
一、前綴索引
當字段類型為字符串( varchar , text , longtext 等)時,有時候需要索引很長的字符串,這會讓
索引變得很大,查詢時,浪費大量的磁盤 IO , 影響查詢效率。此時可以只將字符串的一部分前綴,建立索引,這樣可以大大節約索引空間,從而提高索引效率。
1. 語法
create index idx_xxxx on table_name(column(n)) ;
示例:
為 tb_user 表的 email 字段,建立長度為 5 的前綴索引。
create index index_email on tb_user(email(5));
2. 如何選擇前綴長度
可以根據索引的選擇性來決定,而選擇性是指不重復的索引值(基數)和數據表的記錄總數的比值,索引選擇性越高則查詢效率越高, 唯一索引的選擇性是1 ,這是最好的索引選擇性,性能也是最好的。
下面這里我們看一下案例:
select count(distinct email)/count(*) from tb_user;
可以看到上面顯示的是1,也就是說所有的email字段的數據都沒有出現重復,下面我們去從email字段數據去截取前5個字符比較試試看:
select count(distinct substring(email,1,5)) / count(*) from tb_user ;
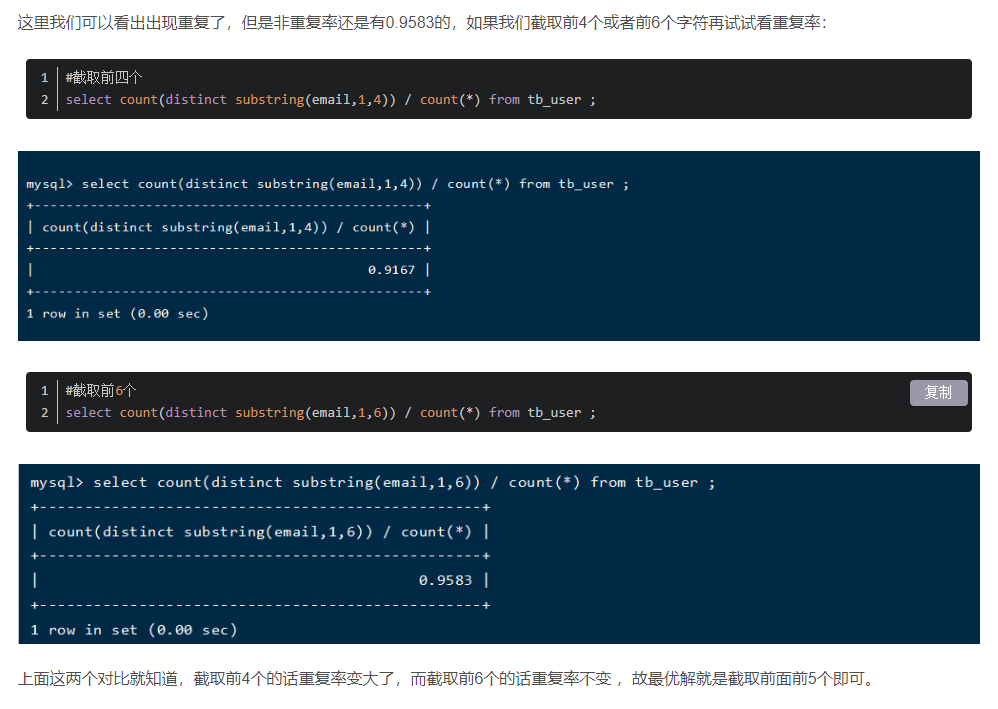
這里我們可以看出出現重復了,但是非重復率還是有0.9583的,如果我們截取前4個或者前6個字符再試試看重復率:
#截取前四個
select count(distinct substring(email,1,4)) / count(*) from tb_user ;
#截取前6個
select count(distinct substring(email,1,6)) / count(*) from tb_user ;
上面這兩個對比就知道,截取前4個的話重復率變大了,而截取前6個的話重復率不變 ,故最優解就是截取前面前5個即可。
3. 前綴索引的查詢流程
前綴索引的查詢流程基本上跟前面講到過的是差不多的,這里會通過我們選擇好的前綴去建立一個輔助索引,在輔助索引上面去找到相對應的索引目標,如果出現重復的話就會先找到第一個重復的索引數據,然后再去進行回表查詢,如果確定完整的字段能夠匹配成功的話就為當前字段,反正繼續遍歷下一個重復的結果。
二、單列索引與聯合索引
這個的話我們前面幾期的內容就接觸過了。
單列索引:即一個索引只包含單個列。
聯合索引:即一個索引包含了多個列。
我們先來看看 tb_user 表中目前的索引情況:
在查詢出來的索引中,既有單列索引,又有聯合索引。
接下來,我們來執行一條SQL語句,看看其執行計劃:
explain select id,phone,name from tb_user where phone='17799990000' and name='呂布';
通過上述執行計劃我們可以看出來,在 and 連接的兩個字段 phone 、 name 上都是有單列索引的,但是最終mysql 只會選擇一個索引,也就是說,只能走一個字段的索引,此時是會回表查詢的。
緊接著,我們再來創建一個 phone 和 name 字段的聯合索引來查詢一下執行計劃。
create unique index idx_user_phone_name on tb_user(phone,name);
此時,查詢時,就走了聯合索引,而在聯合索引中包含 phone、name的信息,在葉子節點下掛的是對應的主鍵id,所以查詢是無需回表查詢的。
如果查詢使用的是聯合索引,具體的結構示意圖如下:
在業務場景中,如果存在多個查詢條件,考慮針對于查詢字段建立索引時,建議建立聯合索引,而非單列索引 。
三、索引設計原則
```
* 針對于數據量較大,且查詢比較頻繁的表建立索引。
* 針對于常作為查詢條件(where)、排序(order by)、分組(group by)操作的字段建立索 引。
* 盡量選擇區分度高的列作為索引,盡量建立唯一索引,區分度越高,使用索引的效率越高。
* 如果是字符串類型的字段,字段的長度較長,可以針對于字段的特點,建立前綴索引。
* 盡量使用聯合索引,減少單列索引,查詢時,聯合索引很多時候可以覆蓋索引,節省存儲空間, 避免回表,提高查詢效率。
* 要控制索引的數量,索引并不是多多益善,索引越多,維護索引結構的代價也就越大,會影響增刪改的效率。
* 如果索引列不能存儲NULL值,請在創建表時使用NOT NULL約束它。當優化器知道每列是否包含NULL值時,它可以更好地確定哪個索引最有效地用于查詢
```
原文鏈接:https://blog.csdn.net/m0_73633088/article/details/137352430
- Golang
- Beego框架
- Gin框架
- gin框架介紹
- 使用Gin web框架的知名開源線上項目
- go-admin-gin
- air 熱啟動
- 完整的form表單參數驗證語法
- Go 語言入門練手項目推薦
- Golang是基于多線程模型
- golang 一些概念
- Golang程序開發注意事項
- fatal error: all goroutines are asleep - deadlock
- defer
- Golang 的內建調試器
- go部署
- golang指針重要性
- 包(golang)
- Golang框架選型比較: goframe, beego, iris和gin
- GoFrame
- golang-admin-項目
- go module的使用方法及原理
- go-admin支持多框架的后臺系統(go-admin.cn)
- docker gocv
- go-fac
- MSYS2
- 企業開發框架系統推薦
- gorm
- go-zero
- 優秀系統
- GinSkeleton(gin web 及gin 知識)
- 一次 request -> response 的生命周期概述
- 路由與路由組以及gin源碼學習
- 中間件以及gin源碼學習
- golang項目部署
- 獨立部署golang
- 代理部署golang
- 容器部署golang
- golang交叉編譯
- goravel
- kardianos+gin 項目作為windows服務運行
- go env
- 適用在Windows、Linux和macOS環境下打包Go應用程序的詳細步驟和命令
- Redis
- Dochub
- Docker部署開發go環境
- Docker部署運行go環境
- dochub說明
- Vue
- i18n
- vue3
- vue3基本知識
- element-plus 表格單選
- vue3后臺模板
- Thinkphp
- Casbin權限控制中間件
- 容器、依賴注入、門面、事件、中間件
- tp6問答
- 偽靜態
- thinkphp-queue
- think-throttle
- thinkphp隊列queue的一些使用說明,queue:work和queue:listen的區別
- ThinkPHP6之模型事件的觸發條件
- thinkphp-swoole
- save、update、insert 的區別
- Socket
- workerman
- 介紹
- 從ThinkPHP6移植到Webman的一些技術和經驗(干貨)
- swoole
- swoole介紹
- hyperf
- hf官網
- Swoft
- swoft官網
- easyswoole
- easyswoole官網地址
- EASYSWOOLE 聊天室DEMO
- socket問答
- MySQL
- 聚簇索引與非聚簇索引
- Mysql使用max獲取最大值細節
- 主從復制
- 隨機生成20萬User表的數據
- MySQL進階-----前綴索引、單例與聯合索引
- PHP
- 面向切面編程AOP
- php是單線程的一定程度上也可以看成是“多線程”
- PHP 線程,進程、并發、并行 的理解
- excel數據畫表格圖片
- php第三方包
- monolog/monolog
- league/glide
- 博客-知識網站
- php 常用bc函數
- PHP知識點的應用場景
- AOP(面向切面編程)
- 注解
- 依賴注入
- 事件機制
- phpspreadsheet導出數據和圖片到excel
- Hyperf
- mineAdmin
- 微服務
- nacos注冊服務
- simps-mqtt連接客戶端simps
- Linux
- 切換php版本
- Vim
- Laravel
- RabbitMQ
- thinkphp+rabbitmq
- 博客
- Webman框架
- 框架注意問題
- 關于內存泄漏
- 移動端自動化
- 懶人精靈
- 工具應用
- render
- gitlab Sourcetree
- ssh-agent失敗 錯誤代碼-1
- 資源網站
- Git
- wkhtmltopdf
- MSYS2 介紹
- powershell curl 使用教程
- NSSM(windows服務工具)
- MinGW64
- 知識擴展
- 對象存儲系統
- minio
- 雪花ID
- 請求body參數類型
- GraphQL
- js 深拷貝
- window 共享 centos文件夾
- 前端get/post 請求 特殊符號 “+”傳參數問題
- 什么是SCM系統?SCM系統與ERP系統有什么區別?
- nginx 日志格式統一為 json
- 特殊符號怎么打
- 收藏網址
- 收藏-golang
- 收藏-vue3
- 收藏-php
- 收藏-node
- 收藏-前端
- 規劃ITEM
- 旅游類
- 人臉識別
- dlib
- Docker&&部署
- Docker-compose
- Docker的網絡模式
- rancher
- DHorse
- Elasticsearch
- es與kibana都docke連接
- 4種數據同步到Elasticsearch方案
- GPT
- 推薦系統
- fastposter海報生成
- elasticsearch+logstash+kibana
- beego文檔系統-MinDoc
- jeecg開源平臺
- Java
- 打包部署
- spring boot
- 依賴
- Maven 相關 命令
- Gradle 相關命令
- mybatis
- mybatis.plus
- spring boot 模板引擎
- SpringBoot+Maven多模塊項目(創建、依賴、打包可執行jar包部署測試)完整流程
- Spring Cloud
- Sentinel
- nacos
- Apollo
- java推薦項目
- gradle
- Maven
- Nexus倉庫管理器
- Python
- Masonite框架
- scrapy
- Python2的pip2
- Python3 安裝 pip3
- 安全攻防
- 運維技術
- 騰訊云安全加固建議
- 免費freessl證書申請
- ruby
- homeland
- Protobuf
- GIT
- FFMPEG
- 命令說明
- 音頻
- ffmpeg合并多個MP4視頻
- NODEJS
- 開發npm包
- MongoDB
- php-docker-mongodb環境搭建
- mongo基本命令
- Docker安裝MongoDB最新版并連接
- 少兒編程官網
- UI推薦
- MQTT
- PHP連接mqtt
- EMQX服務端
- php搭建mqtt服務端