[TOC]
# db-spring-boot-starter
我們將采用springboot 標準starter的做法開發項目基礎組件,利用org.springframework.boot.autoconfigure,完成對象的基本裝配。同時他具有以下功能:
* druid數據源
* mybatis-plus
* sharding-jdbc
* 字段填充插件
* 多租戶插件
* sql執行時間監控插件
* 查詢大結果集監控插件
* 敏感數據脫敏插件
* pagehelper分頁處理
## maven 相關依賴引入
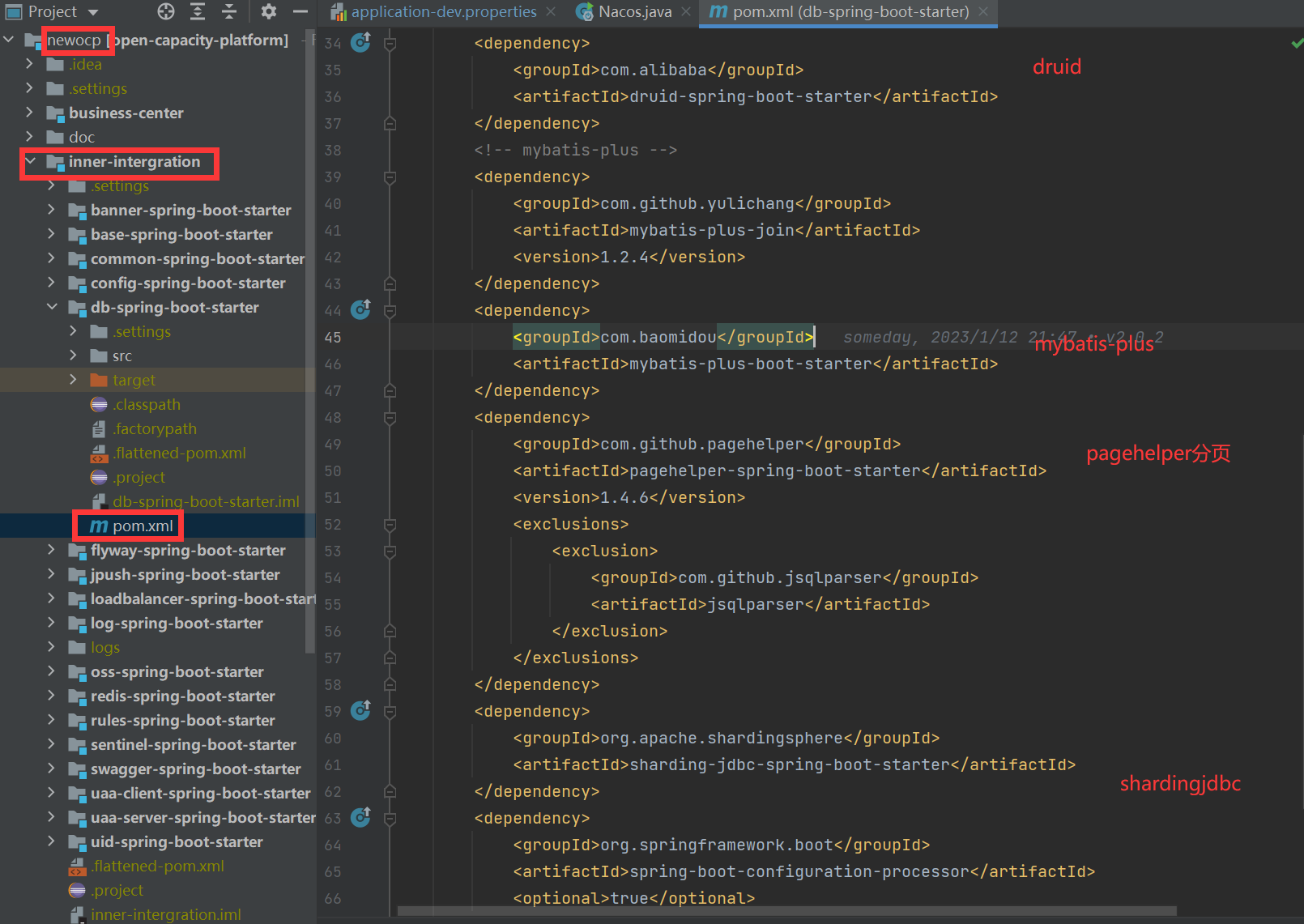
## druid數據源
* druid 連接池是阿里巴巴開源的數據庫連接池項目。Druid連接池為監控而生,內置強大的監控功能,監控特性不影響性能。功能強大,能防SQL注入,內置Loging能診斷Hack應用行為。
### 數據源競品分析

### druid 使用方式
平臺本身沒有重復造輪子,而是做整合,
* druid-spring-boot-starter
* dynamic-datasource-spring-boot-starter
* sharding-jdbc-spring-boot-starter
*單數據源配置
```
spring:
session:
store-type: none
datasource:
druid:
url: jdbc:mysql://${ocp.datasource.ip:192.168.92.216}:3306/oauth-center?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&useSSL=false
username: ${ocp.datasource.username}
password: ${ocp.datasource.password}
driver-class-name: com.mysql.cj.jdbc.Driver
#連接池配置(通常來說,只需要修改initialSize、minIdle、maxActive
initial-size: 5
max-active: 50
min-idle: 5
# 配置獲取連接等待超時的時間
max-wait: 60000
#打開PSCache,并且指定每個連接上PSCache的大小
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
validation-query: SELECT 'x'
test-on-borrow: false
test-on-return: false
test-while-idle: true
#配置間隔多久才進行一次檢測,檢測需要關閉的空閑連接,單位是毫秒
time-between-eviction-runs-millis: 60000
#配置一個連接在池中最小生存的時間,單位是毫秒
min-evictable-idle-time-millis: 300000
filter:
stat:
enabled: true
wall:
config:
multi-statement-allow: true
# WebStatFilter配置,說明請參考Druid Wiki,配置_配置WebStatFilter
#是否啟用StatFilter默認值true
web-stat-filter:
enabled: true
url-pattern: /*
exclusions: "*.js , *.gif ,*.jpg ,*.png ,*.css ,*.ico , /druid/*"
session-stat-max-count: 1000
profile-enable: true
# StatViewServlet配置
#展示Druid的統計信息,StatViewServlet的用途包括:1.提供監控信息展示的html頁面2.提供監控信息的JSON API
#是否啟用StatViewServlet默認值true
stat-view-servlet:
enabled: true
url-pattern: /druid/*
reset-enable: true
login-username: admin
login-password: admin
#根據配置中的url-pattern來訪問內置監控頁面,如果是上面的配置,內置監控頁面的首頁是/druid/index.html例如:
#http://110.76.43.235:9000/druid/index.html
#http://110.76.43.235:8080/mini-web/druid/index.html
#允許清空統計數據
#StatViewSerlvet展示出來的監控信息比較敏感,是系統運行的內部情況,如果你需要做訪問控制,可以配置allow和deny這兩個參數
#deny優先于allow,如果在deny列表中,就算在allow列表中,也會被拒絕。如果allow沒有配置或者為空,則允許所有訪問
#配置的格式
#<IP>
#或者<IP>/<SUB_NET_MASK_size>其中128.242.127.1/24
#24表示,前面24位是子網掩碼,比對的時候,前面24位相同就匹配,不支持IPV6。
#stat-view-servlet.allow=
#stat-view-servlet.deny=128.242.127.1/24,128.242.128.1
# Spring監控配置,說明請參考Druid Github Wiki,配置_Druid和Spring關聯監控配置
#aop-patterns= # Spring監控AOP切入點,如x.y.z.service.*,配置多個英文逗號分隔
mybatis-plus:
mapper-locations: com/open/**/mapper/*Mapper.xml
#實體掃描,多個package用逗號或者分號分隔
typeAliasesPackage: com.open.capacity.oauth.model
global-config:
banner: false
db-config:
id-type: auto
```
* 多數據源配置
```
spring:
datasource:
dynamic:
enabled: true
datasource:
master:
url: jdbc:mysql://${ocp.datasource.ip:192.168.92.216}:3306/oauth-center?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&useSSL=false
username: ${ocp.datasource.username}
password: ${ocp.datasource.password}
driver-class-name: com.mysql.cj.jdbc.Driver
slave:
url: jdbc:mysql://${ocp.datasource.ip:192.168.92.216}:3306/user-center?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&useSSL=false
username: ${ocp.datasource.username}
password: ${ocp.datasource.password}
driver-class-name: com.mysql.cj.jdbc.Driver
druid:
filter:
stat:
enabled: true
wall:
config:
multi-statement-allow: true
# WebStatFilter配置,說明請參考Druid Wiki,配置_配置WebStatFilter
#是否啟用StatFilter默認值true
web-stat-filter:
enabled: true
url-pattern: /*
exclusions: "*.js , *.gif ,*.jpg ,*.png ,*.css ,*.ico , /druid/*"
session-stat-max-count: 1000
profile-enable: true
# StatViewServlet配置
#展示Druid的統計信息,StatViewServlet的用途包括:1.提供監控信息展示的html頁面2.提供監控信息的JSON API
#是否啟用StatViewServlet默認值true
stat-view-servlet:
enabled: true
url-pattern: /druid/*
reset-enable: true
login-username: admin
login-password: admin
mybatis-plus:
mapper-locations: com/open/**/mapper/*Mapper.xml
#實體掃描,多個package用逗號或者分號分隔
typeAliasesPackage: com.open.capacity.oauth.model
global-config:
banner: false
db-config:
id-type: auto
```
* sharding配置如下
```
spring:
shardingsphere:
enabled: false
datasource:
druid:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://${ocp.datasource.ip:192.168.92.216}:3306/user-center?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai
username: ${ocp.datasource.username}
password: ${ocp.datasource.password}
#初始化時建立物理連接的個數。初始化發生在顯示調用init方法,或者第一次getConnection時
initial-size: 5
#最大連接數
max-active: 50
#最小連接數
min-idle: 5
#獲取連接時最大等待時間,單位毫秒。配置了maxWait之后,缺省啟用公平鎖,并發效率會有所下降,如果需要可以通過配置useUnfairLock屬性為true使用非公平鎖。
max-wait: 60000
#用來檢測連接是否有效的sql,要求是一個查詢語句,常用select 'x'。如果validationQuery為null,testOnBorrow、testOnReturn、testWhileIdle都不會起作用。
validation-query: SELECT 1 FROM DUAL
#單位:秒,檢測連接是否有效的超時時間。底層調用jdbc Statement對象的void setQueryTimeout(int seconds)方法
validation-query-timeout: 5
#建議配置為true,不影響性能,并且保證安全性。申請連接的時候檢測,如果空閑時間大于timeBetweenEvictionRunsMillis,執行validationQuery檢測連接是否有效。
test-while-idle: true
#申請連接時執行validationQuery檢測連接是否有效,做了這個配置會降低性能。
test-on-borrow: false
#歸還連接時執行validationQuery檢測連接是否有效,做了這個配置會降低性能。
test-on-return: false
#有兩個含義: 1) Destroy線程會檢測連接的間隔時間,如果連接空閑時間大于等于minEvictableIdleTimeMillis則關閉物理連接。 2) testWhileIdle的判斷依據,詳細看testWhileIdle屬性的說明
time-between-eviction-runs-millis: 60000
# 連接保持空閑而不被驅逐的最小時間
min-evictable-idle-time-millis: 300000
#連接池中的minIdle數量以內的連接,空閑時間超過minEvictableIdleTimeMillis,則會執行keepAlive操作。
keep-alive: true
# 通過connectProperties屬性來打開mergeSql功能;慢SQL記錄
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 合并多個DruidDataSource的監控數據
useGlobalDataSourceStat: true
#是否緩存preparedStatement,也就是PSCache。PSCache對支持游標的數據庫性能提升巨大,比如說oracle。在mysql下建議關閉。
pool-prepared-statements: false
#要啟用PSCache,必須配置大于0,當大于0時,poolPreparedStatements自動觸發修改為true。在Druid中,不會存在Oracle下PSCache占用內存過多的問題,可以把這個數值配置大一些,比如說100
max-pool-prepared-statement-per-connection-size: 100
#是否到期強制刪除,避免某個連接長時間阻塞無法回收
remove-abandoned: true
#租用時長,Druid避免連泄露 s
remove-abandoned-timeout: 120
```
## druid原理解析
### 1.主流程:獲取連接流程
首先從入口來看看它在獲取連接時做了哪些操作:
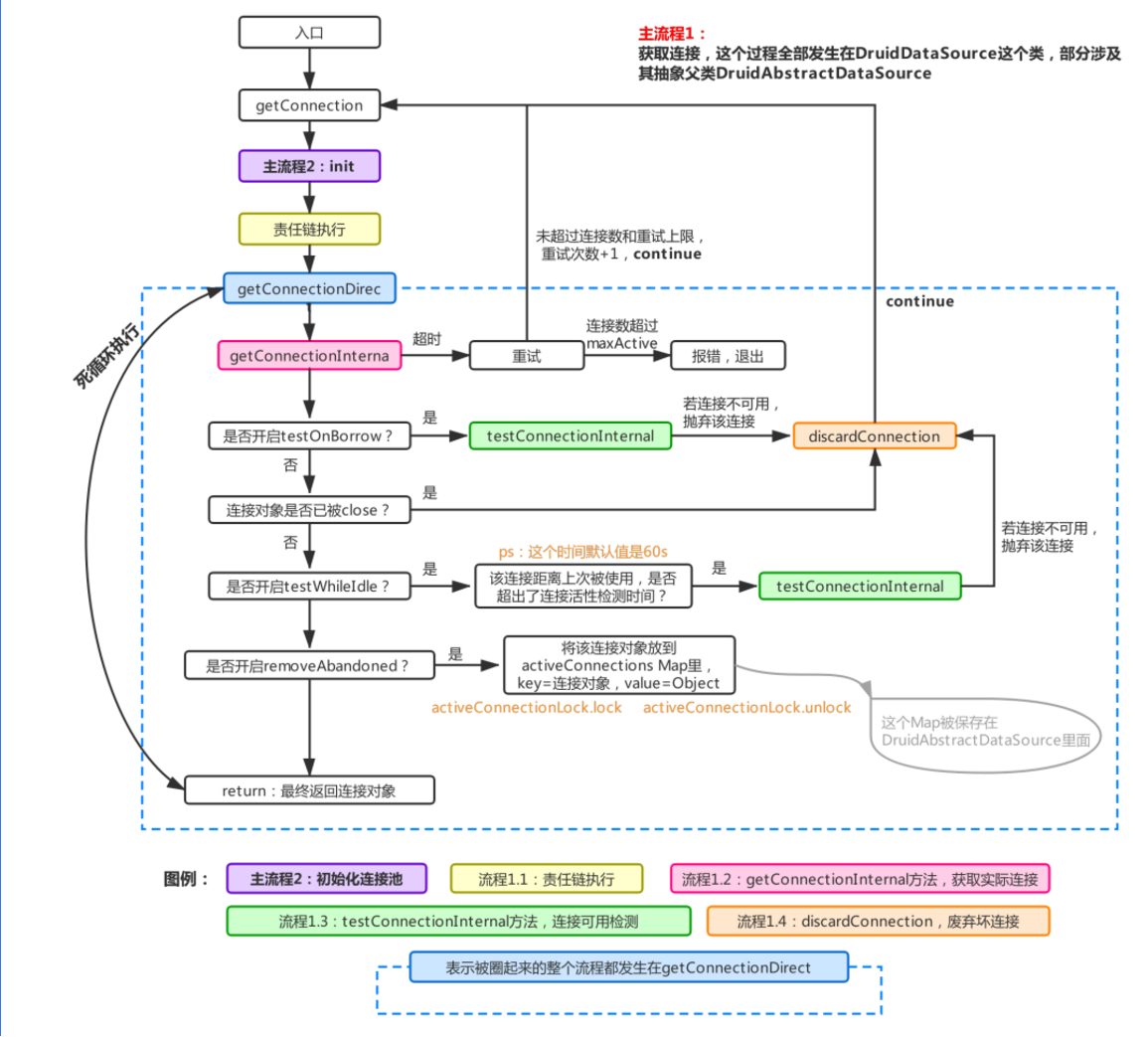
* 上述為獲取連接時的流程圖,首先會調用init進行連接池的初始化,然后運行責任鏈上的每一個filter,最終執行getConnectionDirect獲取真正的連接對象,如果開啟了testOnBorrow,則每次都會去測試連接是否可用(這也是官方不建議設置testOnBorrow為true的原因,影響性能,這里的測試是指測試mysql服務端的長連接是否斷開,一般mysql服務端長連保活時間是8h,被使用一次則刷新一次使用時間,若一個連接距離上次被使用超過了保活時間,那么再次使用時將無法與mysql服務端通信)。
* 如果testOnBorrow沒有被置為true,則會進行testWhileIdle的檢查(這一項官方建議設置為true,缺省值也是true),檢查時會判斷當前連接對象距離上次被使用的時間是否超過規定檢查的時間,若超過,則進行檢查一次,這個檢查時間通過timeBetweenEvictionRunsMillis來控制,默認60s。
* 每個連接對象會記錄下上次被使用的時間,用當前時間減去上一次的使用時間得出閑置時間,閑置時間再跟timeBetweenEvictionRunsMillis比較,超過這個時間就做一次連接可用性檢查,這個相比testOnBorrow每次都檢查來說,性能會提升很多,用的時候無需關注該值,因為缺省值是true,經測試如果將該值設置為false,testOnBorrow也設置為false,數據庫服務端長連保活時間改為60s,60s內不使用連接,超過60s后使用將會報連接錯誤。
* 若使用testConnectionInternal方法測試長連接結果為false,則證明該連接已被服務端斷開或者有其他的網絡原因導致該連接不可用,則會觸發discardConnection進行連接回收(對應流程1.4,因為丟棄了一個連接,因此該方法會喚醒主流程3進行檢查是否需要新建連接)。整個流程運行在一個死循環內,直到取到可用連接或者超過重試上限報錯退出(在連接沒有超過連接池上限的話,最多重試一次(重試次數默認重試1次,可以通過notFullTimeoutRetryCount屬性來控制),所以取連接這里一旦發生等待,在連接池沒有滿的情況下,最大等待 2 × maxWait 的時間 ←這個有待驗證)。
#### 特別說明①
為了保證性能,不建議將testOnBorrow設置為true,或者說牽扯到長連接可用檢測的那幾項配置使用druid默認的配置就可以保證性能是最好的,如上所說,默認長連接檢查是60s一次,所以不啟用testOnBorrow的情況下要想保證萬無一失,自己要確認下所連的那個mysql服務端的長連接保活時間(雖然默認是8h,但是dba可能給測試環境設置的時間遠小于這個時間,所以如果這個時間小于60s,就需要手動設置timeBetweenEvictionRunsMillis了,如果mysql服務端長連接時間是8h或者更長,則用默認值即可。
#### 特別說明②
為了防止不必要的擴容,在mysql服務端長連接夠用的情況下,對于一些qps較高的服務、網關業務,建議把池子的最小閑置連接數minIdle和最大連接數maxActive設置成一樣的,且按照需要調大,且開啟keepAlive進行連接活性檢查(參考流程4.1),這樣就不會后期發生動態新建連接的情況(建連還是個比較重的操作,所以不如一開始就申請好所有需要的連接,個人意見,僅供參考),但是像管理后臺這種,長期qps非常低,但是有的時候需要用管理后臺做一些巨大的操作(比如導數據什么的)導致需要的連接暴增,且管理后臺不會特別要求性能,就適合將minIdle的值設置的比maxActive小,這樣不會造成不必要的連接浪費,也不會在需要暴增連接的時候無法動態擴增連接。
### 2.主流程:初始化連接池
通過上面的流程圖可以看到,在獲取一個連接的時候首先會檢查連接池是否已經初始化完畢(通過inited來控制,bool類型,未初始化為flase,初始化完畢為true,這個判斷過程在init方法內完成),若沒有初始化,則調用init進行初始化(圖主流程1中的紫色部分),下面來看看init方法里又做了哪些操作:
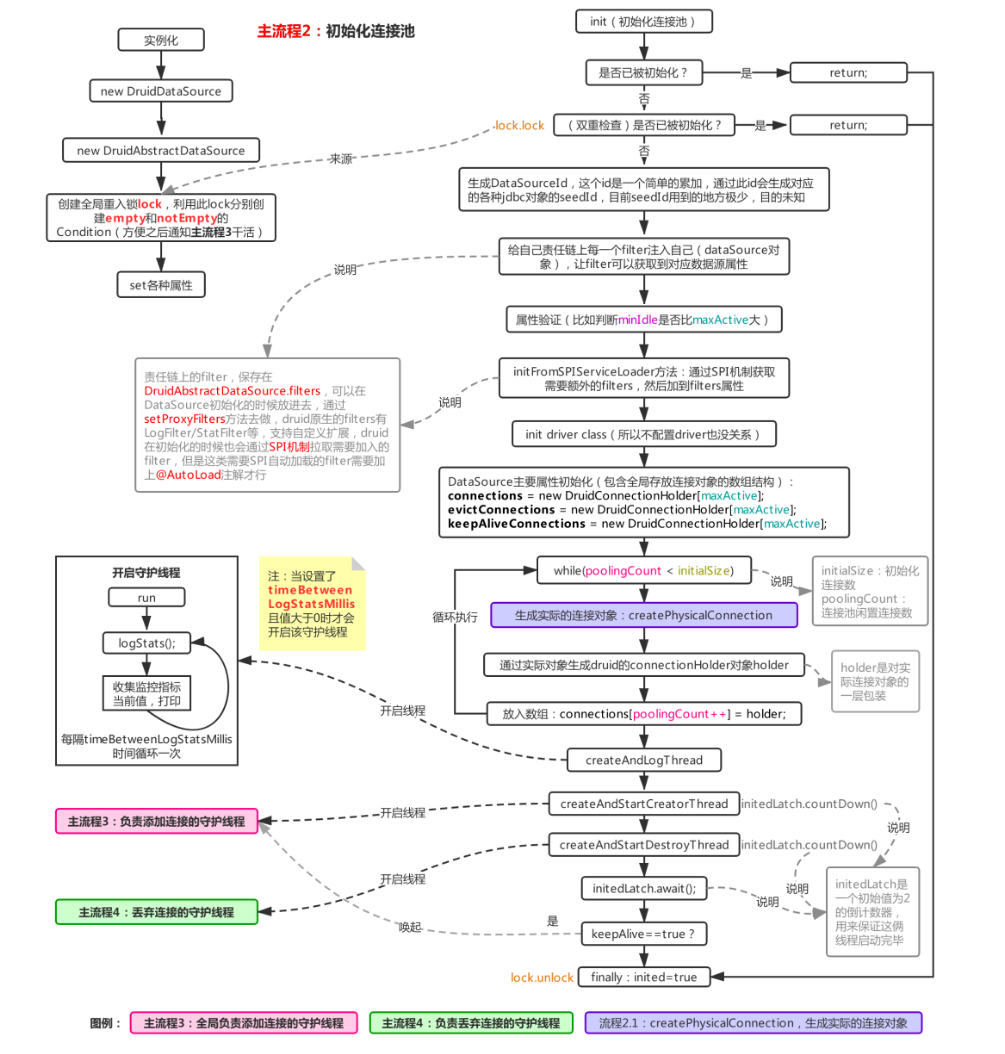
可以看到,實例化的時候會初始化全局的重入鎖lock,在初始化過程中包括后續的連接池操作都會利用該鎖保證線程安全,初始化連接池的時候首先會進行雙重檢查是否已經初始化過,若沒有,則進行連接池的初始化,這時候還會通過SPI機制額外加載責任鏈上的filter。
但是這類filter需要在類上加上@AutoLoad注解。然后初始化了三個數組,容積都為maxActive,首先connections就是用來存放池子里連接對象的,evictConnections用來存放每次檢查需要拋棄的連接(結合流程4.1理解),keepAliveConnections用于存放需要連接檢查的存活連接(同樣結合流程4.1理解),然后生成初始化數(initialSize)個連接,放進connections,然后生成兩個必須的守護線程,用來添加連接進池以及從池子里摘除不需要的連接,這倆過程較復雜,因此拆出來單說(主流程3和主流程4)。
特別說明①
* 從流程上看如果一開始實例化的時候不對連接池進行初始化(這個初始化是指對池子本身的初始化,并非單純的指druid對象屬性的初始化),那么在第一次調用getConnection時就會走上圖那么多邏輯,尤其是耗時較久的建立連接操作,被重復執行了很多次,導致第一次getConnection時耗時過久,如果你的程序并發量很大,那么第一次獲取連接時就會因為初始化流程而發生排隊,所以建議在實例化連接池后對其進行預熱,通過調用init方法或者getConnection方法都可以。
特別說明②
在構建全局重入鎖的時候,利用lock對象生成了倆Condition,對這倆Condition解釋如下:
當連接池連接夠用時,利用empty阻塞添加連接的守護線程(主流程3),當連接池連接不夠用時,獲取連接的那個線程(這里記為業務線程A)就會阻塞在notEmpty上,且喚起阻塞在empty上的添加連接的守護線程,走完添加連接的流程,走完后會重新喚起阻塞在notEmpty上的業務線程A,業務線程A就會繼續嘗試獲取連接。
#### 流程1.1:責任鏈
WARN:這塊東西結合源碼看更容易理解
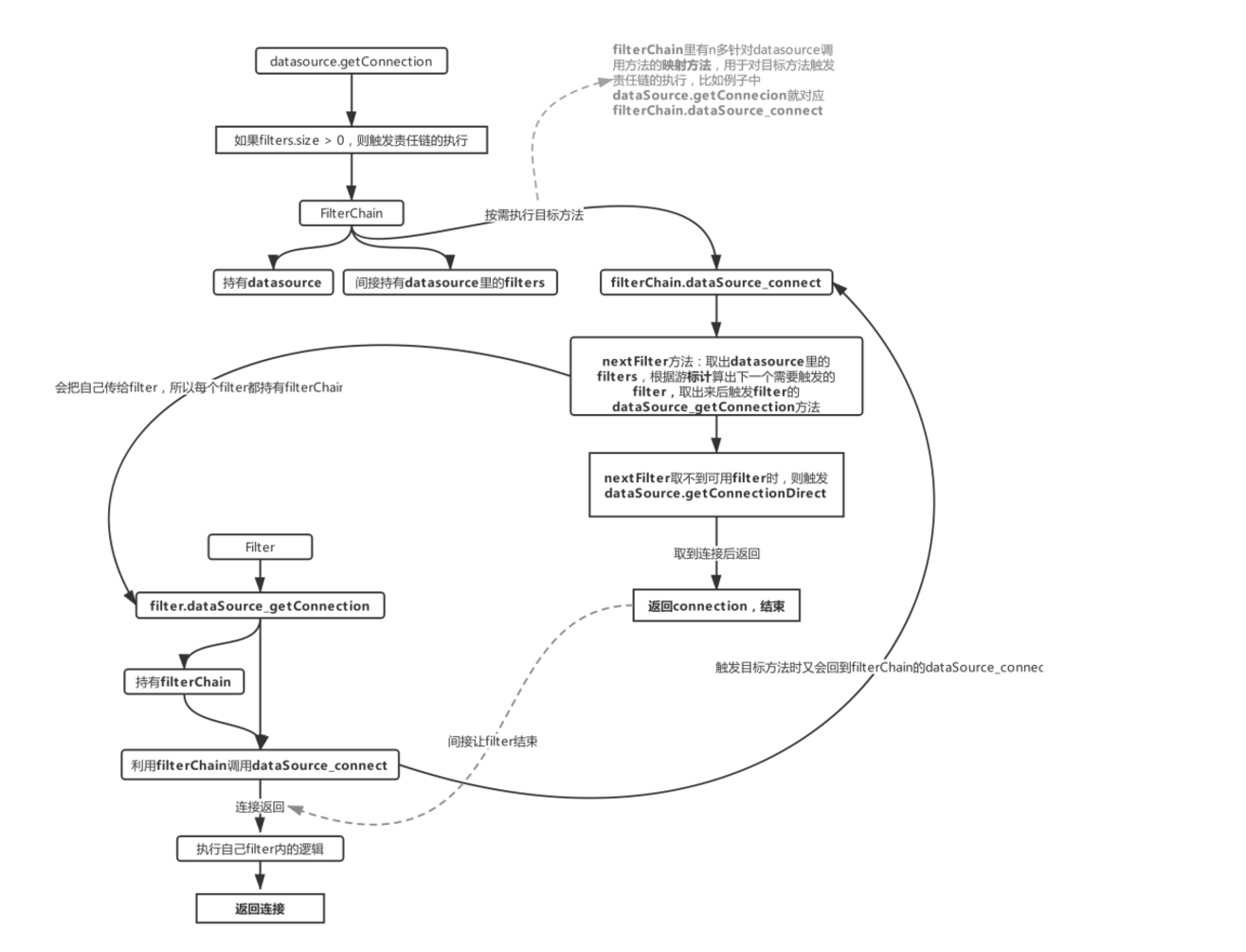
這里對應流程1里獲取連接時需要執行的責任鏈,每個DruidAbstractDataSource里都包含filters屬性,filters是對Druid里Filters接口的實現,里面有很多對應著連接池里的映射方法,比如例子中dataSource的getConnection方法在觸發的時候就會利用FilterChain把每個filter里的dataSource\_getConnection給執行一遍,這里也要說明下FilterChain,通過流程1.1可以看出來,datasource是利用FilterChain來觸發各個filter的執行的,FilterChain里也有一堆datasource里的映射方法,比如上圖里的dataSource\_connect,這個方法會把datasource里的filters全部執行一遍直到nextFilter取不到值,才會觸發dataSource.getConnectionDirect,這個結合代碼會比較容易理解。
#### 流程1.2:從池中獲取連接的流程
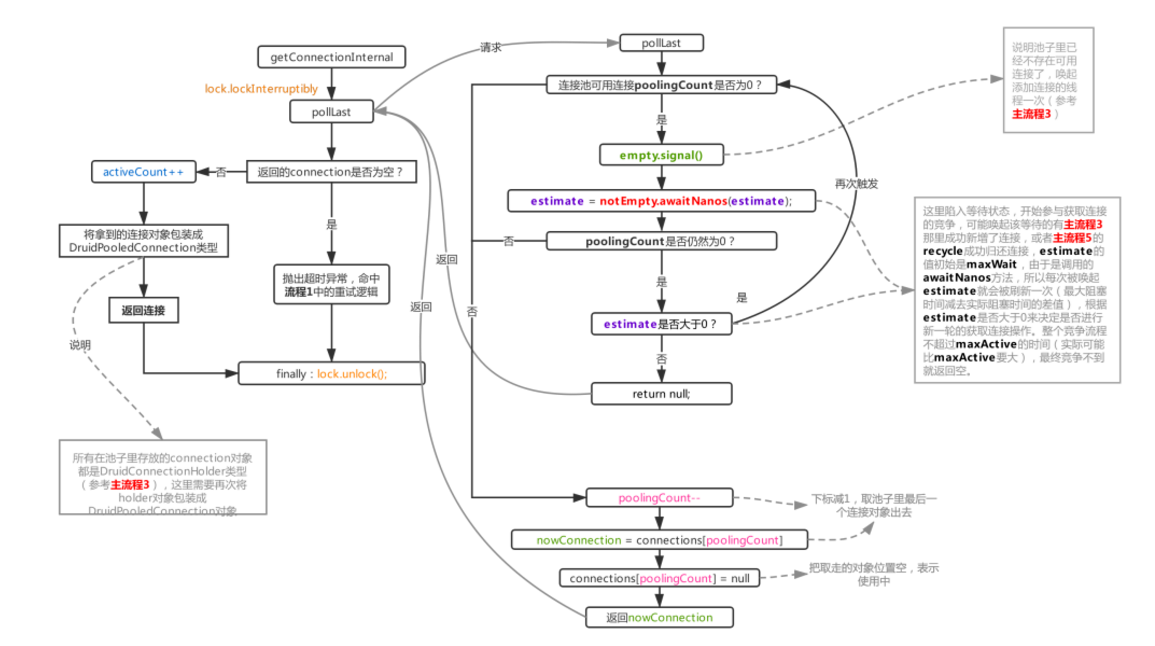
通過getConnectionInternal方法從池子里獲取真正的連接對象,druid支持兩種方式新增連接,一種是通過開啟不同的守護線程通過await、signal通信實現(本文啟用的方式,也是默認的方式),另一種是直接通過線程池異步新增,這個方式通過在初始化druid時傳入asyncInit=true,再把一個線程池對象賦值給createScheduler,就成功啟用了這種模式,沒仔細研究這種方式,所以本文的流程圖和代碼塊都會規避這個模式。
上面的流程很簡單,連接足夠時就直接poolingCount-1,數組取值,返回,activeCount+1,整體復雜度為O(1),關鍵還是看取不到連接時的做法,取不到連接時,druid會先喚起新增連接的守護線程新增連接,然后陷入等待狀態,然后喚醒該等待的點有兩處,一個是用完了連接recycle(主流程5)進池子后觸發,另外一個就是新增連接的守護線程成功新增了一個連接后觸發,await被喚起后繼續加入鎖競爭,然后往下走如果發現池子里的連接數仍然是0(說明在喚醒后參與鎖競爭里剛被放進來的連接又被別的線程拿去了),則繼續下一次的await,這里采用的是awaitNanos方法,初始值是maxWait,然后下次被刷新后就是maxWait減去上次阻塞花費的實際時間,每次await的時間會逐步減少,直到歸零,整體時間是約等于maxWait的,但實際比maxActive要大,因為程序本身存在耗時以及被喚醒后又要參與鎖競爭導致也存在一定的耗時。
如果最終都沒辦法拿到連接則返回null出去,緊接著觸發主流程1中的重試邏輯。
druid如何防止在獲取不到連接時阻塞過多的業務線程?
* 通過上面的流程圖和流程描述,如果非常極端的情況,池子里的連接完全不夠用時,會阻塞過多的業務線程,甚至會阻塞超過maxWait這么久,有沒有一種措施是可以在連接不夠用的時候控制阻塞線程的個數,超過這個限制后直接報錯,而不是陷入等待呢?
* druid其實支持這種策略的,在maxWaitThreadCount屬性為默認值(-1)的情況下不啟用,如果maxWaitThreadCount配置大于0,表示啟用,這是druid做的一種丟棄措施,如果你不希望在池子里的連接完全不夠用導阻塞的業務線程過多,就可以考慮配置該項,這個屬性的意思是說在連接不夠用時最多讓多少個業務線程發生阻塞,流程1.2的圖里沒有體現這個開關的用途,可以在代碼里查看,每次在pollLast方法里陷入等待前會把屬性notEmptyWaitThreadCount進行累加,阻塞結束后會遞減,由此可見notEmptyWaitThreadCount就是表示當前等待可用連接時阻塞的業務線程的總個數,而getConnectionInternal在每次調用pollLast前都會判斷這樣一段代碼:
```
if (maxWaitThreadCount \> 0 && notEmptyWaitThreadCount \>= maxWaitThreadCount) { connectErrorCountUpdater.incrementAndGet(this); throw new SQLException("maxWaitThreadCount " + maxWaitThreadCount + ", current wait Thread count " + lock.getQueueLength()); //直接拋異常,而不是陷入等待狀態阻塞業務線程 }
```
可以看到,如果配置了maxWaitThreadCount所限制的等待線程個數,那么會直接判斷當前陷入等待的業務線程是否超過了maxWaitThreadCount,一旦超過甚至不觸發pollLast的調用(防止新增等待線程),直接拋錯。
一般情況下不需要啟用該項,一定要啟用建議考慮好maxWaitThreadCount的取值,一般來說發生大量等待說明代碼里存在不合理的地方:比如典型的連接池基本配置不合理,高qps的系統里maxActive配置過小;比如借出去的連接沒有及時close歸還;比如存在慢查詢或者慢事務導致連接借出時間過久。這些要比配置maxWaitThreadCount更值得優先考慮,當然配置這個做一個極限保護也是沒問題的,只是要結合實際情況考慮好取值。
#### 流程1.3:連接可用性測試
#### ①init-checker
講這塊的東西之前,先來了解下如何初始化檢測連接用的checker,整個流程參考下圖:
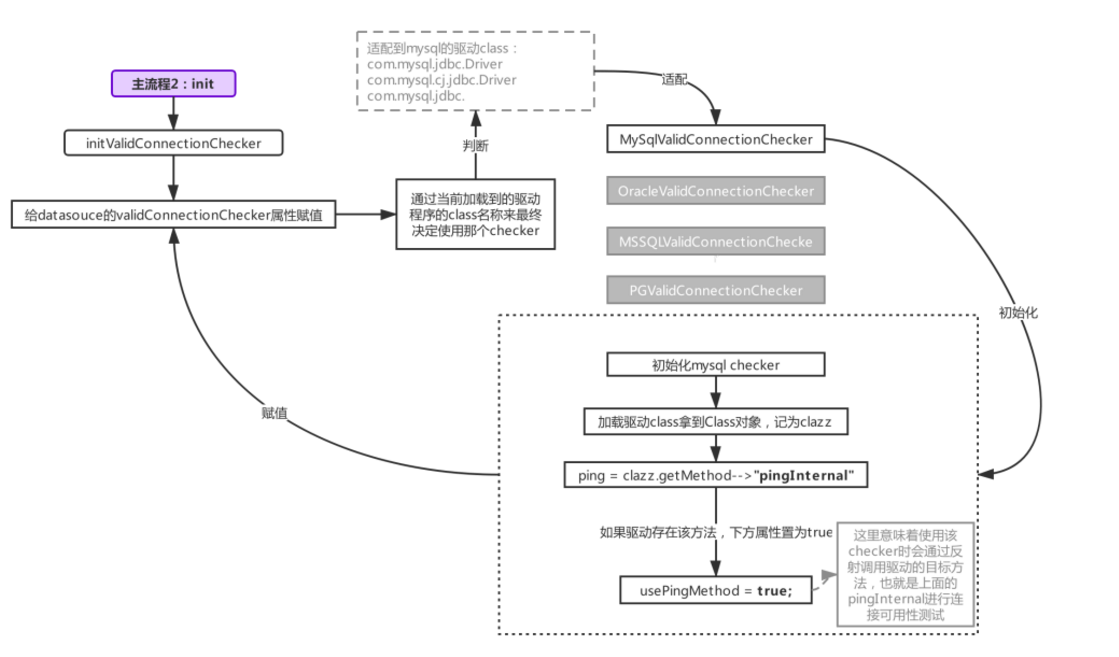
初始化checker發生在init階段(限于篇幅,沒有在主流程2(init階段)里體現出來,只需要記住初始化checker也是發生在init階段就好),druid支持多種數據庫的連接源,所以checker針對不同的驅動程序都做了適配,所以才看到圖中checker有不同的實現,我們根據加載到的驅動類名匹配不同的數據庫checker,上圖匹配至mysql的checker,checker的初始化里做了一件事情,就是判斷驅動內是否有ping方法(jdbc4開始支持,mysql-connector-java早在3.x的版本就有ping方法的實現了),如果有,則把usePingMethod置為true,用于后續啟用checker時做判斷用(下面會講,這里置為true,則通過反射的方式調用驅動程序的ping方法,如果為false,則觸發普通的SELECT 1查詢檢測,SELECT 1就是我們非常熟悉的那個東西啦,新建statement,然后執行SELECT 1,然后再判斷連接是否可用)。
#### ②testConnectionInternal
然后回到本節探討的方法:流程1.3對應的testConnectionInternal
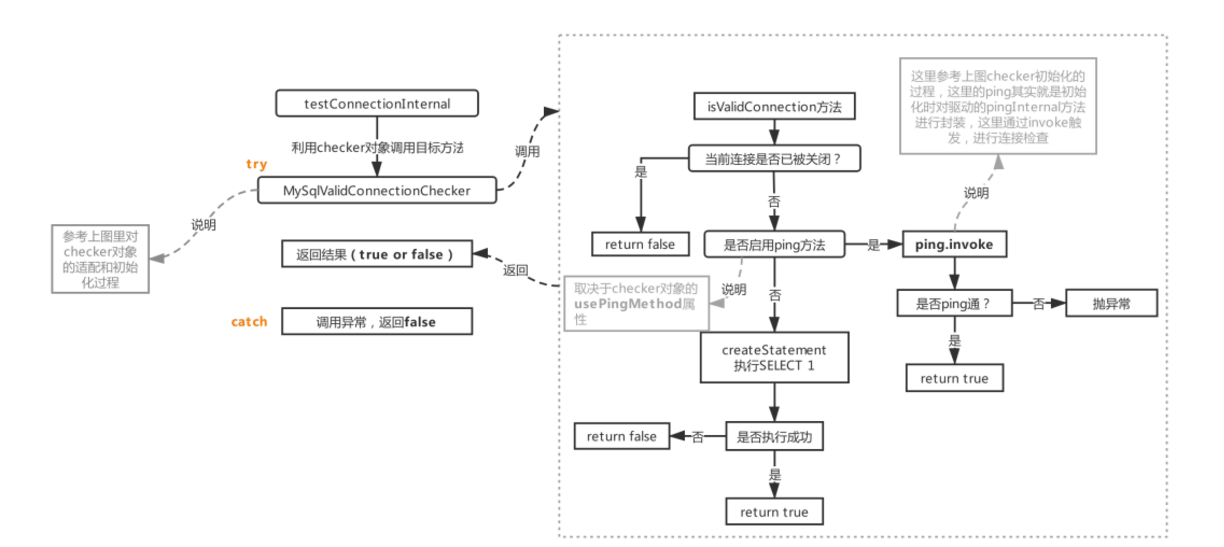
這個方法會利用主流程2(init階段)里初始化好的checker對象(流程參考init-checker)里的isValidConnection方法,如果啟用ping,則該方法會利用invoke觸發驅動程序里的ping方法,如果不啟用ping,就采用SELECT 1方式(從init-checker里可以看出啟不啟用取決于加載到的驅動程序里是否存在相應的方法)。
#### 流程1.4:拋棄連接
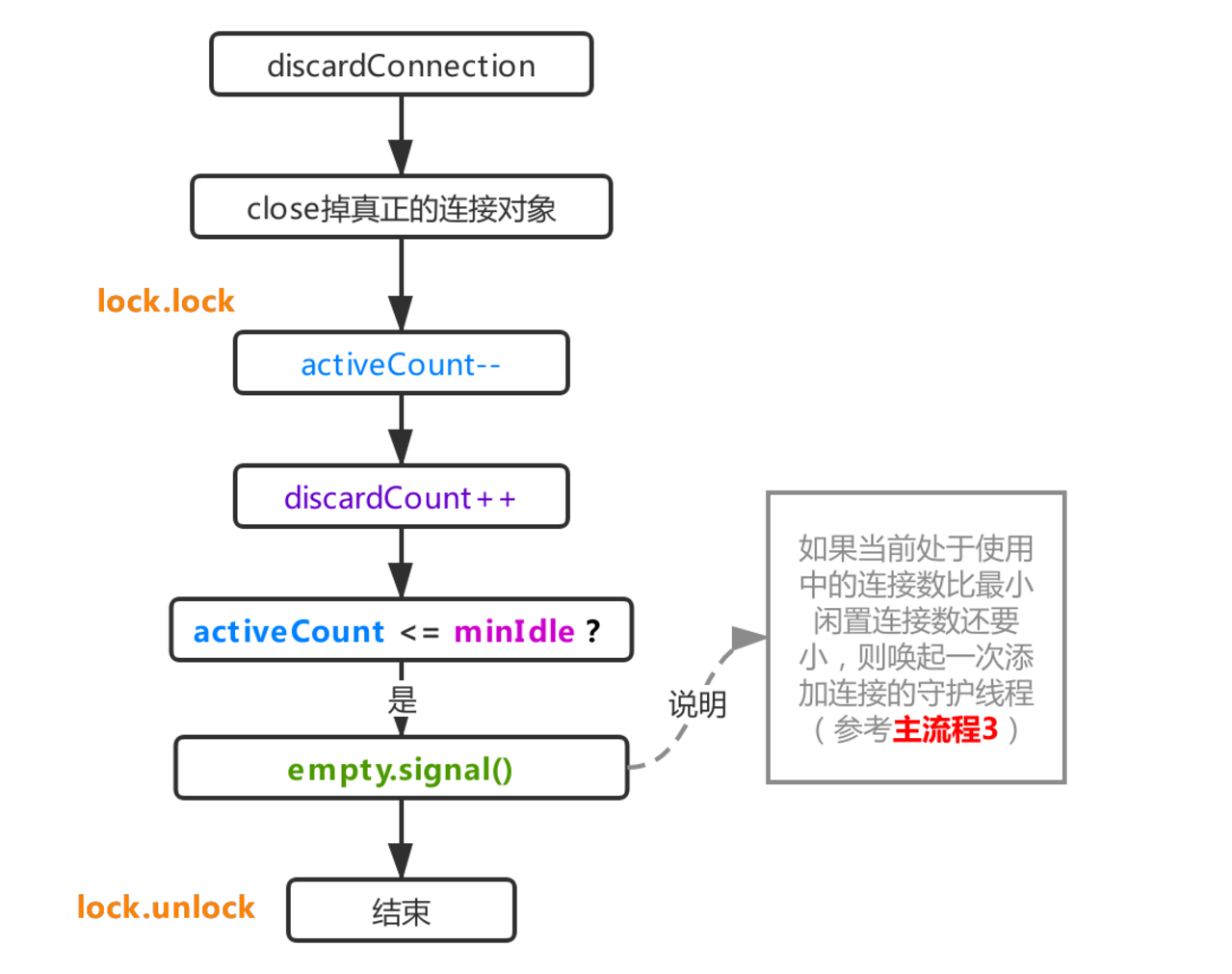
經過流程1.3返回的測試結果,如果發現連接不可用,則直接觸發拋棄連接邏輯,這個過程非常簡單,如上圖所示,由流程1.2獲取到該連接時累加上去的activeCount,在本流程里會再次減一,表示被取出來的連接不可用,并不能active狀態。其次這里的close是拿著驅動那個連接對象進行close,正常情況下一個連接對象會被druid封裝成DruidPooledConnection對象,內部持有的conn就是真正的驅動Connection對象,上圖中的關閉連接就是獲取的該對象進行close,如果使用包裝類DruidPooledConnection進行close,則代表回收連接對象(recycle,參考主流程5)。
### 3.主流程:添加連接的守護線程
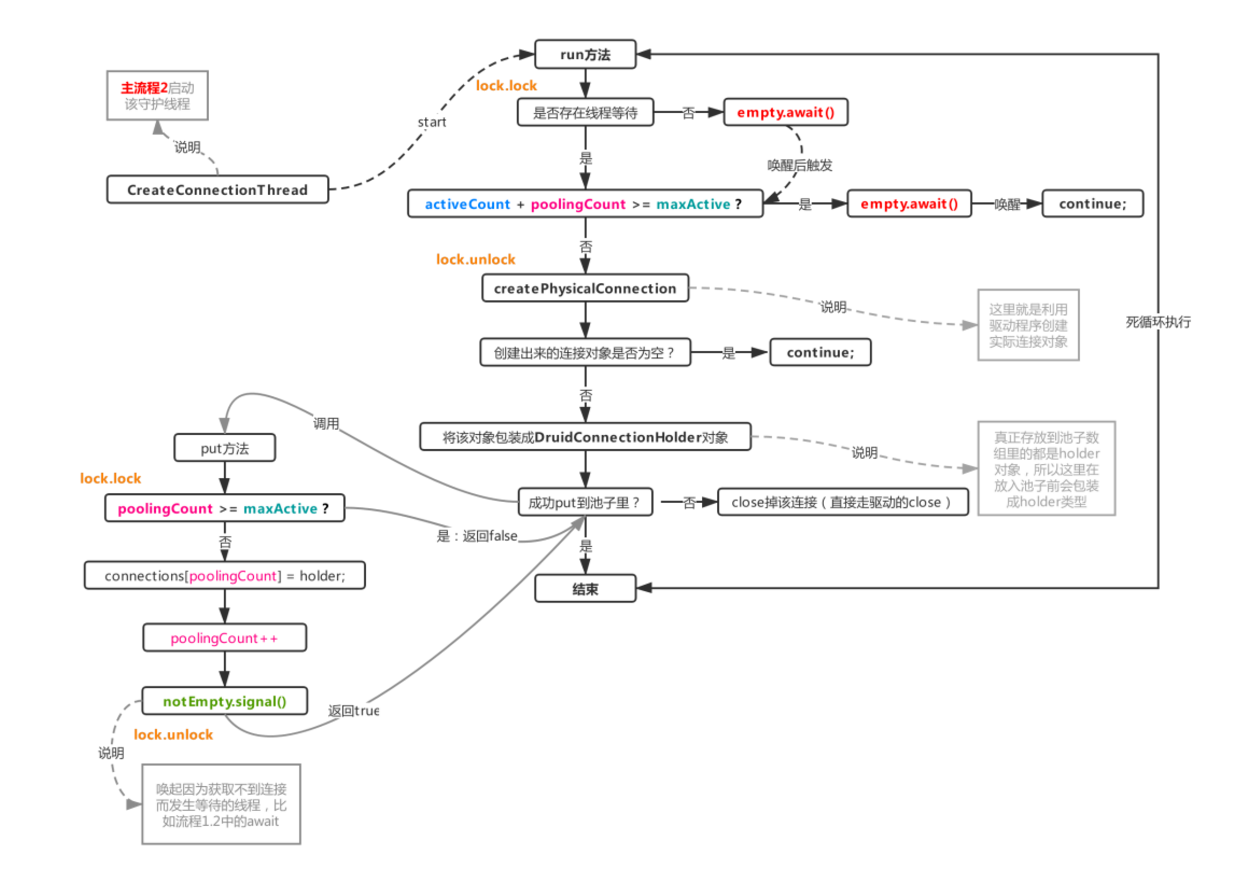
在主流程2(init初始化階段)時就開啟了該流程,該流程獨立運行,大部分時間處于等待狀態,不會搶占cpu,但是當連接不夠用時,就會被喚起追加連接,成功創建連接后將會喚醒其他正在等待獲取可用連接的線程,比如:
結合流程1.2來看,當連接不夠用時,會通過empty.signal喚醒該線程進行補充連接(阻塞在empty上的線程只有主流程3的單線程),然后通過notEmpty阻塞自己,當該線程補充連接成功后,又會對阻塞在notEmpty上的線程進行喚醒,讓其進入鎖競爭狀態,簡單理解就是一個生產-消費模型。這里有一些細節,比如池子里的連接使用中(activeCount)加上池子里剩余連接數(poolingCount)就是指當前一共生成了多少個連接,這個數不能比maxActive還大,如果比maxActive還大,則再次陷入等待。而在往池子里put連接時,則判斷poolingCount是否大于maxActive來決定最終是否入池。
### 4.主流程:拋棄連接的守護線程
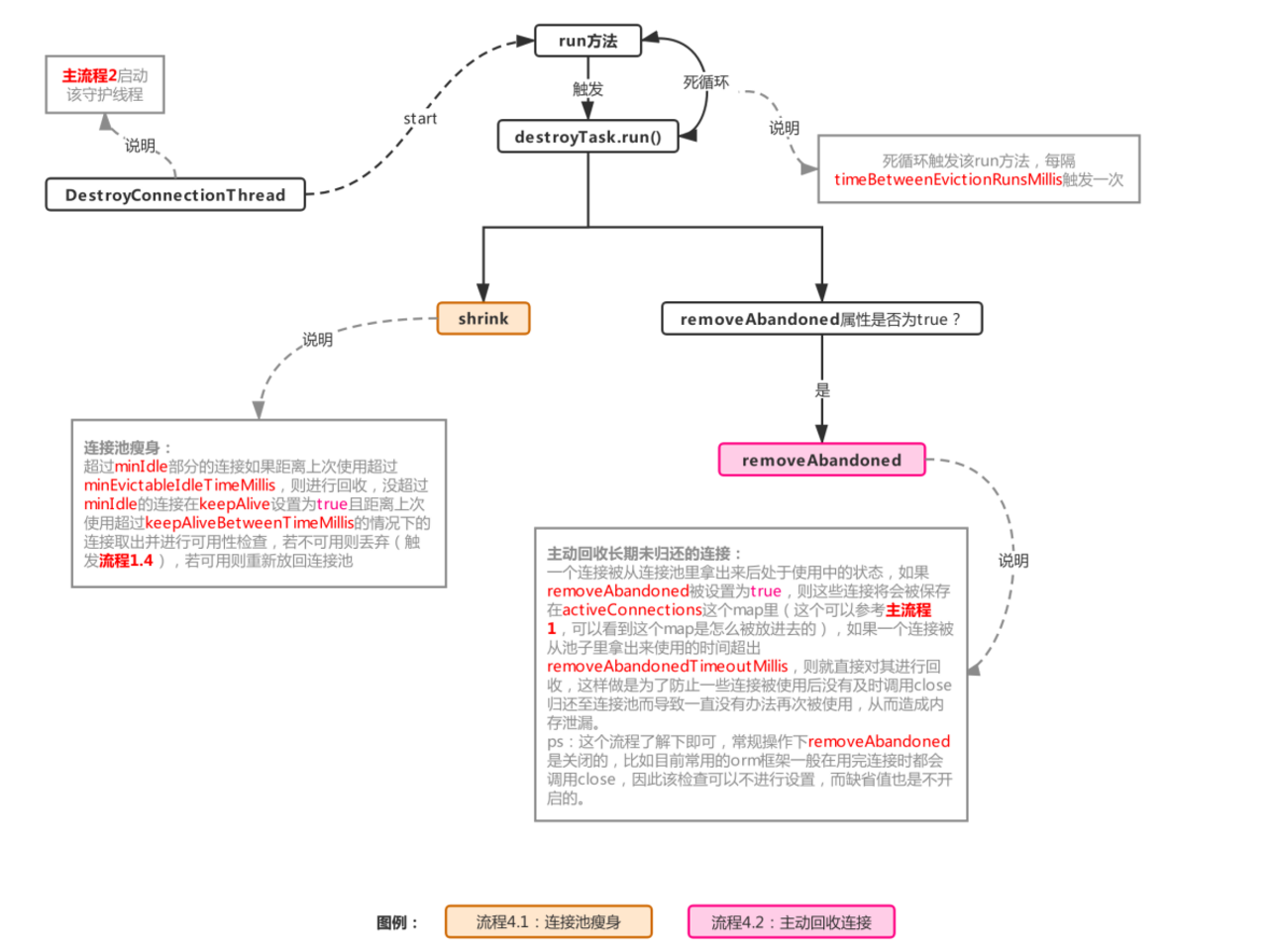
#### 流程4.1:連接池瘦身,檢查連接是否可用以及丟棄多余連接
整個過程如下:
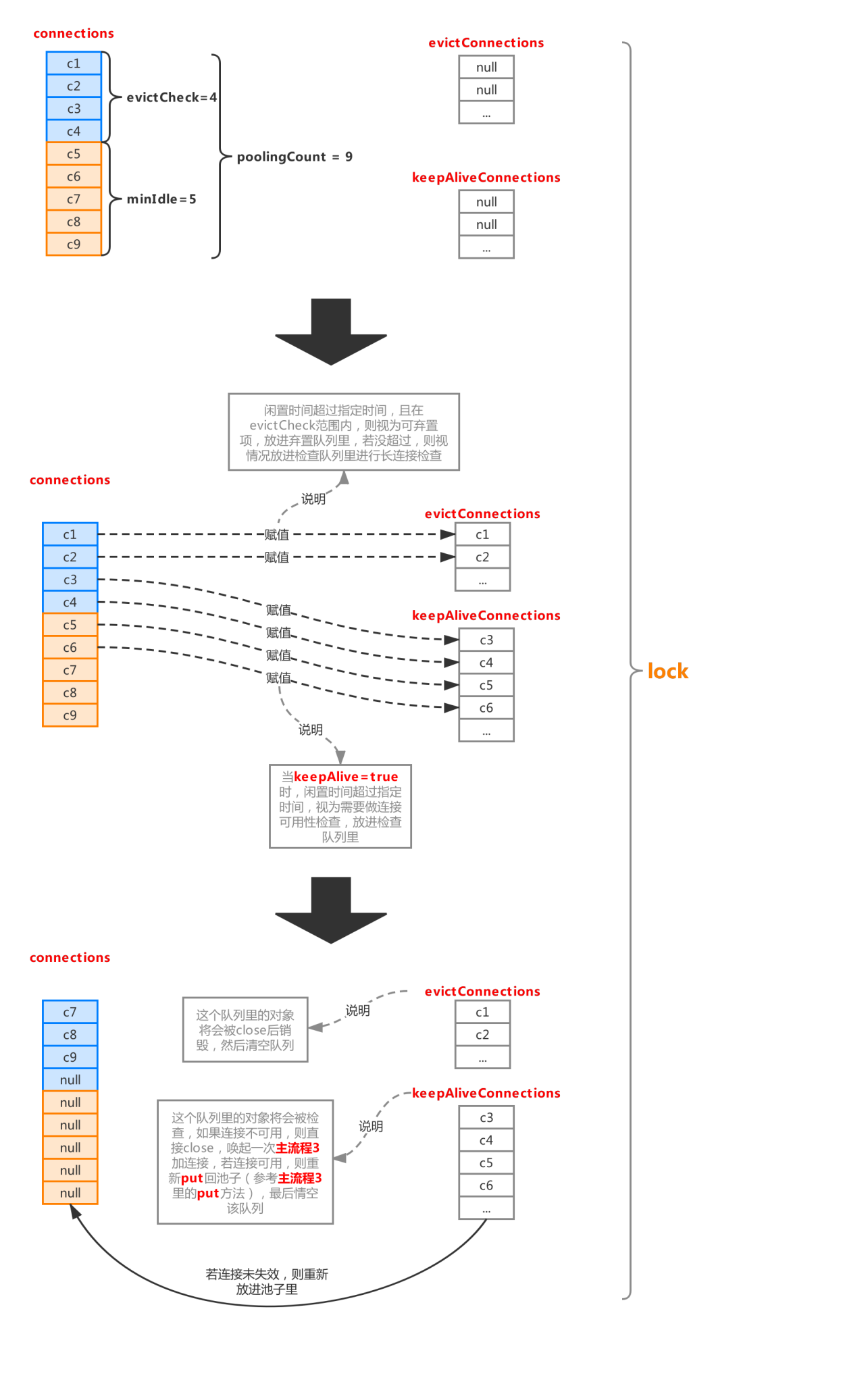
整個流程分成圖中主要的幾步,首先利用poolingCount減去minIdle計算出需要做丟棄檢查的連接對象區間,意味著這個區間的對象有被丟棄的可能,具體要不要放進丟棄隊列evictConnections,要判斷兩個屬性:
minEvictableIdleTimeMillis:最小檢查間隙,缺省值30min,官方解釋:一個連接在池中最小生存的時間(結合檢查區間來看,閑置時間超過這個時間,才會被丟棄)。
maxEvictableIdleTimeMillis:最大檢查間隙,缺省值7h,官方解釋:一個連接在池中最大生存的時間(無視檢查區間,只要閑置時間超過這個時間,就一定會被丟棄)。
如果當前連接對象閑置時間超過minEvictableIdleTimeMillis且下標在evictCheck區間內,則加入丟棄隊列evictConnections,如果閑置時間超過maxEvictableIdleTimeMillis,則直接放入evictConnections(一般情況下會命中第一個判斷條件,除非一個連接不在檢查區間,且閑置時間超過maxEvictableIdleTimeMillis)。
如果連接對象不在evictCheck區間內,且keepAlive屬性為true,則判斷該對象閑置時間是否超出keepAliveBetweenTimeMillis(缺省值60s),若超出,則意味著該連接需要進行連接可用性檢查,則將該對象放入keepAliveConnections隊列。
兩個隊列賦值完成后,則池子會進行一次壓縮,沒有涉及到的連接對象會被壓縮到隊首。
然后就是處理evictConnections和keepAliveConnections兩個隊列了,evictConnections里的對象會被close最后釋放掉,keepAliveConnections里面的對象將會其進行檢測(流程參考流程1.3的isValidConnection),碰到不可用的連接會調用discard(流程1.4)拋棄掉,可用的連接會再次被放進連接池。
整個流程可以看出,連接閑置后,也并非一下子就減少到minIdle的,如果之前產生一堆的連接(不超過maxActive),突然閑置了下來,則至少需要花minEvictableIdleTimeMillis的時間才可以被移出連接池,如果一個連接閑置時間超過maxEvictableIdleTimeMillis則必定被回收,所以極端情況下(比如一個連接池從初始化后就沒有再被使用過),連接池里并不會一直保持minIdle個連接,而是一個都沒有,生產環境下這是非常不常見的,默認的maxEvictableIdleTimeMillis都有7h,除非是極度冷門的系統才會出現這種情況,而開啟keepAlive也不會推翻這個規則,keepAlive的優先級是低于maxEvictableIdleTimeMillis的,keepAlive只是保證了那些檢查中不需要被移出連接池的連接在指定檢測時間內去檢測其連接活性,從而決定是否放入池子或者直接discard。
#### 流程4.2:主動回收連接,防止內存泄漏
過程如下:
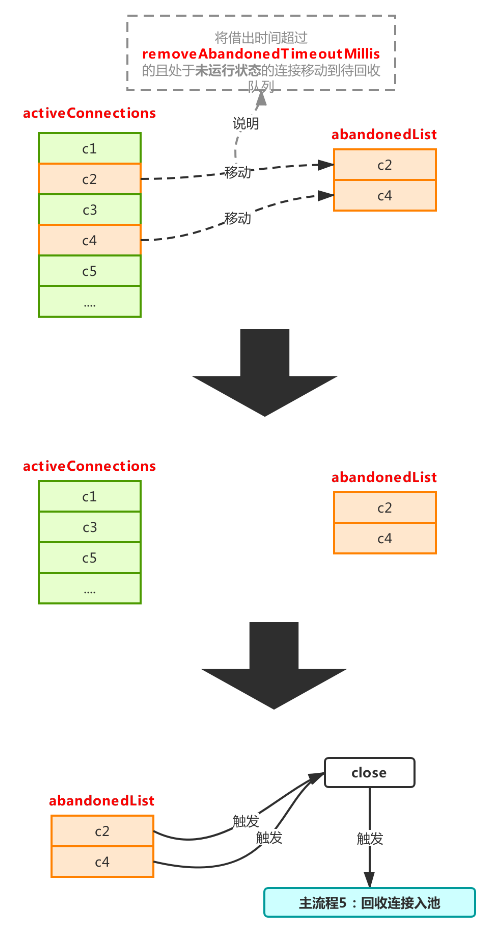
這個流程在removeAbandoned設置為true的情況下才會觸發,用于回收那些拿出去的使用長期未歸還(歸還:調用close方法觸發主流程5)的連接。
先來看看activeConnections是什么,activeConnections用來保存當前從池子里被借出去的連接,這個可以通過主流程1看出來,每次調用getConnection時,如果開啟removeAbandoned,則會把連接對象放到activeConnections,然后如果長期不調用close,那么這個被借出去的連接將永遠無法被重新放回池子,這是一件很麻煩的事情,這將存在內存泄漏的風險,因為不close,意味著池子會不斷產生新的連接放進connections,不符合連接池預期(連接池出發點是盡可能少的創建連接),然后之前被借出去的連接對象還有一直無法被回收的風險,存在內存泄漏的風險,因此為了解決這個問題,就有了這個流程,流程整體很簡單,就是將現在借出去還沒有歸還的連接,做一次判斷,符合條件的將會被放進abandonedList進行連接回收(這個list里的連接對象里的abandoned將會被置為true,標記已被該流程處理過,防止主流程5再次處理)。
這個如果在實踐中能保證每次都可以正常close,完全不用設置removeAbandoned=true,目前如果使用了類似mybatis、spring等開源框架,框架內部是一定會close的,所以此項是不建議設置的,視情況而定。
### 5.主流程:回收連接
這個流程通常是靠連接包裝類DruidPooledConnection的close方法觸發的,目標方法為recycle,流程圖如下:
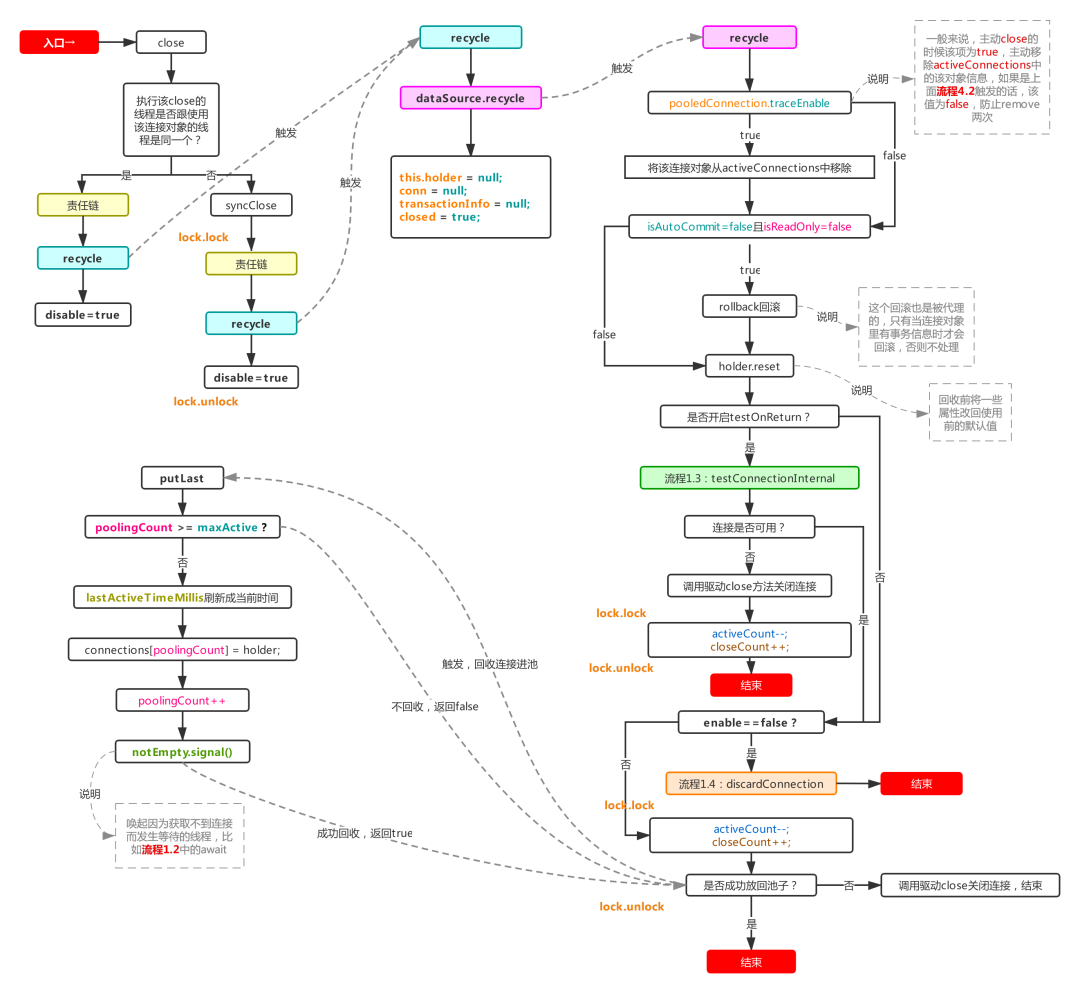
這也是非常重要的一個流程,連接用完要歸還,就是利用該流程完成歸還的動作,利用druid對外包裝的Connecion包裝類DruidPooledConnection的close方法觸發,該方法會通過自己內部的close或者syncClose方法來間接觸發dataSource對象的recycle方法,從而達到回收的目的。
最終的recycle方法:
①如果removeAbandoned被設置為true,則通過traceEnable判斷是否需要從activeConnections移除該連接對象,防止流程4.2再次檢測到該連接對象,當然如果是流程4.2主動觸發的該流程,那么意味著流程4.2里已經remove過該對象了,traceEnable會被置為false,本流程就不再觸發remove了(這個流程都是在removeAbandoned=true的情況下進行的,在主流程1里連接被放進activeConnections時traceEnable被置為true,而在removeAbandoned=false的情況下traceEnable恒等于false)。
②如果回收過程中發現存在有未處理完的事務,則觸發回滾(比較有可能觸發這一條的是流程4.2里強制歸還連接,也有可能是單純使用連接,開啟事務卻沒有提交事務就直接close的情況),然后利用holder.reset進行恢復連接對象里一些屬性的默認值,除此之外,holder對象還會把由它產生的statement對象放到自己的一個arraylist里面,reset方法會循環著關閉內部未關閉的statement對象,最后清空list,當然,statement對象自己也會記錄下其產生的所有的resultSet對象,然后關閉statement時同樣也會循環關閉內部未關閉的resultSet對象,這是連接池做的一種保護措施,防止用戶拿著連接對象做完一些操作沒有對打開的資源關閉。
③判斷是否開啟testOnReturn,這個跟testOnBorrow一樣,官方默認不開啟,也不建議開啟,影響性能,理由參考主流程1里針對testOnBorrow的解釋。
④直接放回池子(當前connections的尾部),然后需要注意的是putLast方法和put方法的不同之處,putLast會把lastActiveTimeMillis置為當前時間,也就是說不管一個連接被借出去過久,只要歸還了,最后活躍時間就是當前時間,這就會有造成某種特殊異常情況的發生(非常極端,幾乎不會觸發,可以選擇不看):
如果不開啟testOnBorrow和testOnReturn,并且keepAlive設置為false,那么長連接可用測試的間隔依據就是利用當前時間減去上次活躍時間(lastActiveTimeMillis)得出閑置時間,然后再利用閑置時間跟timeBetweenEvictionRunsMillis(默認60s)進行對比,超過才進行長連接可用測試。
那么如果一個mysql服務端的長連接保活時間被人為調整為60s,然后timeBetweenEvictionRunsMillis被設置為59s,這個設置是非常合理的,保證了測試間隔小于長連接實際保活時間,然后如果這時一個連接被拿出去后一直過了61s才被close回收,該連接對象的lastActiveTimeMillis被刷為當前時間,如果在59s內再次拿到該連接對象,就會繞過連接檢查直接報連接不可用的錯誤。
### 10.結束
以上針對druid連接池的初始化以及其內部一個連接從生產到消亡的整個流程就已經整理完了,主要是列出其運行流程以及一些主要的監控數據都是如何產生的,沒有涉及到的是一個sql的執行,因為這個基本上就跟使用原生驅動程序差不多,只是druid又包裝了一層Statement等,用于完成一些自己的操作。
## mybatis-plus介紹
* MyBatis 是一款優秀的持久層框架,其目的是想當做互聯網的籬笆墻,圍繞著數據庫提供持久化服務的一個框架,支持自定義 SQL、存儲過程及高級映射。
* MyBatis 免除了幾乎所有的 JDBC 代碼以及設置參數和獲取結果集的工作,還可以通過簡單的 XML 或注解來配置和映射原始類型、接口和 Java POJO(Plain Ordinary Java Object,普通 Java 對象)為數據庫中的記錄。
* [MyBatis-Plus](https://github.com/baomidou/mybatis-plus)(簡稱 MP)是一個[MyBatis](http://www.mybatis.org/mybatis-3/)的增強工具,在 MyBatis 的基礎上只做增強不做改變,為簡化開發、提高效率而生。
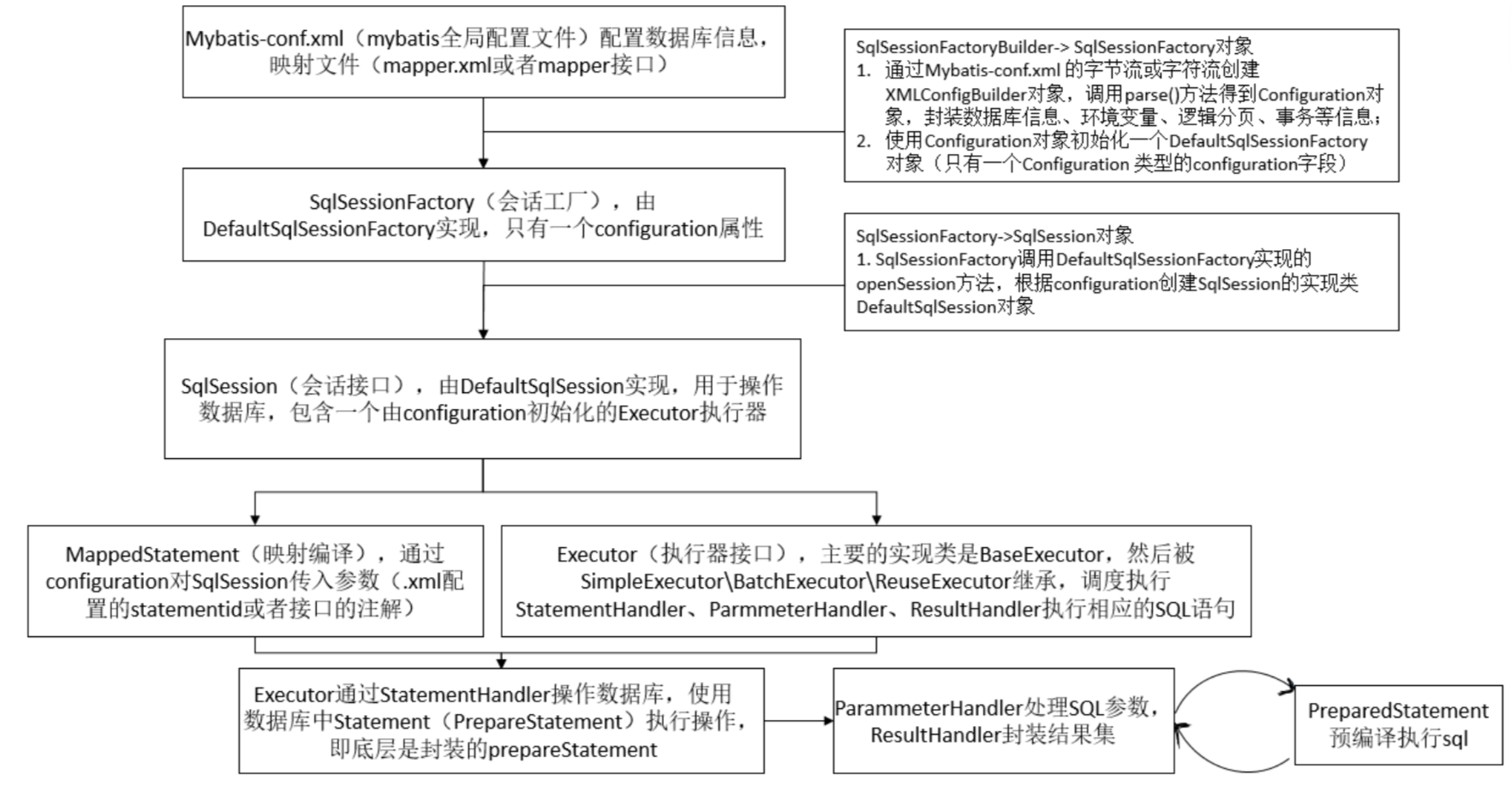
### mybatis原理
### mybatis-plus配置方式
配置mybatis-plus全局配置,是否關閉啟動mybatis-plus圖標,id生成策略,掃描mapper.xml位置
```
mybatis-plus:
mapper-locations: com/open/**/mapper/*Mapper.xml
#實體掃描,多個package用逗號或者分號分隔
typeAliasesPackage: com.open.capacity.common.model
global-config:
banner: false
db-config:
id-type: auto
```
### mybatis-plus簡單使用
## sharding-jdbc介紹
Sharding-JDBC是ShardingSphere的第一個產品,也是ShardingSphere的前身。 它定位為輕量級Java框架,在Java的JDBC層提供的額外服務。它使用客戶端直連數據庫,以jar包形式提供服務,無需額外部署和依賴,可理解為增強版的JDBC驅動,完全兼容JDBC和各種ORM框架。
* 適用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
* 支持任何第三方的數據庫連接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
* 支持任意實現JDBC規范的數據庫。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92標準的數據庫。
### sharding配置
shardingjdbc配置默認屬于,采用雪花算法生成id方式
```
spring:
shardingsphere:
enabled: false
sharding:
default-data-source-name: ds0
default-key-generator:
column: id
props:
worker:
id: ${workerId}
type: SNOWFLAKE
datasource:
names: ds0
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://${ocp.datasource.ip:192.168.92.216}:3306/user-center?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai
username: ${ocp.datasource.username}
password: ${ocp.datasource.password}
#初始化時建立物理連接的個數。初始化發生在顯示調用init方法,或者第一次getConnection時
initial-size: 5
#最大連接數
max-active: 50
#最小連接數
min-idle: 5
#獲取連接時最大等待時間,單位毫秒。配置了maxWait之后,缺省啟用公平鎖,并發效率會有所下降,如果需要可以通過配置useUnfairLock屬性為true使用非公平鎖。
max-wait: 60000
#用來檢測連接是否有效的sql,要求是一個查詢語句,常用select 'x'。如果validationQuery為null,testOnBorrow、testOnReturn、testWhileIdle都不會起作用。
validation-query: SELECT 1 FROM DUAL
#單位:秒,檢測連接是否有效的超時時間。底層調用jdbc Statement對象的void setQueryTimeout(int seconds)方法
validation-query-timeout: 5
#建議配置為true,不影響性能,并且保證安全性。申請連接的時候檢測,如果空閑時間大于timeBetweenEvictionRunsMillis,執行validationQuery檢測連接是否有效。
test-while-idle: true
#申請連接時執行validationQuery檢測連接是否有效,做了這個配置會降低性能。
test-on-borrow: false
#歸還連接時執行validationQuery檢測連接是否有效,做了這個配置會降低性能。
test-on-return: false
#有兩個含義: 1) Destroy線程會檢測連接的間隔時間,如果連接空閑時間大于等于minEvictableIdleTimeMillis則關閉物理連接。 2) testWhileIdle的判斷依據,詳細看testWhileIdle屬性的說明
time-between-eviction-runs-millis: 60000
# 連接保持空閑而不被驅逐的最小時間
min-evictable-idle-time-millis: 300000
#連接池中的minIdle數量以內的連接,空閑時間超過minEvictableIdleTimeMillis,則會執行keepAlive操作。
keep-alive: true
# 通過connectProperties屬性來打開mergeSql功能;慢SQL記錄
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 合并多個DruidDataSource的監控數據
useGlobalDataSourceStat: true
#是否緩存preparedStatement,也就是PSCache。PSCache對支持游標的數據庫性能提升巨大,比如說oracle。在mysql下建議關閉。
pool-prepared-statements: false
#要啟用PSCache,必須配置大于0,當大于0時,poolPreparedStatements自動觸發修改為true。在Druid中,不會存在Oracle下PSCache占用內存過多的問題,可以把這個數值配置大一些,比如說100
max-pool-prepared-statement-per-connection-size: 100
#是否到期強制刪除,避免某個連接長時間阻塞無法回收
remove-abandoned: true
#租用時長,Druid避免連泄露 s
remove-abandoned-timeout: 120
# 配置監控統計攔截的filters,去掉后監控界面sql無法統計,'wall'用于防火墻
filters: stat,wall
#合并多個DruidDataSource的監控數據
use-global-data-source-stat: false
#配置stat-view-servlet
stat-view-servlet:
#允許開啟監控
enabled: true
#監控面板路徑
url-pattern: /druid/*
```
### shardingjdbc雪花id生成配置
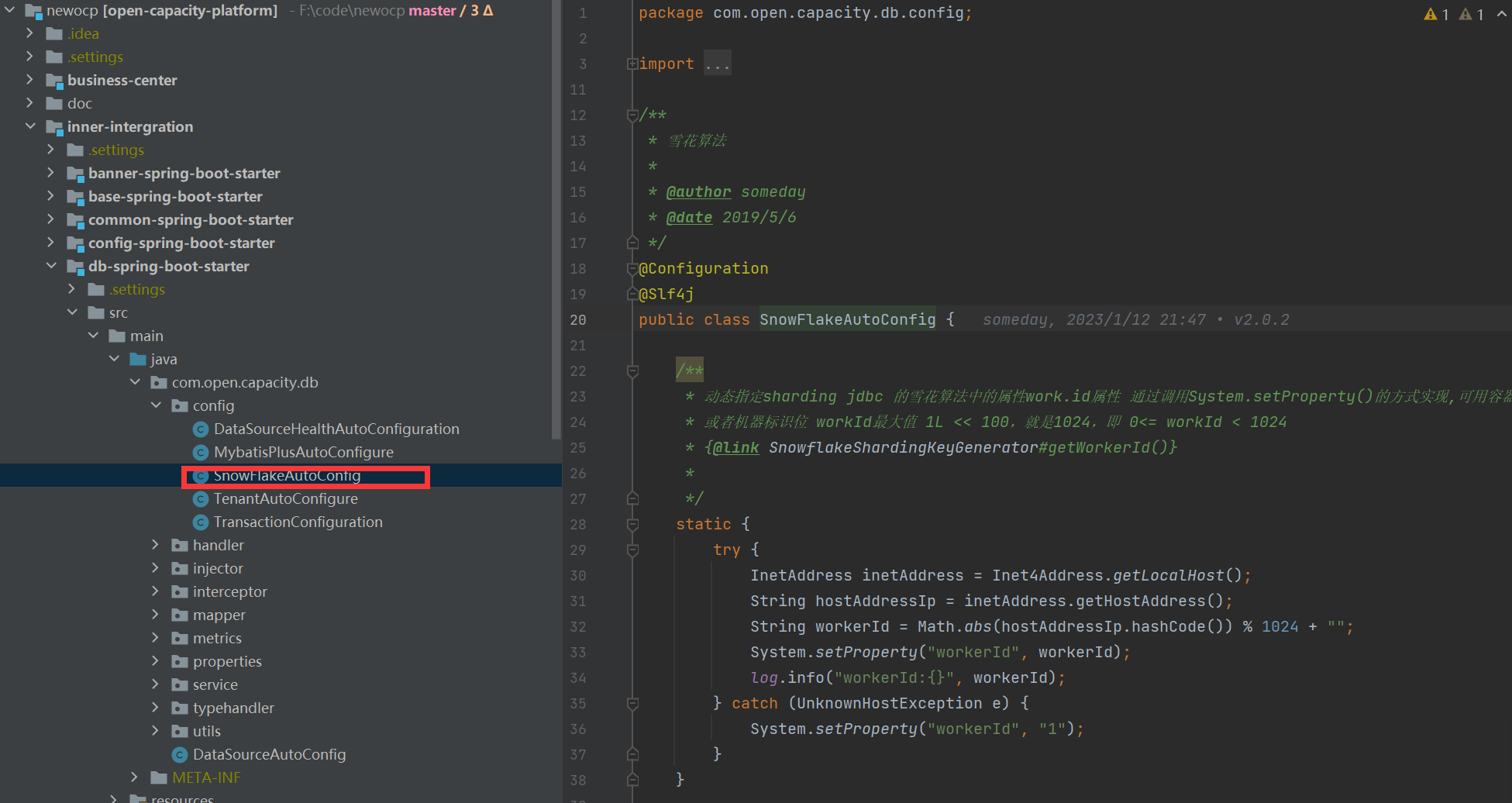
```
spring:
shardingsphere:
enabled: false
sharding:
default-data-source-name: ds0
default-key-generator:
column: id
props:
worker:
id: ${workerId}
type: SNOWFLAKE
```
## 字段填充
配置自動填充創建時間修改時間
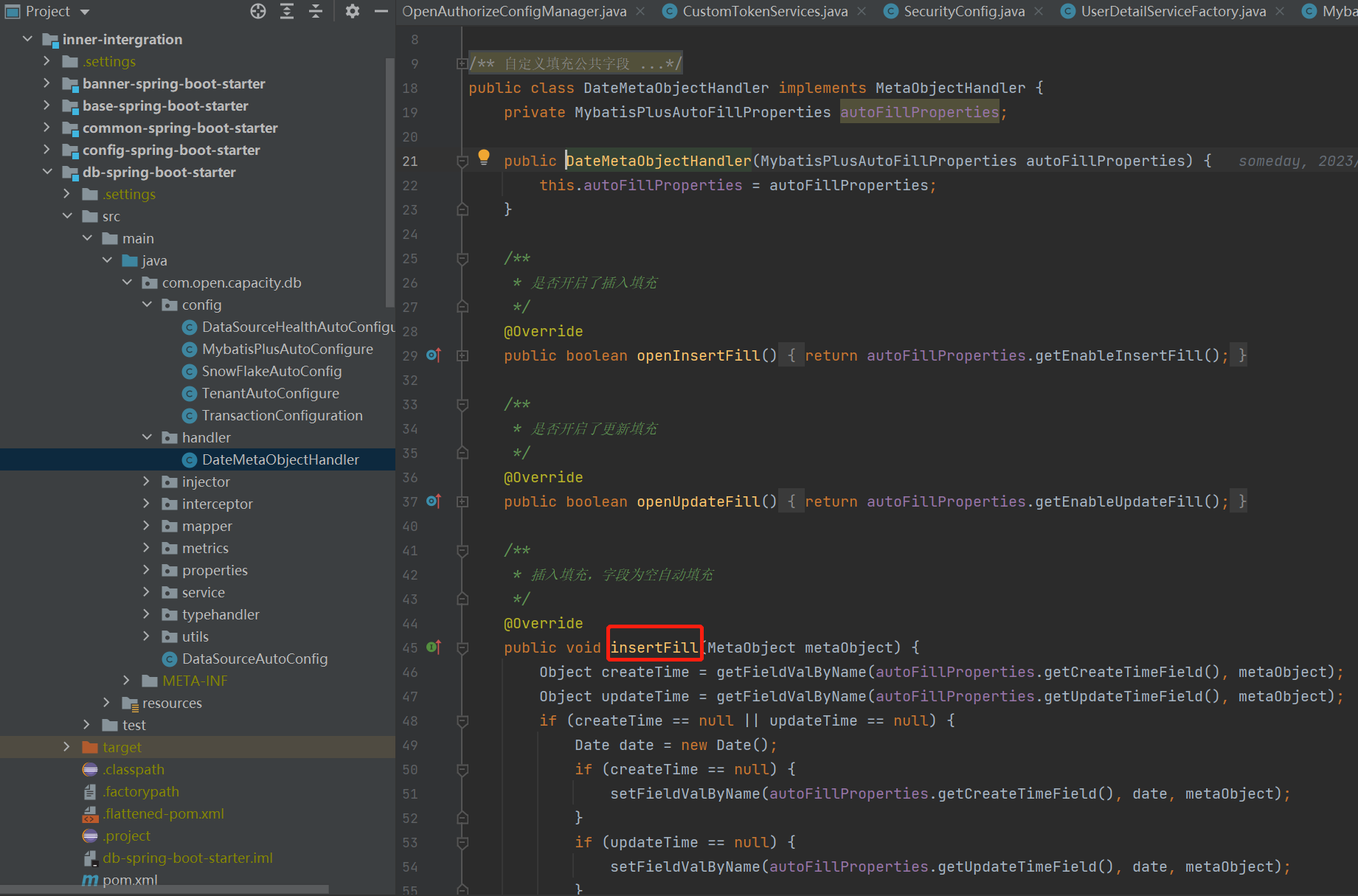
## 多租戶應用隔離
當不同的租戶使用同一套程序,這里就需要考慮一個數據隔離的情況。
數據隔離有三種方案:
獨立數據庫:簡單來說就是一個租戶使用一個數據庫,這種數據隔離級別最高,安全性最好,但是提高成本。
共享數據庫、隔離數據架構:多租戶使用同一個數據褲,但是每個租戶對應一個Schema(數據庫user)。
共享數據庫、共享數據架構:使用同一個數據庫,同一個Schema,但是在表中增加了租戶ID的字段,這種共享數據程度最高,隔離級別最低。平臺采用mybatis-plus多租戶插件,進行oauth體系的應用隔離方式。
* 不同應用系統之間是完全隔離的!!!
* 啟用多租戶后所有執行的method的sql都會進行處理.
* 自寫的sql請按規范書寫(sql涉及到多個表的每個表都要給別名,特別是 inner join 的要寫標準的 inner join)
### 多租插件介紹

### 租戶自動裝配
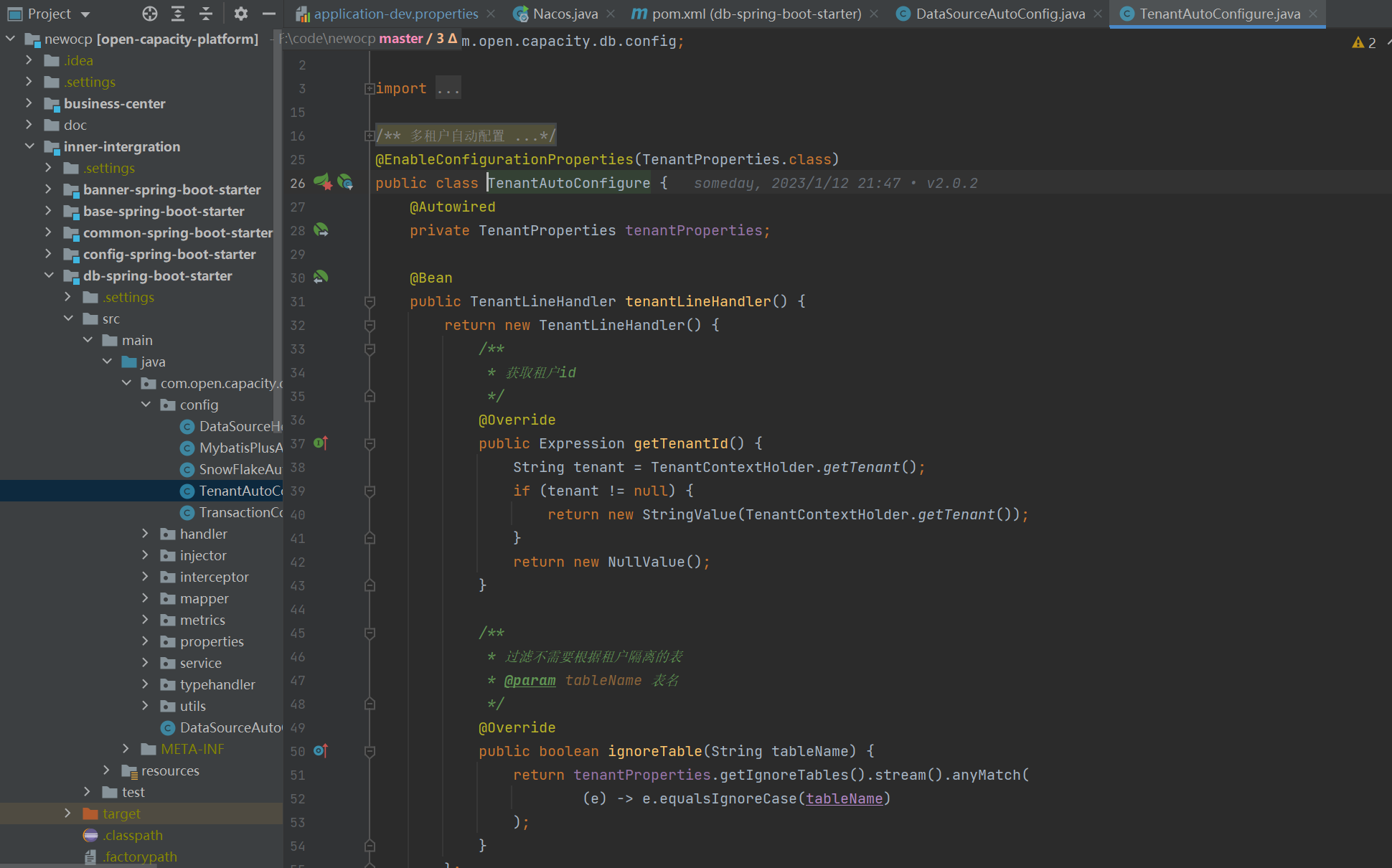
### 多租戶攔截器
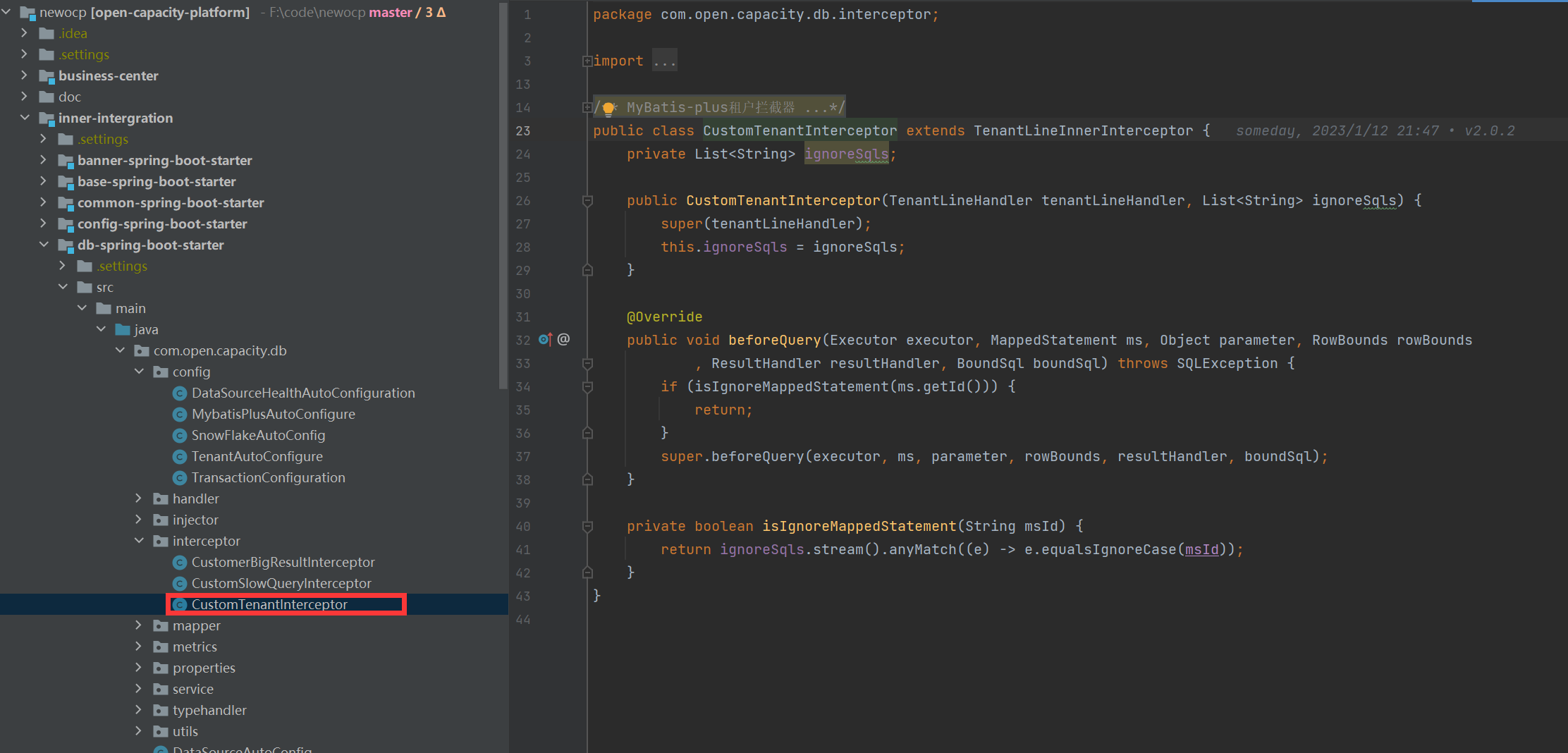
### 租戶配置
```
ocp:
#多租戶配置
tenant:
enable: true
ignoreTables:
- sys_user
- sys_role_user
- sys_role_menu
ignoreSqls:
# 用戶關聯角色時,顯示所有角色
- SysRoleMapper.findAll
# 用戶列表顯示用戶所關聯的所有角色
- SysUserRoleMapper.findRolesByUserIds
```
## sql執行時間監控插件
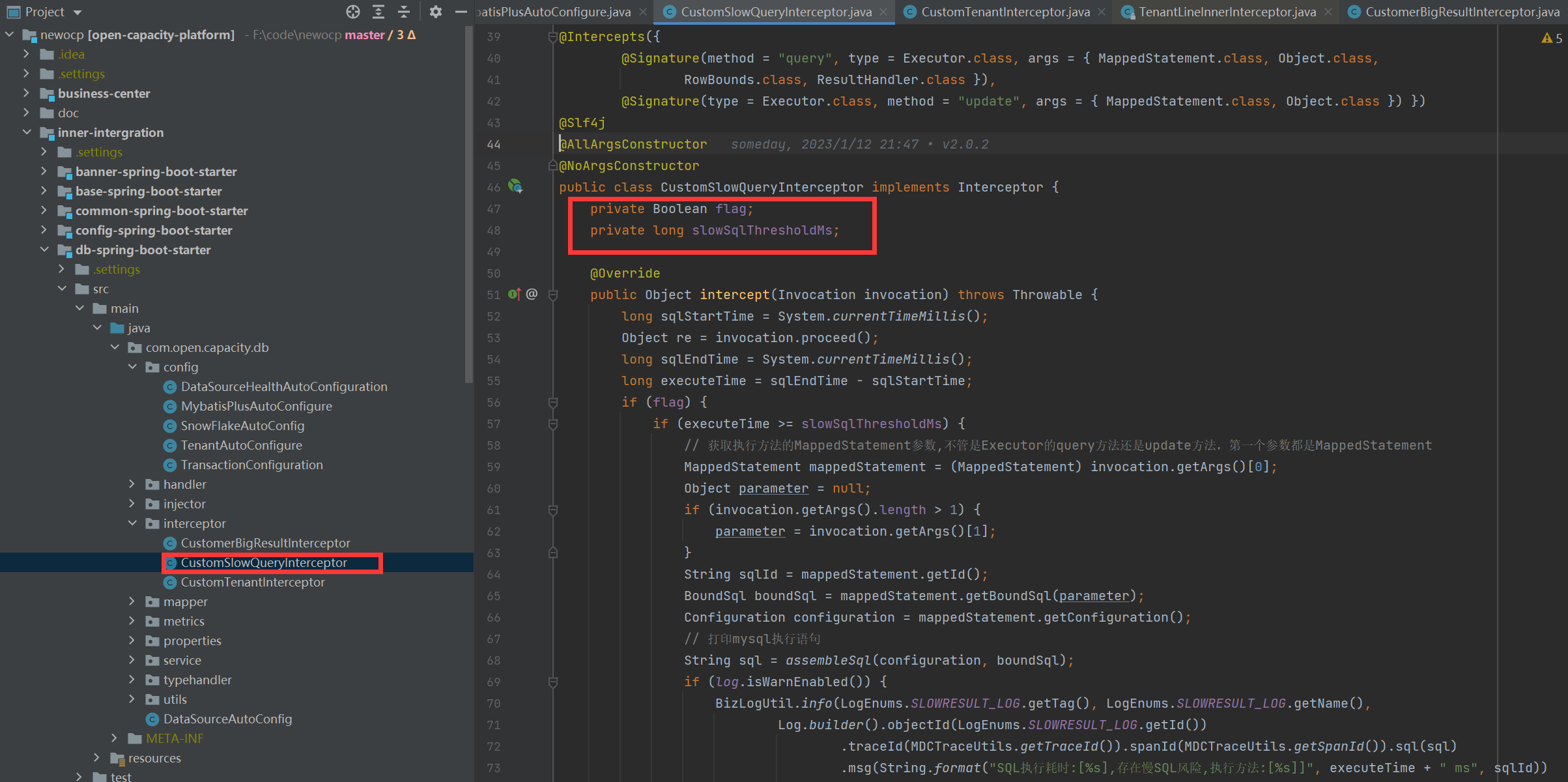
系統運行期間,可能存在一些性能較差的sql語句,平臺需要對這種語句進行監控打印,盡快發現平臺sql瓶頸進行優化,對此平臺采用自定義sql執行時間監控插件方式進行集成。
### 時間監控代碼處理
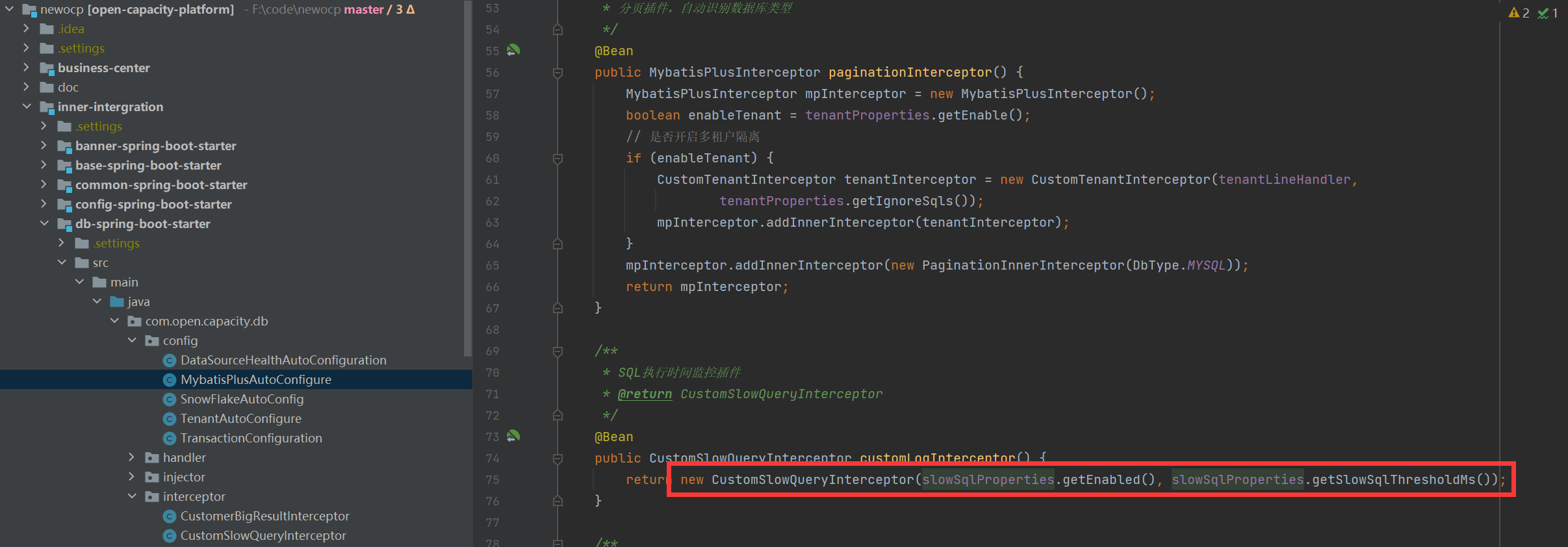
### 時間監控自動裝配
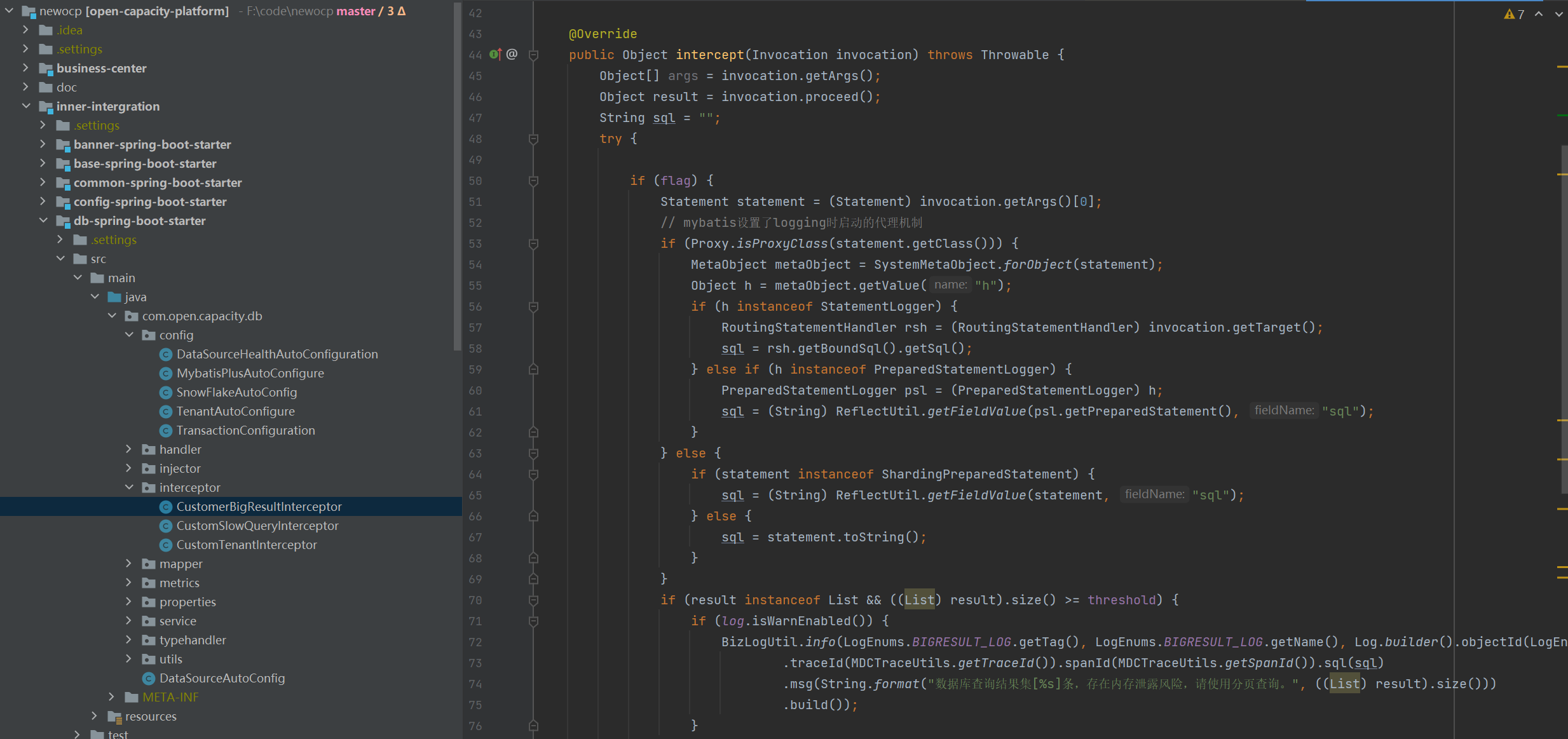
## 查詢大結果集監控插件
系統運行期間,需要對一些查詢大表結果集進行監控,查詢是否需要分頁分批處理進行優化,防止查詢大結果集導致oom風險。
## 敏感數據脫敏插件
在某些單位中,安全評測要求十分嚴格,要求存儲到數據庫中的數據需要脫敏,同時程序還可以進行like查詢,平臺采用以下方式進行數據存儲脫敏。
### 使用方法
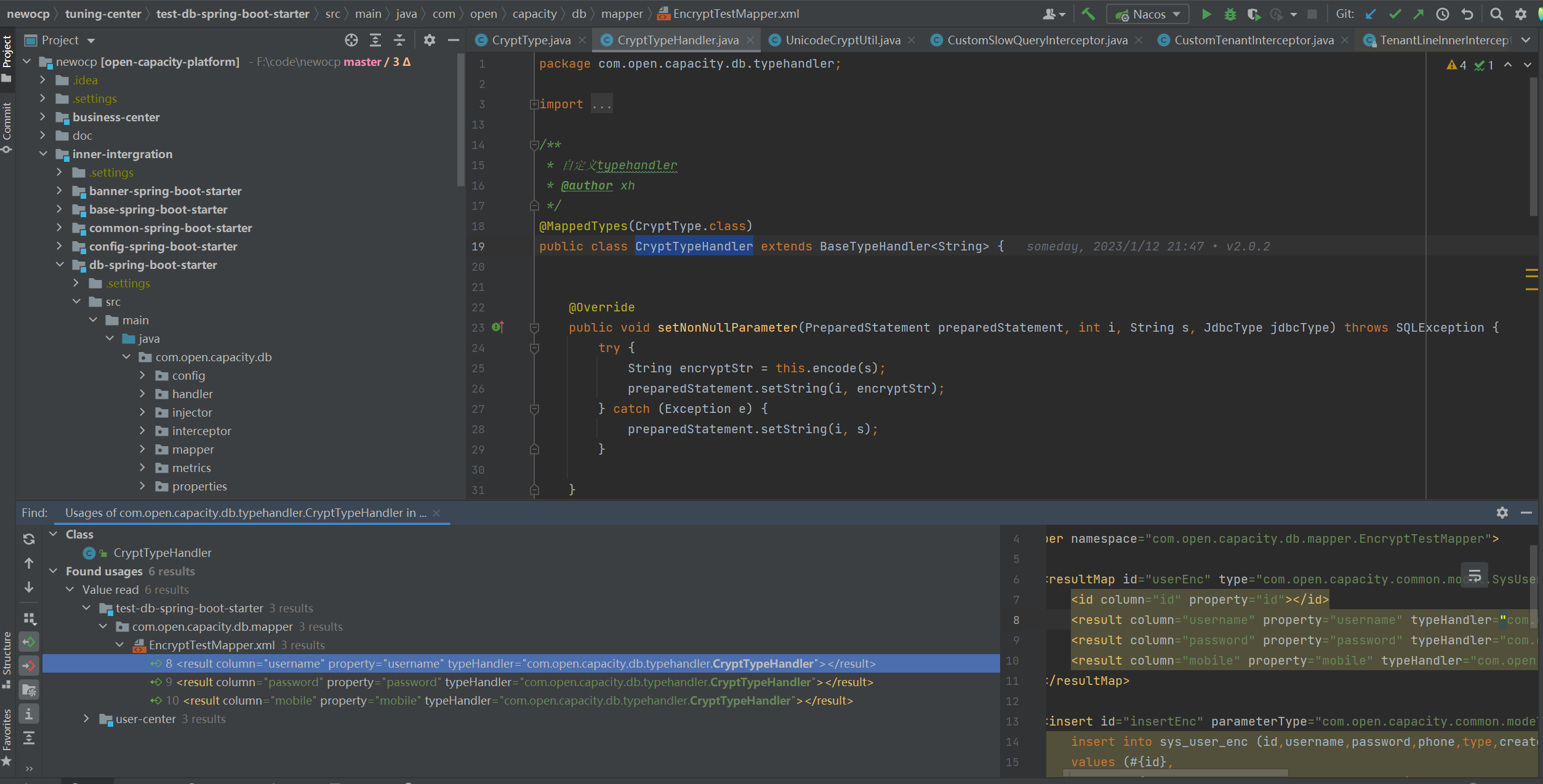
## Guava
Guava 還提供了很多實用工具,如 Lists、Maps、Sets,接下來我們分別來看下這些常用工具的使用和原理。
* List list = Lists.newArrayList();
* Map hashMap = Maps.newHashMap();
這種寫法其實就是一種簡單的工廠模式
~~~
// 可以預估 list 的大小為 20
List<String> list = Lists.newArrayListWithCapacity(20);
List<String> list = Lists.newArrayListWithExpectedSize(20);
Map<String,String> hashMap = Maps.newHashMap();
Map<String,String> linkedHashMap = Maps.newLinkedHashMap();
Map<String,String> withExpectedSizeHashMap = Maps.newHashMapWithExpectedSize(20);
~~~
Guava 還提供了提供了一些異常處理的靜態方法
~~~
Throwables.throwIfUnchecked(new RuntimeException("模擬業務出錯"));
~~~
## db-spring-boot-starter自動裝配原理解析
咱們想想,在不同項目中,咱們的項目是如何使用db-spring-boot-starter裝配這些對象的嗎?下面咱們需要揭密。
* db-spring-boot-starter 中定義了spring.factories文件
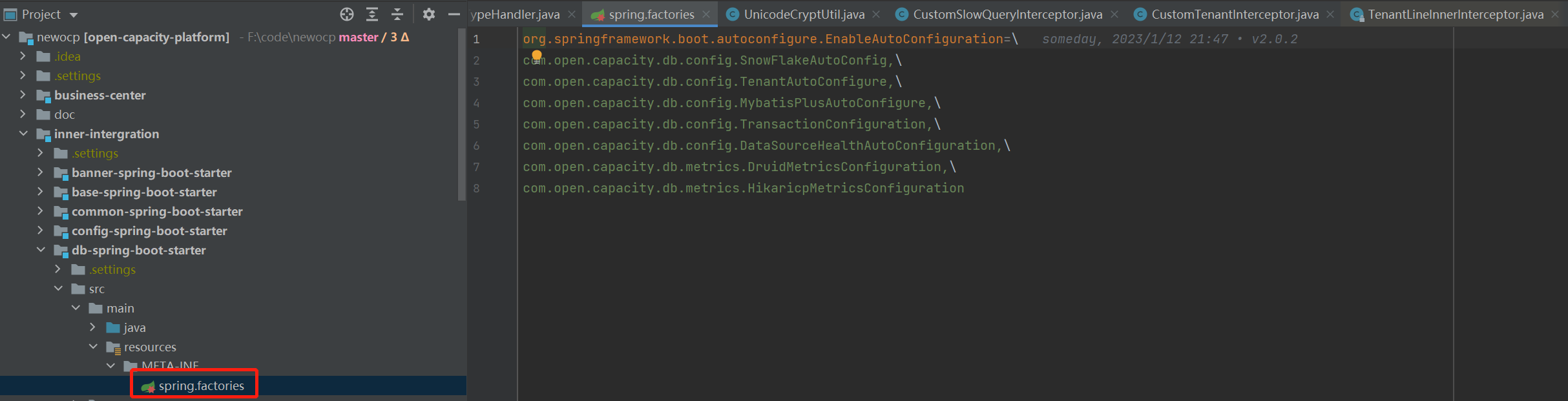
那么這些文件是如何完成加載到spring容器的呢? 此時,咱們必須回到user-center,閱讀源碼
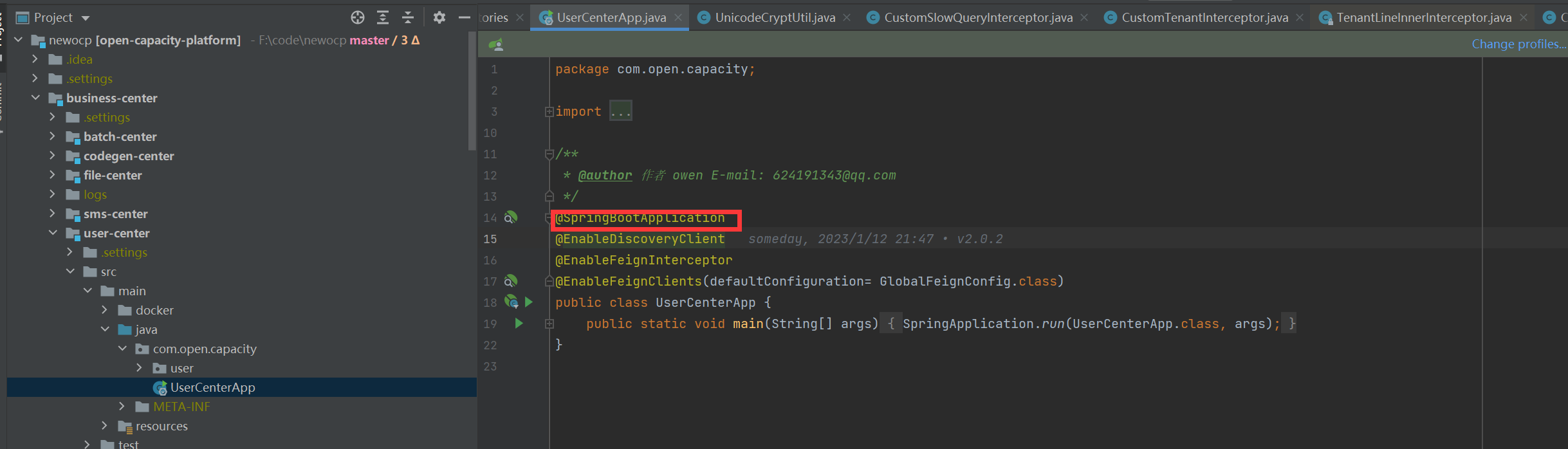
* @SpringBootApplication
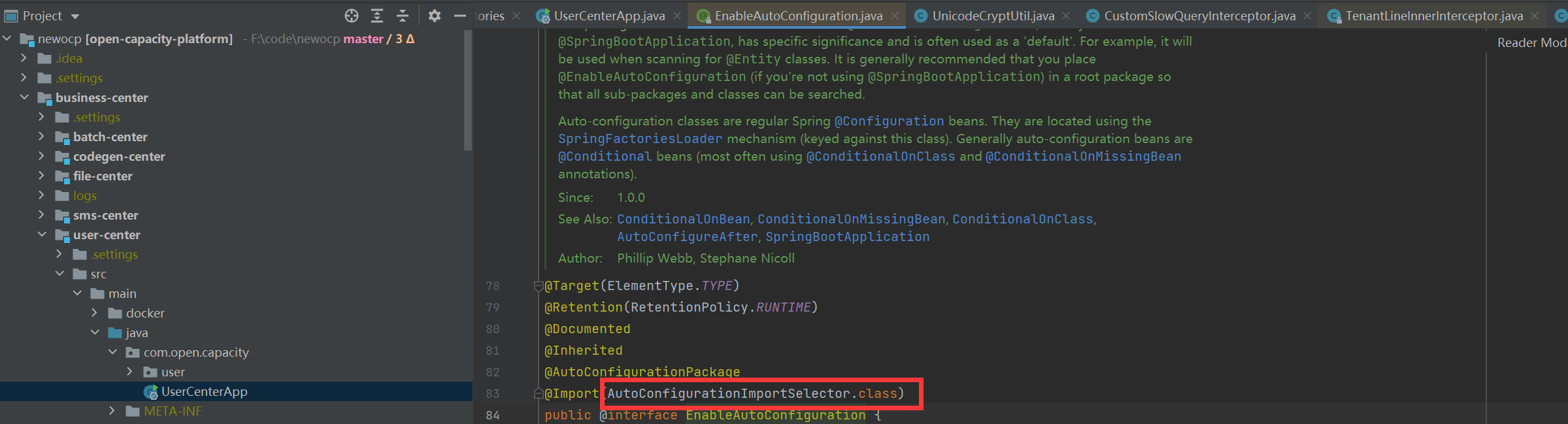
* @EnableAutoConfiguration
* AutoConfigurationImportSelector
閱讀到這里,我們了解到,user-center在啟動時,由于@SpringBootApplication是復合注解,包含@EnableAutoConfiguration,這個類中@import了核心處理類AutoConfigurationImportSelector,這個類的核心就是將classpath中搜索所有META-INF/spring.factories配置文件,并且將其中org.springframework.boot.autoconfigure.EnableAutoConfiguration key對應的配置項加載到spring容器,所以在user-center啟動的時候自動裝配了db-spring-boot-starter中的配置信息類。
## 總結
通過微內核spi的方式構建db-spring-boot-starter模塊提供平臺級數據庫通用功能。
- 01.前言
- 02.快速開始
- 01.maven構建項目
- 02.安裝mysql數據庫
- 03.安裝redis緩存中間件
- 04.快速啟動框架
- 03.總體流程
- 01.架構設計圖
- 02.oauth接口
- 03.功能介紹
- 04.部署細節
- 04.模塊詳解
- 01.基礎介紹
- 02.自定義db-spring-boot-starter
- 03.自定義log-spring-boot-starter
- 04.自定義redis-spring-boot-starter
- 05.自定義base-spring-boot-starter
- 06.自定義common-spring-boot-starter
- 07.自定義loadbalancer-spring-boot-starter
- 08.自定義swagger-spring-boot-starter
- 09.自定義uaa-client-spring-boot-starter
- 10.自定義uaa-server-spring-boot-starter
- 11.自定義oss-spring-boot-starter
- 12.自定義sentinel-spring-boot-starter
- 05.服務詳解
- 01.nacos-server
- 02.auth-server
- 03.user-center
- 04.new-api-gateway
- 05.file-center
- 06.log-center
- 07.back-center
- 08.auth-sso模塊
- 09.admin-server
- 10.job-center
- 06.系統安全
- 01.非法字符漏洞攻擊
- 02.防重放攻擊
- 03.代碼審計
- 04.Xray掃洞
- 05.混沌工程質量保證
- 07.生產部署K8S
- 01.基本環境安裝
- 02.基本組件安裝
- 03.集群驗證
- 04.安裝Metrics Server
- 05.安裝容器平臺
- 06.Ingress網關
- 07.metalb負載均衡器
- 08.容器平臺集群
- 08.K8S資源練習
- 01.Deployment
- 02.StatefulSet
- 03.DaemonSet
- 04.redis集群服務
- 05.elasticsearch集群
- 06.rocketmq部署
- 09.生產容器化部署
- 01.nacos集群部署
- 02.user-center服務
- 03.auth-server服務
- 04.new-api-gateway服務
- 技術交流