## Leo
和現在很多站點開始的時候一樣, LinkedIn使用一個應用程序做所有的工作。 這個應用程序被稱之為 "Leo"。它包含所有的Java Servlet頁面, 處理業務邏輯, 連接少量的LinkedIn數據庫。
[](https://box.kancloud.cn/2015-07-30_55b9e34927a3a.png "*哈!早年網站的樣式-簡單實用*")
*哈!早年網站的樣式-簡單實用*
## Member Graph (會員關系圖)
開始的工作之一就是管理會員之間關系的社交網絡。我們需要一個系統通過圖遍歷(graph traversals)的方式來查詢關系數據, 同時需要將數據駐留內存以便獲得高效和性能。從這個不同的使用特征來看, 很明顯這需要一個獨立于Leo的系統以方便擴大規模,于是一個叫做"Clould"專門用于會員關系圖(member graph)的獨立系統誕生了。這是LinkedIn的第一個服務系統。為了和Leo系統分離,我們使用Java RPC來進行通訊。
也大約在此期間我們需要增加搜索服務的能力。我們的會員關系圖服務也提供數據給一個基于[Lucene](https://lucene.apache.org/)的搜索服務。
## Replica read DBs (多個只讀數據庫副本)
隨著站點的增長, Leo系統也在擴大, 增加了更多的角色和職能, 也更加復雜。 通過負載均衡可以運行多個Leo實例,但是新增的負載也影響到LinkedIn的最關鍵系統-會員信息數據庫。
一個最容易的解決方案就是垂直擴展 - 在其上增加更多的CPU和內存。這雖然可以支撐一段時間,但是將來我們還是會遇到規模擴展的問題。會員信息數據庫既處理讀又處理寫。 為了擴展,我們引入了復制從庫(replica slave DB)。 復制數據庫是會員數據庫的一個拷貝, 使用?[databus](http://data.linkedin.com/blog/2012/10/driving-the-databus)?(現已開源)的最早版本來進行同步。這些復制從庫處理所有的讀請求, 并且增加了保證主庫和從庫數據一致性的邏輯。
[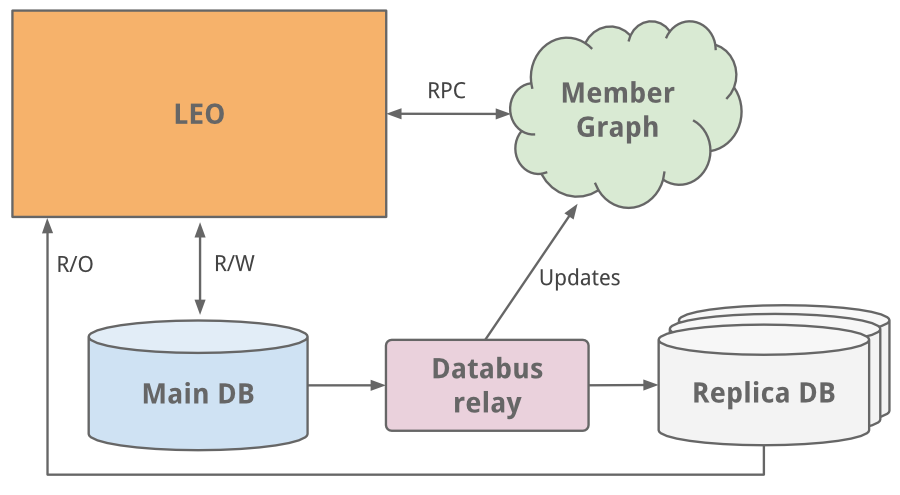](https://box.kancloud.cn/2015-07-30_55b9e35579c93.png "*主從讀寫分離的方案之后,我們轉向了數據庫分區的解決方案*")
*主從讀寫分離的方案之后,我們轉向了數據庫分區的解決方案*
當站點遇到越來越多的流量時,單一的Leo系統經常宕機,而且很難排查和恢復, 發布新代碼也很困難。 高可用性對LinkedIn至關重要, 很明顯我們需要"干掉" Leo, 把它分解成多個小的功能模塊和無狀態的服務。
[](https://box.kancloud.cn/2015-07-30_55b9e357d39e7.jpg "*")
*"Kill Leo"這個咒語在內部傳頌了好多年*
## Service Oriented Architecture (面向服務的架構)
工程師開始抽取出一些微服務, 這些微服務提供API和一些業務邏輯, 如搜索,會員信息, 通訊和群組平臺。接著我們的表現層也被抽取出來了,比如招聘產品和公共信息頁。新產品,新服務都獨立于Leo。 不久,各個功能區的垂直棧完成了。
我們構建了前端服務器, 可以從不同的域獲取數據,處理展示邏輯以及生成HTML (通過JSP)。我們還構建了中間層服務提供API接口訪問數據模型以及提供數據庫一致性訪問后端數據服務。到2010年,我們已經有超過150個獨立的服務,而今天,我們已經有超過750個服務。
[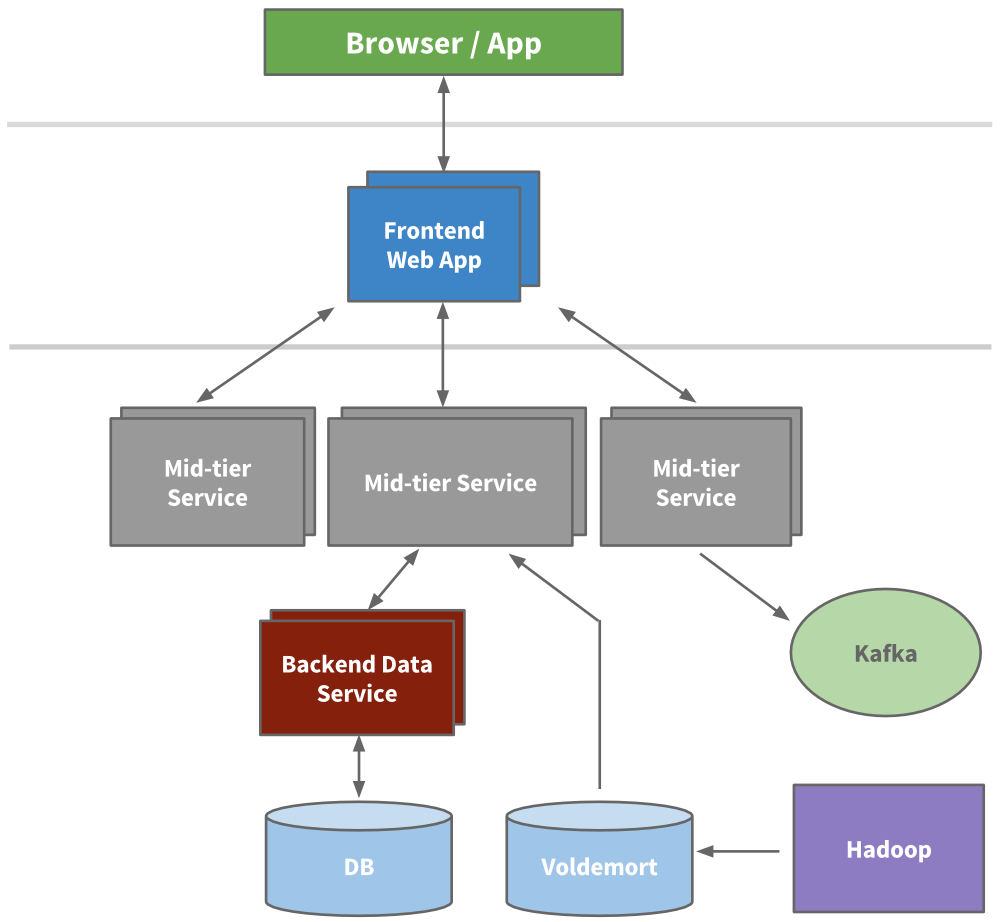](https://box.kancloud.cn/2015-07-30_55b9e358dee69.png)
因為無狀態, 規模擴展可以通過堆疊任意服務的新實例以及在它們之間進行負載均衡來完成。我們給每個服務設定了警戒紅線, 知道它的負載能力, 提供早期預警和性能監控。
## cache (緩存)
LinkedIn可預見的增長促使我們要進一步的擴展。我們知道通過添加更多的緩存層以減少負載壓力。很多應用開始引入中間緩存層如?[memecached](https://en.wikipedia.org/wiki/Memcached)?或者?[couchbase](https://en.wikipedia.org/wiki/Couchbase_Server)。 我們還在數據層增加了緩存, 并且在適當的時候使用?[Voldemort](http://engineering.linkedin.com/tags/voldemort)?提供預先計算的結果。
之后,我們實際上去掉了中間緩存層。中間緩存層存儲來自多個域的數據。雖然開始時緩存看起來是減少壓力的一種簡單方式,但是緩存數據失效的復雜性和調用圖(call graph)變得無法控制。將緩存更可能地接近數據層可以降低延遲, 使我們可以水平擴展,降低可知的負載(cognitive load)。
## Kafka
為了收集日益增長的數據,LinkedIn開發了很多定制的數據通道來流水化和隊列化數據(streaming and queueing)。 比如, 我們需要將數據放入數據倉庫,我們需要將一批數據放入Hadoop工作流以便分析,我們從每個服務中中聚合了大量日志, 我們收集了很多用戶追蹤事件如頁面點擊, 我們需要隊列化inMail消息系統中的數據, 我們需要保證用戶更新完個人信息后搜索數據也是最新的等等。
隨著網站還在壯大,更多的定制管道出現了。 因為網站規模需要擴展,每一個獨立的管道也需要擴展, 有些東西不得不放棄。 結果就是Kafka開發出來了, 它是我們的分布式的發布訂閱消息系統。Kafka成為一個統一的管道, 根據[commit log](http://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying)的概念構建, 特別注重速度和擴展性。 它可以接近實時的訪問數據源,驅動Hadoop任務, 允許我們構建實時的分析,廣泛地提升了我們的站點監控和報警能力, 也使我們能夠可視化和跟蹤調用圖(call graph)。 今天, Kafka 每天處理超過[5千億的事件](http://engineering.linkedin.com/kafka/kafka-linkedin-current-and-future)。
[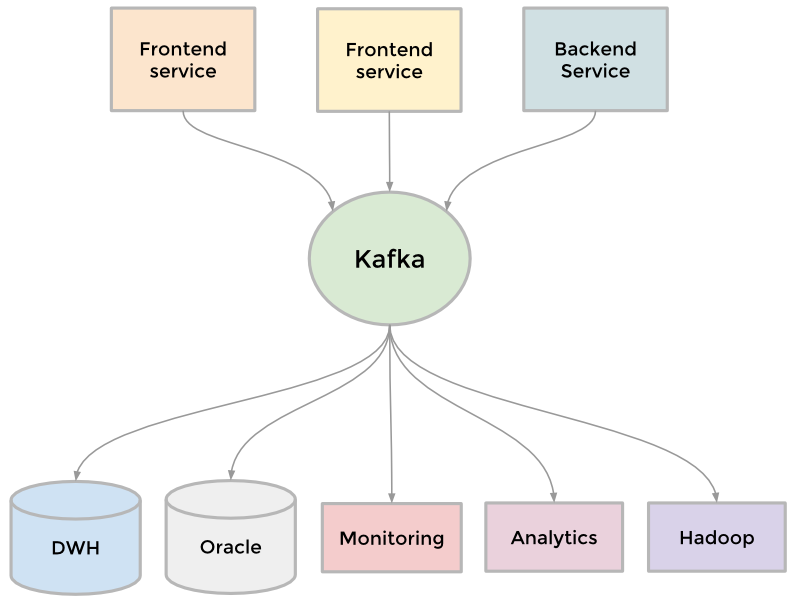](https://box.kancloud.cn/2015-07-30_55b9e35b43305.png)
## Inversion(反轉)
擴展可以從很多維度來衡量,包括組織結構。 在2011年底, LinkedIn開始了一個內部創新,叫 “反轉” ([Inversion](http://www.bloomberg.com/bw/articles/2013-04-10/inside-operation-inversion-the-code-freeze-that-saved-linkedin))。我們暫停了新功能的開發, 允許整個工程部門專注于提升工具,部署,基礎架構和開發者生產力上。它成功地使我們可以敏捷地建立可擴展性新產品。
