
[toc]
# 瀏覽器
### 從輸入URL到頁面加載的全過程
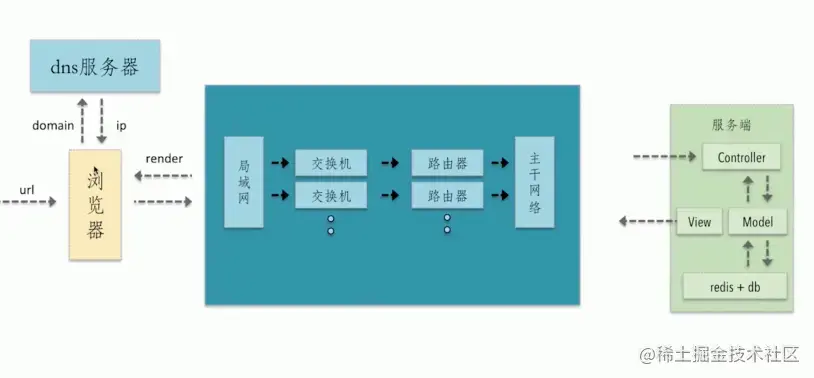
1. 首先在瀏覽器中輸入URL
1. 查找緩存:瀏覽器先查看瀏覽器緩存-系統緩存-路由緩存中是否有該地址頁面,如果有則顯示頁面內容。如果沒有則進行下一步。
- 瀏覽器緩存:瀏覽器會記錄DNS一段時間,因此,只是第一個地方解析DNS請求;
- 操作系統緩存:如果在瀏覽器緩存中不包含這個記錄,則會使系統調用操作系統, 獲取操作系統的記錄(保存最近的DNS查詢緩存);
- 路由器緩存:如果上述兩個步驟均不能成功獲取DNS記錄,繼續搜索路由器緩存;
- ISP緩存:若上述均失敗,繼續向ISP搜索。
1. DNS域名解析:瀏覽器向DNS服務器發起請求,解析該URL中的域名對應的IP地址。`DNS服務器是基于UDP的,因此會用到UDP協議`。
1. 建立TCP連接:解析出IP地址后,根據IP地址和默認80端口,和服務器建立TCP連接
1. 發起HTTP請求:瀏覽器發起讀取文件的HTTP請求,,該請求報文作為TCP三次握手的第三次數據發送給服務器
1. 服務器響應請求并返回結果:服務器對瀏覽器請求做出響應,并把對應的html文件發送給瀏覽器
1. 關閉TCP連接:通過四次揮手釋放TCP連接
1. 瀏覽器渲染:客戶端(瀏覽器)解析HTML內容并渲染出來,瀏覽器接收到數據包后的解析流程為:
- 構建DOM樹:詞法分析然后解析成DOM樹(dom tree),是由dom元素及屬性節點組成,樹的根是document對象
- 構建CSS規則樹:生成CSS規則樹(CSS Rule Tree)
- 構建render樹:Web瀏覽器將DOM和CSSOM結合,并構建出渲染樹(render tree)
- 布局(Layout):計算出每個節點在屏幕中的位置
- 繪制(Painting):即遍歷render樹,并使用UI后端層繪制每個節點。
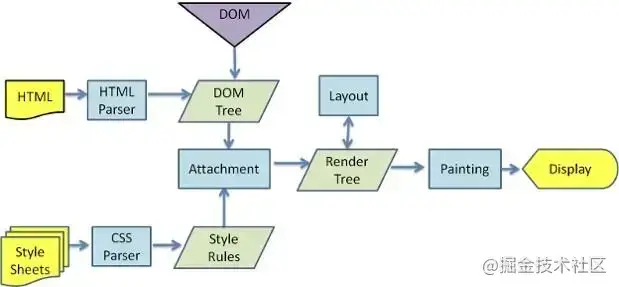
1. JS引擎解析過程:調用JS引擎執行JS代碼(JS的解釋階段,預處理階段,執行階段生成執行上下文,VO,作用域鏈、回收機制等等)
- 創建window對象:window對象也叫全局執行環境,當頁面產生時就被創建,所有的全局變量和函數都屬于window的屬性和方法,而DOM Tree也會映射在window的doucment對象上。當關閉網頁或者關閉瀏覽器時,全局執行環境會被銷毀。
- 加載文件:完成js引擎分析它的語法與詞法是否合法,如果合法進入預編譯
- 預編譯:在預編譯的過程中,瀏覽器會尋找全局變量聲明,把它作為window的屬性加入到window對象中,并給變量賦值為'undefined';尋找全局函數聲明,把它作為window的方法加入到window對象中,并將函數體賦值給他(匿名函數是不參與預編譯的,因為它是變量)。而變量提升作為不合理的地方在ES6中已經解決了,函數提升還存在。
- 解釋執行:執行到變量就賦值,如果變量沒有被定義,也就沒有被預編譯直接賦值,在ES5非嚴格模式下這個變量會成為window的一個屬性,也就是成為全局變量。string、int這樣的值就是直接把值放在變量的存儲空間里,object對象就是把指針指向變量的存儲空間。函數執行,就將函數的環境推入一個環境的棧中,執行完成后再彈出,控制權交還給之前的環境。JS作用域其實就是這樣的執行流機制實現的。
傳送門 ? [# DNS域名解析過程](https://juejin.cn/post/7005468491067162655) ?[# 瀏覽器的工作原理](https://juejin.cn/post/6992597760935460901)
### 在瀏覽器中輸入URL到顯示頁面經歷哪些過程,涉及到哪些協議?
瀏覽器要將URL解析為IP地址,解析域名就要用到DNS協議,首先主機會查詢DNS的緩存,如果沒有就給本地DNS發送查詢請求。DNS查詢分為兩種方式,一種是遞歸查詢,一種是迭代查詢。如果是迭代查詢,本地的DNS服務器,向根域名服務器發送查詢請求,根域名服務器告知該域名的一級域名服務器,然后本地服務器給該一級域名服務器發送查詢請求,然后依次類推直到查詢到該域名的IP地址。`DNS服務器是基于UDP的,因此會用到UDP協議。`
得到IP地址后,瀏覽器就要與服務器建立一個http連接。因此要用到http協議。http生成一個get請求報文,將該報文傳給TCP層處理,所以還會用到TCP協議。如果采用https還會使用https協議先對http數據進行加密。TCP層如果有需要先將HTTP數據包分片,分片依據路徑MTU和MSS。TCP的數據包然后會發送給IP層,用到IP協議。IP層通過路由選路,一跳一跳發送到目的地址。當然在一個網段內的尋址是通過以太網協議實現(也可以是其他物理層協議,比如PPP,SLIP),以太網協議需要直到目的IP地址的物理地址,有需要ARP協議。
其中:
1、`DNS協議,http協議,https協議屬于應用層`
應用層是體系結構中的最高層。應用層確定進程之間通信的性質以滿足用戶的需要。這里的進程就是指正在運行的程序。應用層不僅要提供應用進程所需要的信息交換和遠地操作,而且還要作為互相作用的應用進程的用戶代理,來完成一些為進行語義上有意義的信息交換所必須的功能。應用層直接為用戶的應用進程提供服務。
2、`TCP/UDP屬于傳輸層`
傳輸層的任務就是負責主機中兩個進程之間的通信。因特網的傳輸層可使用兩種不同協議:即面向連接的傳輸控制協議TCP,和無連接的用戶數據報協議UDP。面向連接的服務能夠提供可靠的交付,但無連接服務則不保證提供可靠的交付,它只是“盡最大努力交付”。這兩種服務方式都很有用,備有其優缺點。在分組交換網內的各個交換結點機都沒有傳輸層。
3、`IP協議,ARP協議屬于網絡層`
網絡層負責為分組交換網上的不同主機提供通信。在發送數據時,網絡層將運輸層產生的報文段或用戶數據報封裝成分組或包進行傳送。在TCP/IP體系中,分組也叫作IP數據報,或簡稱為數據報。網絡層的另一個任務就是要選擇合適的路由,使源主機運輸層所傳下來的分組能夠交付到目的主機。
4、數據鏈路層
當發送數據時,數據鏈路層的任務是將在網絡層交下來的IP數據報組裝成幀,在兩個相鄰結點間的鏈路上傳送以幀為單位的數據。每一幀包括數據和必要的控制信息(如同步信息、地址信息、差錯控制、以及流量控制信息等)。控制信息使接收端能夠知道—個幀從哪個比特開始和到哪個比特結束。控制信息還使接收端能夠檢測到所收到的幀中有無差錯。
5、物理層
物理層的任務就是透明地傳送比特流。在物理層上所傳數據的單位是比特。傳遞信息所利用的一些物理媒體,如雙絞線、同軸電纜、光纜等,并不在物理層之內而是在物理層的下面。因此也有人把物理媒體當做第0層。
### 瀏覽器的主要功能
瀏覽器的主要功能就是向服務器發出請求,在瀏覽器窗口中展示您選擇的網絡資源。這里所說的資源一般是指 HTML 文檔,也可以是 PDF、圖片或其他的類型。資源的位置由用戶使用 URI(統一資源標示符)指定。
### 瀏覽器的工作原理
渲染引擎一開始會從網絡層獲取請求文檔的內容,內容的大小一般限制在 8000 個塊以內。
然后進行如下所示的基本流程:

圖:渲染引擎的基本流程。
渲染引擎將開始`解析 HTML 文檔`,并將各標記逐個轉化成“內容樹”上的?[DOM](https://link.juejin.cn?target=https%3A%2F%2Fwww.html5rocks.com%2Fzh%2Ftutorials%2Finternals%2Fhowbrowserswork%2F%23DOM "https://www.html5rocks.com/zh/tutorials/internals/howbrowserswork/#DOM")?節點。同時也會`解析外部 CSS 文件以及樣式元素中的樣式數據`。HTML 中這些帶有視覺指令的樣式信息將用于創建另一個樹結構:[`渲染樹`](https://link.juejin.cn?target=https%3A%2F%2Fwww.html5rocks.com%2Fzh%2Ftutorials%2Finternals%2Fhowbrowserswork%2F%23Render_tree_construction "https://www.html5rocks.com/zh/tutorials/internals/howbrowserswork/#Render_tree_construction")。
渲染樹包含多個帶有視覺屬性(如顏色和尺寸)的矩形。這些矩形的排列順序就是它們將在屏幕上顯示的順序。
渲染樹構建完畢之后,進入“[布局](https://link.juejin.cn?target=https%3A%2F%2Fwww.html5rocks.com%2Fzh%2Ftutorials%2Finternals%2Fhowbrowserswork%2F%23layout "https://www.html5rocks.com/zh/tutorials/internals/howbrowserswork/#layout")”處理階段,也就是為每個節點分配一個應出現在屏幕上的確切坐標。下一個階段是[繪制](https://link.juejin.cn?target=https%3A%2F%2Fwww.html5rocks.com%2Fzh%2Ftutorials%2Finternals%2Fhowbrowserswork%2F%23Painting "https://www.html5rocks.com/zh/tutorials/internals/howbrowserswork/#Painting")?- 渲染引擎會遍歷渲染樹,由用戶界面后端層將每個節點繪制出來。
需要著重指出的是,這是一個漸進的過程。為達到更好的用戶體驗,渲染引擎會力求盡快將內容顯示在屏幕上。它不必等到整個 HTML 文檔解析完畢之后,就會開始構建呈現樹和設置布局。在不斷接收和處理來自網絡的其余內容的同時,渲染引擎會將部分內容解析并顯示出來。
### 瀏覽器的主要組成部分是什么?
1. **用戶界面**?- 包括地址欄、前進/后退按鈕、書簽菜單等。除了瀏覽器主窗口顯示的您請求的頁面外,其他顯示的各個部分都屬于用戶界面。
1. **瀏覽器引擎**?- 在用戶界面和呈現引擎之間傳送指令。
1. **呈現引擎**?- 負責顯示請求的內容。如果請求的內容是 HTML,它就負責解析 HTML 和 CSS 內容,并將解析后的內容顯示在屏幕上。
1. **網絡**?- 用于網絡調用,比如 HTTP 請求。其接口與平臺無關,并為所有平臺提供底層實現。
1. **用戶界面后端**?- 用于繪制基本的窗口小部件,比如組合框和窗口。其公開了與平臺無關的通用接口,而在底層使用操作系統的用戶界面方法。
1. **JavaScript 解釋器**。用于解析和執行 JavaScript 代碼。
1. **數據存儲**。這是持久層。瀏覽器需要在硬盤上保存各種數據,例如 Cookie。新的 HTML 規范 (HTML5) 定義了“網絡數據庫”,這是一個完整(但是輕便)的瀏覽器內數據庫。
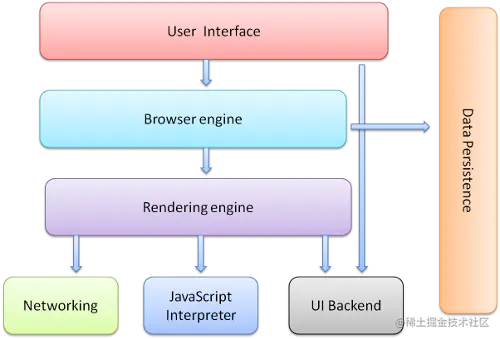
圖:瀏覽器的主要組件。
值得注意的是,和大多數瀏覽器不同,Chrome 瀏覽器的每個標簽頁都分別對應一個呈現引擎實例。每個標簽頁都是一個獨立的進程。
### 瀏覽器是如何渲染UI的?
1. 瀏覽器獲取HTML文件,然后對文件進行解析,形成DOM Tree
1. 與此同時,進行CSS解析,生成Style Rules
1. 接著將DOM Tree與Style Rules合成為 Render Tree
1. 接著進入布局(Layout)階段,也就是為每個節點分配一個應出現在屏幕上的確切坐標
1. 隨后調用GPU進行繪制(Paint),遍歷Render Tree的節點,并將元素呈現出來
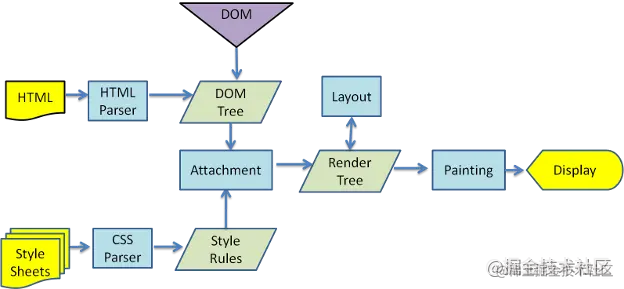
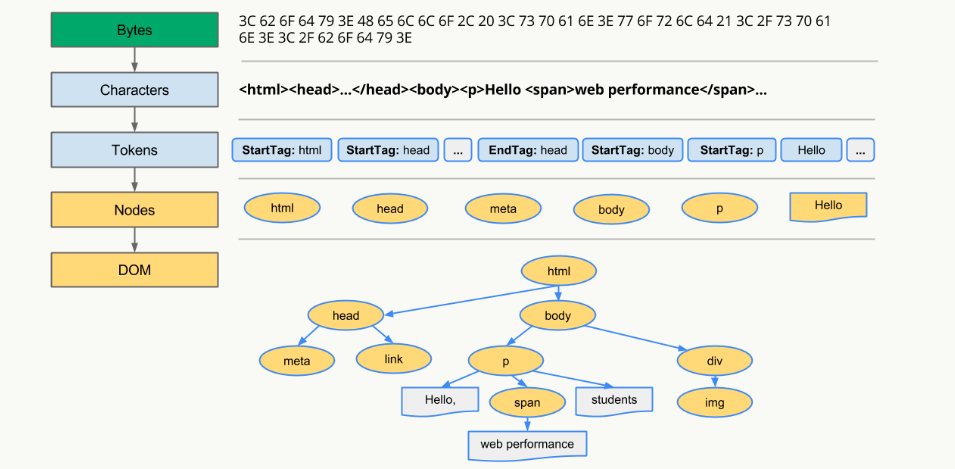
### DOM Tree是如何構建的?
1. 轉碼: 瀏覽器將接收到的二進制數據按照指定編碼格式轉化為HTML字符串
1. 生成Tokens: 之后開始parser,瀏覽器會將HTML字符串解析成Tokens
1. 構建Nodes: 對Node添加特定的屬性,通過指針確定 Node 的父、子、兄弟關系和所屬 treeScope
1. 生成DOM Tree: 通過node包含的指針確定的關系構建出DOM\
Tree
### 瀏覽器重繪與重排的區別?
- `重排/回流(Reflow)`:當`DOM`的變化影響了元素的幾何信息,瀏覽器需要重新計算元素的幾何屬性,將其安放在界面中的正確位置,這個過程叫做重排。表現為重新生成布局,重新排列元素。
- `重繪(Repaint)`: 當一個元素的外觀發生改變,但沒有改變布局,重新把元素外觀繪制出來的過程,叫做重繪。表現為某些元素的外觀被改變
單單改變元素的外觀,肯定不會引起網頁重新生成布局,但當瀏覽器完成重排之后,將會重新繪制受到此次重排影響的部分
重排和重繪代價是高昂的,它們會破壞用戶體驗,并且讓UI展示非常遲緩,而相比之下重排的性能影響更大,在兩者無法避免的情況下,一般我們寧可選擇代價更小的重繪。
『重繪』不一定會出現『重排』,『重排』必然會出現『重繪』。
### 如何觸發重排和重繪?
任何改變用來構建渲染樹的信息都會導致一次重排或重繪:
- 添加、刪除、更新DOM節點
- 通過display: none隱藏一個DOM節點-觸發重排和重繪
- 通過visibility: hidden隱藏一個DOM節點-只觸發重繪,因為沒有幾何變化
- 移動或者給頁面中的DOM節點添加動畫
- 添加一個樣式表,調整樣式屬性
- 用戶行為,例如調整窗口大小,改變字號,或者滾動。
### 如何避免重繪或者重排?
1. `集中改變樣式`,不要一條一條地修改 DOM 的樣式。
1. 不要把 DOM 結點的屬性值放在循環里當成循環里的變量。
1. 為動畫的 HTML 元件使用 `fixed` 或 `absoult` 的 `position`,那么修改他們的 CSS 是不會 reflow 的。
1. 不使用 table 布局。因為可能很小的一個小改動會造成整個 table 的重新布局。
1. 盡量只修改`position:absolute`或`fixed`元素,對其他元素影響不大
1. 動畫開始`GPU`加速,`translate`使用`3D`變化
1. 提升為合成層
將元素提升為合成層有以下優點:
- 合成層的位圖,會交由 GPU 合成,比 CPU 處理要快
- 當需要 repaint 時,只需要 repaint 本身,不會影響到其他的層
- 對于 transform 和 opacity 效果,不會觸發 layout 和 paint
提升合成層的最好方式是使用 CSS 的 will-change 屬性:
```
#target {
will-change: transform;
}
```
> 關于合成層的詳解請移步[無線性能優化:Composite](https://link.juejin.cn?target=http%3A%2F%2Ftaobaofed.org%2Fblog%2F2016%2F04%2F25%2Fperformance-composite%2F "http://taobaofed.org/blog/2016/04/25/performance-composite/")
### 介紹下304過程
- a. 瀏覽器請求資源時首先命中資源的Expires 和 Cache-Control,Expires 受限于本地時間,如果修改了本地時間,可能會造成緩存失效,可以通過Cache-control: max-age指定最大生命周期,狀態仍然返回200,但不會請求數據,在瀏覽器中能明顯看到from cache字樣。
- b. 強緩存失效,進入協商緩存階段,首先驗證ETagETag可以保證每一個資源是唯一的,資源變化都會導致ETag變化。服務器根據客戶端上送的If-None-Match值來判斷是否命中緩存。
- c. 協商緩存Last-Modify/If-Modify-Since階段,客戶端第一次請求資源時,服務服返回的header中會加上Last-Modify,Last-modify是一個時間標識該資源的最后修改時間。再次請求該資源時,request的請求頭中會包含If-Modify-Since,該值為緩存之前返回的Last-Modify。服務器收到If-Modify-Since后,根據資源的最后修改時間判斷是否命中緩存。
### 瀏覽器的緩存機制 強制緩存 && 協商緩存
瀏覽器與服務器通信的方式為應答模式,即是:瀏覽器發起HTTP請求 – 服務器響應該請求。那么瀏覽器第一次向服務器發起該請求后拿到請求結果,會根據響應報文中HTTP頭的緩存標識,決定是否緩存結果,是則將請求結果和緩存標識存入瀏覽器緩存中,簡單的過程如下圖:
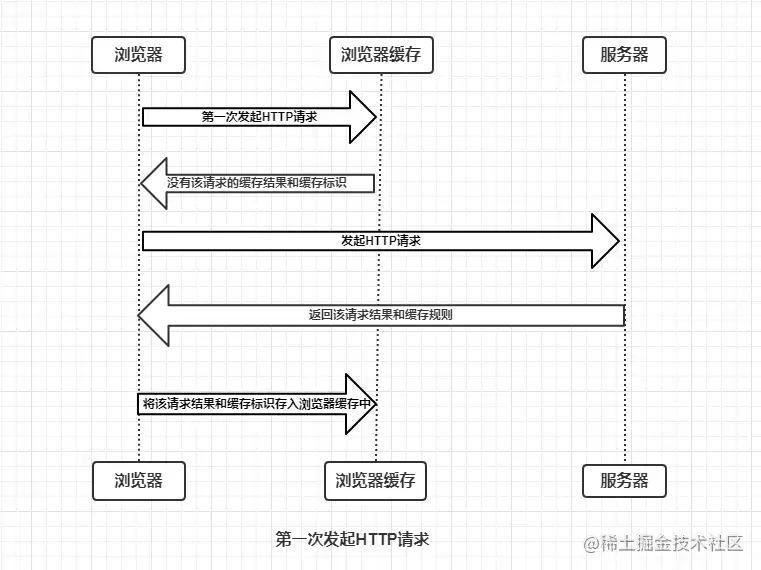
由上圖我們可以知道:
- 瀏覽器每次發起請求,都會`先在瀏覽器緩存中查找該請求的結果以及緩存標識`
- 瀏覽器每次拿到返回的請求結果都會`將該結果和緩存標識存入瀏覽器緩存中`
以上兩點結論就是瀏覽器緩存機制的關鍵,他確保了每個請求的緩存存入與讀取,只要我們再理解瀏覽器緩存的使用規則,那么所有的問題就迎刃而解了。為了方便理解,這里根據是否需要向服務器重新發起HTTP請求將緩存過程分為兩個部分,分別是`強制緩存`和`協商緩存`。
- **強制緩存**
`強制緩存就是向瀏覽器緩存查找該請求結果,并根據該結果的緩存規則來決定是否使用該緩存結果的過程。`當瀏覽器向服務器發起請求時,服務器會將緩存規則放入HTTP響應報文的HTTP頭中和請求結果一起返回給瀏覽器,控制強制緩存的字段分別是 `Expires` 和 `Cache-Control`,其中Cache-Control優先級比Expires高。
強制緩存的情況主要有三種(暫不分析協商緩存過程),如下:
1. 不存在該緩存結果和緩存標識,強制緩存失效,則直接向服務器發起請求(跟第一次發起請求一致)。
1. 存在該緩存結果和緩存標識,但該結果已失效,強制緩存失效,則使用協商緩存。
1. 存在該緩存結果和緩存標識,且該結果尚未失效,強制緩存生效,直接返回該結果
- **協商緩存**
`協商緩存就是強制緩存失效后,瀏覽器攜帶緩存標識向服務器發起請求,由服務器根據緩存標識決定是否使用緩存的過程`,同樣,協商緩存的標識也是在響應報文的HTTP頭中和請求結果一起返回給瀏覽器的,控制協商緩存的字段分別有:`Last-Modified / If-Modified-Since` 和 `Etag / If-None-Match`,其中Etag / If-None-Match的優先級比Last-Modified / If-Modified-Since高。協商緩存主要有以下兩種情況:
1. 協商緩存生效,返回304
2. 協商緩存失效,返回200和請求結果結果
傳送門 ? [# 徹底理解瀏覽器的緩存機制](https://juejin.cn/post/6992843117963509791)
### Cookie、sessionStorage、localStorage 的區別
**相同點**:
- 存儲在客戶端
**不同點**:
- cookie數據大小不能超過4k;sessionStorage和localStorage的存儲比cookie大得多,可以達到5M+
- cookie設置的過期時間之前一直有效;localStorage永久存儲,瀏覽器關閉后數據不丟失除非主動刪除數據;sessionStorage數據在當前瀏覽器窗口關閉后自動刪除
- cookie的數據會自動的傳遞到服務器;sessionStorage和localStorage數據保存在本地
### 說下進程、線程和協程
**進程**是一個具有一定獨立功能的程序在一個數據集上的一次動態執行的過程,`是操作系統進行資源分配和調度的一個獨立單位`,是應用程序運行的載體。進程是一種抽象的概念,從來沒有統一的標準定義。
**線程**是程序執行中一個單一的順序控制流程,是`程序執行流的最小單元`,是處理器調度和分派的基本單位。一個進程可以有一個或多個線程,各個線程之間共享程序的內存空間(也就是所在進程的內存空間)。一個標準的線程由線程ID、當前指令指針(PC)、寄存器和堆棧組成。而進程由內存空間(代碼、數據、進程空間、打開的文件)和一個或多個線程組成。
**協程**,英文Coroutines,是一種`基于線程之上,但又比線程更加輕量級的存在`,這種由程序員自己寫程序來管理的輕量級線程叫做『用戶空間線程』,具有對內核來說不可見的特性。
**進程和線程的區別與聯系**
【區別】:
調度:線程作為調度和分配的基本單位,進程作為擁有資源的基本單位;
并發性:不僅進程之間可以并發執行,同一個進程的多個線程之間也可并發執行;
擁有資源:進程是擁有資源的一個獨立單位,線程不擁有系統資源,但可以訪問隸屬于進程的資源。
系統開銷:在創建或撤消進程時,由于系統都要為之分配和回收資源,導致系統的開銷明顯大于創建或撤消線程時的開銷。但是進程有獨立的地址空間,一個進程崩潰后,在保護模式下不會對其它進程產生影響,而線程只是一個進程中的不同執行路徑。線程有自己的堆棧和局部變量,但線程之間沒有單獨的地址空間,一個進程死掉就等于所有的線程死掉,所以多進程的程序要比多線程的程序健壯,但在進程切換時,耗費資源較大,效率要差一些。
【聯系】:
一個線程只能屬于一個進程,而一個進程可以有多個線程,但至少有一個線程;
資源分配給進程,同一進程的所有線程共享該進程的所有資源;
處理機分給線程,即真正在處理機上運行的是線程;
線程在執行過程中,需要協作同步。不同進程的線程間要利用消息通信的辦法實現同步。
傳送門 ? [# 一文搞懂進程、線程、協程及JS協程的發展](https://juejin.cn/post/7005465381791875109)
[?了解更多](http://www.360doc.com/content/20/0417/14/32196507_906628857.shtml)
關于瀏覽器傳送門 ?[# 深入了解現代 Web 瀏覽器](https://juejin.cn/post/6993095345576083486)
### 進程間的通信方式
`進程通信`:
每個進程各自有不同的用戶地址空間,任何一個進程的全局變量在另一個進程中都看不到,所以進程之間要交換數據必須通過內核,在內核中開辟一塊緩沖區,進程A把數據從用戶空間拷到內核緩沖區,進程B再從內核緩沖區把數據讀走,內核提供的這種機制稱為進程間通信。
進程間的通信方式:管道、有名管道、信號、消息隊列、共享內存、信號量、socket
`匿名管道( pipe )`: 管道是一種半雙工的通信方式,數據只能**單向流動**,而且只能在具有親緣關系的進程間使用。進程的親緣關系通常是指**父子進程關系**。
`高級管道(popen)`:將另一個程序當做一個新的進程在當前程序進程中啟動,則它算是當前程序的子進程,這種方式我們成為高級管道方式。
`有名管道 (named pipe) `: 有名管道也是半雙工的通信方式,但是它允許無親緣關系進程間的通信。
`消息隊列( message queue )` : 消息隊列是由消息的鏈表,存放在內核中并由消息隊列標識符標識。消息隊列克服了信號傳遞信息少、管道只能承載無格式字節流以及緩沖區大小受限等缺點。
`信號量( semophore )` : 信號量是一個計數器,可以用來控制多個進程對共享資源的訪問。它常作為一種鎖機制,防止某進程正在訪問共享資源時,其他進程也訪問該資源。因此,主要作為進程間以及同一進程內不同線程之間的同步手段。
`信號 ( sinal )` : 信號是一種比較復雜的通信方式,用于通知接收進程某個事件已經發生。
`共享內存( shared memory )` :共享內存就是映射一段能被其他進程所訪問的內存,這段共享內存由一個進程創建,但多個進程都可以訪問。共享內存是最快的 IPC 方式,它是針對其他進程間通信方式運行效率低而專門設計的。它往往與其他通信機制,如信號兩,配合使用,來實現進程間的同步和通信。
`套接字( socket ) 通信`: 套接口也是一種進程間通信機制,與其他通信機制不同的是,它可用于不同機器間的進程通信
### 瀏覽器樣式兼容
#### 一、CSS初始化
每個瀏覽器的css默認樣式不盡相同,所以最簡單有效的方式就是對其進行初始化(覆蓋默認樣式)
> 常見 :? *{ margin: 0; padding: 0;}
>
> 庫:normalize.css
#### 二、**瀏覽器私有屬性**
> 常用的前綴有:
>
> firefox瀏覽器 :-moz-
>
> chrome、safari :-webkit-
>
> opera :-o- /?-xv-
>
> IE瀏覽器 :-ms-(目前只有 IE 8+支持)
#### **三、CSS hack(條件hack、屬性級hack、選擇符級hack)**
### JS垃圾回收機制
1. 項目中,如果存在大量不被釋放的內存(堆/棧/上下文),頁面性能會變得很慢。當某些代碼操作不能被合理釋放,就會造成內存泄漏。我們盡可能減少使用閉包,因為它會消耗內存。
1. 瀏覽器垃圾回收機制/內存回收機制:
> 瀏覽器的`Javascript`具有自動垃圾回收機制(`GC:Garbage Collecation`),垃圾收集器會定期(周期性)找出那些不在繼續使用的變量,然后釋放其內存。
**標記清除**:在`js`中,最常用的垃圾回收機制是標記清除:當變量進入執行環境時,被標記為“進入環境”,當變量離開執行環境時,會被標記為“離開環境”。垃圾回收器會銷毀那些帶標記的值并回收它們所占用的內存空間。\
**谷歌瀏覽器**:“查找引用”,瀏覽器不定時去查找當前內存的引用,如果沒有被占用了,瀏覽器會回收它;如果被占用,就不能回收。\
**IE瀏覽器**:“引用計數法”,當前內存被占用一次,計數累加1次,移除占用就減1,減到0時,瀏覽器就回收它。
1. 優化手段:內存優化 ; 手動釋放:取消內存的占用即可。
(1)堆內存:fn = null 【null:空指針對象】
(2)棧內存:把上下文中,被外部占用的堆的占用取消即可。
1. 內存泄漏
在 JS 中,常見的內存泄露主要有 4 種,全局變量、閉包、DOM 元素的引用、定時器
- JavaScript
- 1. DOM事件流
- 2. 模擬 new, Object create(), bind
- 5. 封裝函數進行字符串駝峰命名的轉換
- 6. 什么是promise
- 7. 判斷一個數是否為數組
- 10. __proto__和prototype以及原型,原型鏈,構造函數
- 11. 繼承
- 12. 閉包
- 13. 回調函數
- 14. var 和 let 區別
- 15. this、bind、call、apply
- 16.undefined和null的區別
- 17.內存泄漏
- 18.垃圾回收機制
- html css
- 1. 元素垂直水平居中
- 2. 清除浮動
- 3. bootstrap柵格系統
- 4. px rpx em rem vw 的區別
- 5. 兩種盒子模型
- 6. 合集
- web類
- 1. html5的新特性以及理解(web標簽語義化)
- 2. 什么是路由,關于前端路由和后端路由
- 3. 對優質代碼的理解
- 4. cookie 和 sessionStorage和localStorage
- 5. 瀏覽器內核
- 6. http 狀態碼
- 7. href 和 src 的區別
- 8. link 和 @import 的區別
- 9. http 狀態碼
- 10. websocket
- 11. 瀏覽器解析url
- 12.http緩存
- vue
- 1.vue2和vue3有哪些區別
- 1. 對 mvvvm 的理解
- 2. mvvm的優缺點
- 3. 數據雙向綁定的原理
- 4. 生命周期
- 5. 組件如何通信
- 6. computed和watch的區別
- 7. proxy 和 Object.defineProperty
- 8. 虛擬dom和 diff算法
- 9. 路由的嵌套與傳參
- 10. 路由導航鉤子
- 11. axios 的理解
- 12. vue自定義指令 diretive
- 13. diff 的實現
- 14. 實現一個簡單的雙向綁定
- 15. 為什么 data 是一個函數
- 題譜
- js
- 手寫篇
- css
- vue
- react
- 算法
- 自我介紹
- 八股文
- 源項目地址
- 1.計算機網絡
- 2.瀏覽器
- 3.html和css
- 4.javascript
- 6.typescript
- 7.vue
- 8.react
- 大廠面試
- 面試題大全
- 常見性能優化
- 面試實戰
- 面試分析
- 押題
- 1.微前端在項目中的實際應用
- 2.性能優化
- vue相關
- 1.說一說HashRouter和HistoryRouter的區別和原理
- 無敵之路,牛客網面試題自測記錄
- 前端基礎
- 1.html
- 2.js基礎
- 珠峰性能優化
- WebWorker
- url到渲染
- 瀏覽器加載機制
- 自我介紹1
- 手寫題
- 1.compose
- 2.setTimeout模擬setInterval
- 3.手寫數組拍平
- 4.手寫promise.all
- 5.手寫深拷貝
- webpack
- 實戰