全表掃描
* Using where,使用了where過濾
* Using join buffer,使用了連接緩存
* impossible where,不可能的條件,where子句的值總是false
- 1-數據庫-基本使用
- 1-1-數據存儲
- 1-2-數據庫
- 1-3-MySQL安裝和配置
- 1-4-SQL
- 1-5-數據完整性
- 1-6-命令行操作數據庫
- 2-MySQL查詢
- 2-1-MySQL查詢
- 2-2-條件
- 2-3-聚合函數
- 2-4-分組
- 2-5-排序
- 2-6-分頁
- 2-7-連接查詢
- 2-8-子查詢
- 2-9-自關聯
- 3-MySQL外鍵
- 4-MySQL與Python交互
- 4-1-數據準備
- 4-2-數據表的拆分
- 4-3-Python操作MySQL
- 5-MySQL高級
- 5-1-視圖
- 5-2-事務
- 5-3-索引
- 5-4-賬戶管理(了解)
- 6-數據庫存儲引擎
- 6-1-MyISAM存儲引擎
- 6-2-Innodb存儲引擎
- 6-3-CSV存儲引擎
- 6-4-Memory存儲引
- 7-MySQL基準測試
- 8-explain分析SQL語句
- 8-1-影響服務器性能的幾個方面
- 8-2-explain分析SQL
- 9-索引優化案例
- 10-索引優化
- 11-排序優化
- 12-慢查詢日志
- 13-Show Profile進行SQL分析
- 14-數據庫鎖
- 15-主從復制
- 16-MySQL分區表
- 17-MySQL操作規范