第四關地址:[http://www.pythonchallenge.com/pc/def/linkedlist.php](http://www.pythonchallenge.com/pc/def/linkedlist.php)
<br><br>
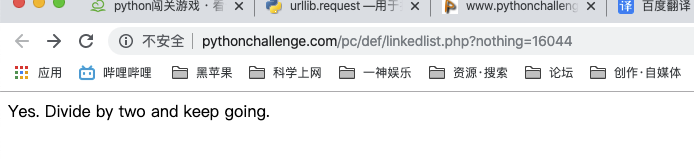
解題過程:首先圖片是一個鏈接,可以點擊。源代碼中也有一段文字提示
```
urllib may help. DON'T TRY ALL NOTHINGS, since it will never end. 400 times is more than enough.
```
**百度翻譯:urllib可能有幫助。不要什么都試,因為它永遠不會結束。400次就足夠了。**
<br><br><br>
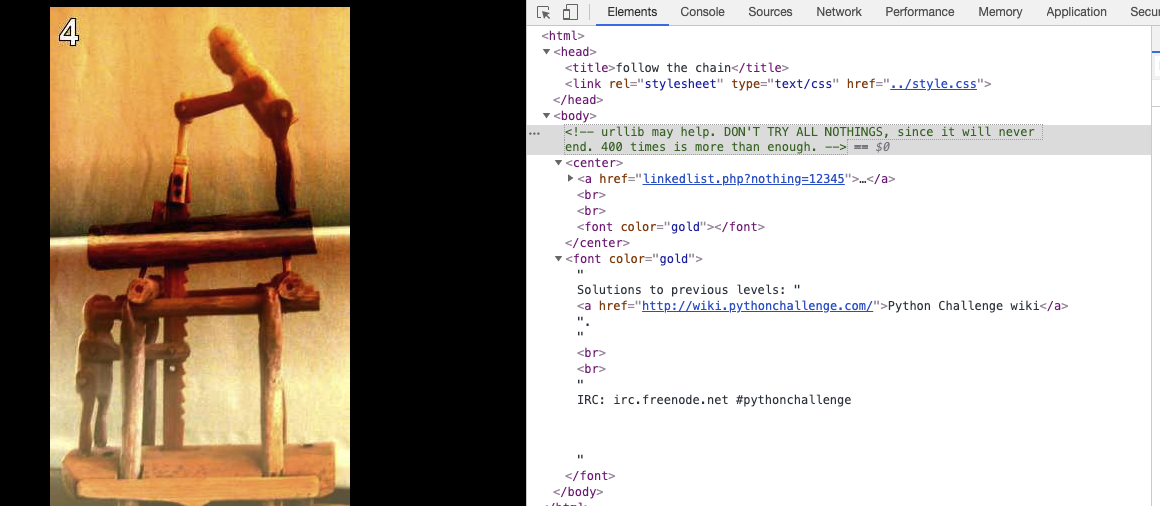
多次點擊圖片
**第一次點擊:**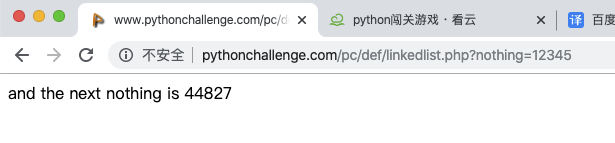
將鏈接中的12345換位44827繼續訪問
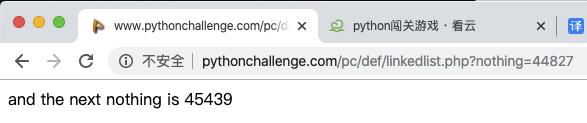
在繼續一次:
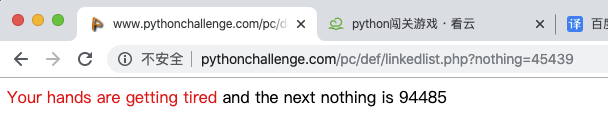
到現在,大概該明白源代碼中提示的意思了!
```
# 目標獲取網頁內容 "and the next nothing is 44827"中的44827(倒數5位數),將其作為域名訪問,一直循環
# 大概需要用到urllib庫的知識
import urllib.request
str_index = '72156' # 初始值是12345,下面兩個是會遇到的特殊值
# str_index = '8022' # 這個特殊值需要自己手動輸入
# str_index = '63579' # There maybe misleading numbers in the text. One example is 82683. Look only for the next nothing and the next nothing is 63579,你可以通過從右邊開始搜索is,或者搜索'and the next nothing is'都是可以跳過這句的
for i in range(100): # 次數這里可以設置更大數字,100是隨緣寫的,實際大概總共需要循環四,五百次吧,直接寫while TRUE應該也是可以的
url = 'http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=' + str_index # 下一次該要訪問的url
print(url)
response = urllib.request.urlopen(url) # 請求站點獲得一個HTTPResponse對象
str_text = response.read().decode('utf-8') # 返回網頁內容,字符串
print(str_text)
index = str_text.find('is') # 尋找is出現的位置,便于后面獲取nothing值
print('nothing值的長度:' + str(len(str_text) - (index + 3)))
if (len(str_text) - (index + 3)) == 5:
str_index = str_text[index+3] + str_text[index+4] + str_text[index+5] + str_text[index+6] + str_text[index+7] # nothing值
elif (len(str_text) - (index + 3)) == 4:
str_index = str_text[index + 3] + str_text[index + 4] + str_text[index + 5] + str_text[index + 6] # nothing值
elif (len(str_text) - (index + 3)) == 3:
str_index = str_text[index + 3] + str_text[index + 4] + str_text[index + 5] # nothing值
```
最終經過好幾百此的循環,見證到結果!
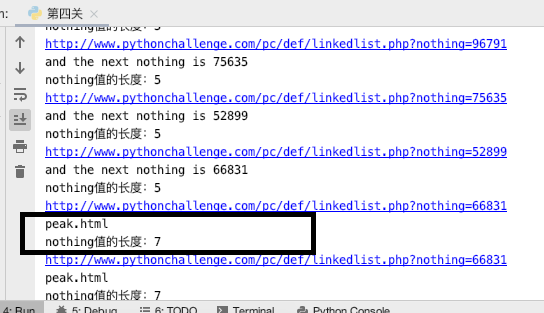
**中間過程中,會出現一些特殊值,需要你自己重新輸入nothing值繼續循環!**
**下面是特殊值的截圖!**