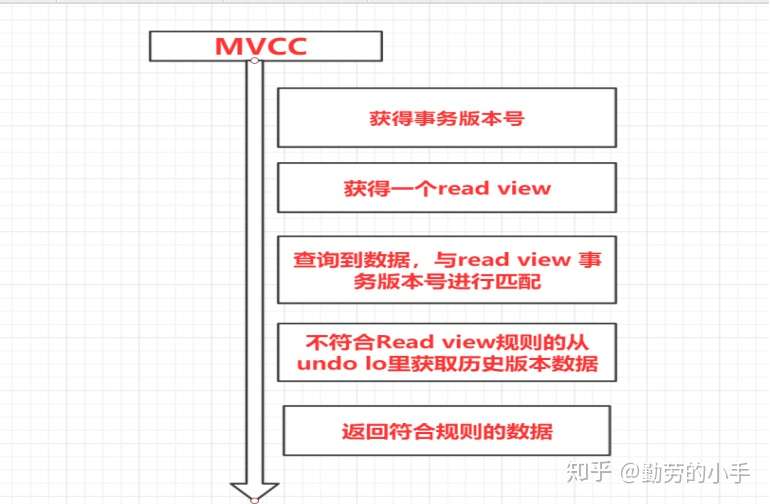
## **一、什么是MVCC?**
MVCC是在并發訪問數據庫時,通過對數據做多版本管理,避免因為寫鎖的阻塞而造成讀數據的并發阻塞問題。
通俗的講就是MVCC通過保存數據的歷史版本,根據比較版本號來處理數據的是否顯示,從而達到讀取數據的時候不需要加鎖就可以保證事務隔離性的效果
## **二、Innodb MVCC實現的核心知識點**
1、事務版本號
2、表的隱藏列。
3、undo log
4、 read view
### **2-1、事務版本號**
每次事務開啟前都會從數據庫獲得一個自增長的事務ID,可以從事務ID判斷事務的執行先后順序。
### **2-2、表格的隱藏列**
**DB\_TRX\_ID:**記錄操作該數據事務的事務ID;
**DB\_ROLL\_PTR:**指向上一個版本數據在undo log 里的位置指針;
**DB\_ROW\_ID:**隱藏ID ,當創建表沒有合適的索引作為聚集索引時,會用該隱藏ID創建聚集索引;
### **2-3、Undo log**
Undo log 主要用于記錄數據被修改之前的日志,在表信息修改之前先會把數據拷貝到undo log 里,當事務進行回滾時可以通過undo log 里的日志進行數據還原。
**Undo log 的用途**
(1)保證事務進行rollback時的原子性和一致性,當事務進行回滾的時候可以用undo log的數據進行恢復。
(2)用于MVCC快照讀的數據,在MVCC多版本控制中,通過讀取undo log的歷史版本數據可以實現不同事務版本號都擁有自己獨立的快照數據版本。
### **2-4、事務版本號、表格的隱藏列、undo log的關系**
我們模擬一次數據修改的過程來讓我們了解下事務版本號、表格隱藏的列和undo log他們之間的使用關系。
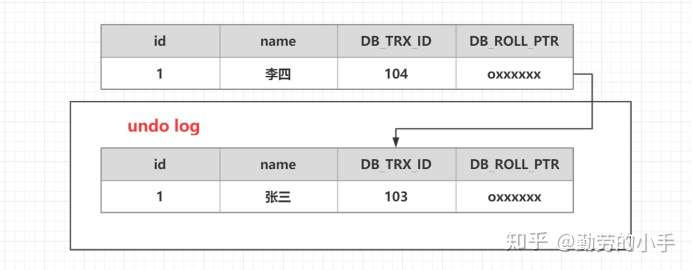
**(1)首先準備一張原始原始數據表**

**(2)開啟一個事務A:**對user\_info表執行 update user\_info set name =“李四”where id=1 會進行如下流程操作
1、首先獲得一個事務編號 104
2、把user\_info表修改前的數據拷貝到undo log
3、修改user\_info表 id=1的數據
4、把修改后的數據事務版本號改成 當前事務版本號,并把DB\_ROLL\_PTR 地址指向undo log數據地址。
**(3)最后執行完結果如圖:**
### **2-5、Read view**
在innodb 中每個事務開啟后都會得到一個read\_view。副本主要保存了當前數據庫系統中正處于活躍(沒有commit)的事務的ID號,其實簡單的說這個副本中保存的是系統中當前不應該被本事務看到的其他事務id列表。
### **Read view 的幾個重要屬性**
**trx\_ids:**當前系統活躍(未提交)事務版本號集合。
**low\_limit\_id:**創建當前read view 時“當前系統最大**事務版本號**+1”。
**up\_limit\_id:**創建當前read view 時“系統正處于**活躍事務**最小版本號”
**creator\_trx\_id:**創建當前read view的事務版本號;
### **Read view 匹配條件**
**(1)數據事務ID <up\_limit\_id 則顯示**
如果數據事務ID小于read view中的最小活躍事務ID,則可以肯定該數據是在當前事務啟之前就已經存在了的,所以可以顯示。
**(2)數據事務ID>=low\_limit\_id 則不顯示**
如果數據事務ID大于read view 中的當前系統的最大事務ID,則說明該數據是在當前read view 創建之后才產生的,所以數據不予顯示。
**(3) up\_limit\_id <=**數據事務ID<**low\_limit\_id 則與活躍事務集合**trx\_ids**里匹配**
如果數據的事務ID大于最小的活躍事務ID,同時又小于等于系統最大的事務ID,這種情況就說明這個數據有可能是在當前事務開始的時候還沒有提交的。
所以這時候我們需要把數據的事務ID與當前read view 中的活躍事務集合trx\_ids 匹配:
**情況1:**如果事務ID不存在于trx\_ids 集合(則說明read view產生的時候事務已經commit了),這種情況數據則可以顯示。
**情況2:**如果事務ID存在trx\_ids則說明read view產生的時候數據還沒有提交,但是如果數據的事務ID等于creator\_trx\_id ,那么說明這個數據就是當前事務自己生成的,自己生成的數據自己當然能看見,所以這種情況下此數據也是可以顯示的。
**情況3:**如果事務ID既存在trx\_ids而且又不等于creator\_trx\_id那就說明read view產生的時候數據還沒有提交,又不是自己生成的,所以這種情況下此數據不能顯示。
**(4)不滿足read view條件時候,從undo log里面獲取數據**
當數據的事務ID不滿足read view條件時候,從undo log里面獲取數據的歷史版本,然后數據歷史版本事務號回頭再來和read view 條件匹配 ,直到找到一條滿足條件的歷史數據,或者找不到則返回空結果;
* * *
## **三、Innodb實現MCC的原理**
### **3-1、模擬MVCC實現流程**
下面我們通過開啟兩個同時進行的事務來模擬MVCC的工作流程。
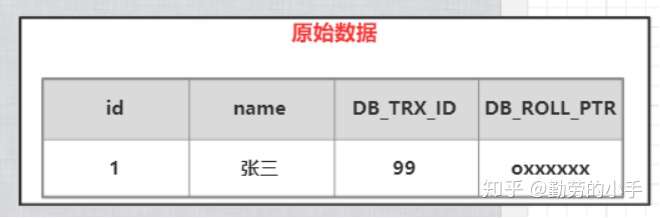
**(1)創建user\_info表,插入一條初始化數據**
**(2)事務A和事務B同時對user\_info進行修改和查詢操作**
事務A:update user\_info set name =”李四”
事務B:select \* fom user\_info where id=1
**問題:**
先開啟事務A ,在事務A修改數據后但未進行commit,此時執行事B。最后返回結果如何。
**執行流程如下圖:**
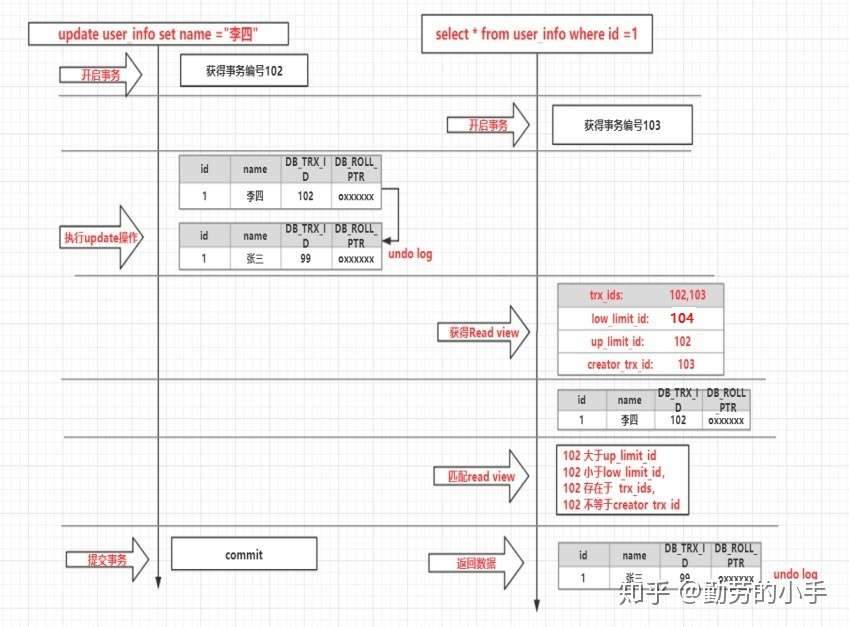
**執行流程說明:**
**(1)事務A:開啟事務,首先得到一個事務編號102;**
**(2)事務B:開啟事務,得到事務編號103;**
**(3)事務A:進行修改操作,首先把原數據拷貝到undolog,然后對數據進行修改,標記事務編號和上一個數據版本在undo log的地址。**
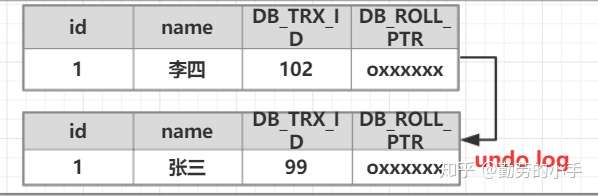
**(4)事務B: 此時事務B獲得一個read view ,read view對應的值如下**
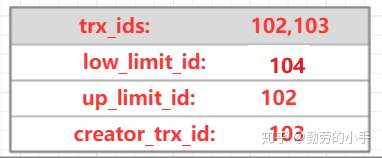
**(5)事務B: 執行查詢語句,此時得到的是事務A修改后的數據**

**(6)事務B: 把數據與read view進行匹配,**
數據事務ID為102 等于up\_limit\_id (這里不小于up\_limit\_id)
數據事務ID為102 小于low\_limit\_id
數據事務ID為102存在于 trx\_ids,
數據事務ID為102不等于creator\_trx\_id
發現不滿足read view顯示條件,所以從undo lo獲取歷史版本的數據再和read view進行匹配,最后返回數據如下。

* * *
## **四、補充**
### **各種事務隔離級別下的Read view 工作方式**
RC(read commit) 級別下同一個事務里面的每一次查詢都會獲得一個新的read view副本。這樣就可能造成同一個事務里前后讀取數據可能不一致的問題(重復讀)

RR(重復讀)級別下的一個事務里只會獲取一次read view副本,從而保證每次查詢的數據都是一樣的。

READ\_UNCOMMITTED 級別的事務不會獲取read view 副本。
### **快照讀和當前讀**
**快照讀**
快照讀是指讀取數據時不是讀取最新版本的數據,而是基于歷史版本讀取的一個快照信息(mysql讀取undo log歷史版本) ,快照讀可以使普通的SELECT 讀取數據時不用對表數據進行加鎖,從而解決了因為對數據庫表的加鎖而導致的兩個如下問題
1、解決了因加鎖導致的修改數據時無法對數據讀取問題;
2、解決了因加鎖導致讀取數據時無法對數據進行修改的問題;
**當前讀**
當前讀是讀取的數據庫最新的數據,當前讀和快照讀不同,因為要讀取最新的數據而且要保證事務的隔離性,所以當前讀是需要對數據進行加鎖的(Update delete insert select ....lock in share mode select for update 為當前讀)
* * *
## **五、討論**
### **MVCC是否有解決幻讀問題?**
看到有很多網友對這個話題有討論,這里補充一下和大家理一理這個問題,首先我通過驗證得出來的結論是MVCC不存在幻讀問題的,但也并不是說MVCC解決了幻讀的問題,經過理論的推斷和驗證得到的結論是在**快照讀的情況下可以避免幻讀問題,在當前讀的情況下則需要使用間隙鎖來解決幻讀問題的**。
### **MVCC不存在幻讀問題(RR級別的情況下)**
首先確認一點MVCC屬于快照讀的,在進行快照讀的情況下是不會對數據進行加鎖,而是基于事務版本號和undo歷史版本讀取數據,其實上面的文章已經說得很清楚了,我們根據上面的MVCC流程來推導,無論如何在MVCC的情況下都是不會出現幻讀的問題的,如下圖。
1、開啟事務1,獲得事務ID為1。
2、事務1執行查詢,得到readview。
3、開始事務2。
4、執行insert。
5、提交事務2。
6、執行事務1的第二次查詢 (因為這里是RR級別,所以不會再去獲得readview,還是使用第一次獲得的readview)
7、最后得到的結果是,插入的數據不會顯示,因為插入的數據事務ID大于等于 readview里的最大活躍事務ID。
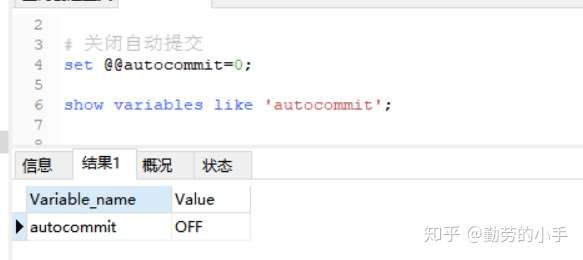
**實際案例:**
首先關閉數據庫的自動提交事務功能。

然后使用手動提交事務的方式,進行一次快照讀,但是不提交事務,然后啟動插入數據的事務,進行數據插入 commit,結果我發現在使用快照讀的時候,數據是可以插入成功的,那這也就說明了一個問題,**快照讀的時候就根本沒加鎖,否則的話數據是不可能插入成功的,而且在插入數據提交成功后,我們執行第二條查詢 語句是讀取不到中間插入的這條數據的,這也就說明在沒有加鎖的情況下,基于歷史版本的MVCC快照讀是可以避免幻讀問題的**。

### **當前讀存的幻讀問題解決方案**
上面我們已經論證了在RR級別快照讀的情況下,是不存在幻讀問題的。 因為會基于歷史版本讀取數據,但是當前讀的話就不同了,當前讀每次都會讀取最新的數據。所以兩次讀取中間如果可以插入數據,那么就肯定會造成幻讀問題,所以在當前讀的情況下就必須通過一種方式來解決幻讀問題,而這種方式就是采用加鎖來解決。
**實際案例:**
首先關閉數據庫的自動提交事務功能, 使用當前讀的方式演示和上面一樣的流程,結果發現在當前讀的時候沒有提交事務之前是根本無法進行數據插入的,所以這也就說明了,使用當前讀的時候會對這個范圍內的數據進行加鎖,所以無法在查詢的范圍內進行數據插入,這無疑也證明了在當前讀的情況下mysql是使用鎖的機制來避免出現重復讀和幻讀問題的。

- 序言
- 從業感悟
- 常用名詞
- HTML
- JS
- ES6新特性
- jquery和vue對比
- 徹底理解this
- JQuery添加自定義函數
- js的實現
- 原始值和引用值
- MYSQL
- 簡介
- 術語
- 特點
- 范式
- 數據類型1
- 數據類型2
- 編碼
- 權限管理
- 事務
- mvvc
- 引擎
- MyISAM與InnoDB區別
- 索引類型
- 鎖
- 死鎖
- 分層架構
- 執行計劃
- join原理
- 高可用
- 日志類型
- 分庫分表
- 中間件
- 服務器
- 操作系統
- 信號量 鎖 隊列
- PHP
- composer加載原理
- composer基礎知識
- 自動加載函數
- composer加載代碼
- composer 自動加載
- 內存管理
- PHP執行流程
- cgi,fastCgi,php-fpm
- HTTP
- 錯誤碼
- 跨域請求
- 面試
- 安全
- HTTP劫持
- 設計模式
- 如何正確的使用設計模式
- 單例模式
- 原型模式
- 簡單工廠模式
- 工廠方法模式
- 抽象工廠模式
- 建造者模式
- 設計原則
- 算法
- PHP短標簽