
[音頻傳輸之Jitter Buffer設計與實現](https://www.cnblogs.com/talkaudiodev/p/8025242.html)
在語音通信中Jitter Buffer(下面簡稱JB)是接收側一個非常重要的模塊,它是決定音質的重要因素之一。一方面它會把收到的亂序的語音包排好序放在buffer里正確的位置上,另一方面它把接收到的語音包放在buffer中緩沖一些時間使播放的更平滑從而獲得更好的語音質量。下圖是JB在接收側軟件框圖中的位置。

從上圖可以看出,從網絡上收到的語音包會放在JB里(這個操作叫做PUT),在需要的時候便從JB里取出來(這個操作叫做GET)解碼直到播放出來。JB有兩種模式:adaptive(自適應的)和fixed(固定的)。Adaptive是指buffer的大小可以根據網絡環境的狀況自適應的調整;fixed是指buffer的大小固定不變。自適應的模式實現難度大,要求高,fixed相對簡單,現在基本上都用adaptive的模式。JB在生命周期里也有兩種狀態:prefetching(預存取)和processing(處理中),只有在processing時才能從JB中取到語音幀。初始化時把狀態置成prefetching,當在JB中的語音包個數達到指定的值時便把狀態切到processing。如果從JB里取不到語音幀了,它將又回到prefetching。等buffer里語音包個數達到指定值時又重新回到processing狀態。
首先看PUT操作。RTP包有包頭和負載(payload),為了便于處理,將包頭和payload在buffer中分開保存,保存包頭中相關屬性的叫attribute buffer,保存payload的叫payload buffer。下圖是JB里存RTP包的buffer關系圖:
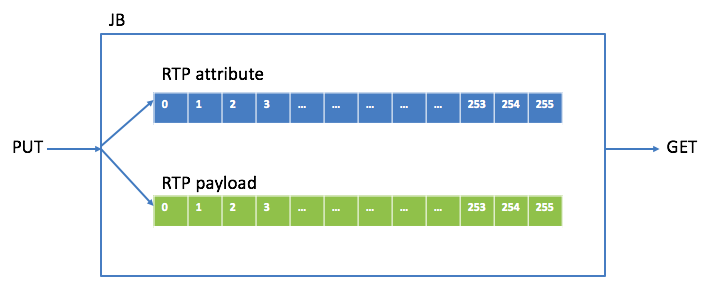
要明確哪幾種類型的RTP包會被PUT進JB,我最初設計JB時類型有G711/G722/G729/SID(靜音包)/RFC2833(DTMF包)。
.
G711/G722十毫秒payload是80個字節,G729十毫秒payload是10個字節,當VAD使能時十毫秒payload是2個字節(G729 VAD是內置的)或0個字節(DTX),一個SID包payload是1個或11個字節,一個RFC2833包payload是4個字節,明確這些是為了確定payload buffer中一個block的大小(取這些類型中最大的,80個字節),attribute buffer中一個block的大小是固定的,即要保存的屬性的個數(這些屬性主要用于控制payload的存放和讀取,有media type(G711/G722/G729/SID/RFC2833),sequence number,timestamp,ssrc,payload size,相對應的存放payload的buffer block指針等。
.
每個RTP的包頭占一個attribute buffer block,但每個RTP的payload有可能占幾個payload buffer block,這跟media type 和packet time有關,例如一個packet time為20ms的G711包,就需要兩個payload buffer block,attribute buffer block和payload buffer block之間有一個映射關系。將attribute buffer block和payload buffer block個數都定為256(index從0到255,設定256是為了早到的包絕不會把前面的包給覆蓋掉,如果block個數小了則有可能),這樣JB 里最少可以存2560ms的語音數據。?
至于JB里最多能放多少個包(即容量capacity),這取決于media type和packet time。如果media type是G711/G722, capacity = 256\*10/packet time,例如當packet time為20ms時,capacity是128,即最多放128個包。這樣attribute buffer和payload buffer的映射關系如下圖:
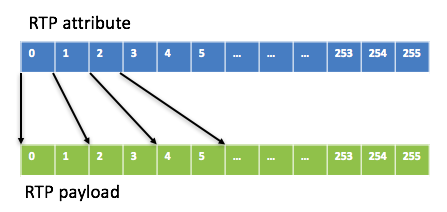
如果media type是G729,考慮到packet time 通常不會超過160ms, 就設定一個G7299包的payload占2個block(160個字節,一般是存不滿的),這樣capacity就是128(256/2)。至于SID和RFC2833包,payload只有幾個字節,為了處理簡單,它們的payload占幾個block是跟著語音包走的,比如一個20ms的G711語音包payload占2個block,SID包和RFC2833包的payload也會占2個block。
.
從網絡上來的RTP包有可能是亂序的,PUT操作要把這些亂序的包(attribute & payload)放在buffer里正確的block里,這主要依靠attribute里的sequence number和timestamp做判斷。RTP協議里sequence number數據類型是unsigned short,范圍是0~65535,就存在從65535到0的轉換,這增加了復雜度。對于收到的RTP包,首先要看它是否來的太遲(相對于上一個已經取出的包),太遲了就要把這個包主動丟棄掉。設上一個已經取出的包的sequence number為 last\_got\_senq,timestamp 為last\_got\_timestamp,當前收到的將要放的包的sequence number為 cur\_senq,timestamp 為cur\_timestamp,當前包的sequence number與上一個取走的sequence number的gap為delta\_senq,則delta\_senq可以根據下面的邏輯關系得到。

如果delta\_senq小于1,就可以認為這個包來的太遲,就要主動丟棄掉。由于我們的buffer足夠大(256個block),如果包早到了也會被放到對應的position上,不會把相應位置上的還沒取走的覆蓋掉。
.
接下來看怎么把包放到正確的位置上。對于收到的第一個包,它的位置(position,范圍是0 ~ capacity-1)是sequence number % capacity。后面的包放的position依賴于它上一個已放好的包的position。設上一個已放好的包的sequence number為 last\_put\_senq,timestamp 為last\_put\_timestamp,position為last\_put\_position,當前收到的將要放的包的sequence number為 cur\_senq,timestamp 為cur\_timestamp,position為cur\_position,當前的包的sequence number與上一個放好的sequence number的gap為delta\_senq,則cur\_position可以根據下面的邏輯關系得到。

得到了當前包的position后就可以把包頭里的timestamp等放到相應的attribute buffer block里了,payload根據算好的占幾個block放到相應的那幾個block上(有可能填不滿block,不過沒關系,取payload時是根據index取的)。如果放進對應block時發現里面已經有包了并且sequence number一樣,說明這個包是重復包,就要把這個包主動丟棄掉。
.
再來看GET操作。每次從JB里不是取一個包,而是取1幀(能編解碼的最小單位,通常是10ms,也有例外,比如AMR-WB是20ms),這主要是因為播放loop是10ms一次(每次都是取一幀語音數據播放)。取時總是從head上取,開始時head為第一個放進JB的包的position,每取完一個包(幾幀)后head就會向后移一個位置。如果到某個位置時它的block里沒有包,就說明這個包丟了,這時取出的就是payload大小就是0,告訴后續的decoder要做PLC。不同類型的包取法不一樣,下面分別加以介紹。
.
對于G711/G722,每次從payload buffer里取10ms數據(一個block, 80個字節),一個包取完后取下一個包。對于G729,每次從payload buffer里取10ms數據(10個字節或2個字節(VAD使能后的靜音payload)或0個字節(DTX)),一個包取完后取下一個包。至于VAD使能后取10個字節還是2個字節還是0個字節,要取決于當前包以及上一包的payload size。這處理好能顯著提高G7229 VAD使能場景下的語音質量MOS值。以packet time為20ms為例,如果上一個包的payload size是20個字節,當前包的payload size是12個字節,在取時前10ms取10個字節,后10ms取2個字節。如果上一個包的payload size是12個字節,當前包的payload size是10個字節,在取時前10ms取0個字節(DTX),后10ms取10個字節。
.
對于SID包,每次都是從當前包中取相同的payload一直到發現JB里這個SID包后面又有包并且timestamp又大于等于這個包的timestamp,下一次就會從這個新包里取payload。對于RFC2833包,包里有個duration attribute,當前RFC2833包和上一個RFC2833包的duration相減再除以80就是當前包的packet time,根據這算是從這個包里取得次數,次數到后就從下一個包取。
.
上面說過現在JB一般都是用adaptive的mode,即buffer size(緩存包的個數)根據網絡環境自適應的調整大小。那怎么來實現呢?JB初始化時會設定一個緩存包的個數值(叫prefetch),并處于prefetching狀態,這種狀態下是取不到語音幀的。JB里緩存包的個數到達設定的值后就會變成processing狀態,同時可以從JB里取語音幀了。在通話過程中由于網絡環境變得惡劣,GET的次數比PUT的次數多,GET完最后一幀就進入prefetching狀態。當再有包PUT進JB時,先看前面共有多少次連續的GET,從而增大prefetch值,即增大buffer size的大小。如果網絡變得穩定了,GET和PUT就會交替出現,當交替出現的次數達到一定值時,就會減小prefetch值,即減小buffer size的大小,交替的次數更多時再繼續減小prefetch值。
*****
再來看一下在哪些情況下需要reset JB,讓JB在初始狀態下開始運行。
1)當收到的語音包的媒體類型(G711/G722/G729,不包括SID/RFC2833等)變了,就認為來了新的stream,需要reset JB。
2)當收到的語音包的SSRC變了,就認為來了新的stream,需要reset JB。
3)當收到的語音包的packet time變了,就認為來了新的stream,需要reset JB。
前面說過JB是語音通信接收側最重要的模塊之一,當然它也是容易出問題的模塊之一。出問題不怕,關鍵是怎么快速定位問題。對于JB來說,需要知道當前的運行狀態以及一些統計信息等。如果這些信息正常,就說明問題很大可能不是由JB引起的,不正常則說明有很大的可能性。這些信息主要如下:
1)JB當前運行狀態:prefetching / processing
2)JB里有多少個緩存的包
3)從JB中取幀的head的位置
4)緩沖區的capacity是多少
5)網絡丟包的個數
6)由于來的太遲而被主動丟棄的包的個數
7)由于JB里已有這個包而被主動丟棄的包的個數
8)進prefetching狀態的次數(除了第一次)
.
上面就是JB設計的主要思想,在實現時還有很多細節需要注意,這里就不一一詳細說了。我第一次設計實現JB是在2011年,當時從設計實現到調試完成(指標是:bulk call > 10000次,long call time > 60 小時,各種場景下的各種codec的語音質量要達標)總共花了近三個月,還是在對JB有基礎的情況下,要是沒基礎花的時間更多。從設計到能打電話時間不長,主要是后面要過bulk call/long call/voice quality。有好多情況設計時沒考慮到,這也是一個迭代的過程,當調試完成了設計也更完整了。最初設計時只支持G711/G722/G729這三種codec,但是機制定了。后來系統要支持AMR-WB,JB這部分根據現有的機制再加上AMR-WB特有的很快就調好了。
- 序言
- 編解碼
- H264
- HEVC碼流解析
- H264編碼原理
- 多媒體封裝
- MP4
- 學好 MP4,讓直播更給力
- AAC
- FLV
- 流媒體協議
- RTSP
- RTCP
- RTP
- H265 RTP封包筆記
- SDP
- RTMP
- RTMP URL
- rtmp url基礎
- webrtc
- 編譯
- 最簡單的編譯webrtc方案
- Webrtc音視頻會議之Webrtc“不求甚解”
- Webrtc音視頻會議之Mesh/MCU/SFU三種架構
- 音頻傳輸之Jitter Buffer設計與實現
- Janus
- Webrtc音視頻會議之Janus編譯
- Webrtc音視頻會議之Janus源碼架構設計
- webrtc服務器-janus房間管理
- 源碼分析
- WebRTC視頻JitterBuffer詳解
- 走讀Webrtc 中的視頻JitterBuffer(一)
- 走讀webrtc 中的視頻JitterBuffer(二)
- webrtc視頻幀率控制算法機制
- 目標碼率丟幀-1
- 目標幀率丟幀-2
- 29 如何使用Medooze 實現多方視頻會議
- FFmpeg
- FFmpeg編譯
- Window10下編譯最新版FFmpeg的方法步驟
- FFMPEG靜態庫編譯
- ffmpeg實現畫中畫
- FFmpeg推流器
- ffmpeg-aac
- OpenCV
- OpenCV學習筆記——視頻的邊緣檢測
- 圖像特征點匹配(視頻質量診斷、畫面抖動檢測)
- 圖像質量診斷