
## ClickHouse簡介
?
* ClickHouse是俄羅斯的Yandex于2016年開源的一個用于聯機分析(OLAP:Online Analytical Processing)的列式數據庫管理系統(DBMS:Database Management System) , 主要用于在線分析處理查詢(OLAP),能夠使用SQL查詢實時生成分析數據報告。 ClickHouse的全稱是Click Stream,Data WareHouse,簡稱ClickHouse
* ClickHouse是一個完全的列式分布式數據庫管理系統(DBMS),允許在運行時創建表和數據庫,加載數據和運行查詢,而無需重新配置和重新啟動服務器,支持線性擴展,簡單方便,高可靠性,容錯。它在大數據領域沒有走 Hadoop 生態,而是采用 Local attached storage 作為存儲,這樣整個 IO 可能就沒有 Hadoop 那一套的局限。它的系統在生產環境中可以應用到比較大的規模,因為它的線性擴展能力和可靠性保障能夠原生支持 shard + replication 這種解決方案。它還提供了一些 SQL 直接接口,有比較豐富的原生 client。
## 官方文檔
中文文檔
[https://clickhouse.tech/docs/zh/](https://clickhouse.tech/docs/zh/)
英文文檔
[https://clickhouse.tech/docs/en/](https://clickhouse.tech/docs/en/)
版本原因,中文文檔不全面,建議使用英文文檔
例如:

## ClickHouse特性
* 列式數據庫
* 數據壓縮
* 支持SQL
* 實時數據更新
...
[https://clickhouse.tech/docs/zh/introduction/distinctive-features/](https://clickhouse.tech/docs/zh/introduction/distinctive-features/)
## ClickHouse性能
* 單個查詢的吞吐量
吞吐量可以使用每秒處理的行數或每秒處理的字節數來衡量。如果數據被放置在page cache中,則一個不太復雜的查詢在單個服務器上大約能夠以2-10GB/s(未壓縮)的速度進行處理(對于簡單的查詢,速度可以達到30GB/s)。如果數據沒有在page cache中的話,那么速度將取決于你的磁盤系統和數據的壓縮率。例如,如果一個磁盤允許以400MB/s的速度讀取數據,并且數據壓縮率是3,則數據的處理速度為1.2GB/s。這意味著,如果你是在提取一個10字節的列,**那么它的處理速度大約是1-2億行每秒**。
對于分布式處理,處理速度幾乎是線性擴展的,但這受限于聚合或排序的結果不是那么大的情況下。
* 查詢的延遲時間
如果一個查詢使用主鍵并且沒有太多行(幾十萬)進行處理,并且沒有查詢太多的列,那么在數據被page cache緩存的情況下,它的延遲應該**小于50毫秒**(在最佳的情況下應該小于10毫秒)。 否則,延遲取決于數據的查找次數。如果你當前使用的是HDD,在數據沒有加載的情況下,查詢所需要的延遲可以通過以下公式計算得知: 查找時間(10 ms) \* 查詢的列的數量 \* 查詢的數據塊的數量。
* 查詢的吞吐量
ClickHouse可以在單個服務器上每秒處理數百個查詢(在最佳的情況下最多可以處理數千個)。但是由于這不適用于分析型場景。因此我們建議每秒最多查詢100次。
* 寫入性能
我們建議每次寫入不少于1000行的批量寫入,或每秒不超過一個寫入請求。當使用tab-separated格式將一份數據寫入到MergeTree表中時,寫入速度大約為50到200MB/s。如果您寫入的數據每行為1Kb,**那么寫入的速度為50,000到200,000行每秒**。如果您的行更小,那么寫入速度將更高。為了提高寫入性能,您可以使用多個INSERT進行并行寫入,這將帶來線性的性能提升。
[https://clickhouse.tech/docs/zh/introduction/performance/](https://clickhouse.tech/docs/zh/introduction/performance/)
## ClickHouse優點
靈活的MPP架構,支持線性擴展,簡單方便,高可靠性
多服務器分布式處理數據 ,完備的DBMS系統
底層數據列式存儲,支持壓縮,優化數據存儲,優化索引數據 優化底層存儲
容錯跑分快:比Vertica快5倍,比Hive快279倍,比MySQL快800倍,其可處理的數據級別已達到10億級別
功能多:支持數據統計分析各種場景,支持類SQL查詢,異地復制部署
海量數據存儲,分布式運算,快速閃電的性能,幾乎實時的數據分析 ,友好的SQL語法,出色的函數支持
## ClickHouse缺點
不支持事務,不支持真正的刪除/更新
不支持高并發,官方建議qps為100,可以通過修改配置文件增加連接數,但是在服務器足夠好的情況下
不支持二級索引
不擅長多表join
元數據管理需要人為干預
盡量做1000條以上批量的寫入,避免逐行insert或小批量的insert,update,delete操作
依賴zookeeper
## 使用場景
1.絕大多數請求都是用于讀訪問的, 要求實時返回結果
2.數據需要以大批次(大于1000行)進行更新,而不是單行更新;或者根本沒有更新操作
3.數據只是添加到數據庫,沒有必要修改
4.讀取數據時,會從數據庫中提取出大量的行,但只用到一小部分列
5.表很“寬”,即表中包含大量的列
6.查詢頻率相對較低(通常每臺服務器每秒查詢數百次或更少)
7.對于簡單查詢,允許大約50毫秒的延遲
8.列的值是比較小的數值和短字符串(例如,每個URL只有60個字節)
9.在處理單個查詢時需要高吞吐量(每臺服務器每秒高達數十億行)
10.不需要事務
11.數據一致性要求較低 \[原子性 持久性 一致性 隔離性\]
12.每次查詢中只會查詢一個大表。除了一個大表,其余都是小表
13.查詢結果顯著小于數據源。即數據有過濾或聚合。返回結果不超過單個服務器內存大小
## 不適合場景
不支持事務(對并發的讀寫不支持,批量插入是支持事務的)
不擅長根據主鍵按行粒度進行查詢,不應該把ClickHouse當作Key-Value數據庫使用
不擅長按行刪除數據(支持但不擅長,一般批量刪除)
## OLTP和OLAP
業務類系統主要供基層人員使用,進行一線業務操作,通常被稱為OLTP(On-Line Transaction Processing,聯機事務處理)。
數據分析的目標則是探索并挖掘數據價值,作為企業高層進行決策的參考,通常被稱為OLAP(On-Line Analytical Processing,聯機分析處理)。
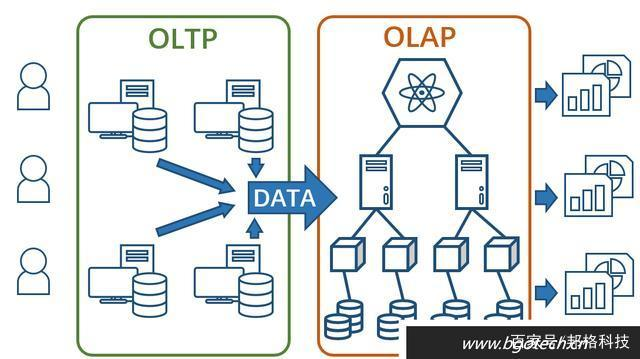
從功能角度來看,OLTP負責基本業務的正常運轉,而業務數據積累時所產生的價值信息則被OLAP不斷呈現,企業高層通過參考這些信息會不斷調整經營方針,也會促進基礎業務的不斷優化,這是OLTP與OLAP最根本的區別。
OLAP不應該對OLTP產生任何影響,(理想情況下)OLTP應該完全感覺不到OLAP的存在。
## 核心概念
列式存儲
列式數據庫更適合于OLAP場景(對于大多數查詢而言,處理速度至少提高了100倍),下面詳細解釋了原因(通過圖片更有利于直觀理解):

分片
* ClickHouse支持分片,而分片則依賴集群。每個集群由1到多個分片組成,而每個分片則對應了ClickHouse的1個服務節點。分片的數量上限 取決于節點數量(1個分片只能對應1個服務節點)。ClickHouse并不像其他分布式系統那樣,擁有高度自動化的分片功能。
* ClickHouse提供了本地表(Local Table)與分布式表(Distributed Table)的概念。一張本地表等同于一份數據的分片。而分布式表本身不存儲任何數據,它是本地表的訪問代理,其作用類似分庫中間件。借助分布式表,能夠代理訪問多個數據分片,從而實現分布式查詢。
副本
* 數據存儲副本,在集群模式下實現高可用 , 簡單理解就是相同的數據備份,在CK中通過復制集,我們實現保障了數據可靠性外,也通過多副本的方式,增加了CK查詢的并發能力。這里一般有2種方式:(1)基于ZooKeeper的表復制方式;(2)基于C[1.2ClickHouse安裝](http://www.hmoore.net/kanbaobao/clickhouse/1.2ClickHouse%E5%AE%89%E8%A3%85.md)luster的復制方式。由于我們推薦的數據寫入方式本地表寫入,禁止分布式表寫入,所以我們的復制表只考慮ZooKeeper的表復制方案。
分區
* ClickHouse支持PARTITION BY子句,在建表時可以指定按照任意合法表達式進行數據分區操作,比如通過toYYYYMM()將數據按月進行分區、toMonday()將數據按照周幾進行分區、對Enum類型的列直接每種取值作為一個分區等。數據以分區的形式統一管理和維護一批數據!
表
* 表的基本結構和數據
引擎
* 表引擎決定了數據在文件系統中的存儲方式,常用的也是官方推薦的存儲引擎是MergeTree系列,如果需要數據副本的話可以使用ReplicatedMergeTree系列,相當于MergeTree的副本版本。讀取集群數據需要使用分布式表引擎Distribute。
向量化
* ClickHouse實現了向量執行引擎(Vectorized execution engine),對內存中的列式數據,一個batch調用一次SIMD指令(而非每一行調用一次),不僅減少了函數調用次數、降低了cache miss,而且可以充分發揮SIMD指令的并行能力,大幅縮短了計算耗時。向量執行引擎,通常能夠帶來數倍的性能提升。
(SIMD全稱Single Instruction Multiple Data,單指令多數據流,能夠復制多個操作數,并把它們打包在大型寄存器的一組指令集。以同步方式,在同一時間內執行同一條指令。)
## ClickHouse VS ElasticSearch
[https://developer.aliyun.com/article/783804?spm=5176.20128342.J\_6302206100.2.9a567ba2KDUuLj&groupCode=clickhouse](https://developer.aliyun.com/article/783804?spm=5176.20128342.J_6302206100.2.9a567ba2KDUuLj&groupCode=clickhouse)
- ClickHouse
- 第一節 ClickHouse入門
- 1.1 ClickHouse概述
- 1.2 ClickHouse單機安裝
- 1.3 ClickHouse配置
- 1.4 ClickHouse數據庫引擎
- 1.5 ClickHouse集群部署
- 第二節 ClickHouse進階
- 2.1 ClicKHouse數據類型
- 2.2 ClicKHouse基本語法
- 2.3 ClickHouse引擎
- 2.4 ClickHouse函數
- 2.5 ClickHouse分布式表
- 2.6 ClickHouse權限和密碼加密
- 2.7 ClickHouse數據導入和導出
- 第三節 ClicKHouse實戰篇
- 3.1 ClickHouse的JDBC連接
- 3.2 ClickHouse用戶行為分析
- 3.3 ClickHouse實戰
- 第四節 ClicKHouse常見問題
- 4.1 ClickHouse常見問題匯總
- 第五節 ClickHouse其他
- 5.1 ClickHouse可視化工具
- 5.2 ClickHouse學習教程