## 第三關:
第三題地址:[http://www.pythonchallenge.com/pc/def/equality.html](http://www.pythonchallenge.com/pc/def/equality.html)<br>
<br>
下面的提示,翻譯過來就是:**一個小字母,兩邊正好有三個大保鏢**我的理解是:一個小寫字母左邊有三個大寫字母,右邊有三個大寫字母
參考上一題,還是找網頁源代碼
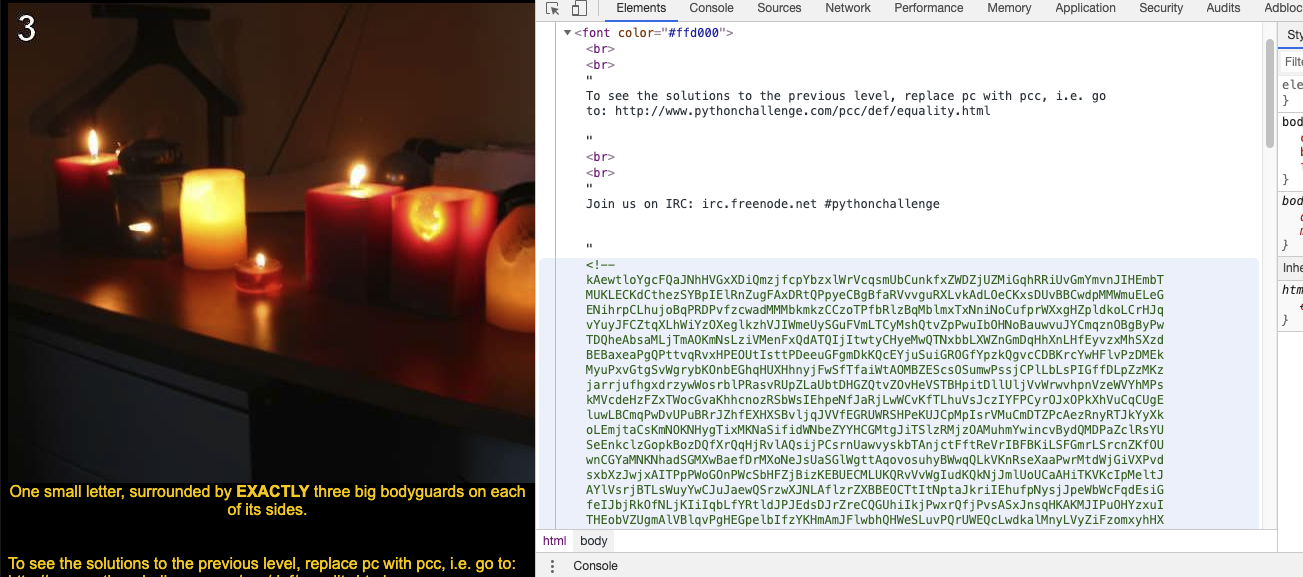
# **解題代碼:**
```
# 目標:一個小寫字母旁邊有是三個大寫字母
# 定為小寫字母:ascii值97-122
# 定位大寫字符:ascii值65-90
# 大概思路,for循環遍歷每一個小寫字母,在判斷其左三個字符,右三個字符(正好左三個,右三個,沒有第四個)
str_text = "源代碼里面的字符太長了,這里不粘貼了,你們自己復制吧!"
new_str_text = "" # 一個空的字符,代表所有小寫字符的集合
list_new_str_text = list(new_str_text) # 轉換為列表
end_text = "" # 一個空字符,代表最終所有滿足條件的小寫字符
list_end_text = list(end_text) # 轉換為列表
print(len(str_text)) # 十萬個字符,這人真狠!
for i in range(len(str_text)): # 字符串第一個是零,此時的i就是字符串的下標位置
# print(i)
# 從第四個(下標3)(含)開始,判斷到倒數四個(下標len()-1-3)(含)
# 判斷其左三個字符都是大寫字符,且右邊三個字符都是大寫字符
if 97 <= ord(str_text[i]) <= 122: # 篩選出來小寫字符
# print(i) # 所有小寫字符的位置全部輸出,這個創建一個列表,直接判斷這個列表
list_new_str_text.append(i) # 新的列表,包含所有小寫字符的位置(下標)
print(list_new_str_text) # 新的列表,包含所有小寫字符的位置(下標)
for a in list_new_str_text: # a:每個小寫字符在原字符串中的位置
# print(a)
if 3 <= a <= (len(str_text) - 4): # 篩選掉兩邊的六個(無法處理,也不會是兩邊的六個)
# print(a)
# 下面開始判斷 a左三個,右三個都是大寫字符
if 65 <= ord(str_text[a - 3]) <= 90:
# print(str_text[a] + '左邊第三個是大寫字符')
if 65 <= ord(str_text[a - 2]) <= 90:
# print(str_text[a] + '左邊第二個是大寫字符,且左邊第三個是大寫字符')
if 65 <= ord(str_text[a - 1]) <= 90:
print(str_text[a] + '左邊第一個是大寫字符,且左邊第二個是大寫字符,且左邊第一個是大寫字符')
# TODO 最后在判斷一下,左邊第四個不是大寫字符
if (97 <= ord(str_text[a - 4]) <= 122):
print(str_text[a] + '左邊第一個是大寫字符,且左邊第二個是大寫字符,且左邊第一個是大寫字符,且左邊第四個是小寫字符')
if 65 <= ord(str_text[a + 3]) <= 90:
# print(str_text[a] + '右邊第三個是大寫字符')
if 65 <= ord(str_text[a + 2]) <= 90:
# print(str_text[a] + '右邊第二個是大寫字符,且右邊第三個是大寫字符')
if 65 <= ord(str_text[a + 1]) <= 90:
# print(str_text[a] + '右邊第一個是大寫字符,且右邊第二個是大寫字符,且右邊第三個是大寫字符')
if (97 <= ord(str_text[a + 4]) <= 122):
print(str_text[a] + '右邊第一個是大寫字符,且右邊第二個是大寫字符,且右邊第一個是大寫字符,且右邊第四個是小寫字符')
list_end_text.append(str_text[a])
print(list_end_text)
print("".join(list_end_text))
# linkedlist
```
代碼還有很大的改動空間,想那個那么多層的if循環可以簡化一些,我這里懶得改了,能過關就行了!
