[TOC]
# redis-spring-boot-starter
redis-spring-boot-starter 通過autoconfig微內核結合redis api提供了通用緩存能力。采用Redis官方推薦的Java版的Redis客戶端Redisson提供了非常強大的功能,利用spring Cache與redis的擴展結合簡化了緩存的使用難度。
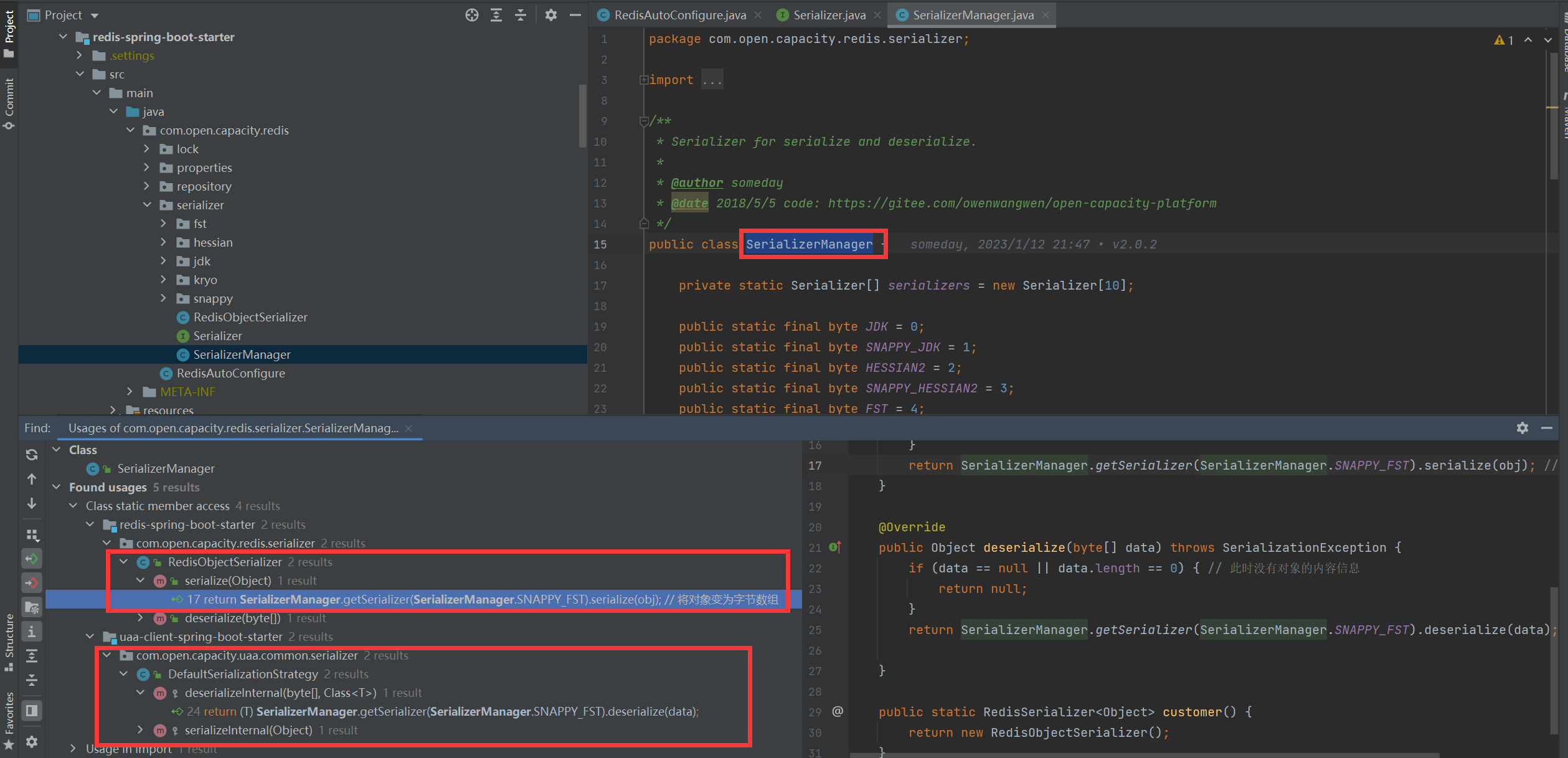
## 序列化反序列化
* 在Java應用的開發中,需要將Java對象實例保存在Redis中,常用方法有兩種:
1. 將對象序列化成字符串后存入Redis;
2. 將對象序列化成byte數組后存入Redis;
通過以上的用戶情景,結合目前主流的序列化框架封裝了一套平臺統一的序列化方案。
### 測試腳本
~~~
public static void main(String[] args) {
Map map = new HashMap();
for (int i = 0; i <= 100; i++) {
map.put("a" + i, "a" + i);
}
Serializer jdkSerializer = SerializerManager.getSerializer(SerializerManager.JDK);
Serializer hessianSerializer = SerializerManager.getSerializer(SerializerManager.HESSIAN2);
Serializer fstObjectSerializer = SerializerManager.getSerializer(SerializerManager.FST);
Serializer snappyFstObjectSerializer = SerializerManager.getSerializer(SerializerManager.SNAPPY_FST);
long size = 0;
long time1 = System.currentTimeMillis();
byte[] jdkserialize = null;
byte[] redisserialize = null;
byte[] kryoserialize = null;
for (int i = 0; i < 1000000; i++) {
jdkserialize = jdkSerializer.serialize(map);
size += jdkserialize.length;
}
System.out.println("原生序列化方案[序列化100000次]耗時:" + (System.currentTimeMillis() - time1) + "ms size:=" + size);
long time2 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
Map aa = (Map) jdkSerializer.deserialize(jdkserialize);
}
System.out.println("原生序列化方案[反序列化100000次]耗時:" + (System.currentTimeMillis() - time2) + "ms size:=" + size);
long time3 = System.currentTimeMillis();
size = 0;
for (int i = 0; i < 1000000; i++) {
redisserialize = hessianSerializer.serialize(map);
size += redisserialize.length;
}
System.out.println("hessian序列化方案[序列化100000次]耗時:" + (System.currentTimeMillis() - time3) + "ms size:=" + size);
long time4 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
Map aa = (Map) hessianSerializer.deserialize(redisserialize);
}
System.out.println("hessian序列化方案[反序列化100000次]耗時:" + (System.currentTimeMillis() - time4) + "ms size:=" + size);
long time5 = System.currentTimeMillis();
size = 0;
for (int i = 0; i < 1000000; i++) {
kryoserialize = fstObjectSerializer.serialize(map);
size += kryoserialize.length;
}
System.out.println("fst序列化方案[序列化100000次]耗時:" + (System.currentTimeMillis() - time5) + "ms size:=" + size);
long time6 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
Map aa = (Map) fstObjectSerializer.deserialize(kryoserialize);
}
System.out.println("fst序列化方案[反序列化100000次]耗時:" + (System.currentTimeMillis() - time6) + "ms size:=" + size);
long time7 = System.currentTimeMillis();
size = 0;
for (int i = 0; i < 1000000; i++) {
kryoserialize = snappyFstObjectSerializer.serialize(map);
size += kryoserialize.length;
}
System.out.println("SNAPPY fst序列化方案[序列化100000次]耗時:" + (System.currentTimeMillis() - time5) + "ms size:=" + size);
long time8 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
Map aa = (Map) snappyFstObjectSerializer.deserialize(kryoserialize);
}
System.out.println("SNAPPY fst反序列化方案[反序列化100000次]耗時:" + (System.currentTimeMillis() - time8) + "ms size:=" + size);
}
~~~
### 結構報告
原生序列化方案[序列化100000次]耗時:15173ms size:=1276000000
原生序列化方案[反序列化100000次]耗時:18906ms size:=1276000000
hessian序列化方案[序列化100000次]耗時:11890ms size:=792000000
hessian序列化方案[反序列化100000次]耗時:6443ms size:=792000000
fst序列化方案[序列化100000次]耗時:4947ms size:=995000000
fst序列化方案[反序列化100000次]耗時:6757ms size:=995000000
SNAPPY fst序列化方案[序列化100000次]耗時:19161ms size:=491000000
SNAPPY fst反序列化方案[反序列化100000次]耗時:8159ms size:=491000000
## 分布式鎖
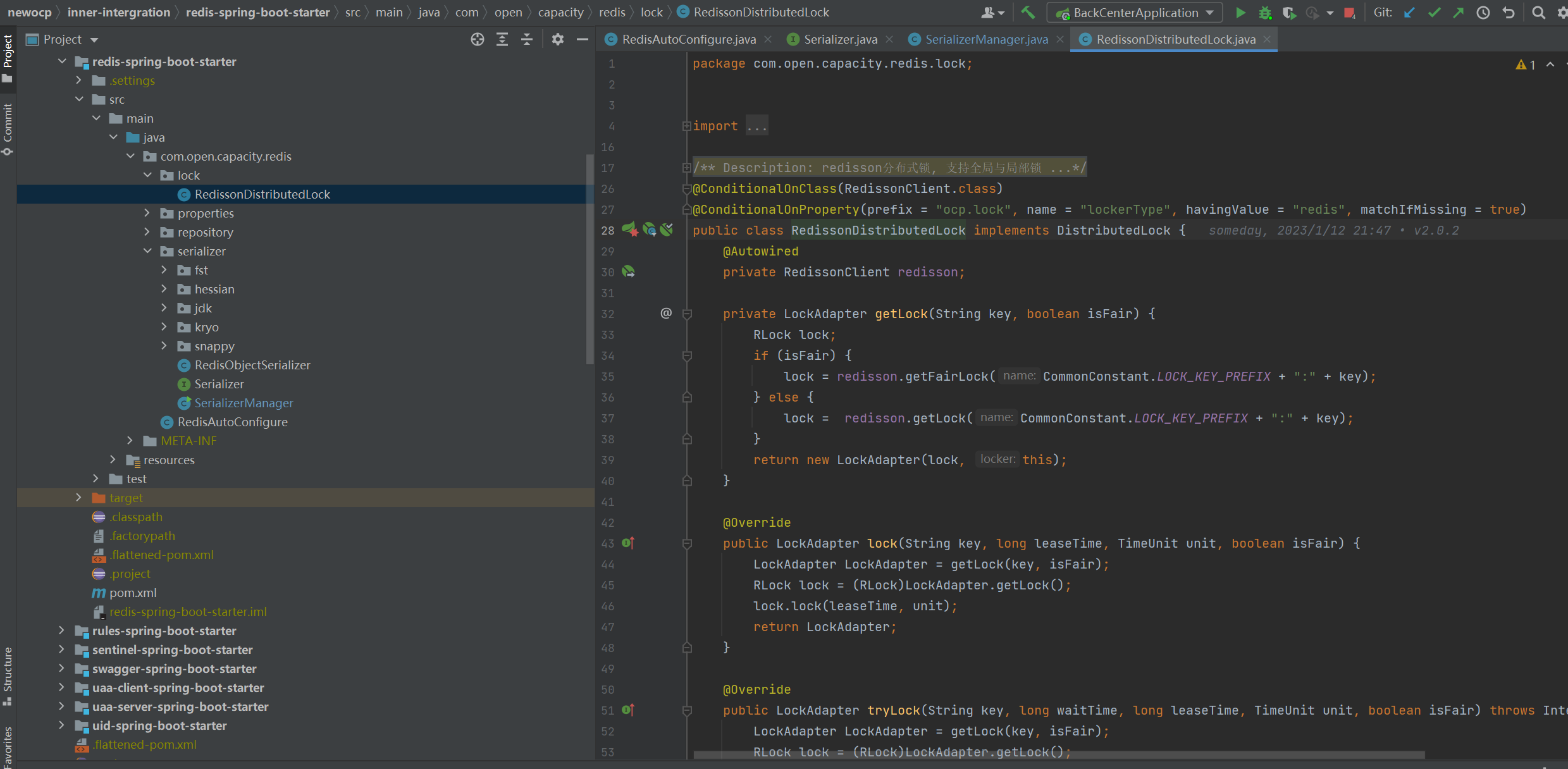
### 過程:
redisson分布式鎖實現細節:
* redisson所有指令都通過lua腳本執行,redis支持lua腳本原子性執行
* redisson設置一個key的默認過期時間為30s,如果某個客戶端持有一個鎖超過了30s怎么辦? redisson中有一個watchdog的概念,翻譯過來就是看門狗,它會在你獲取鎖之后,每隔10秒幫你把key的超時時間設為30s 這樣的話,就算一直持有鎖也不會出現key過期了,其他線程獲取到鎖的問題了。
* redisson的“看門狗”邏輯保證了沒有死鎖發生。 (如果機器宕機了,看門狗也就沒了。此時就不會延長key的過期時間,到了30s之后就會自動過期了,其他線程可以獲取到鎖)
### 代碼分析
* 獲取鎖
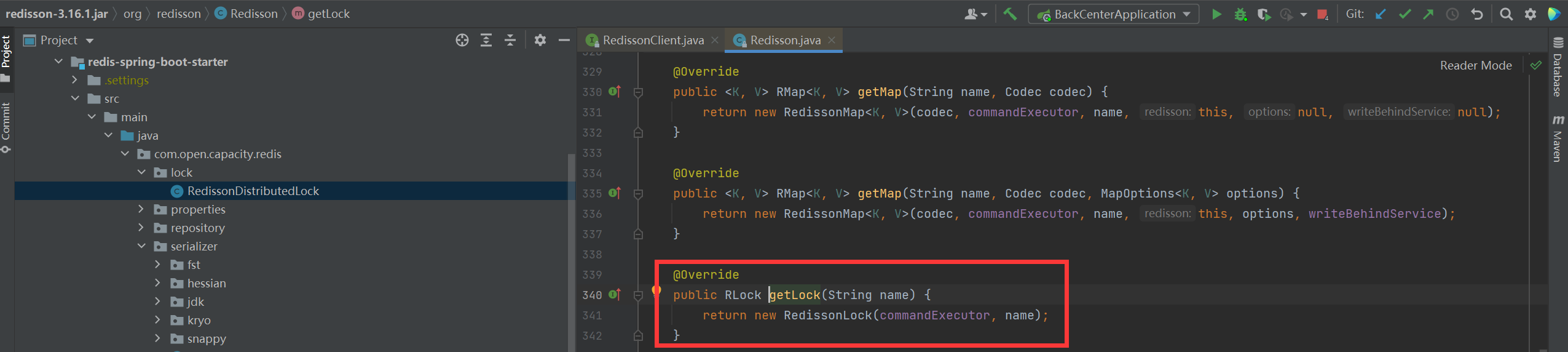
* 加鎖
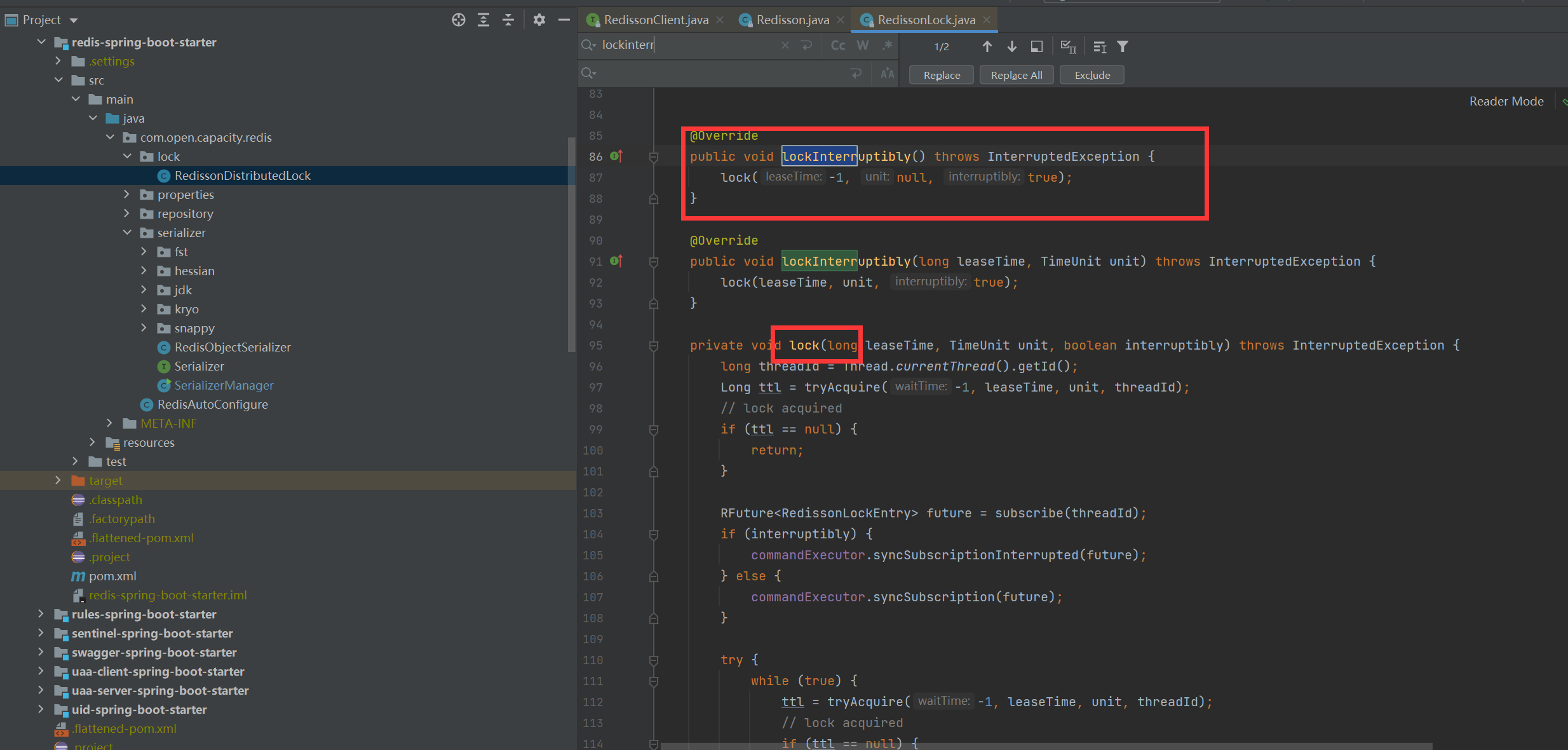
> 在RedissonLock對象的lock()方法主要調用tryAcquire()方法,由于leaseTime == -1,于是走tryLockInnerAsync()方法
* 加鎖細節
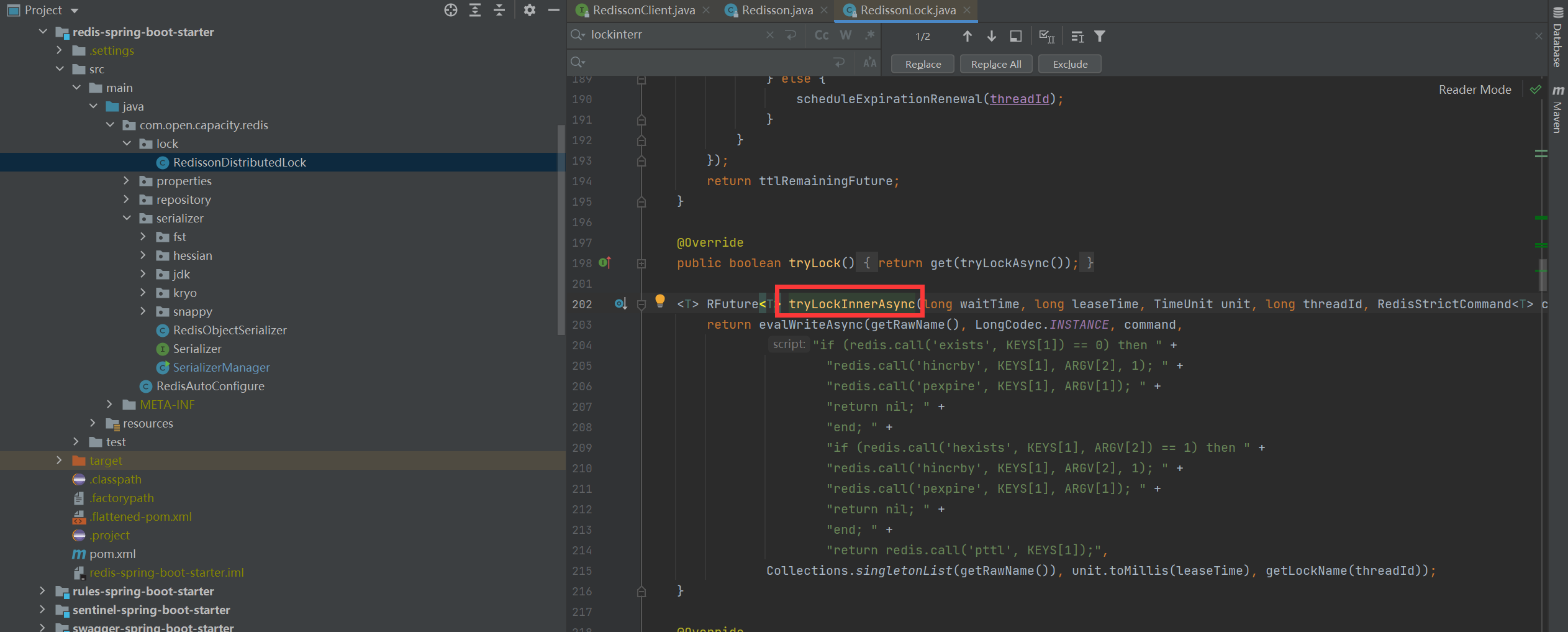
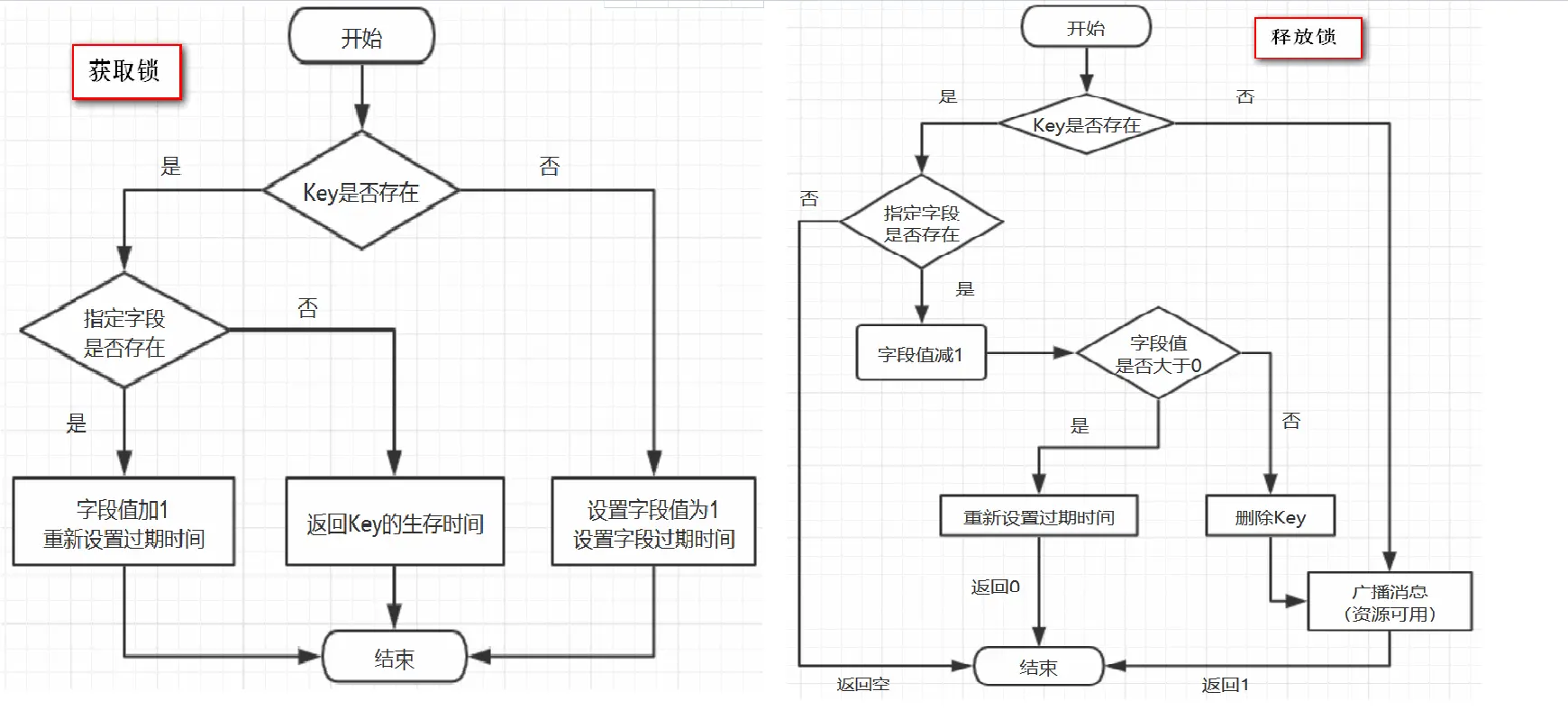
> 結合上面的參數聲明,我們可以知道,這里KEYS\[1\]就是getName(),ARGV\[2\]是getLockName(threadId),假設前面獲取鎖時傳的name是“anyLock”,假設調用的線程ID是Thread-1,假設成員變量UUID類型的id是85b196ce-e6f2-42ff-b3d7-6615b6748b5d:65那么KEYS\[1\]=anyLock,ARGV\[2\]=85b196ce-e6f2-42ff-b3d7-6615b6748b5d:Thread-1 ,因此,這段腳本的意思是1、判斷有沒有一個叫“anyLock”的key2、如果沒有,則在其下設置一個字段為“85b196ce-e6f2-42ff-b3d7-6615b6748b5d:Thread-1”,值為“1”的鍵值對 ,并設置它的過期時間3、如果存在,則進一步判斷“85b196ce-e6f2-42ff-b3d7-6615b6748b5d:Thread-1”是否存在,若存在,則其值加1,并重新設置過期時間4、返回“anyLock”的生存時間(毫秒)
* 加鎖redis結構

> 這里用的數據結構是hash,hash的結構是: key? 字段1? 值1 字段2? 值2? 。。。用在鎖這個場景下,key就表示鎖的名稱,也可以理解為臨界資源,字段就表示當前獲得鎖的線程所有競爭這把鎖的線程都要判斷在這個key下有沒有自己線程的字段,如果沒有則不能獲得鎖,如果有,則相當于重入,字段值加1(次數)
* 解鎖
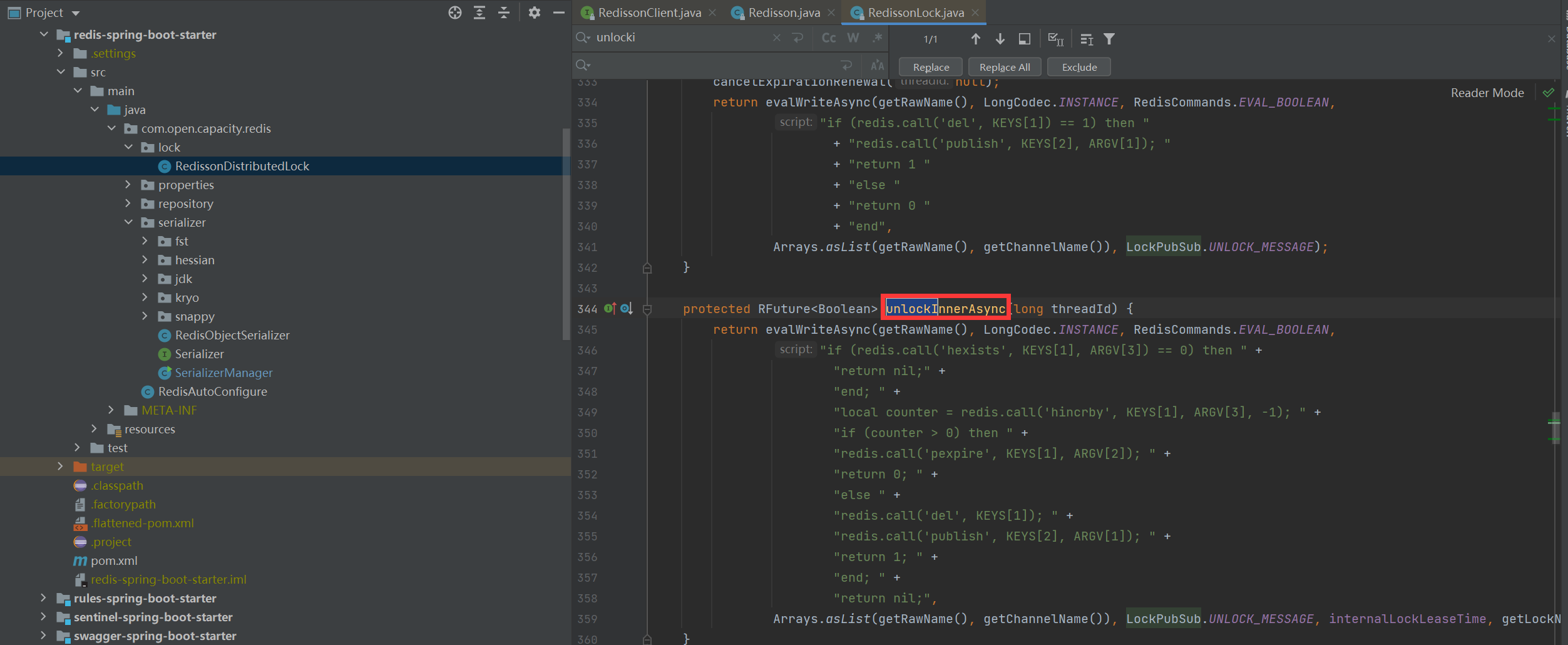
> 我們還是假設name=anyLock,假設線程ID是Thread-1,同理,我們可以知道KEYS\[1\]是getName(),即KEYS\[1\]=anyLock,KEYS\[2\]是getChannelName(),即KEYS\[2\]=redisson\_lock\_\_channel:{anyLock},ARGV\[1\]是LockPubSub.unlockMessage,即ARGV\[1\]=0,ARGV\[2\]是生存時間,ARGV\[3\]是getLockName(threadId),即ARGV\[3\]=85b196ce-e6f2-42ff-b3d7-6615b6748b5d:Thread-1,因此,上面腳本的意思是:1、判斷是否存在一個叫“anyLock”的key2、如果不存在,向Channel中廣播一條消息,廣播的內容是0,并返回1。3、如果存在,進一步判斷字段85b196ce-e6f2-42ff-b3d7-6615b6748b5d:Thread-1是否存在。4、若字段不存在,返回空,若字段存在,則字段值減1,5、若減完以后,字段值仍大于0,則返回0。6、減完后,若字段值小于或等于0,則廣播一條消息,廣播內容是0,并返回1;可以猜測,廣播0表示資源可用,即通知那些等待獲取鎖的線程現在可以獲得鎖了
* 等待
```
~~~
private void lock(long leaseTime, TimeUnit unit, boolean interruptibly) throws InterruptedException {
long threadId = Thread.currentThread().getId();
Long ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return;
}
RFuture<RedissonLockEntry> future = subscribe(threadId);
if (interruptibly) {
commandExecutor.syncSubscriptionInterrupted(future);
} else {
commandExecutor.syncSubscription(future);
}
try {
while (true) {
ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
break;
}
// waiting for message
if (ttl >= 0) {
try {
future.getNow().getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
if (interruptibly) {
throw e;
}
future.getNow().getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
}
} else {
if (interruptibly) {
future.getNow().getLatch().acquire();
} else {
future.getNow().getLatch().acquireUninterruptibly();
}
}
}
} finally {
unsubscribe(future, threadId);
}
// get(lockAsync(leaseTime, unit));
}
~~~
```
> 這里會訂閱Channel,當資源可用時可以及時知道,并搶占,防止無效的輪詢而浪費資源當資源可用用的時候,循環去嘗試獲取鎖,由于多個線程同時去競爭資源,所以這里用了信號量,對于同一個資源只允許一個線程獲得鎖,其它的線程阻塞
## Cache Aside Pattern
* 讀的時候,先讀緩存,緩存沒有的話,那么就讀數據庫,然后取出數據后放入緩存,同時返回響應
* 更新的時候,先刪除緩存,然后再更新數據庫
## Redis和Spring Cache整合
### 配置類
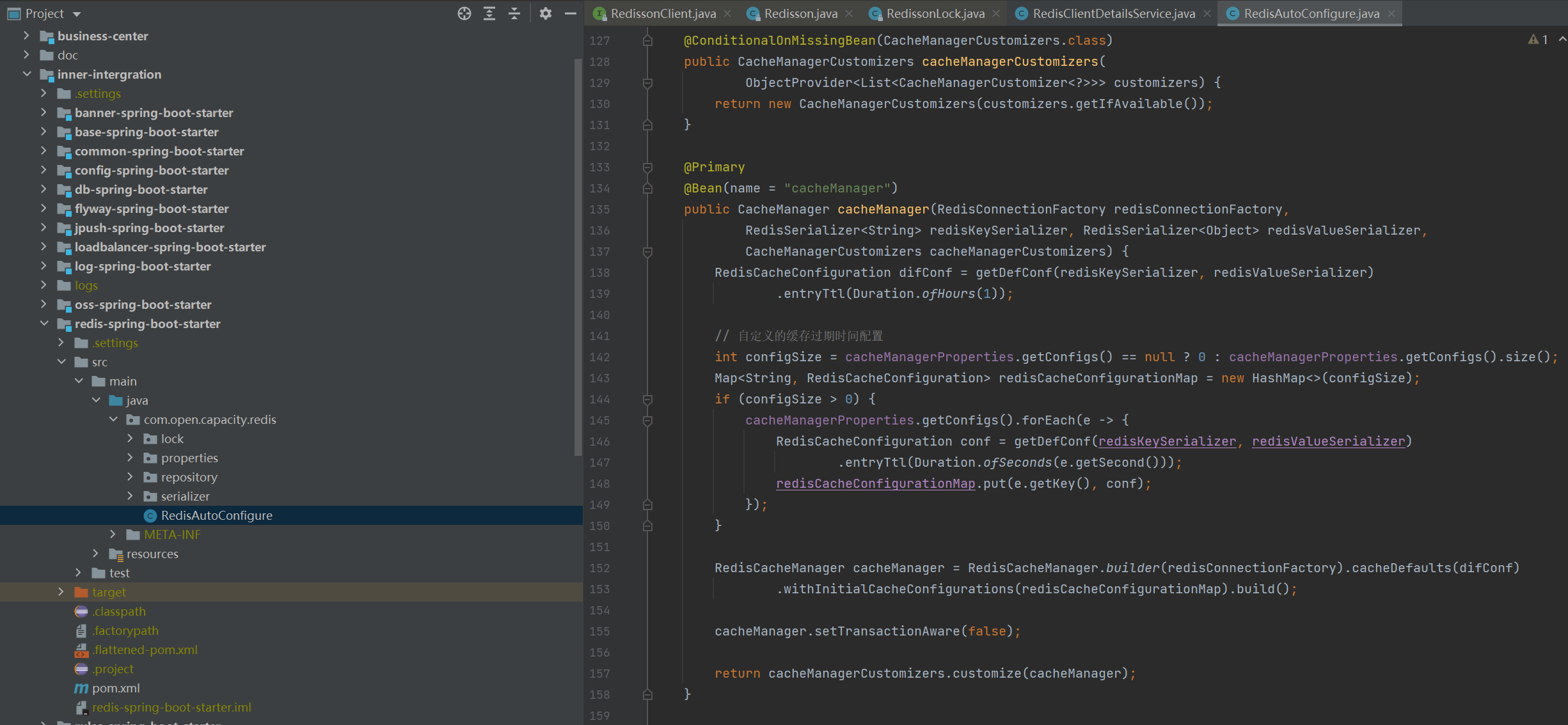
### 緩存key配置
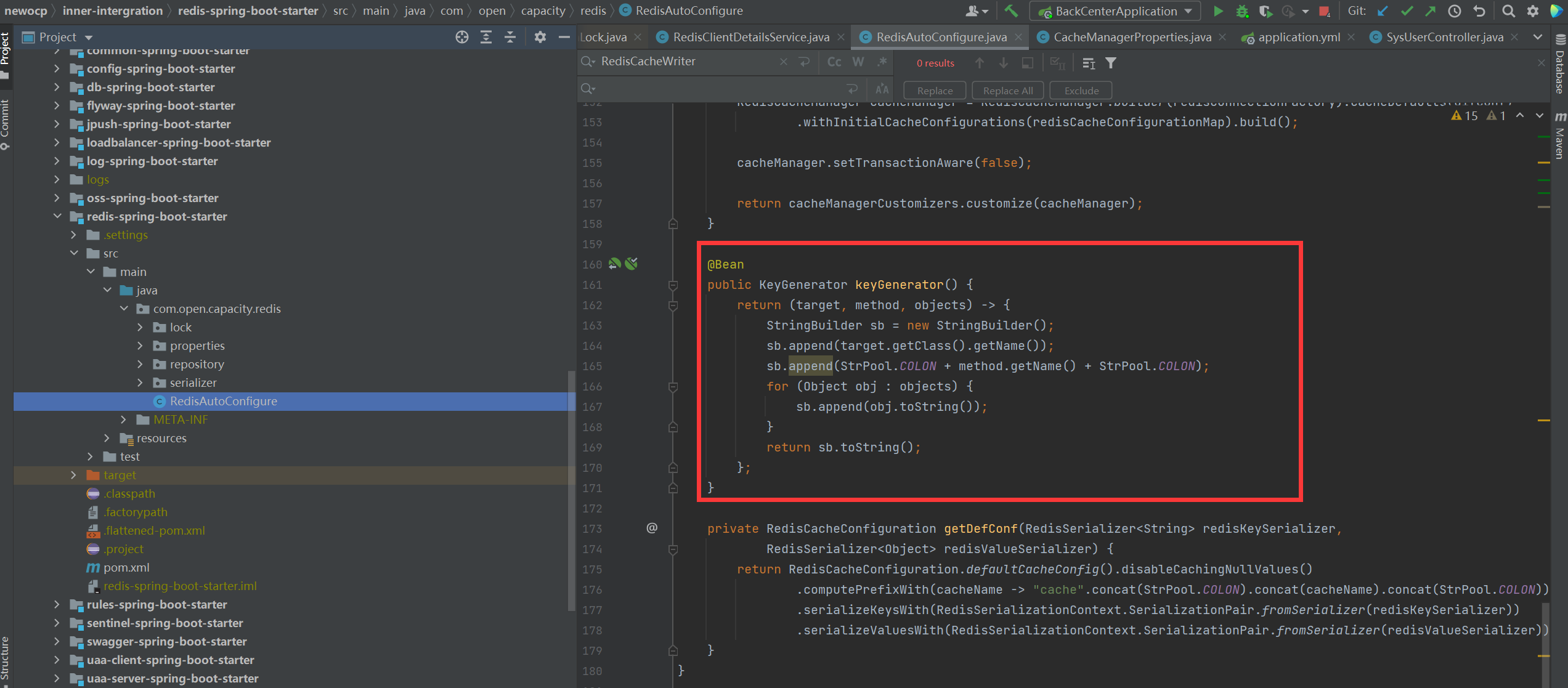
### 配置文件
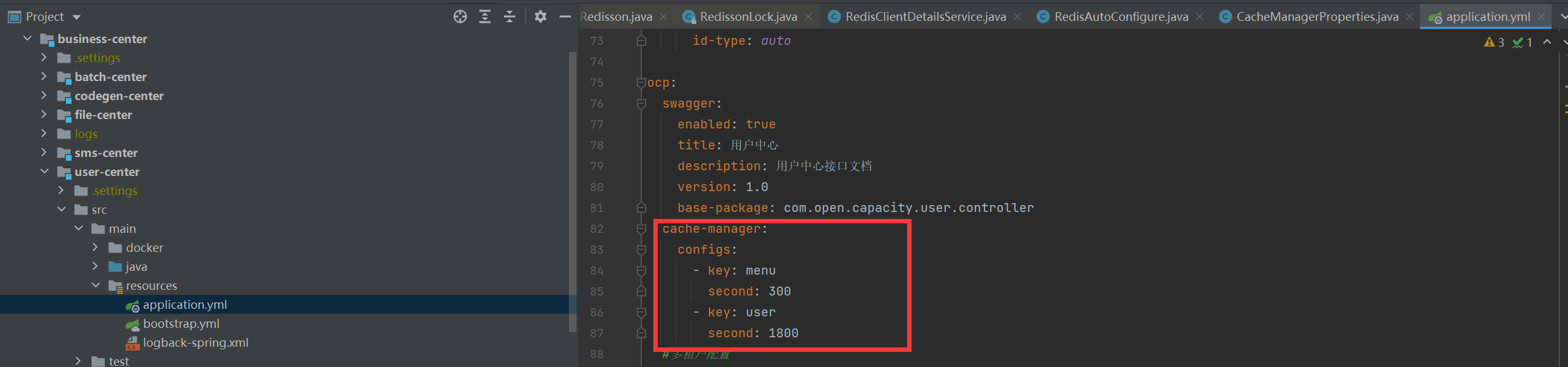
### 使用方式
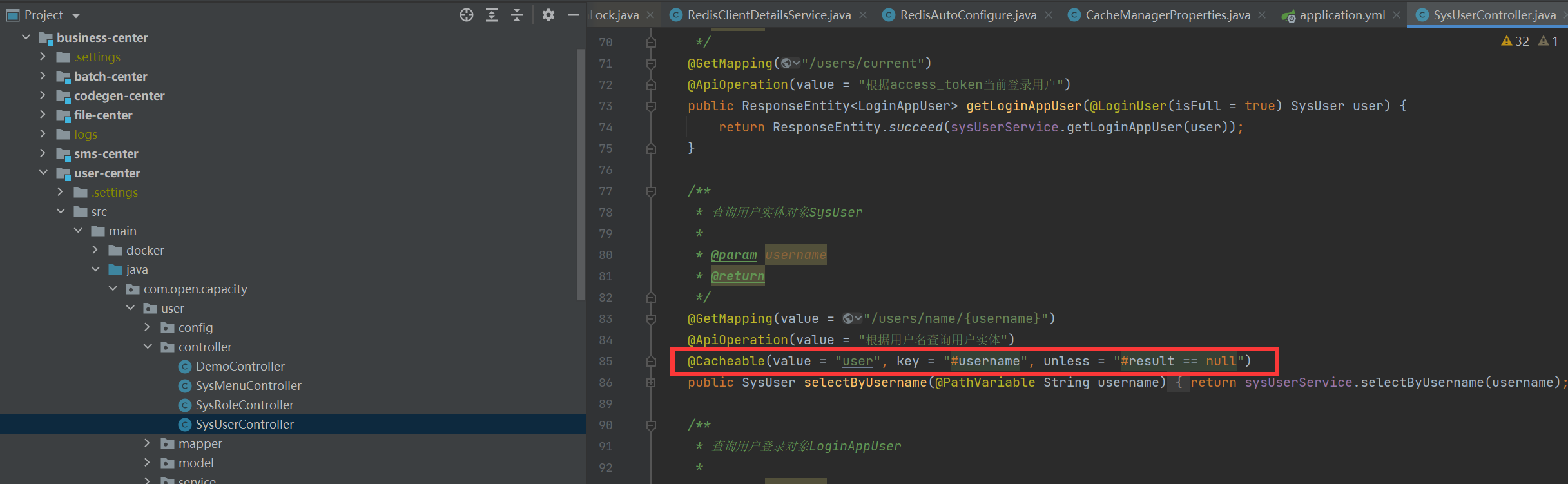
## geohash 經緯度定位
在開發疫情地圖時,我們常常需要進行經緯度定位,查詢該地區附近多少公里有多少疫情,此時我們需要采用geohash方式進行經緯度定位。
```
/**
* 添加經緯度信息 map.put("北京" ,new Point(116.405285 ,39.904989)) //redis 命令:geoadd
* cityGeo 116.405285 39.904989 "北京"
*/
public Long addGeoPoint(String key, Map<Object, Point> map) {
return redisTemplate.opsForGeo().add(key, map);
}
/**
* 查找指定key的經緯度信息 redis命令:geopos cityGeo 北京
*
* @param key
* @param member
* @return
*/
public Point geoGetPoint(String key, String member) {
List<Point> lists = redisTemplate.opsForGeo().position(key, member);
return lists.get(0);
}
/**
* 返回兩個地方的距離,可以指定單位 redis命令:geodist cityGeo 北京 上海
*
* @param key
* @param srcMember
* @param targetMember
* @return
*/
public Distance geoDistance(String key, String srcMember, String targetMember) {
Distance distance = redisTemplate.opsForGeo().distance(key, srcMember, targetMember, Metrics.KILOMETERS);
return distance;
}
/**
* 根據指定的地點查詢半徑在指定范圍內的位置 redis命令:georadiusbymember cityGeo 北京 100 km WITHDIST
* WITHCOORD ASC COUNT 5
*
* @param key
* @param member
* @param distance
* @return
*/
public GeoResults geoRadiusByMember(String key, String member, double distance) {
return redisTemplate.opsForGeo().radius(key, member, new Distance(distance, Metrics.KILOMETERS));
}
/**
* 根據給定的經緯度,返回半徑不超過指定距離的元素 redis命令:georadius cityGeo 116.405285 39.904989 100 km
* WITHDIST WITHCOORD ASC COUNT 5
*
* @param key
* @param circle
* @param distance
* @return
*/
public GeoResults geoRadiusByCircle(String key, Circle circle, double distance) {
return redisTemplate.opsForGeo().radius(key, circle, new Distance(distance, Metrics.KILOMETERS));
}
```
## redis cluster的優化
采用Redisson 方式支持Redis集群模式解決了以下問題:
* 自動發現主從節點
* 自動更新狀態和組態拓撲
* 自動發現槽的變化
項目中 3主3從 redis集群出現單節點宕機,造成master遷移,但是發現應用無法正常連接redis ,分析了代碼,發現默認Lettuce是不會刷新拓撲io.lettuce.core.cluster.models.partitions.Partitions#slotCache,最終造成槽點查找節點依舊找到老的節點,自然訪問不了了,采用平臺方式解決了以上問題,避免了在redis cluster集群中的一些bug。
- 01.前言
- 02.快速開始
- 01.maven構建項目
- 02.安裝mysql數據庫
- 03.安裝redis緩存中間件
- 04.快速啟動框架
- 03.總體流程
- 01.架構設計圖
- 02.oauth接口
- 03.功能介紹
- 04.部署細節
- 04.模塊詳解
- 01.基礎介紹
- 02.自定義db-spring-boot-starter
- 03.自定義log-spring-boot-starter
- 04.自定義redis-spring-boot-starter
- 05.自定義base-spring-boot-starter
- 06.自定義common-spring-boot-starter
- 07.自定義loadbalancer-spring-boot-starter
- 08.自定義swagger-spring-boot-starter
- 09.自定義uaa-client-spring-boot-starter
- 10.自定義uaa-server-spring-boot-starter
- 11.自定義oss-spring-boot-starter
- 12.自定義sentinel-spring-boot-starter
- 05.服務詳解
- 01.nacos-server
- 02.auth-server
- 03.user-center
- 04.new-api-gateway
- 05.file-center
- 06.log-center
- 07.back-center
- 08.auth-sso模塊
- 09.admin-server
- 10.job-center
- 06.系統安全
- 01.非法字符漏洞攻擊
- 02.防重放攻擊
- 03.代碼審計
- 04.Xray掃洞
- 05.混沌工程質量保證
- 07.生產部署K8S
- 01.基本環境安裝
- 02.基本組件安裝
- 03.集群驗證
- 04.安裝Metrics Server
- 05.安裝容器平臺
- 06.Ingress網關
- 07.metalb負載均衡器
- 08.容器平臺集群
- 08.K8S資源練習
- 01.Deployment
- 02.StatefulSet
- 03.DaemonSet
- 04.redis集群服務
- 05.elasticsearch集群
- 06.rocketmq部署
- 09.生產容器化部署
- 01.nacos集群部署
- 02.user-center服務
- 03.auth-server服務
- 04.new-api-gateway服務
- 技術交流