
**本文會先講述數據同步的 4 種方案,并給出常用數據遷移工具**,干貨滿滿!
不 BB,上文章目錄:
# 1\. 前言
在實際項目開發中,我們經常將 MySQL 作為業務數據庫,ES 作為查詢數據庫,用來實現讀寫分離,緩解 MySQL 數據庫的查詢壓力,應對海量數據的復雜查詢。
這其中有一個很重要的問題,就是如何實現 MySQL 數據庫和 ES 的數據同步,今天和大家聊聊 MySQL 和 ES 數據同步的各種方案。
我們先看看下面 4 種常用的數據同步方案。
# 2\. 數據同步方案
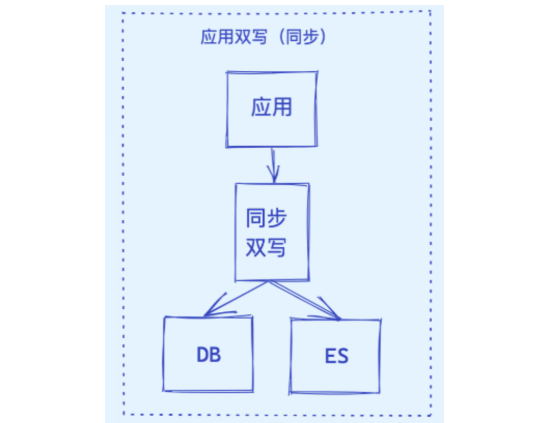
## 2.1 同步雙寫
這是一種最為簡單的方式,在將數據寫到 MySQL 時,同時將數據寫到 ES。
優點:
* 業務邏輯簡單;
* 實時性高。
缺點:
* 硬編碼,有需要寫入 MySQL 的地方都需要添加寫入 ES 的代碼;
* 業務強耦合;
* 存在雙寫失敗丟數據風險;
* 性能較差,本來 MySQL 的性能不是很高,再加一個 ES,系統的性能必然會下降。
## 2.2 異步雙寫
針對多數據源寫入的場景,可以借助 MQ 實現異步的多源寫入。

優點:
* 性能高;
* 不易出現數據丟失問題,主要基于 MQ 消息的消費保障機制,比如 ES 宕機或者寫入失敗,還能重新消費 MQ 消息;
* 多源寫入之間相互隔離,便于擴展更多的數據源寫入。
缺點:
* 硬編碼問題,接入新的數據源需要實現新的消費者代碼;
* 系統復雜度增加,引入了消息中間件;
* MQ是異步消費模型,用戶寫入的數據不一定可以馬上看到,造成延時。
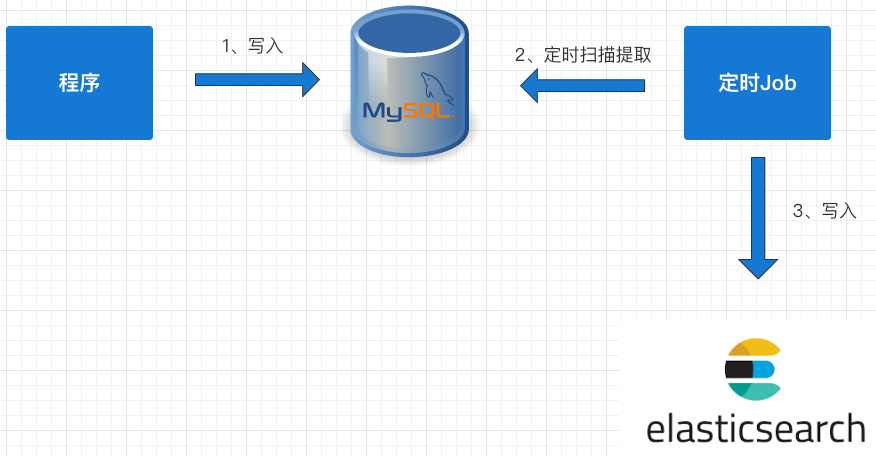
## 2.3 基于 SQL 抽取
上面兩種方案中都存在硬編碼問題,代碼的侵入性太強,如果對實時性要求不高的情況下,可以考慮用定時器來處理:
1. 數據庫的相關表中增加一個字段為 timestamp 的字段,任何 CURD 操作都會導致該字段的時間發生變化;
2. 原來程序中的 CURD 操作不做任何變化;
3. 增加一個定時器程序,讓該程序按一定的時間周期掃描指定的表,把該時間段內發生變化的數據提取出來;
4. 逐條寫入到 ES 中。
優點:
* 不改變原來代碼,沒有侵入性、沒有硬編碼;
* 沒有業務強耦合,不改變原來程序的性能;
* Worker 代碼編寫簡單不需要考慮增刪改查。
缺點:
* 時效性較差,由于是采用定時器根據固定頻率查詢表來同步數據,盡管將同步周期設置到秒級,也還是會存在一定時間的延遲;
* 對數據庫有一定的輪詢壓力,一種改進方法是將輪詢放到壓力不大的從庫上。
> 經典方案:借助 Logstash 實現數據同步,其底層實現原理就是根據配置定期使用 SQL 查詢新增的數據寫入 ES 中,實現數據的增量同步。
## 2.4 基于 Binlog 實時同步
上面三種方案要么有代碼侵入,要么有硬編碼,要么有延遲,那么有沒有一種方案既能保證數據同步的實時性又沒有代入侵入呢?
當然有,可以利用 MySQL 的 Binlog 來進行同步。
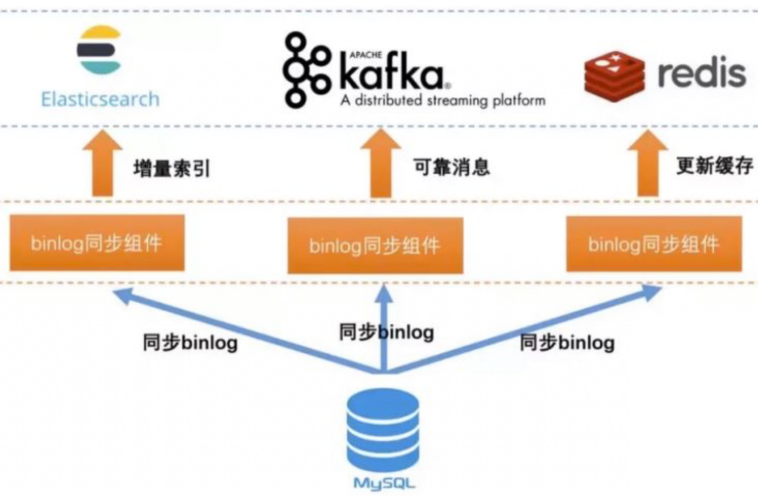
具體步驟如下:
* 讀取 MySQL 的 Binlog 日志,獲取指定表的日志信息;
* 將讀取的信息轉為 MQ;
* 編寫一個 MQ 消費程序;
* 不斷消費 MQ,每消費完一條消息,將消息寫入到 ES 中。
優點:
* 沒有代碼侵入、沒有硬編碼;
* 原有系統不需要任何變化,沒有感知;
* 性能高;
* 業務解耦,不需要關注原來系統的業務邏輯。
缺點:
* 構建 Binlog 系統復雜;
* 如果采用 MQ 消費解析的 Binlog 信息,也會像方案二一樣存在 MQ 延時的風險。
# 3\. 數據遷移工具選型
對于上面 4 種數據同步方案,“基于 Binlog 實時同步”方案是目前最常用的,也誕生了很多優秀的數據遷移工具,這里主要對這些遷移工具進行介紹。
這些數據遷移工具,很多都是基于 Binlog 訂閱的方式實現,**模擬一個 MySQL Slave 訂閱 Binlog 日志,從而實現 CDC**(Change Data Capture),將已提交的更改發送到下游,包括 INSERT、DELETE、UPDATE。
至于如何偽裝?大家需要先了解 MySQL 的主從復制原理,需要學習這塊知識的同學,可以看我之前寫的高并發教程,里面有詳細講解。
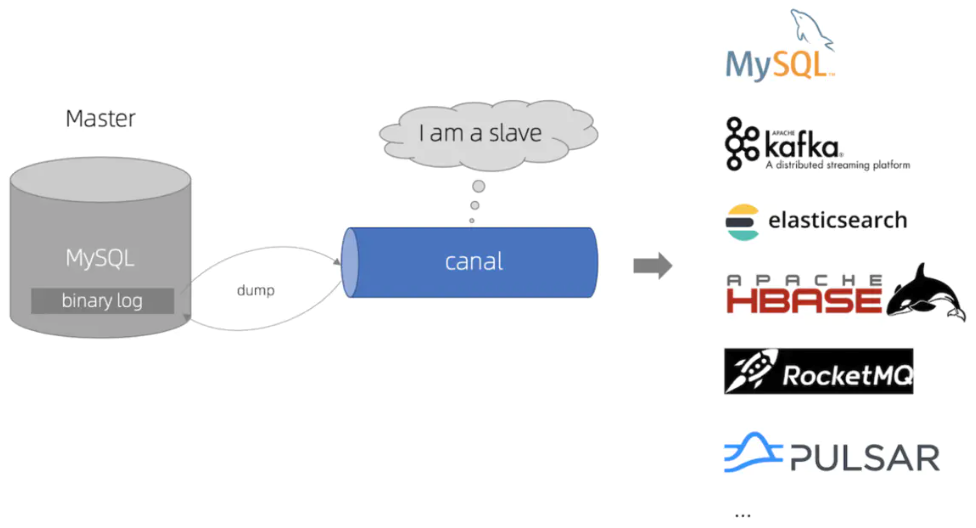
## 3.1 Cannel
基于數據庫增量日志解析,提供增量數據訂閱&消費,目前主要支持 MySQL。
Canal 原理就是偽裝成 MySQL 的從節點,從而訂閱 master 節點的 Binlog 日志,主要流程為:
1. Canal 服務端向 MySQL 的 master 節點傳輸 dump 協議;
2. MySQL 的 master 節點接收到 dump 請求后推送 Binlog 日志給 Canal 服務端,解析 Binlog 對象(原始為 byte 流)轉成 Json 格式;
3. Canal 客戶端通過 TCP 協議或 MQ 形式監聽 Canal 服務端,同步數據到 ES。
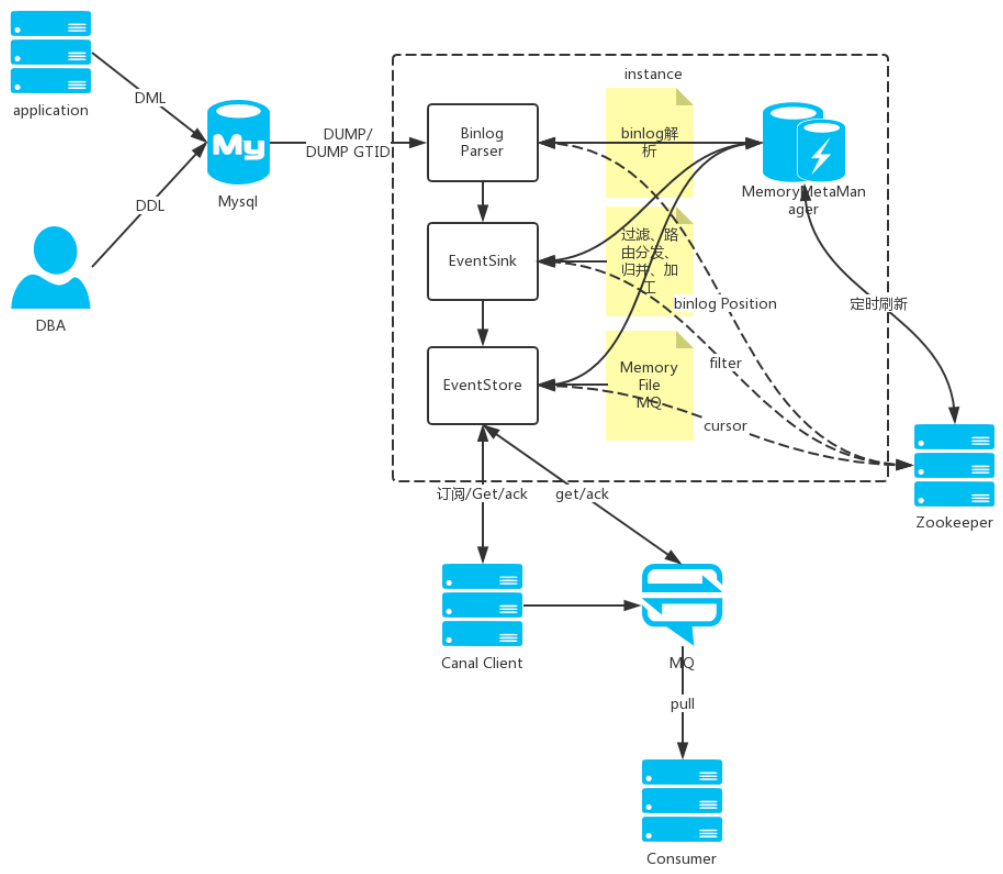
下面是 Cannel 執行的核心流程,其中 Binlog Parser 主要負責 Binlog 的提取、解析和推送,EventSink 負責數據的過濾 、路由和加工,僅作了解即可。
## 3.2 阿里云 DTS
數據傳輸服務 DTS(Data Transmission Service)支持 RDBMS、NoSQL、OLAP 等多種數據源之間的數據傳輸。
它提供了數據遷移、實時數據訂閱及數據實時同步等多種數據傳輸方式。相對于第三方數據流工具,DTS 提供豐富多樣、高性能、高安全可靠的傳輸鏈路,同時它提供了諸多便利功能,極大方便了傳輸鏈路的創建及管理。
特點:
* 多數據源:支持 RDBMS、NoSQL、OLAP 等多種數據源間的數據傳輸;
* 多傳輸方式:支持多種傳輸方式,包括數據遷移、實時數據訂閱及數據實時同步;
* 高性能:底層采用了多種性能優化措施,全量數據遷移高峰期時性能可以達到70MB/s,20萬的TPS,使用高規格服務器來保證每條遷移或同步鏈路都能擁有良好的傳輸性能;
* 高可用:底層為服務集群,如果集群內任何一個節點宕機或發生故障,控制中心都能夠將這個節點上的所有任務快速切換到其他節點上,鏈路穩定性高;
* 簡單易用:提供可視化管理界面,提供向導式的鏈路創建流程,用戶可以在其控制臺簡單輕松地創建傳輸鏈路;
* 需要付費。
再看看 DTS 的系統架構。

* 高可用:數據傳輸服務內部每個模塊都有主備架構,保證系統高可用。容災系統實時檢測每個節點的健康狀況,一旦發現某個節點異常,會將鏈路快速切換到其他節點。
* 數據源地址動態適配:對于數據訂閱及同步鏈路,容災系統還會監測數據源的連接地址切換等變更操作,一旦發現數據源發生連接地址變更,它會動態適配數據源新的連接方式,在數據源變更的情況下,保證鏈路的穩定性。
更多內容,請查看阿里官方文檔:https://help.aliyun.com/product/26590.html
## 3.3 Databus
Databus 是一個低延遲、可靠的、支持事務的、保持一致性的數據變更抓取系統。由 LinkedIn 于 2013 年開源。
Databus 通過挖掘數據庫日志的方式,將數據庫變更實時、可靠的從數據庫拉取出來,業務可以通過定制化 client 實時獲取變更并進行其他業務邏輯。
特點:
* 多數據源:Databus 支持多種數據來源的變更抓取,包括 Oracle 和 MySQL。
* 可擴展、高度可用:Databus 能擴展到支持數千消費者和事務數據來源,同時保持高度可用性。
* 事務按序提交:Databus 能保持來源數據庫中的事務完整性,并按照事務分組和來源的提交順尋交付變更事件。
* 低延遲、支持多種訂閱機制:數據源變更完成后,Databus 能在毫秒級內將事務提交給消費者。同時,消費者使用D atabus 中的服務器端過濾功能,可以只獲取自己需要的特定數據。
* 無限回溯:對消費者支持無限回溯能力,例如當消費者需要產生數據的完整拷貝時,它不會對數據庫產生任何額外負擔。當消費者的數據大大落后于來源數據庫時,也可以使用該功能。
再看看 Databus 的系統架構。
Databus 由 Relays、bootstrap 服務和 Client lib 等組成,Bootstrap 服務中包括 Bootstrap Producer 和 Bootstrap Server。
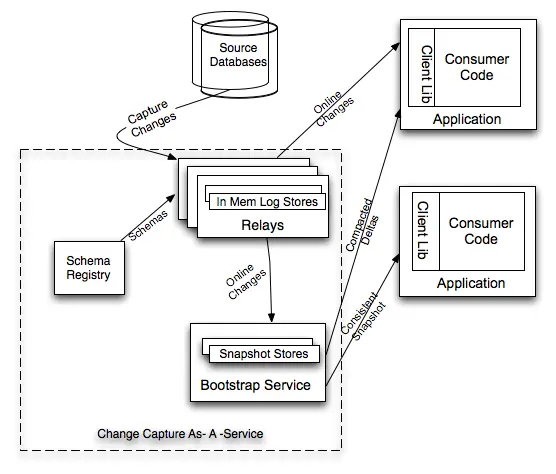
* 快速變化的消費者直接從 Relay 中取事件;
* 如果一個消費者的數據更新大幅落后,它要的數據就不在 Relay 的日志中,而是需要**請求 Bootstrap 服務,返回的將會是自消費者上次處理變更之后的所有數據變更快照。**
開源地址:https://github.com/linkedin/databus
## 3.4 其它
**Flink**
* 有界數據流和無界數據流上進行有狀態計算分布式處理引擎和框架。
* 官網地址:https://flink.apache.org
**CloudCanal**
* 數據同步遷移系統,商業產品。
* 官網地址:https://www.clougence.com/?utm\_source=wwek
**Maxwell**
* 使用簡單,直接將數據變更輸出為json字符串,不需要再編寫客戶端。
* 官網地址:http://maxwells-daemon.io
**DRD**
* 阿里巴巴集團自主研發的分布式數據庫中間件產品,專注于解決單機關系型數據庫擴展性問題,具備輕量(無狀態)、靈活、穩定、高效等特性。
* 官方地址:https://www.aliyun.com/product/drds
**yugong**
* 幫助用戶完成從 Oracle 數據遷移到 MySQL。
* 訪問地址:https://github.com/alibaba/yugong
# 4\. 后記
通過這篇文章,讓你知道 MySQL 和其它多維數據的同步方案,以及常用的數據遷移工具,幫助你更好選型。
作者|樓仔
來源: https://www.cnblogs.com/88223100/p/Four-data-synchronization-schemes-to-Elasticsearch.html
- Golang
- Beego框架
- Gin框架
- gin框架介紹
- 使用Gin web框架的知名開源線上項目
- go-admin-gin
- air 熱啟動
- 完整的form表單參數驗證語法
- Go 語言入門練手項目推薦
- Golang是基于多線程模型
- golang 一些概念
- Golang程序開發注意事項
- fatal error: all goroutines are asleep - deadlock
- defer
- Golang 的內建調試器
- go部署
- golang指針重要性
- 包(golang)
- Golang框架選型比較: goframe, beego, iris和gin
- GoFrame
- golang-admin-項目
- go module的使用方法及原理
- go-admin支持多框架的后臺系統(go-admin.cn)
- docker gocv
- go-fac
- MSYS2
- 企業開發框架系統推薦
- gorm
- go-zero
- 優秀系統
- GinSkeleton(gin web 及gin 知識)
- 一次 request -> response 的生命周期概述
- 路由與路由組以及gin源碼學習
- 中間件以及gin源碼學習
- golang項目部署
- 獨立部署golang
- 代理部署golang
- 容器部署golang
- golang交叉編譯
- goravel
- kardianos+gin 項目作為windows服務運行
- go env
- 適用在Windows、Linux和macOS環境下打包Go應用程序的詳細步驟和命令
- Redis
- Dochub
- Docker部署開發go環境
- Docker部署運行go環境
- dochub說明
- Vue
- i18n
- vue3
- vue3基本知識
- element-plus 表格單選
- vue3后臺模板
- Thinkphp
- Casbin權限控制中間件
- 容器、依賴注入、門面、事件、中間件
- tp6問答
- 偽靜態
- thinkphp-queue
- think-throttle
- thinkphp隊列queue的一些使用說明,queue:work和queue:listen的區別
- ThinkPHP6之模型事件的觸發條件
- thinkphp-swoole
- save、update、insert 的區別
- Socket
- workerman
- 介紹
- 從ThinkPHP6移植到Webman的一些技術和經驗(干貨)
- swoole
- swoole介紹
- hyperf
- hf官網
- Swoft
- swoft官網
- easyswoole
- easyswoole官網地址
- EASYSWOOLE 聊天室DEMO
- socket問答
- MySQL
- 聚簇索引與非聚簇索引
- Mysql使用max獲取最大值細節
- 主從復制
- 隨機生成20萬User表的數據
- MySQL進階-----前綴索引、單例與聯合索引
- PHP
- 面向切面編程AOP
- php是單線程的一定程度上也可以看成是“多線程”
- PHP 線程,進程、并發、并行 的理解
- excel數據畫表格圖片
- php第三方包
- monolog/monolog
- league/glide
- 博客-知識網站
- php 常用bc函數
- PHP知識點的應用場景
- AOP(面向切面編程)
- 注解
- 依賴注入
- 事件機制
- phpspreadsheet導出數據和圖片到excel
- Hyperf
- mineAdmin
- 微服務
- nacos注冊服務
- simps-mqtt連接客戶端simps
- Linux
- 切換php版本
- Vim
- Laravel
- RabbitMQ
- thinkphp+rabbitmq
- 博客
- Webman框架
- 框架注意問題
- 關于內存泄漏
- 移動端自動化
- 懶人精靈
- 工具應用
- render
- gitlab Sourcetree
- ssh-agent失敗 錯誤代碼-1
- 資源網站
- Git
- wkhtmltopdf
- MSYS2 介紹
- powershell curl 使用教程
- NSSM(windows服務工具)
- MinGW64
- 知識擴展
- 對象存儲系統
- minio
- 雪花ID
- 請求body參數類型
- GraphQL
- js 深拷貝
- window 共享 centos文件夾
- 前端get/post 請求 特殊符號 “+”傳參數問題
- 什么是SCM系統?SCM系統與ERP系統有什么區別?
- nginx 日志格式統一為 json
- 特殊符號怎么打
- 收藏網址
- 收藏-golang
- 收藏-vue3
- 收藏-php
- 收藏-node
- 收藏-前端
- 規劃ITEM
- 旅游類
- 人臉識別
- dlib
- Docker&&部署
- Docker-compose
- Docker的網絡模式
- rancher
- DHorse
- Elasticsearch
- es與kibana都docke連接
- 4種數據同步到Elasticsearch方案
- GPT
- 推薦系統
- fastposter海報生成
- elasticsearch+logstash+kibana
- beego文檔系統-MinDoc
- jeecg開源平臺
- Java
- 打包部署
- spring boot
- 依賴
- Maven 相關 命令
- Gradle 相關命令
- mybatis
- mybatis.plus
- spring boot 模板引擎
- SpringBoot+Maven多模塊項目(創建、依賴、打包可執行jar包部署測試)完整流程
- Spring Cloud
- Sentinel
- nacos
- Apollo
- java推薦項目
- gradle
- Maven
- Nexus倉庫管理器
- Python
- Masonite框架
- scrapy
- Python2的pip2
- Python3 安裝 pip3
- 安全攻防
- 運維技術
- 騰訊云安全加固建議
- 免費freessl證書申請
- ruby
- homeland
- Protobuf
- GIT
- FFMPEG
- 命令說明
- 音頻
- ffmpeg合并多個MP4視頻
- NODEJS
- 開發npm包
- MongoDB
- php-docker-mongodb環境搭建
- mongo基本命令
- Docker安裝MongoDB最新版并連接
- 少兒編程官網
- UI推薦
- MQTT
- PHP連接mqtt
- EMQX服務端
- php搭建mqtt服務端