
[TOC]
# HTTP 和 HTTPS
### HTTP 的基本概念
http: 是互聯網上應用最為廣泛的一種網絡協議,是一個客戶端和服務器端`請求和應答的標準(TCP)`,用于從 WWW 服務器傳輸超文本到本地瀏覽器的`超文本傳輸協議`。
### HTTP工作原理
HTTP協議定義Web客戶端如何從Web服務器請求Web頁面,以及服務器如何把Web頁面傳送給客戶端。客戶端向服務器發送一個請求報文,服務器以一個狀態行作為響應。
### HTTP請求/響應的步驟
* 1.客戶端連接到Web服務器
* 2.發送HTTP請求
* 3.服務器接受請求并返回HTTP響應
* 4.釋放TCP連接
* 5.客戶端(瀏覽器)解析HTML內容
> 記憶口訣:連接發送加響應,釋放解析整過程。
### HTTP 的 5 種方法
* GET---獲取資源
* POST---傳輸資源
* PUT---更新資源
* DELETE---刪除資源
* HEAD---獲取報文首部
### GET與POST的區別
**1.瀏覽器回退表現不同** GET在瀏覽器回退時是無害的,而POST會再次提交請求
**2.瀏覽器對請求地址的處理不同** GET請求地址會被瀏覽器主動緩存,而POST不會,除非手動設置
**3.瀏覽器對響應的處理不同**GET請求參數會被完整的保留在瀏覽器歷史記錄里,而POST中的參數不會被保留
**4.參數大小不同.** GET請求在URL中傳送的參數是有長度的限制,而POST沒有限制
**5.安全性不同.** GET參數通過URL傳遞,會暴露,不安全;POST放在Request Body中,相對更安全
**6.針對數據操作的類型不同**.GET對數據進行查詢,POST主要對數據進行增刪改!簡單說,GET是只讀,POST是寫。
### HTTP報文的組成成分
請求報文{ 請求行、請求頭、空行、請求體 } 請求行:{http方法、頁面地址、http協議、http版本} 響應報文{ 狀態行、響應頭、空行、響應體 }
**Request Header:**
1. **GET /sample.Jsp HTTP/1.1** ?//請求行
2. **Host:** ?www.uuid.online/ //請求的目標域名和端口號
3. **Origin:**?[http://localhost:8081/](http://localhost:8081/) //請求的來源域名和端口號 (跨域請求時,瀏覽器會自動帶上這個頭信息)
4. **Referer:** [https://localhost:8081/link?query=xxxxx](https://localhost:8081/link?query=xxxxx) //請求資源的完整URI
5. **User-Agent:**?Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36?//瀏覽器信息
6. **Cookie:** ?BAIDUID=FA89F036:FG=1; BD\_HOME=1; sugstore=0??//當前域名下的Cookie
7. **Accept:**?text/html,image/apng??//代表客戶端希望接受的數據類型是html或者是png圖片類型
8. **Accept-Encoding:**?gzip, deflate??//代表客戶端能支持gzip和deflate格式的壓縮
9. **Accept-Language:** zh-CN,zh;q=0.9??//代表客戶端可以支持語言zh-CN或者zh(值得一提的是q(0~1)是優先級權重的意思,不寫默認為1,這里zh-CN是1,zh是0.9)
10. **Connection:**?keep-alive??//告訴服務器,客戶端需要的tcp連接是一個長連接
**Response Header:**
1. **HTTP/1.1 200 OK**??//?響應狀態行
2. **Date:** ?Mon, 30 Jul 2018 02:50:55 GMT??//服務端發送資源時的服務器時間
3. **Expires:** ?Wed, 31 Dec 1969 23:59:59 GMT?//比較過時的一種驗證緩存的方式,與瀏覽器(客戶端)的時間比較,超過這個時間就不用緩存(不和服務器進行驗證),適合版本比較穩定的網頁
4. **Cache-Control:** ?no-cache??// 現在最多使用的控制緩存的方式,會和服務器進行緩存驗證,具體見[博文”Cache-Control“](https://www.cnblogs.com/amiezhang/p/9389537.html)
5. **etag:** ?"fb8ba2f80b1d324bb997cbe188f28187-ssl-df"??// 一般是[Nginx靜態服務器](http://www.t086.com/article/5207)發來的靜態文件簽名,瀏覽在沒有“Disabled cache”情況下,接收到etag后,同一個url第二次請求就會自動帶上“If-None-Match”
6. **Last-Modified:** ?Fri, 27 Jul 2018 11:04:55 GMT?//是服務器發來的當前資源最后一次修改的時間,下次請求時,如果服務器上當前資源的修改時間大于這個時間,就返回新的資源內容
7. **Content-Type:** ?text/html; charset=utf-8??//如果返回是流式的數據,我們就必須告訴瀏覽器這個頭,不然瀏覽器會下載這個頁面,同時告訴瀏覽器是utf8編碼,否則可能出現亂碼
8. **Content-Encoding:** ?gzip??//告訴客戶端,應該采用gzip對資源進行解碼
9. **Connection:** ?keep-alive??//告訴客戶端服務器的tcp連接也是一個長連接
### https 的基本概念
https:是以安全為目標的 HTTP 通道,即 HTTP 下 加入 SSL 層進行加密。
https 協議的作用:建立一個信息安全通道,來確保數據的傳輸,確保網站的真實性。
### http 和 https 的區別?
* http 是超文本傳輸協議,信息是明文傳輸,https 則是具有安全性的 ssl 加密傳輸協議。
* Https 協議需要 ca 證書,費用較高。
* 使用不同的鏈接方式,端口也不同,一般,http 協議的端口為 80,https 的端口為 443。
* http 的連接很簡單,是無狀態的。
> 記憶口訣:明文傳輸超文本,安全等級各不同。CA證書費用高,無狀連接端難同。
#### https 協議的工作原理
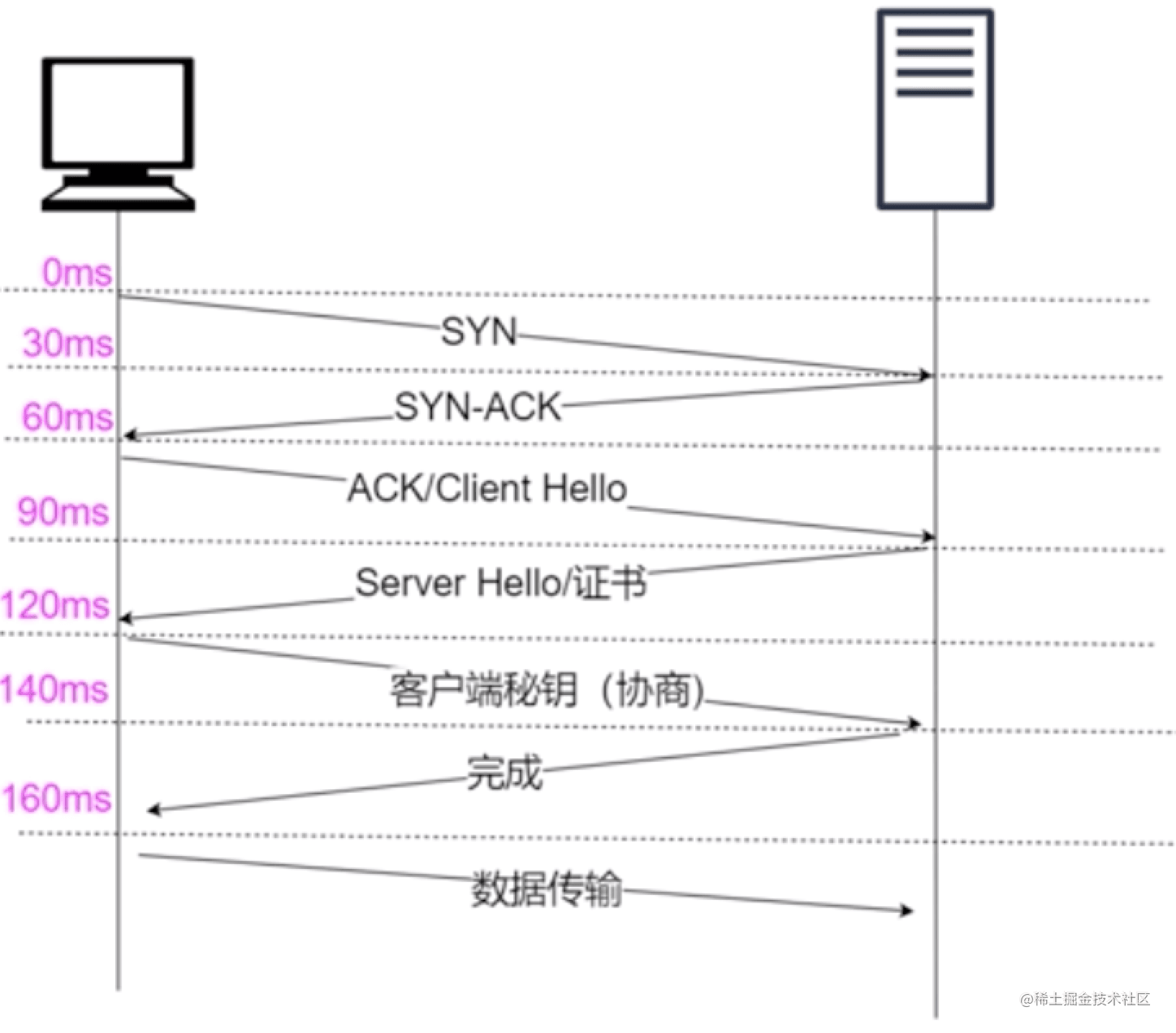
客戶端在使用 HTTPS 方式與 Web 服務器通信時有以下幾個步驟:
1. 客戶端使用 https url 訪問服務器,則要求 web 服務器`建立 ssl 鏈接`。
2. web 服務器接收到客戶端的請求之后,會`將網站的證書(證書中包含了公鑰),傳輸給客戶端`。
3. 客戶端和 web 服務器端開始`協商 SSL 鏈接的安全等級`,也就是加密等級。
4. 客戶端瀏覽器通過雙方協商一致的安全等級,`建立會話密鑰`,然后通過網站的公鑰來加密會話密鑰,并傳送給網站。
5. web 服務器`通過自己的私鑰解密出會話密鑰`。
6. web 服務器`通過會話密鑰加密與客戶端之間的通信`。
> 記憶口訣:一連二傳三協商,四建五得六使用。
#### https 協議的優缺點
* HTTPS 協議要比 http 協議`安全`,可防止數據在傳輸過程中被竊取、改變,確保數據的完整性。
* https 握手階段比較`費時`,會使頁面加載時間延長 50%,增加 10%~20%的耗電。
* https `緩存`不如 http 高效,會增加數據開銷。
* SSL 證書也需要錢,功能越強大的`證書費`用越高。
* SSL 證書需要綁定 `IP`,不能再同一個 ip 上綁定多個域名,ipv4 資源支持不了這種消耗。
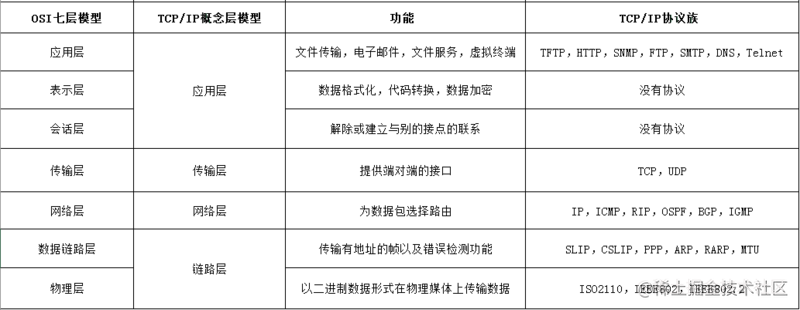
### TCP/IP網絡模型
TCP/IP模型是互聯網的基礎,它是一系列網絡協議的總稱。這些協議可以劃分為四層,分別為鏈路層、網絡層、傳輸層和應用層。
* 鏈路層:負責封裝和解封裝IP報文,發送和接受ARP/RARP報文等。
* 網絡層:負責路由以及把分組報文發送給目標網絡或主機。
* 傳輸層:負責對報文進行分組和重組,并以TCP或UDP協議格式封裝報文。
* 應用層:負責向用戶提供應用程序,比如HTTP、FTP、Telnet、DNS、SMTP等。
### TCP三次握手
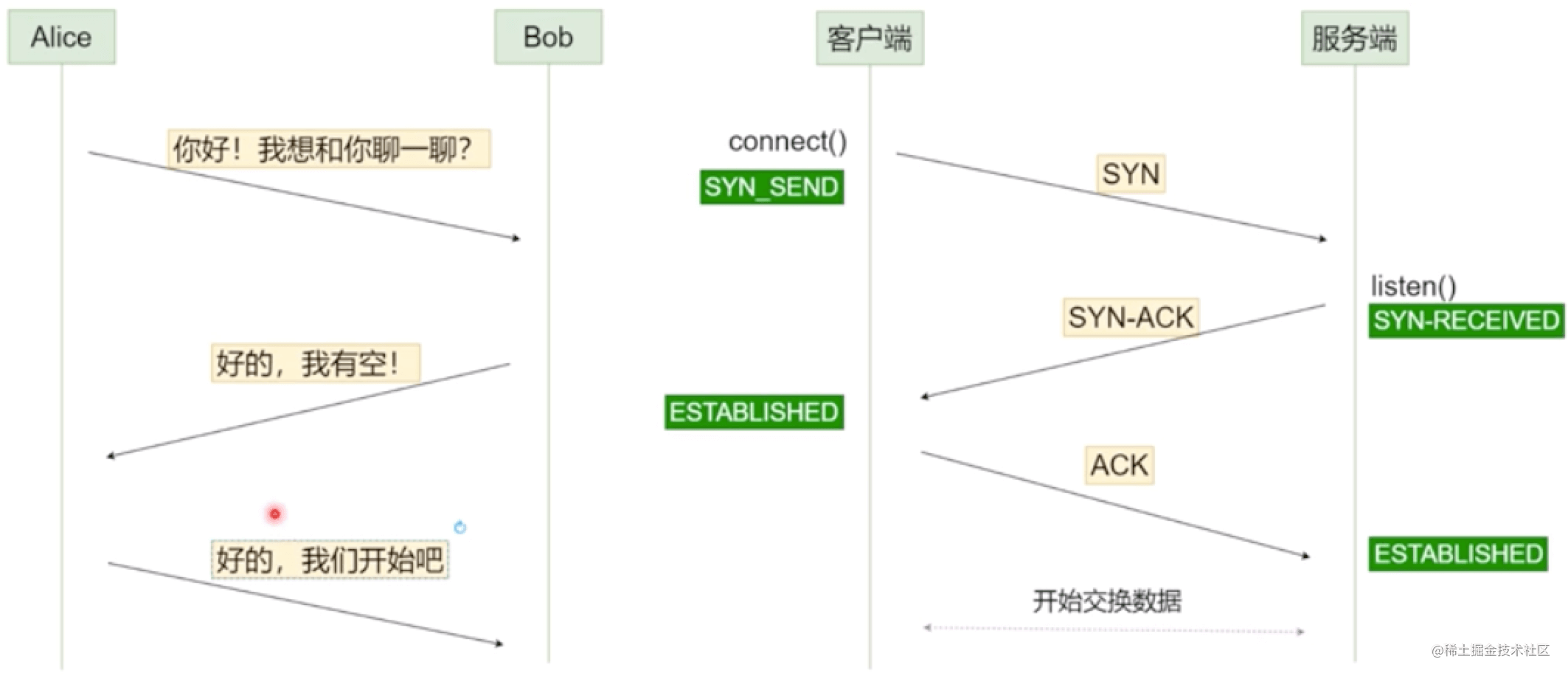
1. 第一次握手:`建立連接時,客戶端發送syn包(syn=j)到服務器,并進入SYN_SENT狀態,等待服務器確認`;SYN:同步序列編號(Synchronize Sequence Numbers)。
2. 第二次握手:`服務器收到syn包并確認客戶的SYN`(ack=j+1),`同時也發送一個自己的SYN包`(syn=k),即SYN+ACK包,此時服務器進入SYN\_RECV狀態;
3. 第三次握手:`客戶端收到服務器的SYN+ACK包,向服務器發送確認包ACK(ack=k+1)`,此包發送完畢,客戶端和服務器進入ESTABLISHED(TCP連接成功)狀態,完成三次握手。
```
握手過程中傳送的包里不包含數據,三次握手完畢后,客戶端與服務器才正式開始傳送數據。
```
### TCP 四次揮手
1. `客戶端進程發出連接釋放報文`,并且停止發送數據。釋放數據報文首部,FIN=1,其序列號為seq=u(等于前面已經傳送過來的數據的最后一個字節的序號加1),此時,客戶端進入FIN-WAIT-1(終止等待1)狀態。 TCP規定,FIN報文段即使不攜帶數據,也要消耗一個序號。
2)`服務器收到連接釋放報文,發出確認報文`,ACK=1,ack=u+1,并且帶上自己的序列號seq=v,此時,服務端就進入了CLOSE-WAIT(關閉等待)狀態。TCP服務器通知高層的應用進程,客戶端向服務器的方向就釋放了,這時候處于半關閉狀態,即客戶端已經沒有數據要發送了,但是服務器若發送數據,客戶端依然要接受。這個狀態還要持續一段時間,也就是整個CLOSE-WAIT狀態持續的時間。
3)客戶端收到服務器的確認請求后,此時,客戶端就進入FIN-WAIT-2(終止等待2)狀態,等待服務器發送連接釋放報文(在這之前還需要接受服務器發送的最 后的數據)。
4)`服務器將最后的數據發送完畢后,就向客戶端發送連接釋放報文`,FIN=1,ack=u+1,由于在半關閉狀態,服務器很可能又發送了一些數據,假定此時的序列號為seq=w,此時,服務器就進入了LAST-ACK(最后確認)狀態,等待客戶端的確認。
5)`客戶端收到服務器的連接釋放報文后,必須發出確認`,ACK=1,ack=w+1,而自己的序列號是seq=u+1,此時,客戶端就進入了TIME-WAIT(時間等待)狀態。注意此時TCP連接還沒有釋放,必須經過2??MSL(最長報文段壽命)的時間后,當客戶端撤銷相應的TCB后,才進入CLOSED狀態。
6)服務器只要收到了客戶端發出的確認,立即進入CLOSED狀態。同樣,撤銷TCB后,就結束了這次的TCP連接。可以看到,服務器結束TCP連接的時間要比客戶端早一些。
### TCP和UDP的區別
1. TCP是面向`連接`的,而UDP是面向無連接的。
2. TCP僅支持`單播傳輸`,UDP 提供了單播,多播,廣播的功能。
3. TCP的三次握手保證了連接的`可靠性`; UDP是無連接的、不可靠的一種數據傳輸協議,首先不可靠性體現在無連接上,通信都不需要建立連接,對接收到的數據也不發送確認信號,發送端不知道數據是否會正確接收。
4. UDP的`頭部開銷`比TCP的更小,數據`傳輸速率更高`,`實時性更好`。
### HTTP 請求跨域問題
1. 跨域的原理
**跨域**,是指瀏覽器不能執行其他網站的腳本。它是由瀏覽器的`同源策略`造成的。**同源策略**,是瀏覽器對 JavaScript 實施的安全限制,只要`協議、域名、端口`有任何一個不同,都被當作是不同的域。**跨域原理**,即是通過各種方式,`避開瀏覽器的安全限制`。
2. 解決方案
最初做項目的時候,使用的是jsonp,但存在一些問題,使用get請求不安全,攜帶數據較小,后來也用過iframe,但只有主域相同才行,也是存在些問題,后來通過了解和學習發現使用代理和proxy代理配合起來使用比較方便,就引導后臺按這種方式做下服務器配置,在開發中使用proxy,在服務器上使用nginx代理,這樣開發過程中彼此都方便,效率也高;現在h5新特性還有 windows.postMessage()
* **JSONP**:ajax 請求受同源策略影響,不允許進行跨域請求,而 script 標簽 src 屬性中的鏈 接卻可以訪問跨域的 js 腳本,利用這個特性,服務端不再返回 JSON 格式的數據,而是 返回一段調用某個函數的 js 代碼,在 src 中進行了調用,這樣實現了跨域。
步驟:
1. 去創建一個script標簽
2. script的src屬性設置接口地址
3. 接口參數,必須要帶一個自定義函數名,要不然后臺無法返回數據
4. 通過定義函數名去接受返回的數據
* ```js
//動態創建 script
var script = document.createElement('script');
// 設置回調函數
function getData(data) {
console.log(data);
}
//設置 script 的 src 屬性,并設置請求地址
script.src = 'http://localhost:3000/?callback=getData';
// 讓 script 生效
document.body.appendChild(script);
```
**JSONP 的缺點**:JSON 只支持 get,因為 script 標簽只能使用 get 請求; JSONP 需要后端配合返回指定格式的數據。
* **document.domain** 基礎域名相同 子域名不同
* [**window.name**](http://window.name) 利用在一個瀏覽器窗口內,載入所有的域名都是共享一個 [window.name](http://window.name)
* **CORS** CORS(Cross-origin resource sharing)跨域資源共享 服務器設置對CORS的支持原理:服務器設置Access-Control-Allow-Origin HTTP響應頭之后,瀏覽器將會允許跨域請求
* **proxy代理** 目前常用方式
* **window.postMessage()** 利用h5新特性 window.postMessage()
* **Websocket**
### Cookie、sessionStorage、localStorage 的區別
**相同點**:
* 存儲在客戶端
**不同點**:
* cookie數據大小不能超過4k;sessionStorage和localStorage的存儲比cookie大得多,可以達到5M+
* cookie設置的過期時間之前一直有效;localStorage永久存儲,瀏覽器關閉后數據不丟失除非主動刪除數據;sessionStorage數據在當前瀏覽器窗口關閉后自動刪除
* cookie的數據會自動的傳遞到服務器;sessionStorage和localStorage數據保存在本地
### HTTP狀態碼及常見狀態碼
#### HTTP狀態碼
* 1xx:指示信息類,表示請求已接受,繼續處理
* 2xx:指示成功類,表示請求已成功接受
* 3xx:指示重定向,表示要完成請求必須進行更近一步的操作
* 4xx:指示客戶端錯誤,請求有語法錯誤或請求無法實現
* 5xx:指示服務器錯誤,服務器未能實現合法的請求
#### 常見狀態碼
* 200 OK:客戶端請求成功
* 301 Moved Permanently:所請求的頁面已經永久重定向至新的URL
* 302 Found:所請求的頁面已經臨時重定向至新的URL
* 304 Not Modified 未修改。
* 403 Forbidden:對請求頁面的訪問被禁止
* 404 Not Found:請求資源不存在
* 500 Internal Server Error:服務器發生不可預期的錯誤原來緩沖的文檔還可以繼續使用
* 503 Server Unavailable:請求未完成,服務器臨時過載或宕機,一段時間后可恢復正常
* 1xx(臨時響應)表示臨時響應并需要請求者繼續執行操作的狀態碼
* 100 - 繼續 請求者應當繼續提出請求。服務器返回此代碼表示已收到請求的第一部分,正在等待其余部分
* 101 - 切換協議 請求者已要求服務器切換協議,服務器已確認并準備切換
* 2xx(成功)表示成功處理了請求的狀態碼
* `200` - 成功 服務器已經成功處理了請求。通常,這表示服務器提供了請求的網頁
* 201 - 已創建 請求成功并且服務器創建了新的資源
* 202 - 已接受 服務器已接受請求,但尚未處理
* 203 - 非授權信息 服務器已經成功處理了請求,但返回的信息可能來自另一來源
* 204 - 無內容 服務器成功處理了請求,但沒有返回任何內容
* 205 - 重置內容 服務器成功處理了請求,但沒有返回任何內容
* 3xx(重定向)表示要完成請求,需要進一步操作;通常,這些狀態代碼用來重定向
* 300 - 多種選擇 針對請求,服務器可執行多種操作。服務器可根據請求者(user agent)選擇一項操作,或提供操作列表供請求者選擇
* `301` - 永久移動 請求的網頁已永久移動到新位置。服務器返回此響應(對GET或HEAD請求的響應)時,會自動將請求者轉到新位置
* `302` - 臨時移動 服務器目前從不同位置的網頁響應請求,但請求者應繼續使用原有位置來進行以后的請求
* 303 - 查看其它位置 請求者應當對不同的位置使用單獨的GET請求來檢索響應時,服務器返回此代碼
* `304` - 未修改 自上次請求后,請求的網頁未修改過。服務器返回此響應,不會返回網頁的內容
* 305 - 使用代理 請求者只能使用代理訪問請求的網頁。如果服務器返回此響應,還表示請求者應使用代理
* `307` - 臨時性重定向 服務器目前從不同位置的網頁響應請求,但請求者應繼續使用原有的位置來進行以后的請求
* 4xx(請求錯誤)這些狀態碼表示請求可能出錯,妨礙了服務器的處理
* `400` - 錯誤請求 服務器不理解請求的語法
* `401` - 未授權 請求要求身份驗證。對于需要登錄的網頁,服務器可能返回此響應
* `403` - 禁止 服務器拒絕請求
* `404` - 未找到 服務器找不到請求的網頁
* 405 - 方法禁用 禁用請求中指定的方法
* 406 - 不接受 無法使用請求的內容特性響應請求的網頁
* `407` - 需要代理授權 此狀態碼與401(未授權)類似,但指定請求者應當授權使用代理
* `408` - 請求超時 服務器等候請求時發生超時
* 410 - 已刪除 如果請求的資源已永久刪除,服務器就會返回此響應
* `413` - 請求實體過大 服務器無法處理請求,因為請求實體過大,超出了服務器的處理能力
* `414` - 請求的URI過長 請求的URI(通常為網址)過長,服務器無法處理
* 5xx(服務器錯誤)這些狀態碼表示服務器在嘗試處理請求時發生內部錯誤。這些錯誤可能是服務器本身的錯誤,而不是請求出錯
* `500` - 服務器內部錯誤 服務器遇到錯誤,無法完成請求
* 501 - 尚未實施 服務器不具備完成請求的功能。例如,服務器無法識別請求方法時可能會返回此代碼
* `502` - 錯誤網關 服務器作為網關或代理,從上游服務器無法收到無效響應
* `503` - 服務器不可用 服務器目前無法使用(由于超載或者停機維護)。通常,這只是暫時狀態
* `504` - 網關超時 服務器作為網關代理,但是沒有及時從上游服務器收到請求
* 505 - HTTP版本不受支持 服務器不支持請求中所用的HTTP協議版本
### 介紹下304過程
* a. 瀏覽器請求資源時首先命中資源的Expires 和 Cache-Control,Expires 受限于本地時間,如果修改了本地時間,可能會造成緩存失效,可以通過Cache-control: max-age指定最大生命周期,狀態仍然返回200,但不會請求數據,在瀏覽器中能明顯看到from cache字樣。
* b. 強緩存失效,進入協商緩存階段,首先驗證ETagETag可以保證每一個資源是唯一的,資源變化都會導致ETag變化。服務器根據客戶端上送的If-None-Match值來判斷是否命中緩存。
* c. 協商緩存Last-Modify/If-Modify-Since階段,客戶端第一次請求資源時,服務服返回的header中會加上Last-Modify,Last-modify是一個時間標識該資源的最后修改時間。再次請求該資源時,request的請求頭中會包含If-Modify-Since,該值為緩存之前返回的Last-Modify。服務器收到If-Modify-Since后,根據資源的最后修改時間判斷是否命中緩存。
### 瀏覽器的緩存機制 強制緩存 && 協商緩存
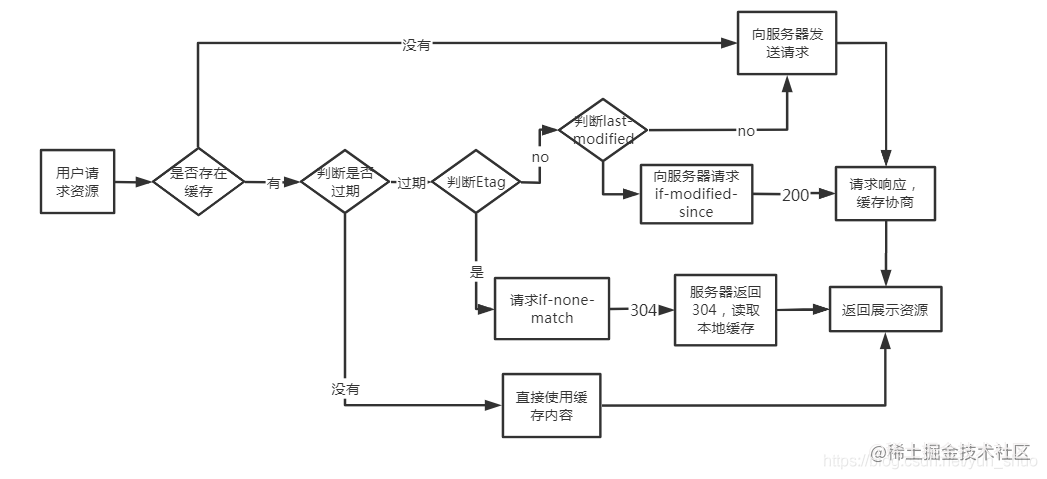
瀏覽器與服務器通信的方式為應答模式,即是:瀏覽器發起HTTP請求 – 服務器響應該請求。那么瀏覽器第一次向服務器發起該請求后拿到請求結果,會根據響應報文中HTTP頭的緩存標識,決定是否緩存結果,是則將請求結果和緩存標識存入瀏覽器緩存中,簡單的過程如下圖:
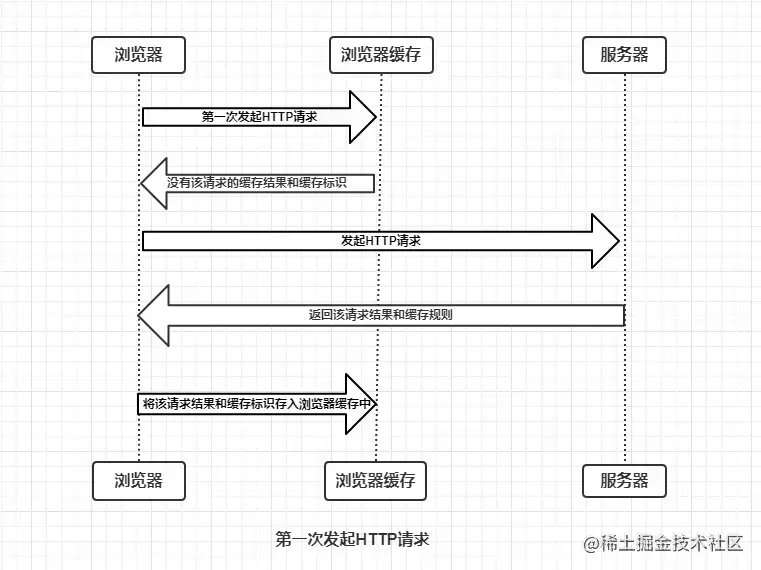
由上圖我們可以知道:
* 瀏覽器每次發起請求,都會`先在瀏覽器緩存中查找該請求的結果以及緩存標識`
* 瀏覽器每次拿到返回的請求結果都會`將該結果和緩存標識存入瀏覽器緩存中`
以上兩點結論就是瀏覽器緩存機制的關鍵,他確保了每個請求的緩存存入與讀取,只要我們再理解瀏覽器緩存的使用規則,那么所有的問題就迎刃而解了。為了方便理解,這里根據是否需要向服務器重新發起HTTP請求將緩存過程分為兩個部分,分別是`強制緩存`和`協商緩存`。
* **強制緩存**
`強制緩存就是向瀏覽器緩存查找該請求結果,并根據該結果的緩存規則來決定是否使用該緩存結果的過程。`當瀏覽器向服務器發起請求時,服務器會將緩存規則放入HTTP響應報文的HTTP頭中和請求結果一起返回給瀏覽器,控制強制緩存的字段分別是 `Expires` 和 `Cache-Control`,其中Cache-Control優先級比Expires高。
強制緩存的情況主要有三種(暫不分析協商緩存過程),如下:
1. 不存在該緩存結果和緩存標識,強制緩存失效,則直接向服務器發起請求(跟第一次發起請求一致)。
2. 存在該緩存結果和緩存標識,但該結果已失效,強制緩存失效,則使用協商緩存。
3. 存在該緩存結果和緩存標識,且該結果尚未失效,強制緩存生效,直接返回該結果
* **協商緩存**
`協商緩存就是強制緩存失效后,瀏覽器攜帶緩存標識向服務器發起請求,由服務器根據緩存標識決定是否使用緩存的過程`,同樣,協商緩存的標識也是在響應報文的HTTP頭中和請求結果一起返回給瀏覽器的,控制協商緩存的字段分別有:`Last-Modified / If-Modified-Since` 和 `Etag / If-None-Match`,其中Etag / If-None-Match的優先級比Last-Modified / If-Modified-Since高。協商緩存主要有以下兩種情況:
1. 協商緩存生效,返回304
2. 協商緩存失效,返回200和請求結果結果
傳送門 ? [\# 徹底理解瀏覽器的緩存機制](https://juejin.cn/post/6992843117963509791 "https://juejin.cn/post/6992843117963509791")
### HTTP 請求跨域問題
1. 跨域的原理
**跨域**,是指瀏覽器不能執行其他網站的腳本。它是由瀏覽器的`同源策略`造成的。跨域訪問是被各大瀏覽器所默認禁止的。**同源策略**,是瀏覽器對 JavaScript 實施的安全限制,只要`協議、域名、端口`有任何一個不同,都被當作是不同的域。**跨域原理**,即是通過各種方式,`避開瀏覽器的安全限制`。
2. 解決方案
最初做項目的時候,使用的是jsonp,但存在一些問題,使用get請求不安全,攜帶數據較小,后來也用過iframe,但只有主域相同才行,也是存在些問題,后來通過了解和學習發現使用代理和proxy代理配合起來使用比較方便,就引導后臺按這種方式做下服務器配置,在開發中使用proxy,在服務器上使用nginx代理,這樣開發過程中彼此都方便,效率也高;現在h5新特性還有 windows.postMessage()
* **JSONP**:ajax 請求受同源策略影響,不允許進行跨域請求,而 script 標簽 src 屬性中的鏈 接卻可以訪問跨域的 js 腳本,利用這個特性,服務端不再返回 JSON 格式的數據,而是 返回一段調用某個函數的 js 代碼,在 src 中進行了調用,這樣實現了跨域。
步驟:
1. 去創建一個script標簽
2. script的src屬性設置接口地址
3. 接口參數,必須要帶一個自定義函數名,要不然后臺無法返回數據
4. 通過定義函數名去接受返回的數據
* ```js
//動態創建 script
var script = document.createElement('script');
// 設置回調函數
function getData(data) {
console.log(data);
}
//設置 script 的 src 屬性,并設置請求地址
script.src = 'http://localhost:3000/?callback=getData';
// 讓 script 生效
document.body.appendChild(script);
```
**JSONP 的缺點**:JSON 只支持 get,因為 script 標簽只能使用 get 請求; JSONP 需要后端配合返回指定格式的數據。
* **document.domain** 基礎域名相同 子域名不同
* [**window.name**](http://window.name) 利用在一個瀏覽器窗口內,[載入所有的域名都是共享一個window.name](http://xn--window-9m7igl23bo8p1d816aimn1m9awlmujd5y9gz67ew7f.name)
* **CORS**
CORS(Cross-origin resource sharing)跨域資源共享 是一種機制,是目前主流的跨域解決方案,它使用額外的 HTTP 頭來告訴瀏覽器 讓運行在一個 origin (domain) 上的Web應用被準許訪問來自不同源服務器上的指定的資源。服務器設置對CORS的支持原理:服務器設置Access-Control-Allow-Origin HTTP響應頭之后,瀏覽器將會允許跨域請求
1.瀏覽器端會自動向請求頭添加origin字段,表明當前請求來源。2.服務器設置Access-Control-Allow-Origin、Access-Control-Allow-Methods、Access-Control-Allow-Headers等 HTTP響應頭字段之后,瀏覽器將會允許跨域請求。
**預檢**
但是還有復雜一點的請求,我們需要先發OPTIONS請求,a.com想請求b.com它需要發一個自定義的Headers:X-ABC和content-type,這個時候就不是簡單請求了, [a.com要給b.com](http://a.xn--comb-295k414c.com) 發一個options請求,它其實在問b.com我用post行不行,還想在Headers中帶X-ABC和content-type;并不是所有的headers都發這個OPTIONS請求,因為X-ABC是自定義的,所以需要發;b.com看到OPTIONS請求,先不會返回數據,先檢查自己的策略,看看能不能支持這次請求,如果支持就返回200。
OPTIONS請求返回以下報文
HTTP/2.0 20 OK
Access-Control-Allow-Origin:[https://a.com](https://a.com)
Access-Control-Allow-Methods:POST,GET,OPTIONS
Access-Control-Allow-Headers:X-ABC,Content-Type
Access-Control-Max-Age:86400 // 告訴瀏覽器這個策略生效時間為一個小時,在一個小時之內發送類似的請求,不用在問服務端了,相當于緩存了
瀏覽器收到了OPTIONS的返回,會在發一次,這一次才是真正的請求數據,這次headers會帶上X-ABC、contentType。
整體的過程cors將請求分為2種,簡單請求和復雜請求,需不需要發送OPTIONS瀏覽器說的算,瀏覽器判斷是簡單請求還是復雜請求,cors是非常廣泛的跨域手段 這里的缺點是OPTIONS請求也是一次請求,消耗帶寬,真正的請求也會延遲。
* 最方便的跨域方案 **proxy代理+ Nginx**
nginx是一款極其強大的web服務器,其優點就是輕量級、啟動快、高并發。
跨域問題的產生是因為瀏覽器的同源政策造成的,但是服務器與服務器之間的數據交換是沒有這個限制。
反向代理就是采用這種方式,建立一個虛擬的代理服務器來接收 internet 上的鏈接請求,然后轉發給內部網絡上的服務器,并將從服務器上得到的結果,返回給 internet 上請求鏈接的客戶端。現在的新項目中nginx幾乎是首選,我們用node或者java開發的服務通常都需要經過nginx的反向代理。
* **window.postMessage()** 利用h5新特性window.postMessage()
跨域傳送門 ? [\# 跨域,不可不知的基礎概念](https://juejin.cn/post/7003232769182547998)
### 粘包問題分析與對策
TCP粘包是指發送方發送的若干包數據到接收方接收時粘成一包,從接收緩沖區看,后一包數據的頭緊接著前一包數據的尾。
**粘包出現原因**
簡單得說,在流傳輸中出現,UDP不會出現粘包,因為它有**消息邊界**
粘包情況有兩種,一種是`粘在一起的包都是完整的數據包`,另一種情況是`粘在一起的包有不完整的包`。
為了**避免粘包**現象,可采取以下幾種措施:
(1)對于發送方引起的粘包現象,用戶可通過編程設置來避免,`TCP提供了強制數據立即傳送的操作指令push`,TCP軟件收到該操作指令后,就立即將本段數據發送出去,而不必等待發送緩沖區滿;
(2)對于接收方引起的粘包,則可通過優化程序設計、精簡接收進程工作量、`提高接收進程優先級等措施`,使其及時接收數據,從而盡量避免出現粘包現象;
(3)由接收方控制,將一包數據按結構字段,人為控制分多次接收,然后合并,通過這種手段來避免粘包。`分包多發`。
以上提到的三種措施,都有其不足之處。
(1)第一種編程設置方法雖然可以避免發送方引起的粘包,但它關閉了優化算法,降低了網絡發送效率,影響應用程序的性能,一般不建議使用。
(2)第二種方法只能減少出現粘包的可能性,但并不能完全避免粘包,當發送頻率較高時,或由于網絡突發可能使某個時間段數據包到達接收方較快,接收方還是有可能來不及接收,從而導致粘包。
(3)第三種方法雖然避免了粘包,但應用程序的效率較低,對實時應用的場合不適合。
> 一種比較周全的對策是:接收方創建一預處理線程,對接收到的數據包進行預處理,將粘連的包分開。實驗證明這種方法是高效可行的。
### 客戶端與服務端長連接的幾種方式
1. **ajax 輪詢**
**實現原理**:ajax 輪詢指客戶端每間隔一段時間向服務端發起請求,保持數據的同步。
**優點**:可實現基礎(指間隔時間較短)的數據更新。
**缺點**:這種方法也只是盡量的模擬即時傳輸,但并非真正意義上的即時通訊,很有可能出現客戶端請求時,服務端數據并未更新。或者服務端數據已更新,但客戶端未發起請求。導致多次請求資源浪費,效率低下。【`數據更新不及時,效率低下`】
2. **long poll 長輪詢**
**實現原理**:
long poll 指的是客戶端發送請求之后,如果沒有數據返回,服務端會將請求掛起放入隊列(不斷開連接)處理其他請求,直到有數據返回給客戶端。然后客戶端再次發起請求,以此輪詢。在 HTTP1.0 中客戶端可以設置請求頭 Connection:keep-alive,服務端收到該請求頭之后知道這是一個長連接,在響應報文頭中也添加 Connection:keep-alive。客戶端收到之后表示長連接建立完成,可以繼續發送其他的請求。在 HTTP1.1 中默認使用了 Connection:keep-alive 長連接。
**優點**:減少客戶端的請求,降低無效的網絡傳輸,保證每次請求都有數據返回,不會一直占用線程。
**缺點**:無法處理高并發,當客戶端請求量大,請求頻繁時對服務器的處理能力要求較高。服務器一直保持連接會消耗資源,需要同時維護多個線程,服務器所能承載的 TCP 連接數是有上限的,這種輪詢很容易把連接數頂滿。每次通訊都需要客戶端發起,服務端不能主動推送。【`無法處理高并發,消耗服務器資源嚴重,服務端不能主動推送`】
3. **iframe 長連接**
**實現原理:**在網頁上嵌入一個 iframe 標簽,該標簽的 src 屬性指向一個長連接請求。這樣服務端就可以源源不斷地給客戶端傳輸信息。保障信息實時更新。
**優點**:消息及時傳輸。
**缺點**:`消耗服務器資源`。
4. **WebSocket**
**實現原理**:
Websocket 實現了客戶端與服務端的雙向通信,只需要連接一次,就可以相互傳輸數據,很適合實時通訊、數據實時更新等場景。
Websocket 協議與 HTTP 協議沒有關系,它是一個建立在 TCP 協議上的全新協議,為了兼容 HTTP 握手規范,在握手階段依然使用 HTTP 協議,握手完成之后,數據通過 TCP 通道進行傳輸。
Websoket 數據傳輸是通過 frame 形式,一個消息可以分成幾個片段傳輸。這樣大數據可以分成一些小片段進行傳輸,不用考慮由于數據量大導致標志位不夠的情況。也可以邊生成數據邊傳遞消息,提高傳輸效率。
**優點**:
雙向通信。客戶端和服務端雙方都可以主動發起通訊。
沒有同源限制。客戶端可以與任意服務端通信,不存在跨域問題。
數據量輕。第一次連接時需要攜帶請求頭,后面數據通信都不需要帶請求頭,減少了請求頭的負荷。
傳輸效率高。因為只需要一次連接,所以數據傳輸效率高。
**缺點**:
長連接需要后端處理業務的代碼更穩定,推送消息相對復雜;長連接受網絡限制比較大,需要處理好重連。兼容性,WebSocket 只支持 IE10 及其以上版本。服務器長期維護長連接需要一定的成本,各個瀏覽器支持程度不一;成熟的 HTTP 生態下有大量的組件可以復用,WebSocket 則沒有,遇到異常問題難以快速定位快速解決。【需要后端代碼穩定,受網絡限制大,兼容性差,維護成本高,生態圈小】
### 利用Socket建立網絡連接的步驟
建立Socket連接至少需要一對套接字,其中一個運行于客戶端,稱為ClientSocket?,另一個運行于服務器端,稱為ServerSocket?。
套接字之間的連接過程分為三個步驟:服務器監聽,客戶端請求,連接確認。
1、服務器監聽:服務器端套接字并不定位具體的客戶端套接字,而是處于等待連接的狀態,實時監控網絡狀態,等待客戶端的連接請求。
2、客戶端請求:指客戶端的套接字提出連接請求,要連接的目標是服務器端的套接字。
為此,客戶端的套接字必須首先描述它要連接的服務器的套接字,指出服務器端套接字的地址和端口號,然后就向服務器端套接字提出連接請求。
3、連接確認:當服務器端套接字監聽到或者說接收到客戶端套接字的連接請求時,就響應客戶端套接字的請求,建立一個新的線程,把服務器端套接字的描述發給客戶端,一旦客戶端確認了此描述,雙方就正式建立連接。
而服務器端套接字繼續處于監聽狀態,繼續接收其他客戶端套接字的連接請求。
### 非對稱加密RSA
簡介:
1. 對稱加密算法又稱現代加密算法。
2. 非對稱加密是計算機通信安全的基石,保證了加密數據不會被破解。
3. 非對稱加密算法需要兩個密鑰:公開密鑰(publickey) 和私有密(privatekey)
4. 公開密鑰和私有密鑰是一對
如果用公開密鑰對數據進行加密,只有用對應的私有密鑰才能解密。?
如果用私有密鑰對數據進行加密,只有用對應的公開密鑰才能解密。
特點:?
算法強度復雜,安全性依賴于算法與密鑰。?
加密解密速度慢。
與對稱加密算法的對比:?
對稱加密只有一種密鑰,并且是非公開的,如果要解密就得讓對方知道密鑰。?
非對稱加密有兩種密鑰,其中一個是公開的。
RSA應用場景:?
由于RSA算法的加密解密速度要比對稱算法速度慢很多,在實際應用中,通常采取?
數據本身的加密和解密使用對稱加密算法(AES)。?用RSA算法加密并傳輸對稱算法所需的密鑰。
### HTTP1、HTTP2、HTTP3
HTTP/2 相比于 HTTP/1.1,可以說是大幅度提高了網頁的性能,只需要升級到該協議就可以減少很多之前需要做的性能優化工作,雖如此但HTTP/2并非完美的,HTTP/3 就是為了解決 HTTP/2 所存在的一些問題而被推出來的。
### **HTTP1.1 的缺陷**
1. 高延遲 — 隊頭阻塞(Head-Of-Line Blocking)
`隊頭阻塞`是指當順序發送的請求序列中的一個請求因為某種原因被阻塞時,在后面排隊的所有請求也一并被阻塞,會導致客戶端遲遲收不到數據。
針對隊頭阻塞的解決辦法:
* `將同一頁面的資源分散到不同域名下,提升連接上限`。
* `合并小文件減少資源數`,使用精靈圖。
* `內聯(Inlining)資源`是另外一種防止發送很多小圖請求的技巧,將圖片的原始數據嵌入在CSS文件里面的URL里,減少網絡請求次數。
* `減少請求數量`,合并文件。
2. 無狀態特性 — 阻礙交互
`無狀態是指協議對于連接狀態沒有記憶能力`。純凈的 HTTP 是沒有 cookie 等機制的,每一個連接都是一個新的連接。
`Header里攜帶的內容過大,在一定程度上增加了傳輸的成本`。且請求響應報文里有大量字段值都是重復的。
3. 明文傳輸 — 不安全性
HTTP/1.1在傳輸數據時,所有`傳輸的內容都是明文`,客戶端和服務器端都無法驗證對方的身份,無法保證數據的安全性。
4. 不支持服務端推送
> 記憶口訣:隊頭阻塞高延遲,無狀態阻交互,明文傳輸不安全,服務推送不支持。
**HTTP 1.1 排隊問題**
HTTP 1.1多個文件共用一個TCP,這樣可以減少tcp握手,這樣3個文件就不用握手9次了,不過這樣請求文件需要排隊,請求和返回都需要排隊, 如果第一個文件響應慢,會阻塞后面的文件,這樣就產生了對頭的等待問題。
有的網站可能會有很多文件,瀏覽器處于對機器性能的考慮,它不可能讓你無限制的發請求建連接,因為建立連接需要占用資源,瀏覽器不想把用戶的網絡資源都占用了,所以瀏覽器最多會建立6個tcp連接;如果有上百個文件可能都需要排隊,http2.0正在解決這個問題。
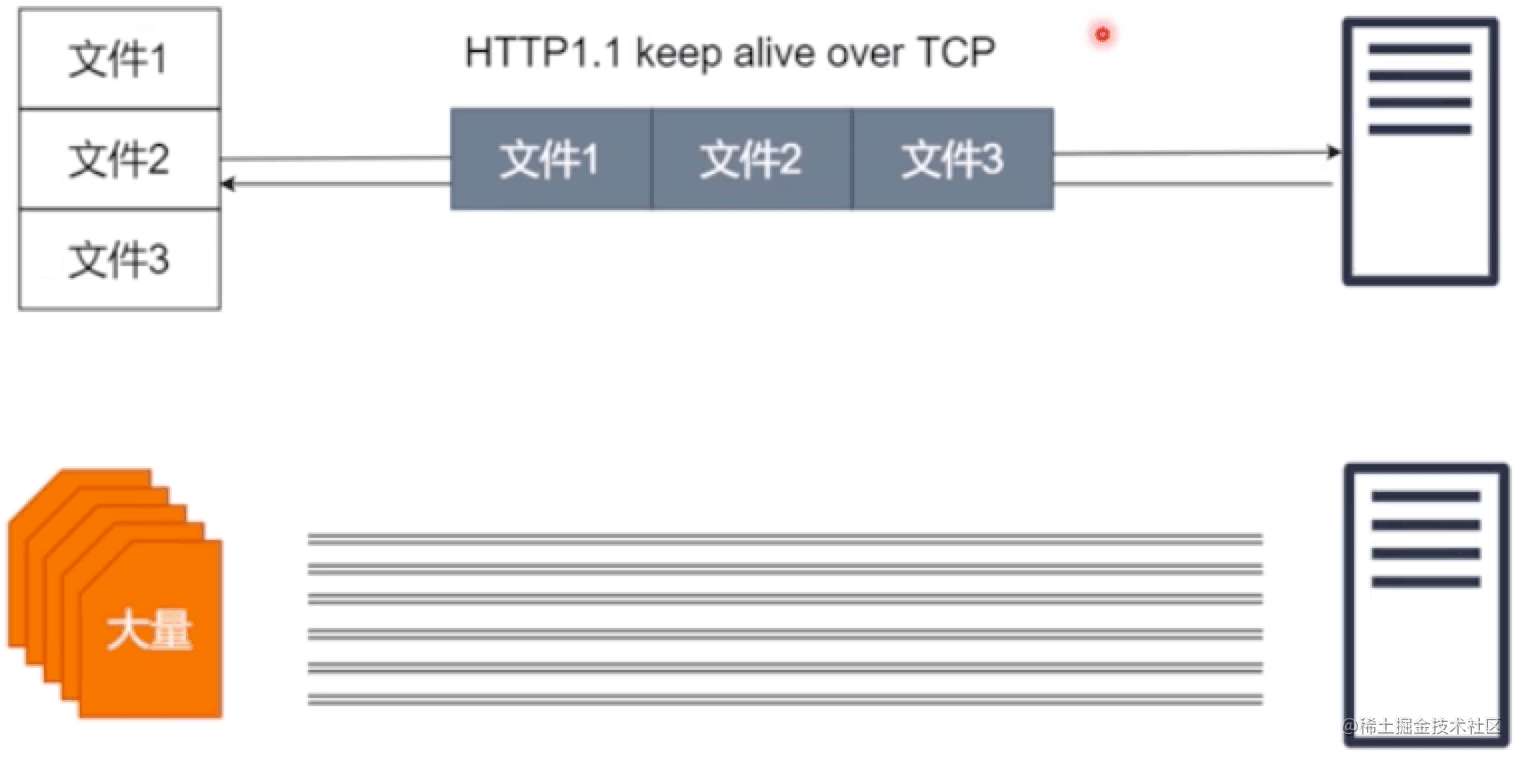
### SPDY 協議與 HTTP/2 簡介
#### 1、HTTP/2 簡介
HTTP/2是現行HTTP協議(HTTP/1.x)的替代,但它不是重寫。**HTTP/2基于SPDY,專注于性能,最大的一個目標是在用戶和網站間只用一個連接(connection)** 。
#### 2、HTTP/2 新特性
#### 1、二進制傳輸
`HTTP/2傳輸數據量的大幅減少,主要有兩個原因:以二進制方式傳輸和Header 壓縮`。我們先來介紹二進制傳輸,HTTP/2 采用二進制格式傳輸數據,而非HTTP/1.x 里純文本形式的報文 ,二進制協議解析起來更高效。`HTTP/2 將請求和響應數據分割為更小的幀,并且它們采用二進制編碼`。
#### 2、Header 壓縮
HTTP/2并沒有使用傳統的壓縮算法,而是開發了專門的"HPACK”算法,在客戶端和服務器兩端建立“字典”,用索引號表示重復的字符串,還采用哈夫曼編碼來壓縮整數和字符串,可以達到50%~90%的高壓縮率。
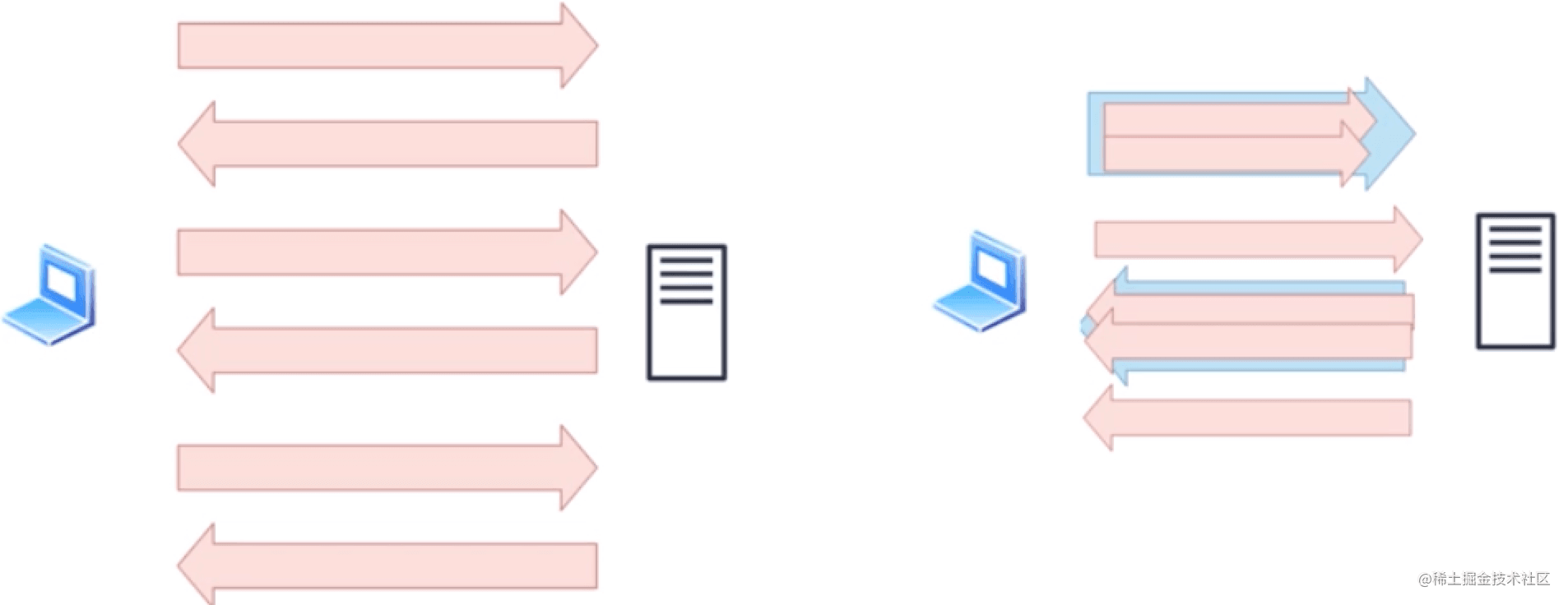
#### 3、多路復用
在 HTTP/2 中引入了多路復用的技術。多路復用很好的解決了瀏覽器限制同一個域名下的請求數量的問題,同時也更容易實現全速傳輸。
#### 4、Server Push
HTTP2還在一定程度上改變了傳統的“請求-應答”工作模式,服務器不再是完全被動地響應請求,也可以新建“流”主動向客戶端發送消息。減少等待的延遲,這被稱為"`服務器推送`"( Server Push,也叫 Cache push)
#### 5、提高安全性
出于兼容的考慮,HTTP/2延續了HTTP/1的“明文”特點,可以像以前一樣使用明文傳輸數據,不強制使用加密通信,不過格式還是二進制,只是不需要解密。
但由于HTTPS已經是大勢所趨,而且主流的瀏覽器Chrome、Firefox等都公開宣布只支持加密的HTTP/2,**所以“事實上”的HTTP/2是加密的**。也就是說,互聯網上通常所能見到的HTTP/2都是使用"https”協議名,跑在TLS上面。HTTP/2協議定義了兩個字符串標識符:“h2"表示加密的HTTP/2,“h2c”表示明文的HTTP/2。
#### 6、防止對頭阻塞
http1.1如果第一個文件阻塞,第二個文件也就阻塞了。

http2.0的解決,把3個請求打包成一個小塊發送過去,即使第一個阻塞了,后面2個也可以回來;相當于3個文件同時請求,就看誰先回來誰后回來,阻塞的可能就后回來,對帶寬的利用是最高的;但沒有解決TCP的對頭阻塞,如果TCP發過去的一個分包發丟了,他會重新發一次;http2.0的解決了大文件的阻塞。
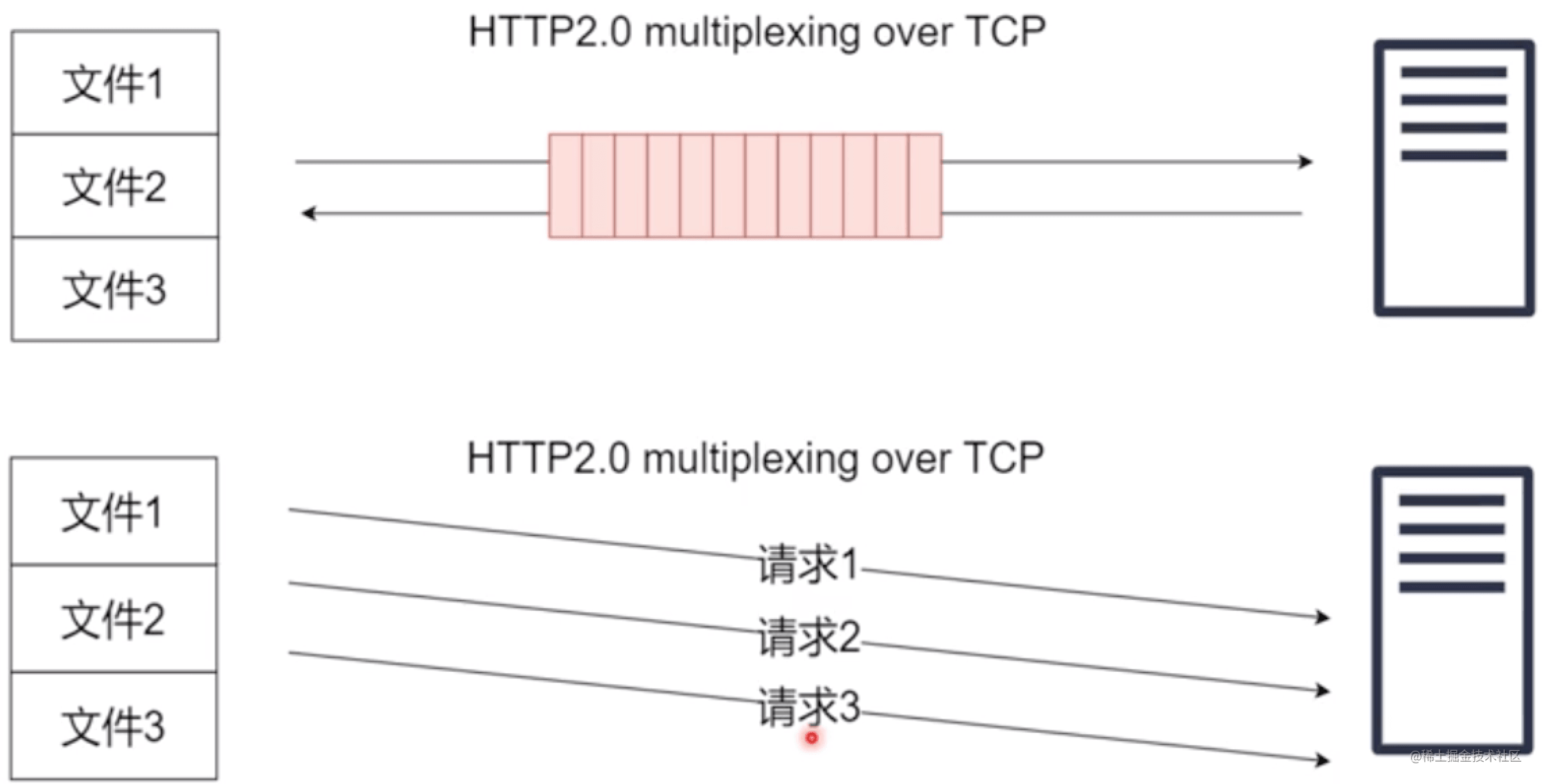
一個分包請求3個文件,即使第一個阻塞了,第二個也能返回
### HTTP/2 的缺點
雖然 HTTP/2 解決了很多之前舊版本的問題,但它還是存在一個巨大的問題,**主要是底層支撐的 TCP 協議造成的**。HTTP/2的缺點主要有以下幾點:
1. TCP 以及 TCP+TLS 建立連接時延時
2. TCP 的隊頭阻塞并沒有徹底解決
3. 多路復用導致服務器壓力上升也容易 Timeout
### HTTP/3 新特性
#### 1、HTTP/3簡介
Google 在推SPDY的時候就搞了個基于 UDP 協議的“QUIC”協議,讓HTTP跑在QUIC上而不是TCP上。而“HTTP over QUIC”就是HTTP/3,真正“完美”地解決了“隊頭阻塞”問題。
QUIC 雖然基于 UDP,但是在原本的基礎上新增了很多功能,接下來我們重點介紹幾個QUIC新功能。
#### 2、QUIC新功能
QUIC基于UDP,而UDP是“無連接”的,根本就不需要“握手”和“揮手”,所以就比TCP來得快。此外QUIC也實現了可靠傳輸,保證數據一定能夠抵達目的地。它還引入了類似HTTP/2的“流”和“多路復用”,單個“流"是有序的,可能會因為丟包而阻塞,但其他“流”不會受到影響。具體來說QUIC協議有以下特點:
* **實現了類似TCP的流量控制、傳輸可靠性的功能**
雖然UDP不提供可靠性的傳輸,但QUIC在UDP的基礎之上增加了一層來保證數據可靠性傳輸。它提供了數據包重傳、擁塞控制以及其他一些TCP中存在的特性。
* **實現了快速握手功能**
由于QUIC是基于UDP的,所以QUIC可以實現使用0-RTT或者1-RTT來建立連接,這意味著QUIC可以用最快的速度來發送和接收數據,這樣可以大大提升首次打開頁面的速度。**0RTT 建連可以說是 QUIC 相比 HTTP2 最大的性能優勢**。
* **集成了TLS加密功能**
* **多路復用,徹底解決TCP中隊頭阻塞的問題**
和TCP不同,QUIC實現了在同一物理連接上可以有多個獨立的邏輯數據流。實現了數據流的單獨傳輸,就解決了TCP中隊頭阻塞的問題。
* **連接遷移**
TCP 是按照 4 要素(客戶端 IP、端口, 服務器 IP、端口)確定一個連接的。而 QUIC 則是讓客戶端生成一個 Connection ID (64 位)來區別不同連接。只要 Connection ID 不變,連接就不需要重新建立,即便是客戶端的網絡發生變化。由于遷移客戶端繼續使用相同的會話密鑰來加密和解密數據包,QUIC 還提供了遷移客戶端的自動加密驗證。
### 總結
* HTTP/1.1有兩個主要的缺點:安全不足和性能不高。
* HTTP/2完全兼容HTTP/1,是“更安全的HTTP、更快的HTTPS",二進制傳輸、頭部壓縮、多路復用、服務器推送等技術可以充分利用帶寬,降低延遲,從而大幅度提高上網體驗;
* QUIC 基于 UDP 實現,是 HTTP/3 中的底層支撐協議,該協議基于 UDP,又取了 TCP 中的精華,實現了即快又可靠的協議。
### 理解xss,csrf,ddos攻擊原理以及避免方式
`XSS`(`Cross-Site Scripting`,**跨站腳本攻擊**)是一種代碼注入攻擊。攻擊者在目標網站上注入惡意代碼,當被攻擊者登陸網站時就會執行這些惡意代碼,這些腳本可以讀取 `cookie,session tokens`,或者其它敏感的網站信息,對用戶進行釣魚欺詐,甚至發起蠕蟲攻擊等。
`CSRF`(`Cross-site request forgery`)**跨站請求偽造**:攻擊者誘導受害者進入第三方網站,在第三方網站中,向被攻擊網站發送跨站請求。利用受害者在被攻擊網站已經獲取的注冊憑證,繞過后臺的用戶驗證,達到冒充用戶對被攻擊的網站執行某項操作的目的。
**XSS避免方式:**
1. `url`參數使用`encodeURIComponent`方法轉義
2. 盡量不是有`InnerHtml`插入`HTML`內容
3. 使用特殊符號、標簽轉義符。
`CSRF`避免方式:
1. 添加驗證碼
2. 使用token
* 服務端給用戶生成一個token,加密后傳遞給用戶
* 用戶在提交請求時,需要攜帶這個token
* 服務端驗證token是否正確
`DDoS`又叫分布式拒絕服務,全稱 `Distributed Denial of Service`,其原理就是利用大量的請求造成資源過載,導致服務不可用。
**`DDos`避免方式:**
1. 限制單IP請求頻率。
2. 防火墻等防護設置禁止`ICMP`包等
3. 檢查特權端口的開放
[360技術:嗨,送你一張Web性能優化地圖](https://mp.weixin.qq.com/s?__biz=MzkzNzI0MDMxNQ==&mid=2247487116&idx=1&sn=09187eeb7e45faa1bee86ff48ae14be1&source=41#wechat_redirect)
- JavaScript
- 1. DOM事件流
- 2. 模擬 new, Object create(), bind
- 5. 封裝函數進行字符串駝峰命名的轉換
- 6. 什么是promise
- 7. 判斷一個數是否為數組
- 10. __proto__和prototype以及原型,原型鏈,構造函數
- 11. 繼承
- 12. 閉包
- 13. 回調函數
- 14. var 和 let 區別
- 15. this、bind、call、apply
- 16.undefined和null的區別
- 17.內存泄漏
- 18.垃圾回收機制
- html css
- 1. 元素垂直水平居中
- 2. 清除浮動
- 3. bootstrap柵格系統
- 4. px rpx em rem vw 的區別
- 5. 兩種盒子模型
- 6. 合集
- web類
- 1. html5的新特性以及理解(web標簽語義化)
- 2. 什么是路由,關于前端路由和后端路由
- 3. 對優質代碼的理解
- 4. cookie 和 sessionStorage和localStorage
- 5. 瀏覽器內核
- 6. http 狀態碼
- 7. href 和 src 的區別
- 8. link 和 @import 的區別
- 9. http 狀態碼
- 10. websocket
- 11. 瀏覽器解析url
- 12.http緩存
- vue
- 1.vue2和vue3有哪些區別
- 1. 對 mvvvm 的理解
- 2. mvvm的優缺點
- 3. 數據雙向綁定的原理
- 4. 生命周期
- 5. 組件如何通信
- 6. computed和watch的區別
- 7. proxy 和 Object.defineProperty
- 8. 虛擬dom和 diff算法
- 9. 路由的嵌套與傳參
- 10. 路由導航鉤子
- 11. axios 的理解
- 12. vue自定義指令 diretive
- 13. diff 的實現
- 14. 實現一個簡單的雙向綁定
- 15. 為什么 data 是一個函數
- 題譜
- js
- 手寫篇
- css
- vue
- react
- 算法
- 自我介紹
- 八股文
- 源項目地址
- 1.計算機網絡
- 2.瀏覽器
- 3.html和css
- 4.javascript
- 6.typescript
- 7.vue
- 8.react
- 大廠面試
- 面試題大全
- 常見性能優化
- 面試實戰
- 面試分析
- 押題
- 1.微前端在項目中的實際應用
- 2.性能優化
- vue相關
- 1.說一說HashRouter和HistoryRouter的區別和原理
- 無敵之路,牛客網面試題自測記錄
- 前端基礎
- 1.html
- 2.js基礎
- 珠峰性能優化
- WebWorker
- url到渲染
- 瀏覽器加載機制
- 自我介紹1
- 手寫題
- 1.compose
- 2.setTimeout模擬setInterval
- 3.手寫數組拍平
- 4.手寫promise.all
- 5.手寫深拷貝
- webpack
- 實戰