## Rest.li
當我們從Leao轉向面向服務的架構后,之前抽取的基于Java RPC的API, 在團隊中開始變得不一致了,和表現層耦合太緊,這只會變得更糟。為了解決這個問題, 我們開發了一個新的API模型,叫做?[Rest.li](http://engineering.linkedin.com/architecture/restli-restful-service-architecture-scale). Rest.li 符合我們面向數據模型的架構, 確保在整個公司提供一致性的無狀態的Restful API模型。
基于HTTP的JSON數據, 我們新的API最終很容易地編寫非Java的客戶端。 LinkedIn今天仍然主要使用Java棧,但是也有很多使用Python, Ruby, Node.js 和 C++的客戶端,可能是自己開發的或者收購過來的。 脫離了RPC也讓我們將變現層和后端兼容型的問題中掙脫出來。另外, 使用Dynamic Discovery (D2)的Rest.li, 我們可以得到自動的基于負載均衡,服務發現和可擴展的API客戶端。
今天, LinkedIn有975 個Rest.li資源, 所有的數據中心每天有超過一千億級Rest.li調用。
[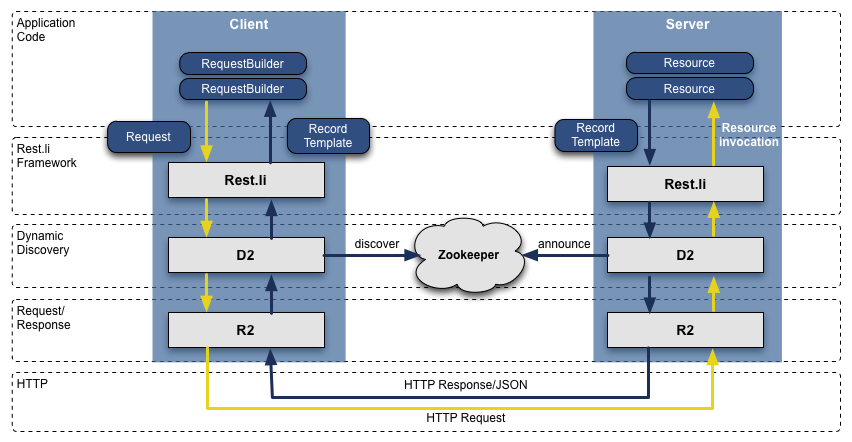](https://box.kancloud.cn/2015-07-30_55b9e3a7c00ab.png "Rest.li R2/D2 技術站")Rest.li R2/D2 技術站
## Super Blocks (超級塊)
面向服務的架構很好的解耦了域之間的聯系和可以獨立地擴展服務。但是也有缺點, 很多應用獲取各種類型的不同的數據, f(call graph)或者叫做"扇出" (fanout)。例如, 任意一次個人信息頁的請求就會獲取照片,會員關系, 組,訂閱信息, 關注,博客,人脈,推薦等信息。 這個調用圖很難管理,而且越來越難控制。
我們引入了超級塊的概念。 為一組后臺服務提供一個單一的訪問API。這樣我們就可以有一個team專門優化這個塊,同時保證每個客戶端的調用圖可控。
## Multi-Data Center (多數據中心)
作為一個會員快速增長的全球化公司,我們需要從一個數據中心進行擴展,我們通過幾年的努力來解決這個問題,首先,從兩個數據中心(洛杉磯 和 芝加哥)提供了公共個人信息,證明可行后,我們開始增強服務來處理數據復制、不同源的調用、單向數據復制事件、將用戶分配到地理位置更近的數據中心。
我們大多的數據庫運行在[Espresso](http://engineering.linkedin.com/espresso/introducing-espresso-linkedins-hot-new-distributed-document-store)(一個新的內部多用戶數據倉庫)上。
Espresso支持多個數據中心,提供了 主-主 的支持,及支持很難的數據復制。
多個數據中心對于高可用性具有不可思議的重要性,你要避免的單點故障不僅僅是某個服務失效,更要擔心整個站點失效。今天,LinkedIn運行了3個主數據中心,同時還有全球化的[PoPs](http://engineering.linkedin.com/performance/how-linkedin-used-pops-and-rum-make-dynamic-content-download-25-faster)服務。
[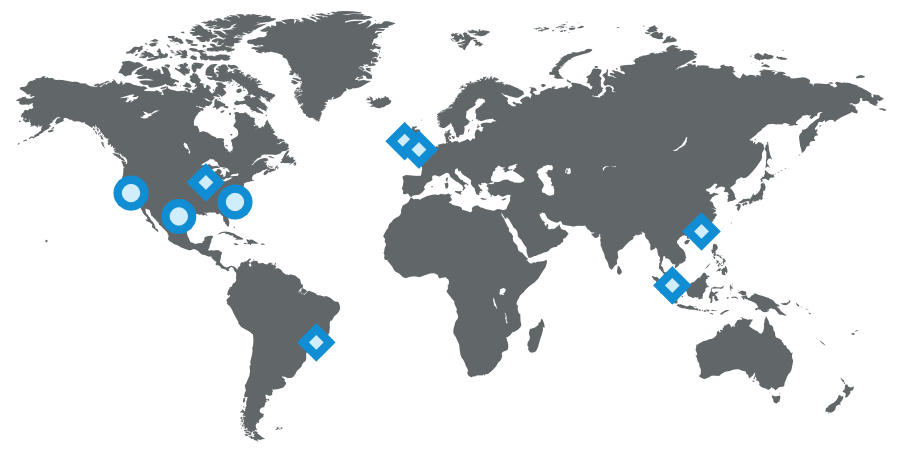](https://box.kancloud.cn/2015-07-30_55b9e3aa5e1af.png "LinkedIn's operational setup as of 2015 (circles represent data centers, diamonds represent PoPs)")LinkedIn's operational setup as of 2015 (circles represent data centers, diamonds represent PoPs)
## 我們還做了哪些工作?
當然,我們的擴展故事永遠不會這么簡單。我們的工程和運維團隊這些年做了不計其數的工作,主要包括這些大的創新:
這些年很多最關鍵系統都有自己豐富的擴展演化歷史,包括會員圖服務(Leo之外的第一個服務),搜索(第二個服務),新聞種子,通訊平臺及會員信息后臺。
我們還構建了數據基礎平臺支持長期的增長,這是Databus和Kafka的第一次實戰,后來用Samza做數據流服務,Espresso和Voldemort作存儲解決方案,Pinot用來分析系統,以及其它自定義解決方案。另外,我們的工具也得到了提升,這樣工程師就可以自動化布署這些基礎架構。
我們還使用Hadoop和Voldemort數據開發了大量的離線工作流,用以智能分析,如“你可能認識的人”,“相似經歷”,“感覺興趣的校友”及“個人簡歷瀏覽地圖”。
我們重新考慮了前端的實現,增加客戶端模板到混合頁面(個人中心、我的大學頁面),這樣應用可以更加可交互,只要我們的服務器發送JSON或部分JSON數據。此外,模板頁面通過CDN和瀏覽器緩存。我們也開始使用了BigPipe和Play框架,把我們的模型從線程化的服務器變成非阻塞異步的服務器。
除了代碼,我們使用了Apache Traffic Server做多層代理和用HAProxy做負載均衡,數據中心,安全,智能路由,服務端渲染等等。
最后,我們繼續提升服務器的性能,包含優化硬件,內存和系統的高級優化,使用更新的JRE。
## 下一步
LinkedIn今天仍在快速增長,仍有大量值得提升的工作要做,我們正在解決一些問題,看起來只解決了一部分 -?[快來加入我們吧!](https://www.linkedin.com/company/linkedin/careers?trk=eng-blog)
感謝Steve, Swee, Venkat, Eran, Ram, Brandon, Mammad, 和 Nick的審閱和幫助
